 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyAI-VL-Interaction: Real-Time Vision-Language Interaction Intelligence
Jun 10, 2026Many moments in the real world do not wait for a user to ask. A fire starts on a security monitor, an expression flickers across a video call, or a product a viewer wants flashes by in a livestream. Yet today's large models remain mostly turn-based by design: they answer only when addressed, and even video-call apps that appear interactive still operate as question-answer systems, reacting only when polled or prompted. We argue for a different paradigm: a model that is present in the world like a person. It continuously watches what is happening now, decides on its own whether to speak or stay silent, interacts in real time, and delegates to a background model when the problem is hard. To advance interaction models and their adoption across domains, we make two fully open-sourced contributions. First, we release JoyAI-VL-Interaction, an 8B-scale, vision-first VL-interaction model. The model makes the response decision internally, choosing each second to stay silent, respond, or delegate to a background model, and it excels at vision-triggered responsiveness and time awareness. We pair it with a transferable training recipe, from which capabilities we never trained for emerge, such as guiding a shopper through changing app screens or improvising a lecture from a slide deck. Second, we release a complete, deployable system built around that model. The system streams any ongoing video into the model, making it genuinely present in the world. All other components are pluggable, including ASR/TTS modules, memory, visualization UI, and a background brain that can connect to any API or agent. Across six real-world scenarios, human raters prefer JoyAI-VL-Interaction over the in-app video-call assistants of Doubao and Gemini by a wide margin. To our knowledge, this is the first open, vision-driven interaction model released together with its training recipe, data, and complete deployable system.
Harnessing Streaming Video in the Wild
Jun 07, 2026Vision-Language Models (VLMs) are increasingly required to process unbounded video streams in applications such as video-call assistants, live commentary, and embodied robots. An ideal streaming system should support proactive interaction, long-horizon memory, and real-time processing, while resting on a VLM backbone capable of handling diverse in-the-wild streaming tasks. However, existing VLMs excel at offline video understanding but fall short in streaming capabilities and lack dedicated infrastructure for streaming deployment. We address this gap on three fronts. (i) For backbone capability, we construct \textbf{Streaming-Train-248K}, a streaming dataset paired with a novel training objective for adapting VLMs to streaming interaction and understanding. (ii) For real-world deployment, we introduce \textbf{Streaming Harness}, a plug-and-play system that endows any VLM with three core abilities: proactive interaction (per-second response decisions), long-term memory (12-hour context retention), and real-time processing (sub-second latency). (iii) To drive continued community progress on streaming capabilities, we design \textbf{Streaming-Eval}, a benchmark that reflects models' capabilities across diverse in-the-wild scenarios. Extensive experiments demonstrate consistent gains from our approach across all core capabilities required for streaming video understanding. We will open-source our data, code, and benchmark to advance the community's shift from offline video understanding to deployable streaming intelligence.
Property Inference Attacks Against GANs
Nov 15, 2021

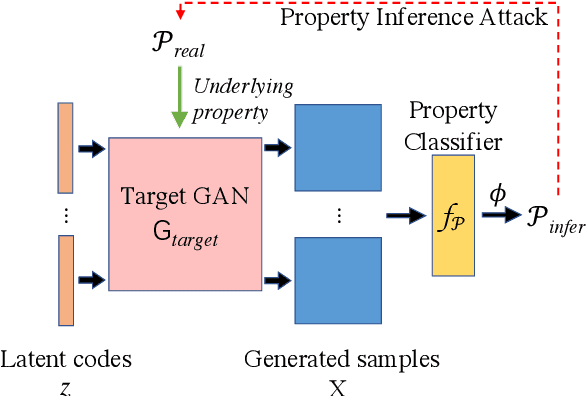

While machine learning (ML) has made tremendous progress during the past decade, recent research has shown that ML models are vulnerable to various security and privacy attacks. So far, most of the attacks in this field focus on discriminative models, represented by classifiers. Meanwhile, little attention has been paid to the security and privacy risks of generative models, such as generative adversarial networks (GANs). In this paper, we propose the first set of training dataset property inference attacks against GANs. Concretely, the adversary aims to infer the macro-level training dataset property, i.e., the proportion of samples used to train a target GAN with respect to a certain attribute. A successful property inference attack can allow the adversary to gain extra knowledge of the target GAN's training dataset, thereby directly violating the intellectual property of the target model owner. Also, it can be used as a fairness auditor to check whether the target GAN is trained with a biased dataset. Besides, property inference can serve as a building block for other advanced attacks, such as membership inference. We propose a general attack pipeline that can be tailored to two attack scenarios, including the full black-box setting and partial black-box setting. For the latter, we introduce a novel optimization framework to increase the attack efficacy. Extensive experiments over four representative GAN models on five property inference tasks show that our attacks achieve strong performance. In addition, we show that our attacks can be used to enhance the performance of membership inference against GANs.