 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Saliency and Coverage: Semantic Prominence-Aware Budgeting for Visual Token Compression in VLMs
Mar 16, 2026Large Vision-Language Models (VLMs) achieve strong multimodal understanding capabilities by leveraging high-resolution visual inputs, but the resulting large number of visual tokens creates a major computational bottleneck. Recent work mitigates this issue through visual token compression, typically compressing tokens based on saliency, diversity, or a fixed combination of both. We observe that the distribution of semantic prominence varies substantially across samples, leading to different optimal trade-offs between local saliency preservation and global coverage. This observation suggests that applying a static compression strategy across all samples can be suboptimal. Motivated by this insight, we propose PromPrune, a sample-adaptive visual token selection framework composed of semantic prominence-aware budget allocation and a two-stage selection pipeline. Our method adaptively balances local saliency preservation and global coverage according to the semantic prominence distribution of each sample. By allocating token budgets between locally salient regions and globally diverse regions, our method maintains strong performance even under high compression ratios. On LLaVA-NeXT-7B, our approach reduces FLOPs by 88% and prefill latency by 22% while preserving 97.5% of the original accuracy.
SAVE: Sparse Autoencoder-Driven Visual Information Enhancement for Mitigating Object Hallucination
Dec 11, 2025Although Multimodal Large Language Models (MLLMs) have advanced substantially, they remain vulnerable to object hallucination caused by language priors and visual information loss. To address this, we propose SAVE (Sparse Autoencoder-Driven Visual Information Enhancement), a framework that mitigates hallucination by steering the model along Sparse Autoencoder (SAE) latent features. A binary object-presence question-answering probe identifies the SAE features most indicative of the model's visual information processing, referred to as visual understanding features. Steering the model along these identified features reinforces grounded visual understanding and effectively reduces hallucination. With its simple design, SAVE outperforms state-of-the-art training-free methods on standard benchmarks, achieving a 10\%p improvement in CHAIR\_S and consistent gains on POPE and MMHal-Bench. Extensive evaluations across multiple models and layers confirm the robustness and generalizability of our approach. Further analysis reveals that steering along visual understanding features suppresses the generation of uncertain object tokens and increases attention to image tokens, mitigating hallucination. Code is released at https://github.com/wiarae/SAVE.
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Dec 06, 2024



Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
Improving Visual Prompt Tuning for Self-supervised Vision Transformers
Jun 08, 2023



Visual Prompt Tuning (VPT) is an effective tuning method for adapting pretrained Vision Transformers (ViTs) to downstream tasks. It leverages extra learnable tokens, known as prompts, which steer the frozen pretrained ViTs. Although VPT has demonstrated its applicability with supervised vision transformers, it often underperforms with self-supervised ones. Through empirical observations, we deduce that the effectiveness of VPT hinges largely on the ViT blocks with which the prompt tokens interact. Specifically, VPT shows improved performance on image classification tasks for MAE and MoCo v3 when the prompt tokens are inserted into later blocks rather than the first block. These observations suggest that there exists an optimal location of blocks for the insertion of prompt tokens. Unfortunately, identifying the optimal blocks for prompts within each self-supervised ViT for diverse future scenarios is a costly process. To mitigate this problem, we propose a simple yet effective method that learns a gate for each ViT block to adjust its intervention into the prompt tokens. With our method, prompt tokens are selectively influenced by blocks that require steering for task adaptation. Our method outperforms VPT variants in FGVC and VTAB image classification and ADE20K semantic segmentation. The code is available at https://github.com/ryongithub/GatedPromptTuning.
A Robotic Dating Coaching System Leveraging Online Communities Posts
Nov 24, 2020
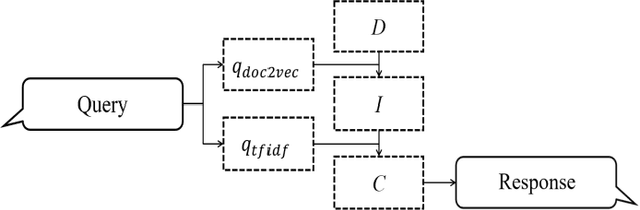
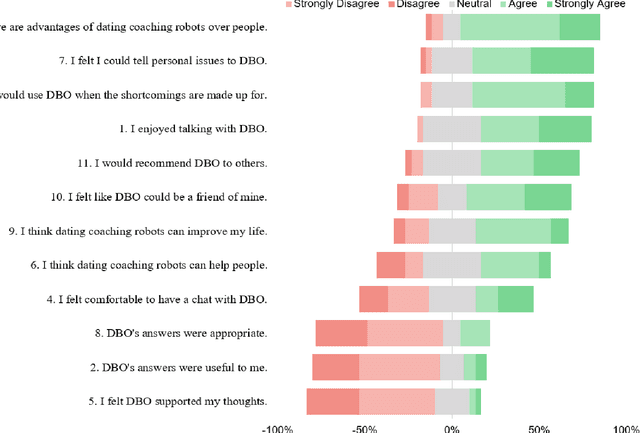
Can a robot be a personal dating coach? Even with the increasing amount of conversational data on the internet, the implementation of conversational robots remains a challenge. In particular, a detailed and professional counseling log is expensive and not publicly accessible. In this paper, we develop a robot dating coaching system leveraging corpus from online communities. We examine people's perceptions of the dating coaching robot with a dialogue module. 97 participants joined to have a conversation with the robot, and 30 of them evaluated the robot. The results indicate that participants thought the robot could become a dating coach while considering the robot is entertaining rather than helpful.