 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Based Search for Deep Generative Models
Oct 06, 2022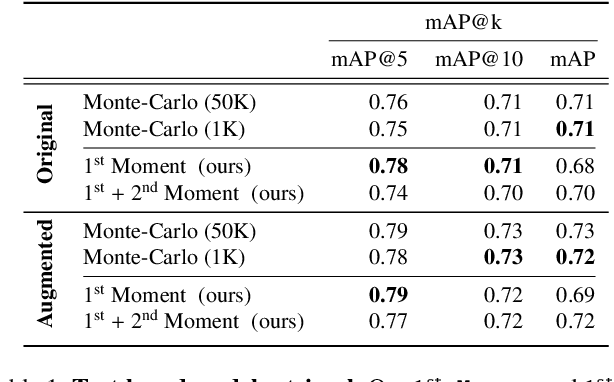
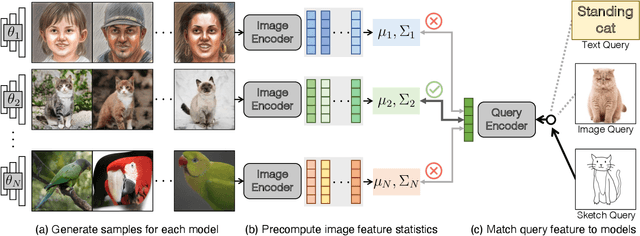
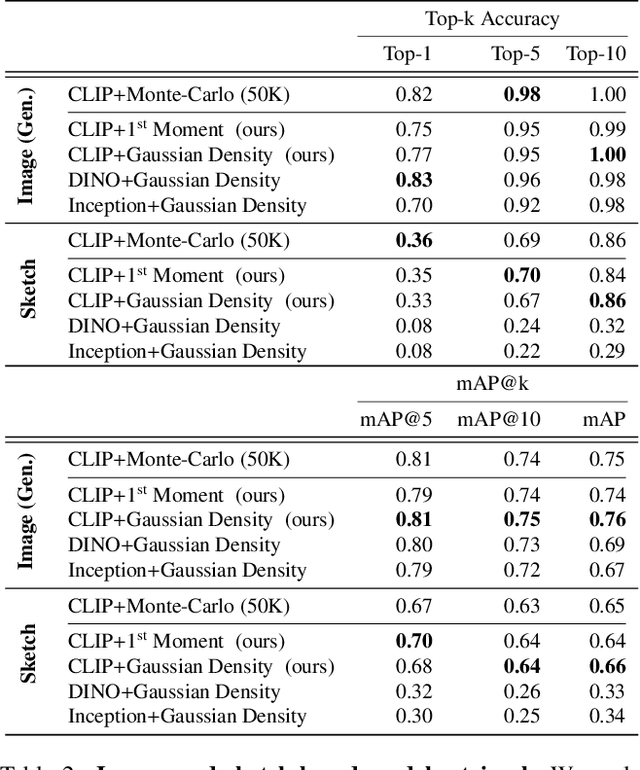

The growing proliferation of pretrained generative models has made it infeasible for a user to be fully cognizant of every model in existence. To address this need, we introduce the task of content-based model search: given a query and a large set of generative models, find the models that best match the query. Because each generative model produces a distribution of images, we formulate the search problem as an optimization to maximize the probability of generating a query match given a model. We develop approximations to make this problem tractable when the query is an image, a sketch, a text description, another generative model, or a combination of the above. We benchmark our method in both accuracy and speed over a set of generative models. We demonstrate that our model search retrieves suitable models for image editing and reconstruction, few-shot transfer learning, and latent space interpolation. Finally, we deploy our search algorithm to our online generative model-sharing platform at https://modelverse.cs.cmu.edu.
Rewriting Geometric Rules of a GAN
Jul 28, 2022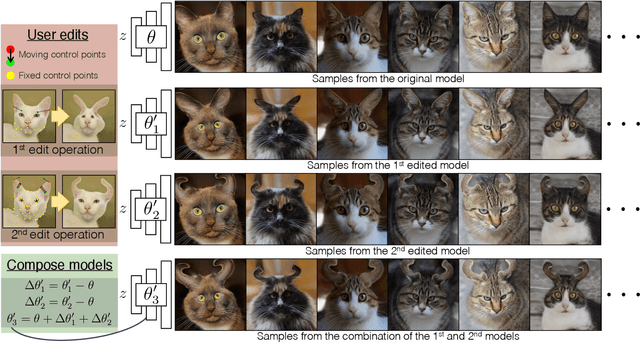
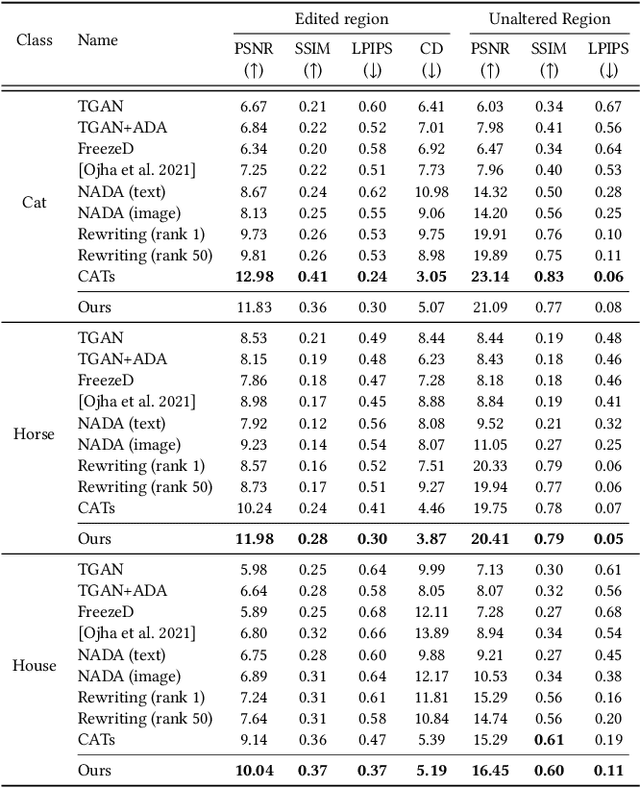
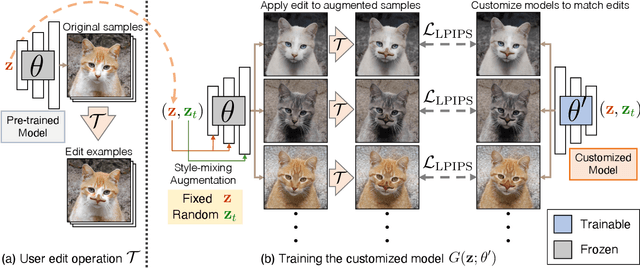
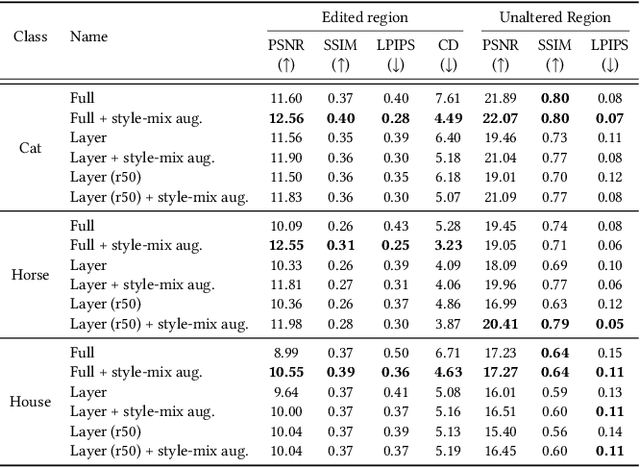
Deep generative models make visual content creation more accessible to novice users by automating the synthesis of diverse, realistic content based on a collected dataset. However, the current machine learning approaches miss a key element of the creative process -- the ability to synthesize things that go far beyond the data distribution and everyday experience. To begin to address this issue, we enable a user to "warp" a given model by editing just a handful of original model outputs with desired geometric changes. Our method applies a low-rank update to a single model layer to reconstruct edited examples. Furthermore, to combat overfitting, we propose a latent space augmentation method based on style-mixing. Our method allows a user to create a model that synthesizes endless objects with defined geometric changes, enabling the creation of a new generative model without the burden of curating a large-scale dataset. We also demonstrate that edited models can be composed to achieve aggregated effects, and we present an interactive interface to enable users to create new models through composition. Empirical measurements on multiple test cases suggest the advantage of our method against recent GAN fine-tuning methods. Finally, we showcase several applications using the edited models, including latent space interpolation and image editing.
Spatially-Adaptive Multilayer Selection for GAN Inversion and Editing
Jun 16, 2022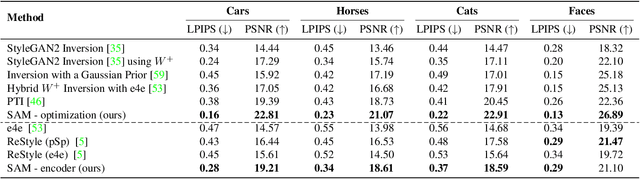
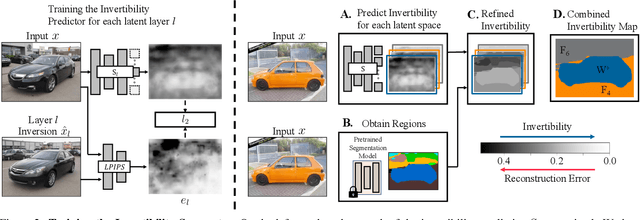
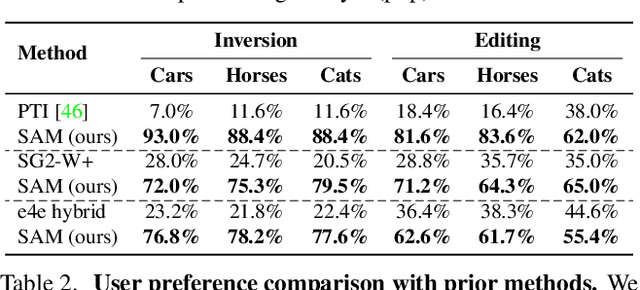

Existing GAN inversion and editing methods work well for aligned objects with a clean background, such as portraits and animal faces, but often struggle for more difficult categories with complex scene layouts and object occlusions, such as cars, animals, and outdoor images. We propose a new method to invert and edit such complex images in the latent space of GANs, such as StyleGAN2. Our key idea is to explore inversion with a collection of layers, spatially adapting the inversion process to the difficulty of the image. We learn to predict the "invertibility" of different image segments and project each segment into a latent layer. Easier regions can be inverted into an earlier layer in the generator's latent space, while more challenging regions can be inverted into a later feature space. Experiments show that our method obtains better inversion results compared to the recent approaches on complex categories, while maintaining downstream editability. Please refer to our project page at https://www.cs.cmu.edu/~SAMInversion.
Dataset Distillation by Matching Training Trajectories
Mar 22, 2022
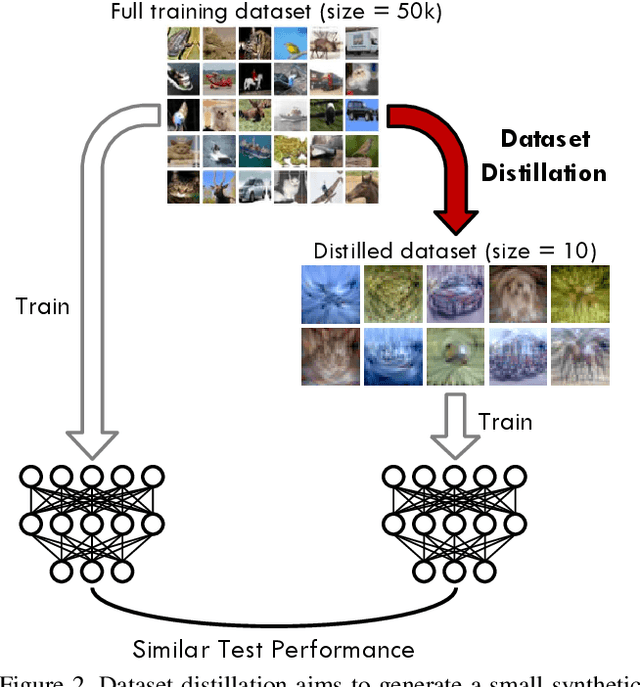
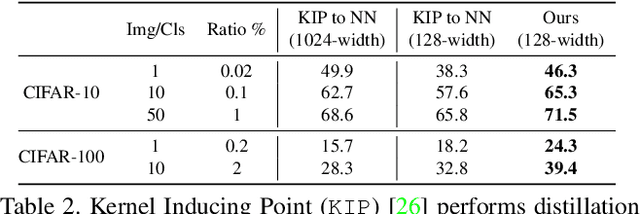
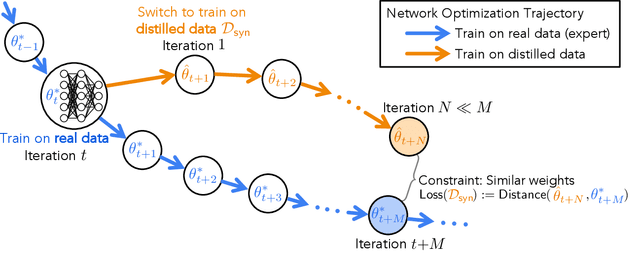
Dataset distillation is the task of synthesizing a small dataset such that a model trained on the synthetic set will match the test accuracy of the model trained on the full dataset. In this paper, we propose a new formulation that optimizes our distilled data to guide networks to a similar state as those trained on real data across many training steps. Given a network, we train it for several iterations on our distilled data and optimize the distilled data with respect to the distance between the synthetically trained parameters and the parameters trained on real data. To efficiently obtain the initial and target network parameters for large-scale datasets, we pre-compute and store training trajectories of expert networks trained on the real dataset. Our method handily outperforms existing methods and also allows us to distill higher-resolution visual data.
Ensembling Off-the-shelf Models for GAN Training
Jan 18, 2022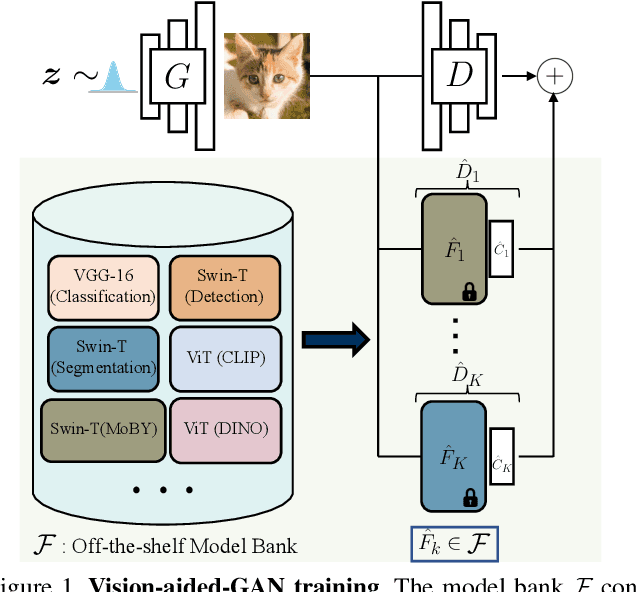
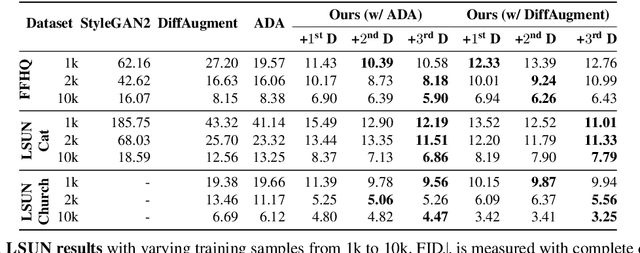
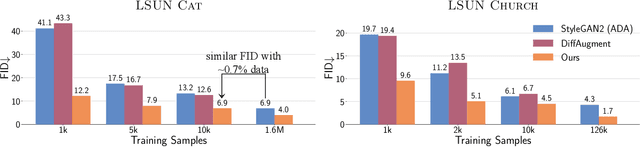
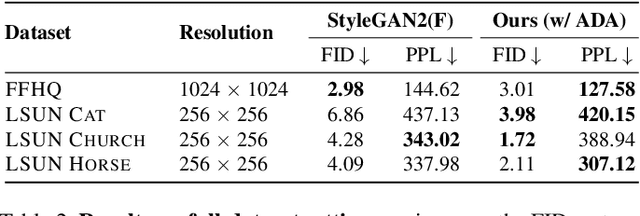
The advent of large-scale training has produced a cornucopia of powerful visual recognition models. However, generative models, such as GANs, have traditionally been trained from scratch in an unsupervised manner. Can the collective "knowledge" from a large bank of pretrained vision models be leveraged to improve GAN training? If so, with so many models to choose from, which one(s) should be selected, and in what manner are they most effective? We find that pretrained computer vision models can significantly improve performance when used in an ensemble of discriminators. Notably, the particular subset of selected models greatly affects performance. We propose an effective selection mechanism, by probing the linear separability between real and fake samples in pretrained model embeddings, choosing the most accurate model, and progressively adding it to the discriminator ensemble. Interestingly, our method can improve GAN training in both limited data and large-scale settings. Given only 10k training samples, our FID on LSUN Cat matches the StyleGAN2 trained on 1.6M images. On the full dataset, our method improves FID by 1.5x to 2x on cat, church, and horse categories of LSUN.
GAN-Supervised Dense Visual Alignment
Dec 09, 2021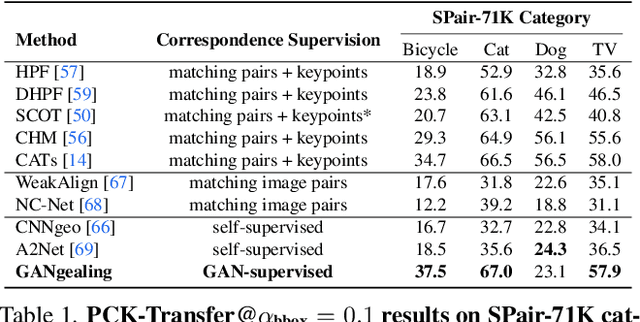
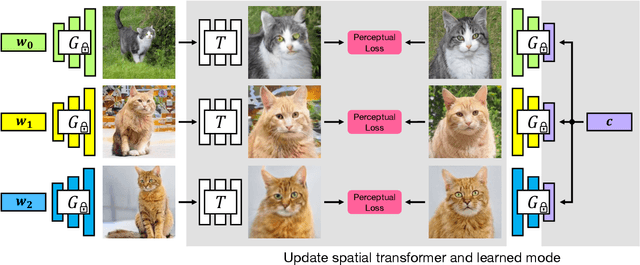


We propose GAN-Supervised Learning, a framework for learning discriminative models and their GAN-generated training data jointly end-to-end. We apply our framework to the dense visual alignment problem. Inspired by the classic Congealing method, our GANgealing algorithm trains a Spatial Transformer to map random samples from a GAN trained on unaligned data to a common, jointly-learned target mode. We show results on eight datasets, all of which demonstrate our method successfully aligns complex data and discovers dense correspondences. GANgealing significantly outperforms past self-supervised correspondence algorithms and performs on-par with (and sometimes exceeds) state-of-the-art supervised correspondence algorithms on several datasets -- without making use of any correspondence supervision or data augmentation and despite being trained exclusively on GAN-generated data. For precise correspondence, we improve upon state-of-the-art supervised methods by as much as $3\times$. We show applications of our method for augmented reality, image editing and automated pre-processing of image datasets for downstream GAN training.
Contrastive Feature Loss for Image Prediction
Nov 12, 2021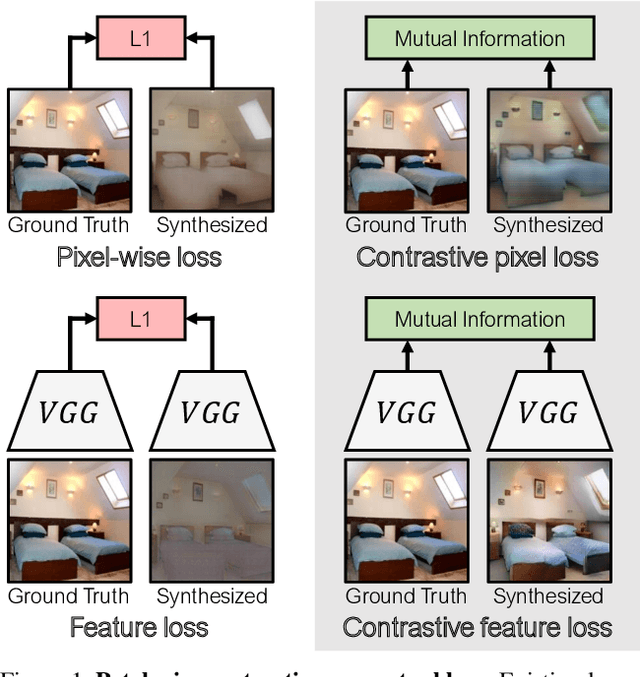
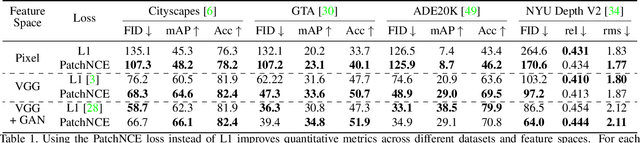
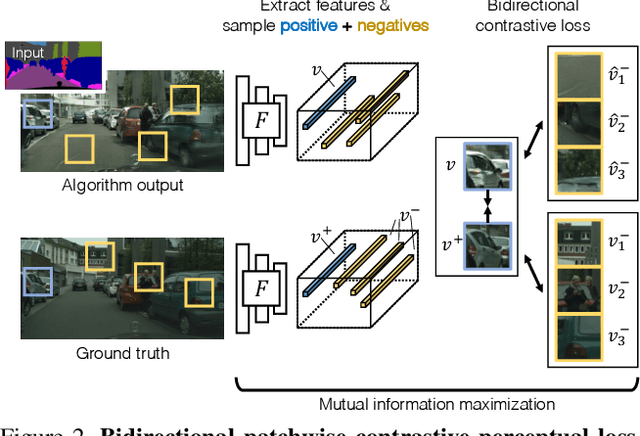
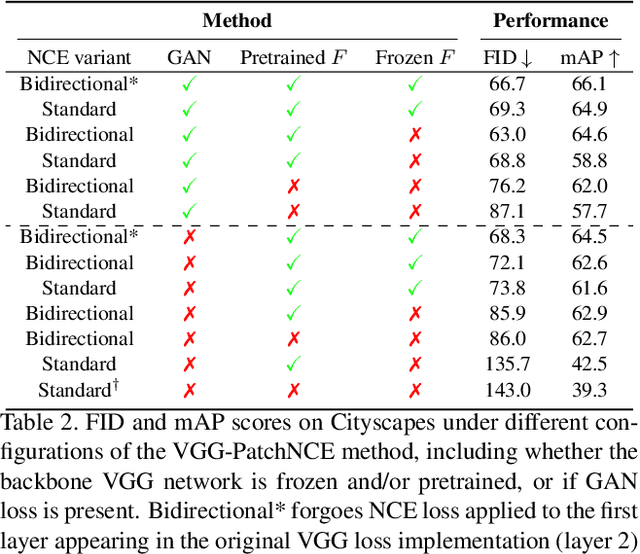
Training supervised image synthesis models requires a critic to compare two images: the ground truth to the result. Yet, this basic functionality remains an open problem. A popular line of approaches uses the L1 (mean absolute error) loss, either in the pixel or the feature space of pretrained deep networks. However, we observe that these losses tend to produce overly blurry and grey images, and other techniques such as GANs need to be employed to fight these artifacts. In this work, we introduce an information theory based approach to measuring similarity between two images. We argue that a good reconstruction should have high mutual information with the ground truth. This view enables learning a lightweight critic to "calibrate" a feature space in a contrastive manner, such that reconstructions of corresponding spatial patches are brought together, while other patches are repulsed. We show that our formulation immediately boosts the perceptual realism of output images when used as a drop-in replacement for the L1 loss, with or without an additional GAN loss.
Sketch Your Own GAN
Aug 05, 2021
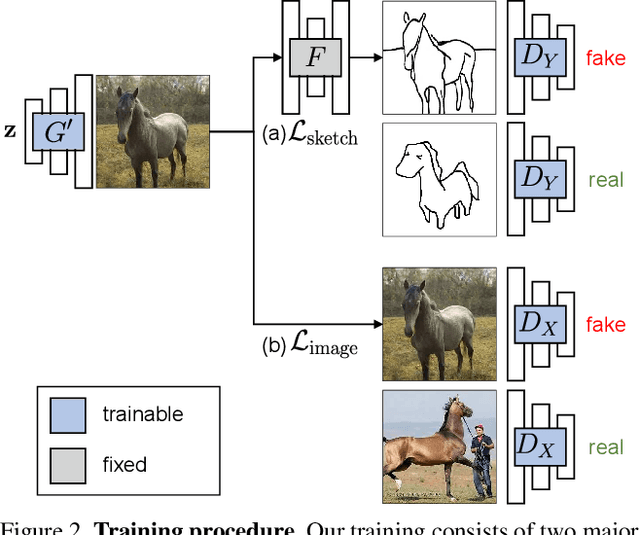
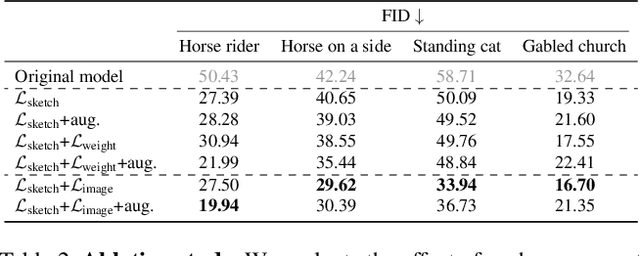

Can a user create a deep generative model by sketching a single example? Traditionally, creating a GAN model has required the collection of a large-scale dataset of exemplars and specialized knowledge in deep learning. In contrast, sketching is possibly the most universally accessible way to convey a visual concept. In this work, we present a method, GAN Sketching, for rewriting GANs with one or more sketches, to make GANs training easier for novice users. In particular, we change the weights of an original GAN model according to user sketches. We encourage the model's output to match the user sketches through a cross-domain adversarial loss. Furthermore, we explore different regularization methods to preserve the original model's diversity and image quality. Experiments have shown that our method can mold GANs to match shapes and poses specified by sketches while maintaining realism and diversity. Finally, we demonstrate a few applications of the resulting GAN, including latent space interpolation and image editing.
SDEdit: Image Synthesis and Editing with Stochastic Differential Equations
Aug 02, 2021
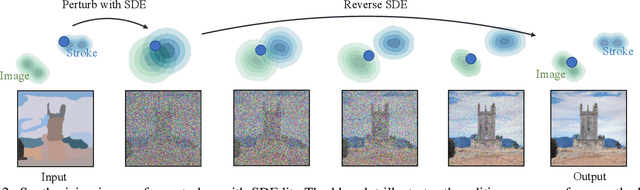
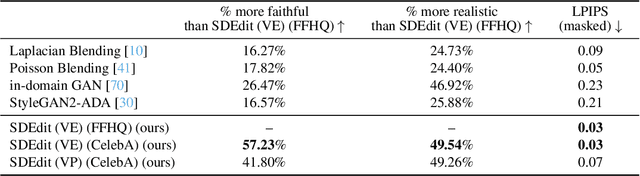

We introduce a new image editing and synthesis framework, Stochastic Differential Editing (SDEdit), based on a recent generative model using stochastic differential equations (SDEs). Given an input image with user edits (e.g., hand-drawn color strokes), we first add noise to the input according to an SDE, and subsequently denoise it by simulating the reverse SDE to gradually increase its likelihood under the prior. Our method does not require task-specific loss function designs, which are critical components for recent image editing methods based on GAN inversion. Compared to conditional GANs, we do not need to collect new datasets of original and edited images for new applications. Therefore, our method can quickly adapt to various editing tasks at test time without re-training models. Our approach achieves strong performance on a wide range of applications, including image synthesis and editing guided by stroke paintings and image compositing.
Depth-supervised NeRF: Fewer Views and Faster Training for Free
Jul 06, 2021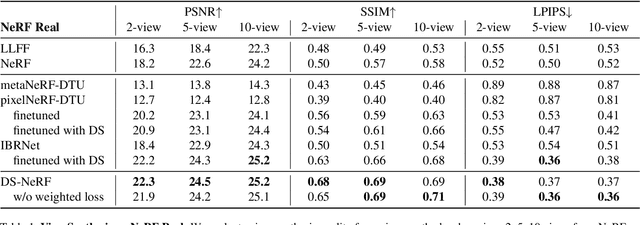
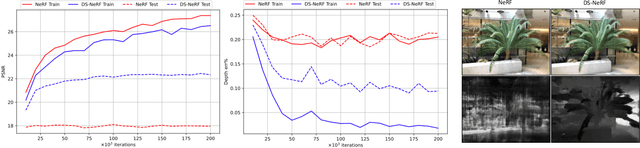
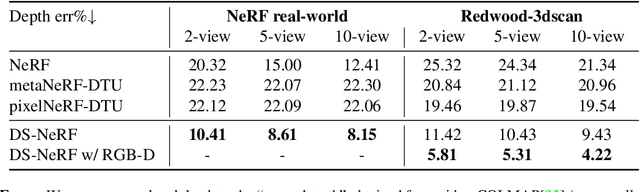
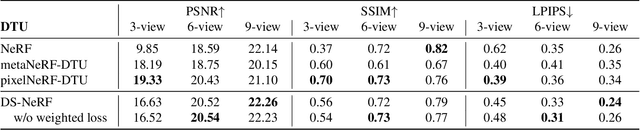
One common failure mode of Neural Radiance Field (NeRF) models is fitting incorrect geometries when given an insufficient number of input views. We propose DS-NeRF (Depth-supervised Neural Radiance Fields), a loss for learning neural radiance fields that takes advantage of readily-available depth supervision. Our key insight is that sparse depth supervision can be used to regularize the learned geometry, a crucial component for effectively rendering novel views using NeRF. We exploit the fact that current NeRF pipelines require images with known camera poses that are typically estimated by running structure-from-motion (SFM). Crucially, SFM also produces sparse 3D points that can be used as ``free" depth supervision during training: we simply add a loss to ensure that depth rendered along rays that intersect these 3D points is close to the observed depth. We find that DS-NeRF can render more accurate images given fewer training views while training 2-6x faster. With only two training views on real-world images, DS-NeRF significantly outperforms NeRF as well as other sparse-view variants. We show that our loss is compatible with these NeRF models, demonstrating that depth is a cheap and easily digestible supervisory signal. Finally, we show that DS-NeRF supports other types of depth supervision such as scanned depth sensors and RGBD reconstruction outputs.