 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Multilinguality benefit Non-autoregressive Machine Translation?
Dec 16, 2021
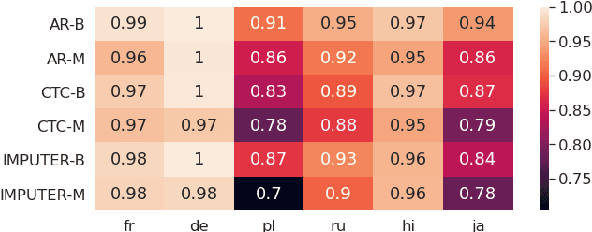
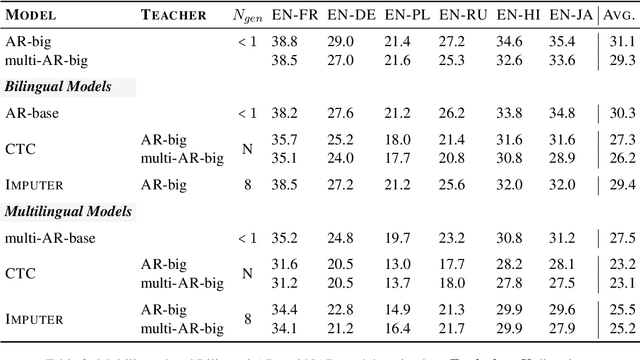
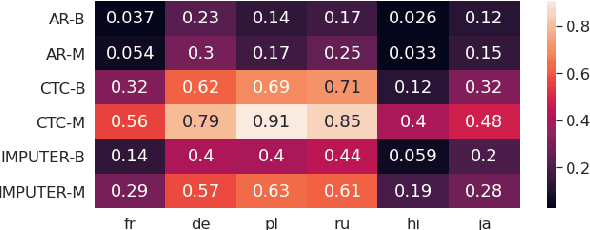
Non-autoregressive (NAR) machine translation has recently achieved significant improvements, and now outperforms autoregressive (AR) models on some benchmarks, providing an efficient alternative to AR inference. However, while AR translation is often implemented using multilingual models that benefit from transfer between languages and from improved serving efficiency, multilingual NAR models remain relatively unexplored. Taking Connectionist Temporal Classification (CTC) as an example NAR model and Imputer as a semi-NAR model, we present a comprehensive empirical study of multilingual NAR. We test its capabilities with respect to positive transfer between related languages and negative transfer under capacity constraints. As NAR models require distilled training sets, we carefully study the impact of bilingual versus multilingual teachers. Finally, we fit a scaling law for multilingual NAR, which quantifies its performance relative to the AR model as model scale increases.
Bandits Don't Follow Rules: Balancing Multi-Facet Machine Translation with Multi-Armed Bandits
Oct 13, 2021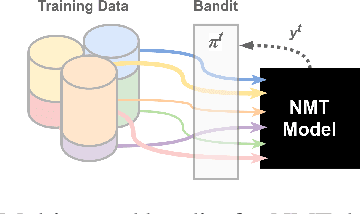
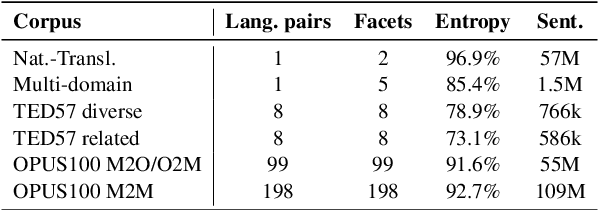
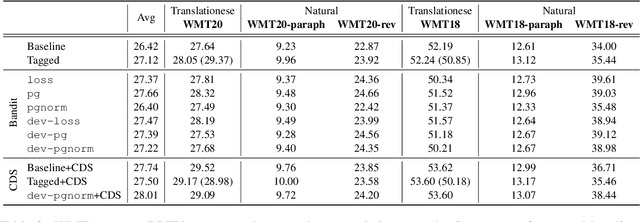
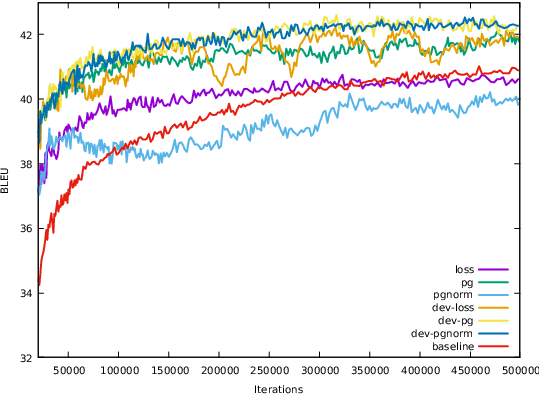
Training data for machine translation (MT) is often sourced from a multitude of large corpora that are multi-faceted in nature, e.g. containing contents from multiple domains or different levels of quality or complexity. Naturally, these facets do not occur with equal frequency, nor are they equally important for the test scenario at hand. In this work, we propose to optimize this balance jointly with MT model parameters to relieve system developers from manual schedule design. A multi-armed bandit is trained to dynamically choose between facets in a way that is most beneficial for the MT system. We evaluate it on three different multi-facet applications: balancing translationese and natural training data, or data from multiple domains or multiple language pairs. We find that bandit learning leads to competitive MT systems across tasks, and our analysis provides insights into its learned strategies and the underlying data sets.
The Low-Resource Double Bind: An Empirical Study of Pruning for Low-Resource Machine Translation
Oct 06, 2021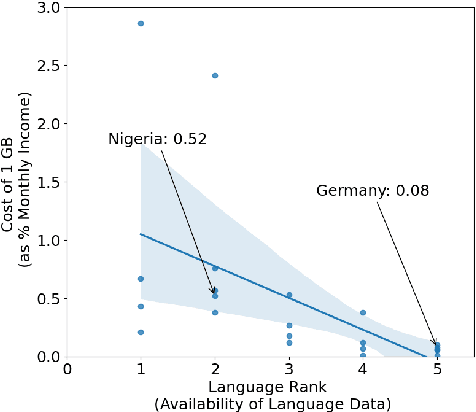
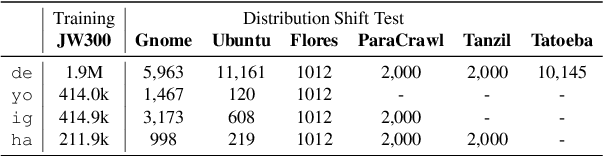
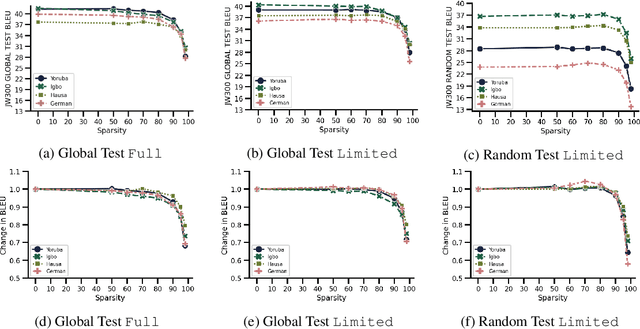

A "bigger is better" explosion in the number of parameters in deep neural networks has made it increasingly challenging to make state-of-the-art networks accessible in compute-restricted environments. Compression techniques have taken on renewed importance as a way to bridge the gap. However, evaluation of the trade-offs incurred by popular compression techniques has been centered on high-resource datasets. In this work, we instead consider the impact of compression in a data-limited regime. We introduce the term low-resource double bind to refer to the co-occurrence of data limitations and compute resource constraints. This is a common setting for NLP for low-resource languages, yet the trade-offs in performance are poorly studied. Our work offers surprising insights into the relationship between capacity and generalization in data-limited regimes for the task of machine translation. Our experiments on magnitude pruning for translations from English into Yoruba, Hausa, Igbo and German show that in low-resource regimes, sparsity preserves performance on frequent sentences but has a disparate impact on infrequent ones. However, it improves robustness to out-of-distribution shifts, especially for datasets that are very distinct from the training distribution. Our findings suggest that sparsity can play a beneficial role at curbing memorization of low frequency attributes, and therefore offers a promising solution to the low-resource double bind.
Evaluating Multiway Multilingual NMT in the Turkic Languages
Sep 13, 2021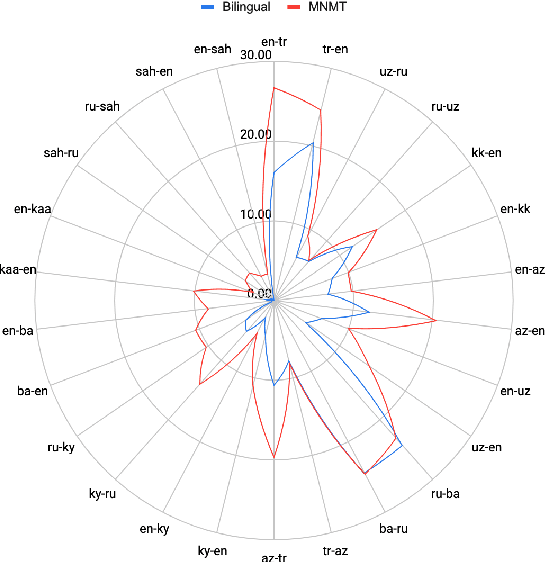
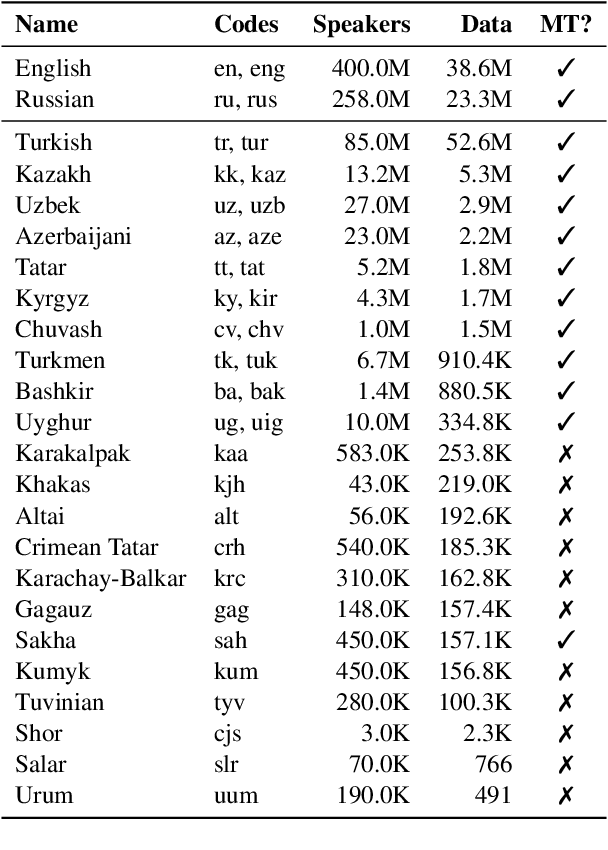

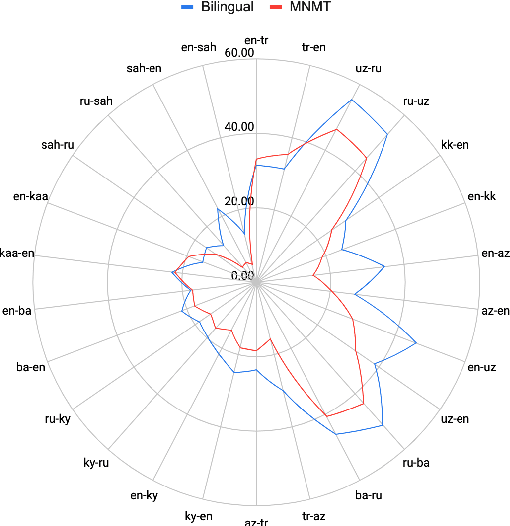
Despite the increasing number of large and comprehensive machine translation (MT) systems, evaluation of these methods in various languages has been restrained by the lack of high-quality parallel corpora as well as engagement with the people that speak these languages. In this study, we present an evaluation of state-of-the-art approaches to training and evaluating MT systems in 22 languages from the Turkic language family, most of which being extremely under-explored. First, we adopt the TIL Corpus with a few key improvements to the training and the evaluation sets. Then, we train 26 bilingual baselines as well as a multi-way neural MT (MNMT) model using the corpus and perform an extensive analysis using automatic metrics as well as human evaluations. We find that the MNMT model outperforms almost all bilingual baselines in the out-of-domain test sets and finetuning the model on a downstream task of a single pair also results in a huge performance boost in both low- and high-resource scenarios. Our attentive analysis of evaluation criteria for MT models in Turkic languages also points to the necessity for further research in this direction. We release the corpus splits, test sets as well as models to the public.
Modelling Latent Translations for Cross-Lingual Transfer
Jul 23, 2021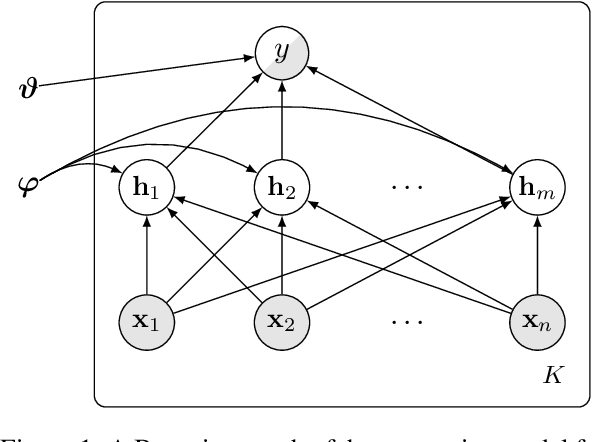
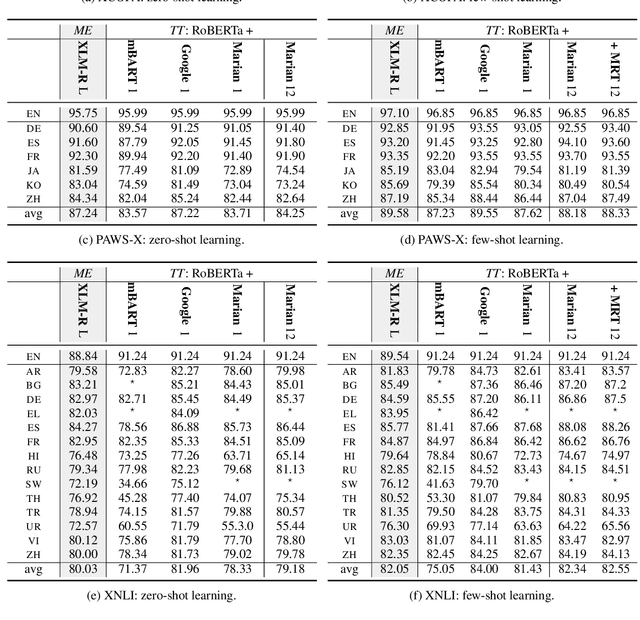
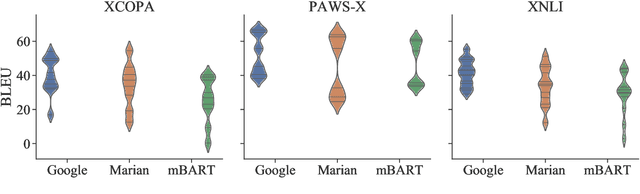

While achieving state-of-the-art results in multiple tasks and languages, translation-based cross-lingual transfer is often overlooked in favour of massively multilingual pre-trained encoders. Arguably, this is due to its main limitations: 1) translation errors percolating to the classification phase and 2) the insufficient expressiveness of the maximum-likelihood translation. To remedy this, we propose a new technique that integrates both steps of the traditional pipeline (translation and classification) into a single model, by treating the intermediate translations as a latent random variable. As a result, 1) the neural machine translation system can be fine-tuned with a variant of Minimum Risk Training where the reward is the accuracy of the downstream task classifier. Moreover, 2) multiple samples can be drawn to approximate the expected loss across all possible translations during inference. We evaluate our novel latent translation-based model on a series of multilingual NLU tasks, including commonsense reasoning, paraphrase identification, and natural language inference. We report gains for both zero-shot and few-shot learning setups, up to 2.7 accuracy points on average, which are even more prominent for low-resource languages (e.g., Haitian Creole). Finally, we carry out in-depth analyses comparing different underlying NMT models and assessing the impact of alternative translations on the downstream performance.
Revisiting the Weaknesses of Reinforcement Learning for Neural Machine Translation
Jun 16, 2021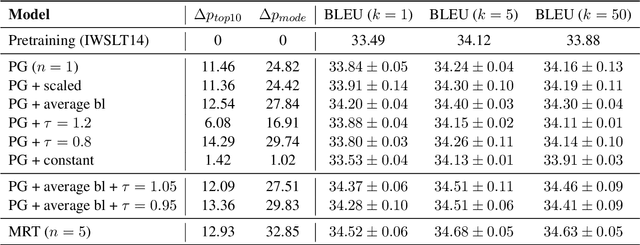
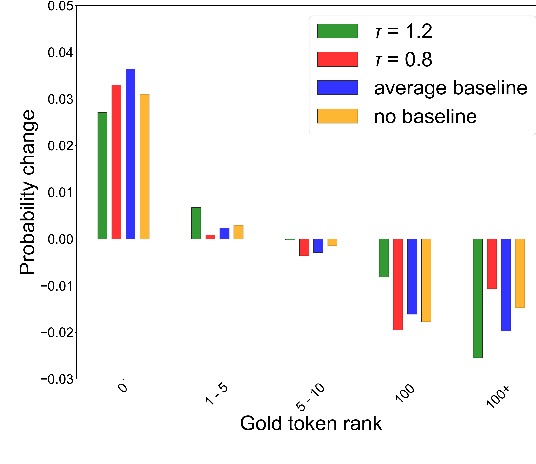
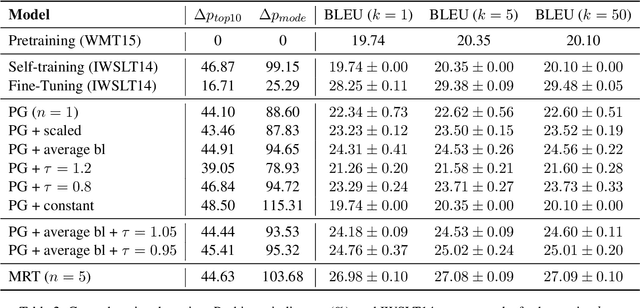
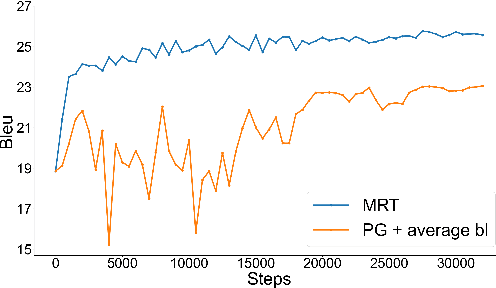
Policy gradient algorithms have found wide adoption in NLP, but have recently become subject to criticism, doubting their suitability for NMT. Choshen et al. (2020) identify multiple weaknesses and suspect that their success is determined by the shape of output distributions rather than the reward. In this paper, we revisit these claims and study them under a wider range of configurations. Our experiments on in-domain and cross-domain adaptation reveal the importance of exploration and reward scaling, and provide empirical counter-evidence to these claims.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
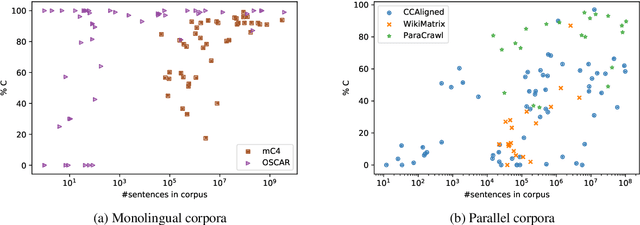

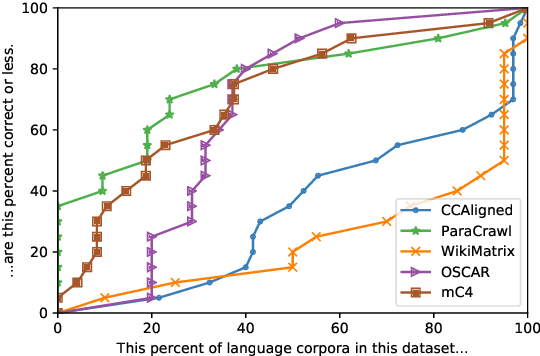
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021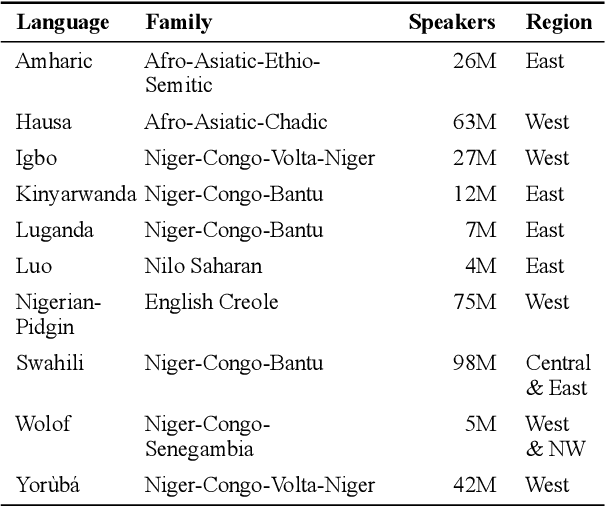

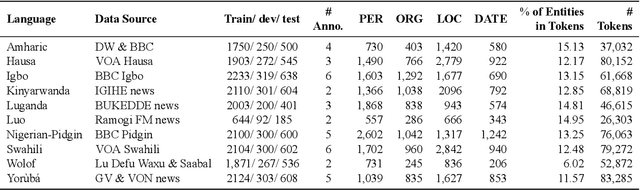
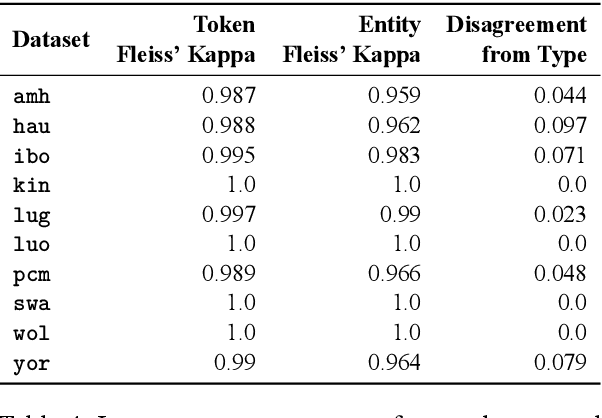
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Neural Machine Translation for Extremely Low-Resource African Languages: A Case Study on Bambara
Nov 10, 2020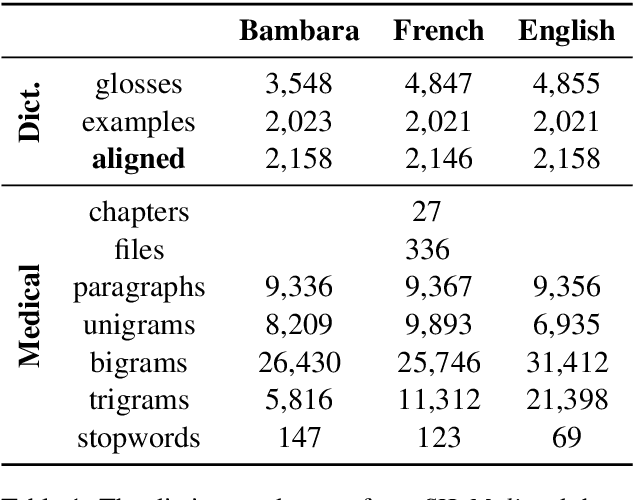
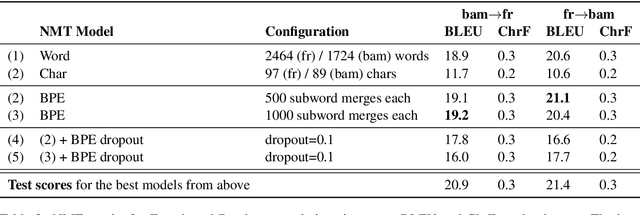
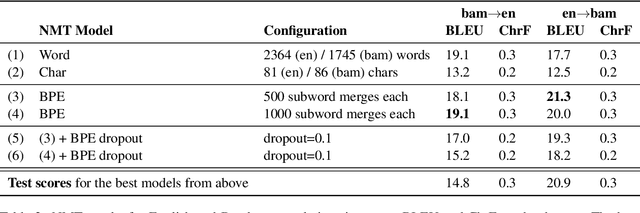
Low-resource languages present unique challenges to (neural) machine translation. We discuss the case of Bambara, a Mande language for which training data is scarce and requires significant amounts of pre-processing. More than the linguistic situation of Bambara itself, the socio-cultural context within which Bambara speakers live poses challenges for automated processing of this language. In this paper, we present the first parallel data set for machine translation of Bambara into and from English and French and the first benchmark results on machine translation to and from Bambara. We discuss challenges in working with low-resource languages and propose strategies to cope with data scarcity in low-resource machine translation (MT).
Learning from Human Feedback: Challenges for Real-World Reinforcement Learning in NLP
Nov 06, 2020Large volumes of interaction logs can be collected from NLP systems that are deployed in the real world. How can this wealth of information be leveraged? Using such interaction logs in an offline reinforcement learning (RL) setting is a promising approach. However, due to the nature of NLP tasks and the constraints of production systems, a series of challenges arise. We present a concise overview of these challenges and discuss possible solutions.