 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Need to Talk About Random Splits
May 01, 2020

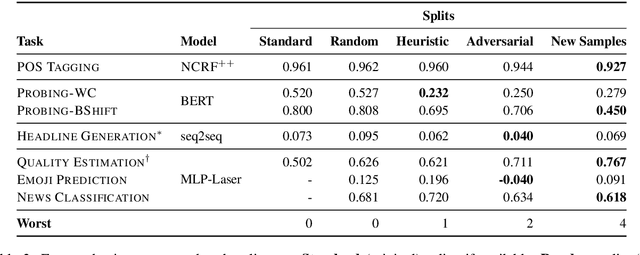
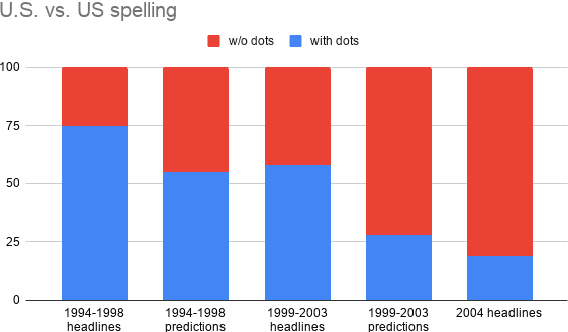
Gorman and Bedrick (2019) recently argued for using random splits rather than standard splits in NLP experiments. We argue that random splits, like standard splits, lead to overly optimistic performance estimates. In some cases, even worst-case splits under-estimate the error observed on new samples of in-domain data, i.e., the data that models should minimally generalize to at test time. This proves wrong the common conjecture that bias can be corrected for by re-weighting data (Shimodaira, 2000; Shah et al., 2020). Instead of using multiple random splits, we propose that future benchmarks instead include multiple, independent test sets.
Joey NMT: A Minimalist NMT Toolkit for Novices
Jul 29, 2019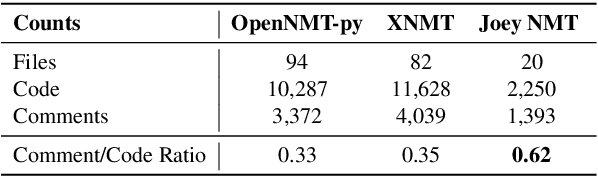
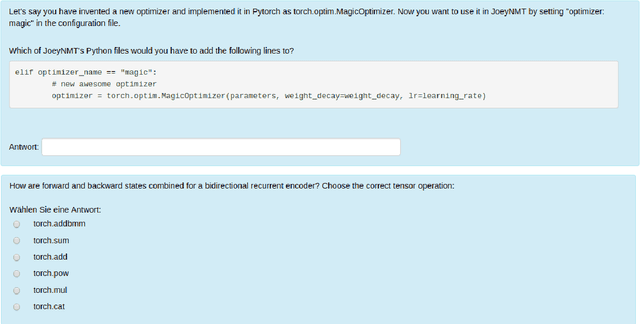
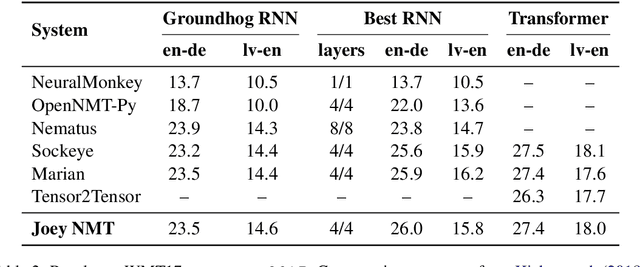
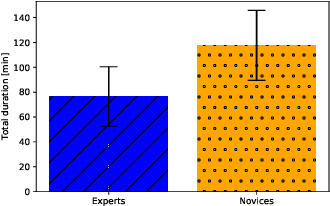
We present Joey NMT, a minimalist neural machine translation toolkit based on PyTorch that is specifically designed for novices. Joey NMT provides many popular NMT features in a small and simple code base, so that novices can easily and quickly learn to use it and adapt it to their needs. Despite its focus on simplicity, Joey NMT supports classic architectures (RNNs, transformers), fast beam search, weight tying, and more, and achieves performance comparable to more complex toolkits on standard benchmarks. We evaluate the accessibility of our toolkit in a user study where novices with general knowledge about Pytorch and NMT and experts work through a self-contained Joey NMT tutorial, showing that novices perform almost as well as experts in a subsequent code quiz. Joey NMT is available at https://github.com/joeynmt/joeynmt .
Interpretable Neural Predictions with Differentiable Binary Variables
May 20, 2019
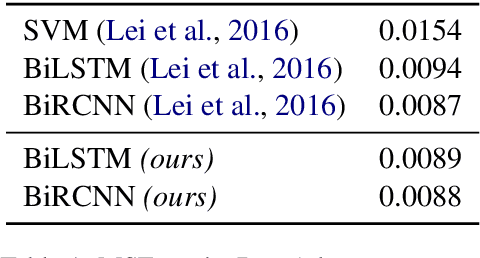
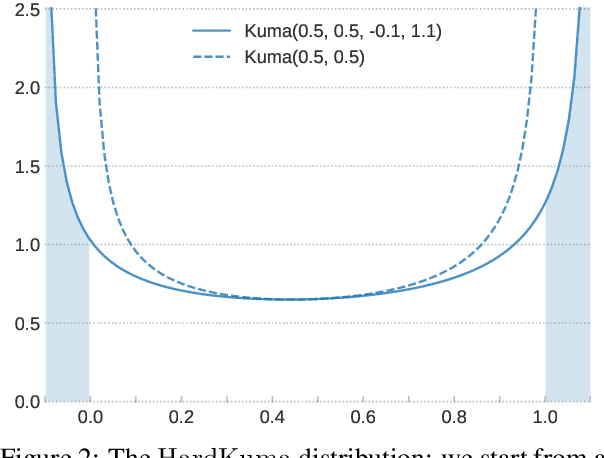
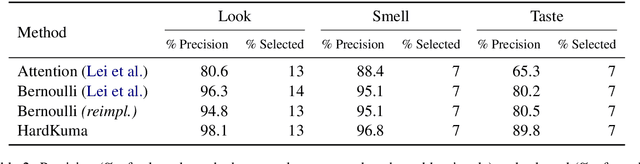
The success of neural networks comes hand in hand with a desire for more interpretability. We focus on text classifiers and make them more interpretable by having them provide a justification, a rationale, for their predictions. We approach this problem by jointly training two neural network models: a latent model that selects a rationale (i.e. a short and informative part of the input text), and a classifier that learns from the words in the rationale alone. Previous work proposed to assign binary latent masks to input positions and to promote short selections via sparsity-inducing penalties such as L0 regularisation. We propose a latent model that mixes discrete and continuous behaviour allowing at the same time for binary selections and gradient-based training without REINFORCE. In our formulation, we can tractably compute the expected value of penalties such as L0, which allows us to directly optimise the model towards a pre-specified text selection rate. We show that our approach is competitive with previous work on rationale extraction, and explore further uses in attention mechanisms.
Modeling Latent Sentence Structure in Neural Machine Translation
Jan 18, 2019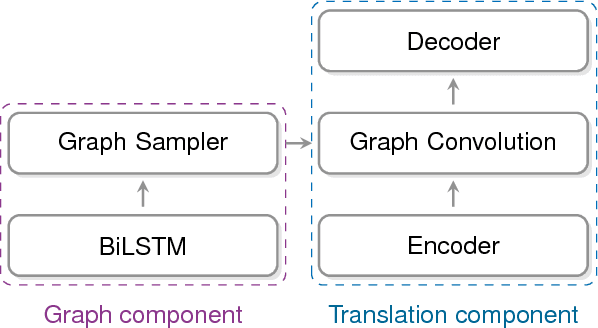
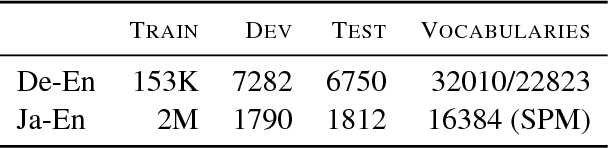
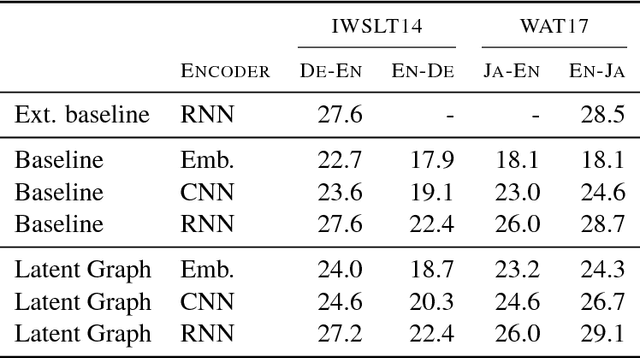
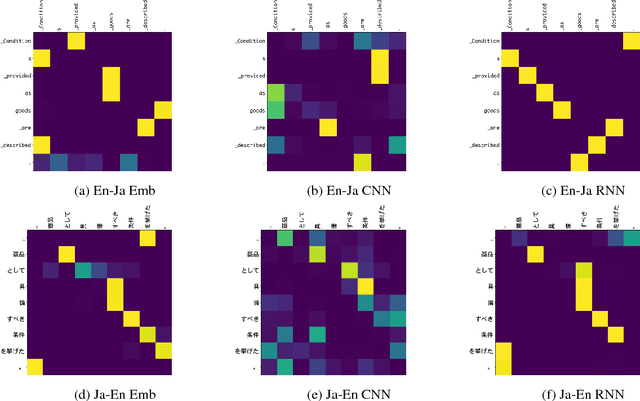
Recently it was shown that linguistic structure predicted by a supervised parser can be beneficial for neural machine translation (NMT). In this work we investigate a more challenging setup: we incorporate sentence structure as a latent variable in a standard NMT encoder-decoder and induce it in such a way as to benefit the translation task. We consider German-English and Japanese-English translation benchmarks and observe that when using RNN encoders the model makes no or very limited use of the structure induction apparatus. In contrast, CNN and word-embedding-based encoders rely on latent graphs and force them to encode useful, potentially long-distance, dependencies.
Jump to better conclusions: SCAN both left and right
Sep 12, 2018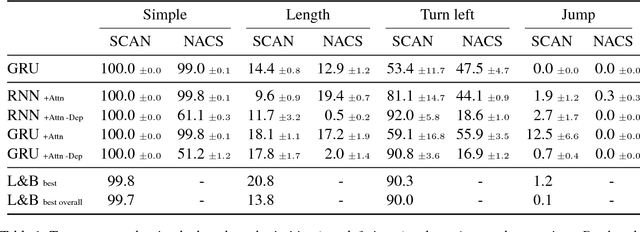
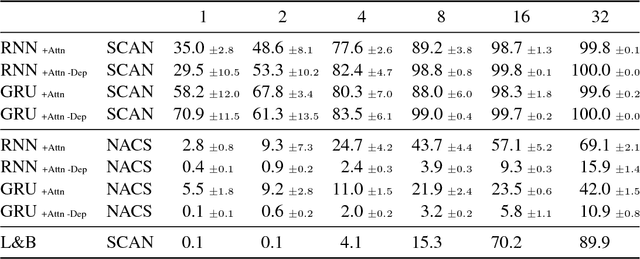

Lake and Baroni (2018) recently introduced the SCAN data set, which consists of simple commands paired with action sequences and is intended to test the strong generalization abilities of recurrent sequence-to-sequence models. Their initial experiments suggested that such models may fail because they lack the ability to extract systematic rules. Here, we take a closer look at SCAN and show that it does not always capture the kind of generalization that it was designed for. To mitigate this we propose a complementary dataset, which requires mapping actions back to the original commands, called NACS. We show that models that do well on SCAN do not necessarily do well on NACS, and that NACS exhibits properties more closely aligned with realistic use-cases for sequence-to-sequence models.
Exploiting Semantics in Neural Machine Translation with Graph Convolutional Networks
Apr 23, 2018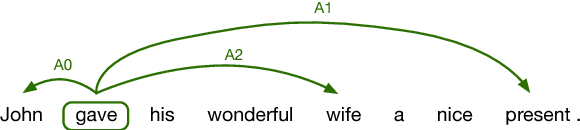

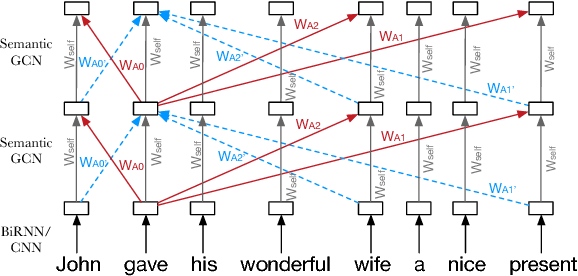

Semantic representations have long been argued as potentially useful for enforcing meaning preservation and improving generalization performance of machine translation methods. In this work, we are the first to incorporate information about predicate-argument structure of source sentences (namely, semantic-role representations) into neural machine translation. We use Graph Convolutional Networks (GCNs) to inject a semantic bias into sentence encoders and achieve improvements in BLEU scores over the linguistic-agnostic and syntax-aware versions on the English--German language pair.