 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Practice of Scaling Search Conversion Rate Prediction
May 28, 2026Scaling a Search Conversion Rate (CVR) prediction model, especially in high-traffic environments, presents a challenge: superior model quality needs to be balanced with strict constraints on training cost and serving latency. This paper details an effective approach for scaling modern search CVR prediction models. We begin with an empirical study to understand the scaling performance of search CVR models, analyzing how quality improves as we scale three key factors of model backbone computation, the size of embedding parameters, and the volume of training data. We use a large-scale production dataset, comprising over a year of customer interaction logs from a high-traffic e-commerce platform, to evaluate the scalability of several state-of-the-art architectures and their ensembles. Our key findings are: (1) selecting the right backbone and scaling factors is crucial; (2) the impact of scaling backbone, embedding, and data is largely independent and additive, which has implications for more efficient scaling exploration; (3) a streamlined warmstart strategy can accelerate training iterations while simplifying new updates; (4) inference optimization strategies such as decoupled graph execution and dynamic batching can enable low-latency GPU serving even for high-capacity models. Compared to a baseline of a pre-scaling production model, we ultimately deployed a model trained on 2.5x larger training data with 8x more inference compute while having minimal latency impact. Online A/B tests also demonstrate that our launches achieved a combined +2.6% gain in a key metric of search conversion rate.
Real-time Event Detection on Social Data Streams
Jul 25, 2019
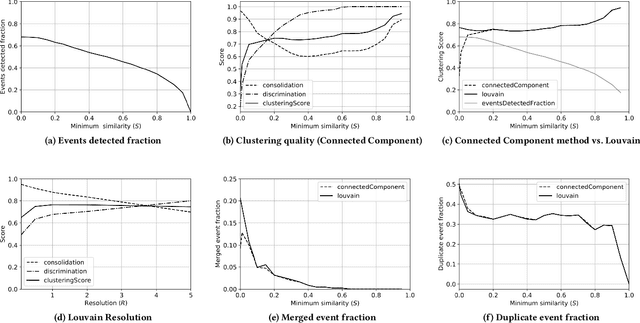

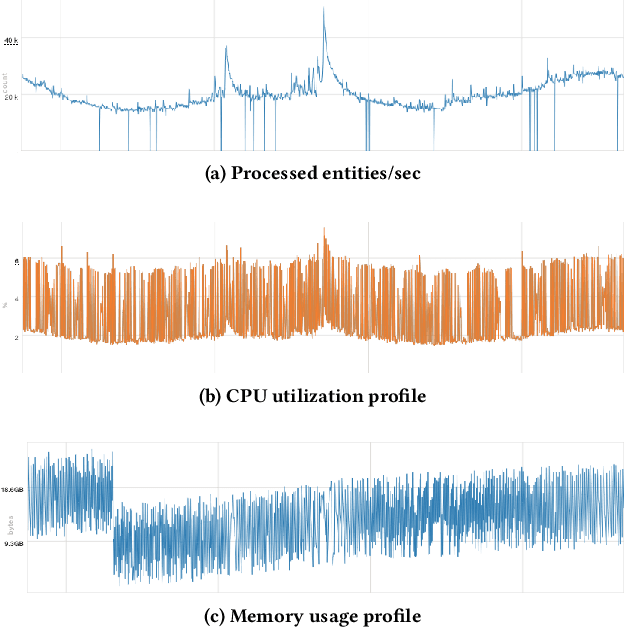
Social networks are quickly becoming the primary medium for discussing what is happening around real-world events. The information that is generated on social platforms like Twitter can produce rich data streams for immediate insights into ongoing matters and the conversations around them. To tackle the problem of event detection, we model events as a list of clusters of trending entities over time. We describe a real-time system for discovering events that is modular in design and novel in scale and speed: it applies clustering on a large stream with millions of entities per minute and produces a dynamically updated set of events. In order to assess clustering methodologies, we build an evaluation dataset derived from a snapshot of the full Twitter Firehose and propose novel metrics for measuring clustering quality. Through experiments and system profiling, we highlight key results from the offline and online pipelines. Finally, we visualize a high profile event on Twitter to show the importance of modeling the evolution of events, especially those detected from social data streams.