 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation
Apr 06, 2022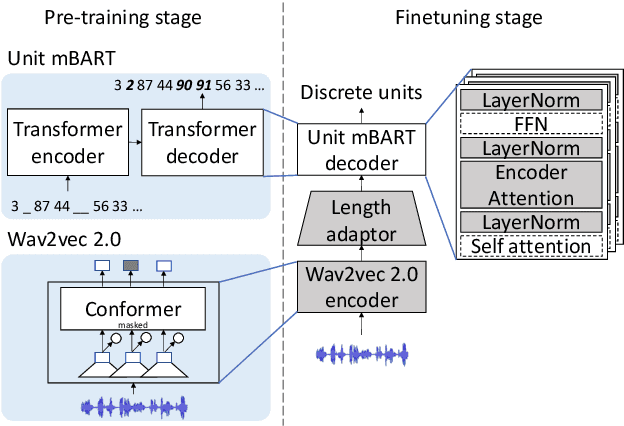
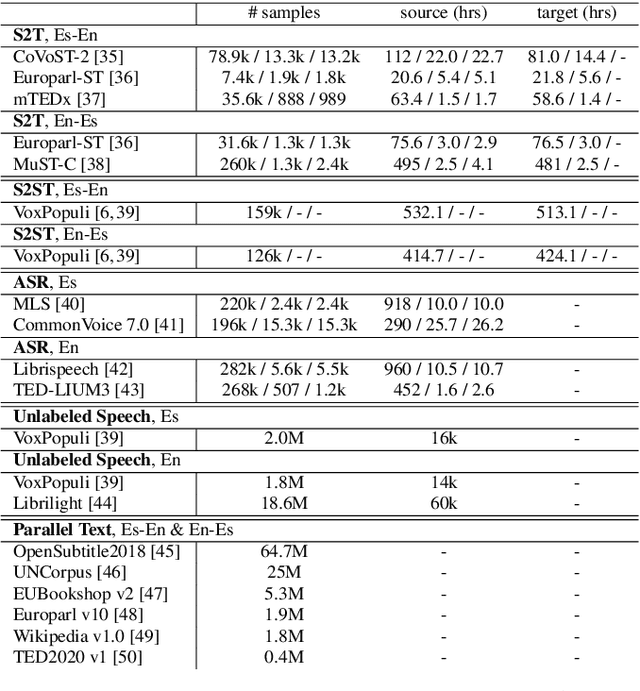
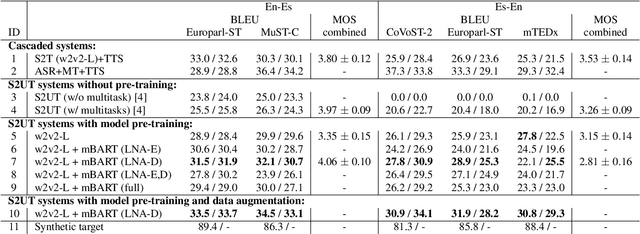

Direct speech-to-speech translation (S2ST) models suffer from data scarcity issues as there exists little parallel S2ST data, compared to the amount of data available for conventional cascaded systems that consist of automatic speech recognition (ASR), machine translation (MT), and text-to-speech (TTS) synthesis. In this work, we explore self-supervised pre-training with unlabeled speech data and data augmentation to tackle this issue. We take advantage of a recently proposed speech-to-unit translation (S2UT) framework that encodes target speech into discrete representations, and transfer pre-training and efficient partial finetuning techniques that work well for speech-to-text translation (S2T) to the S2UT domain by studying both speech encoder and discrete unit decoder pre-training. Our experiments show that self-supervised pre-training consistently improves model performance compared with multitask learning with a BLEU gain of 4.3-12.0 under various data setups, and it can be further combined with data augmentation techniques that apply MT to create weakly supervised training data. Audio samples are available at: https://facebookresearch.github.io/speech_translation/enhanced_direct_s2st_units/index.html .
Textless Speech-to-Speech Translation on Real Data
Dec 15, 2021
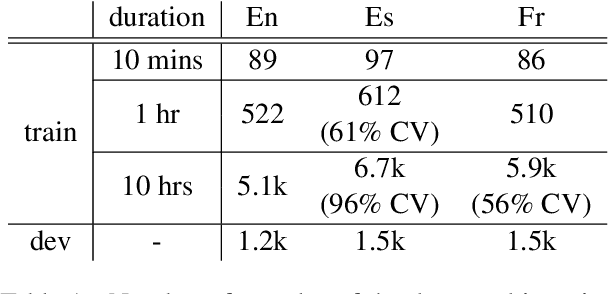
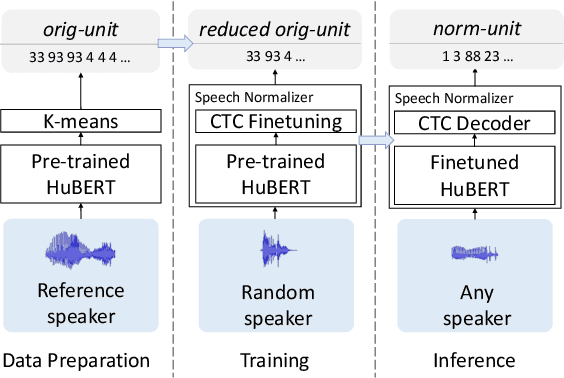
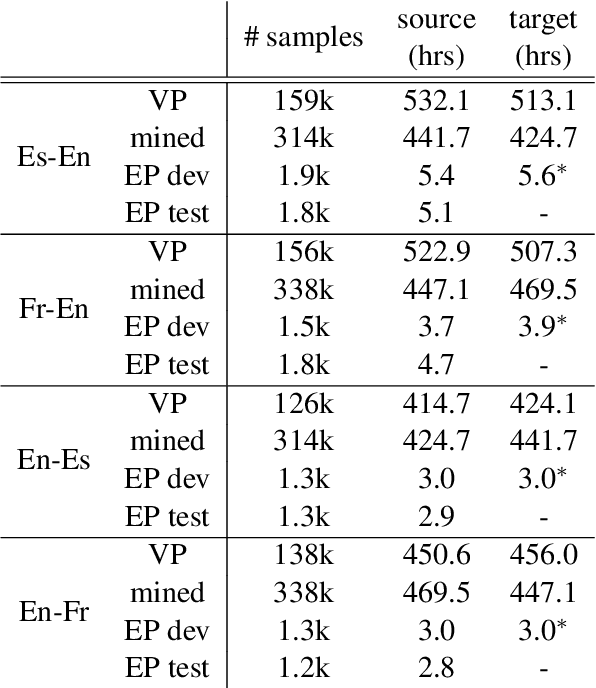
We present a textless speech-to-speech translation (S2ST) system that can translate speech from one language into another language and can be built without the need of any text data. Different from existing work in the literature, we tackle the challenge in modeling multi-speaker target speech and train the systems with real-world S2ST data. The key to our approach is a self-supervised unit-based speech normalization technique, which finetunes a pre-trained speech encoder with paired audios from multiple speakers and a single reference speaker to reduce the variations due to accents, while preserving the lexical content. With only 10 minutes of paired data for speech normalization, we obtain on average 3.2 BLEU gain when training the S2ST model on the \vp~S2ST dataset, compared to a baseline trained on un-normalized speech target. We also incorporate automatically mined S2ST data and show an additional 2.0 BLEU gain. To our knowledge, we are the first to establish a textless S2ST technique that can be trained with real-world data and works for multiple language pairs.
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
Nov 19, 2021
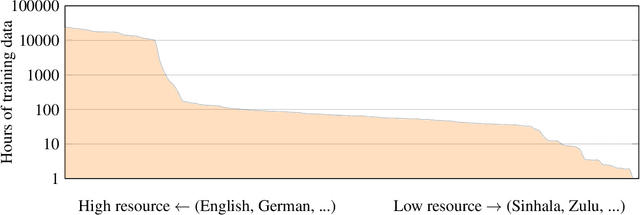

This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on nearly half a million hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 14-34% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
Direct simultaneous speech to speech translation
Oct 15, 2021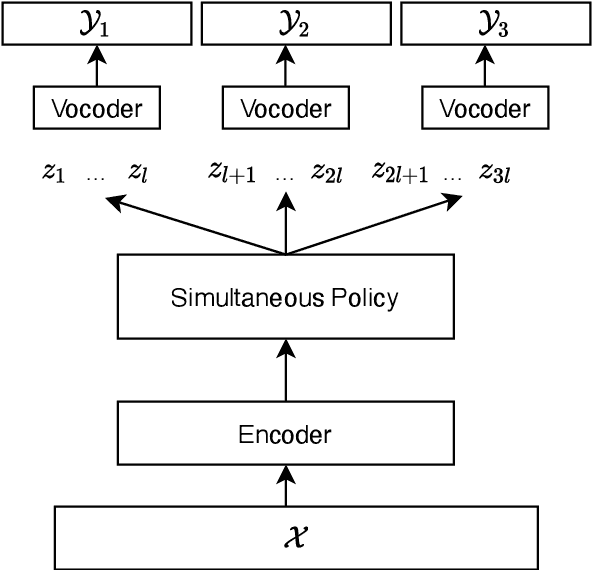
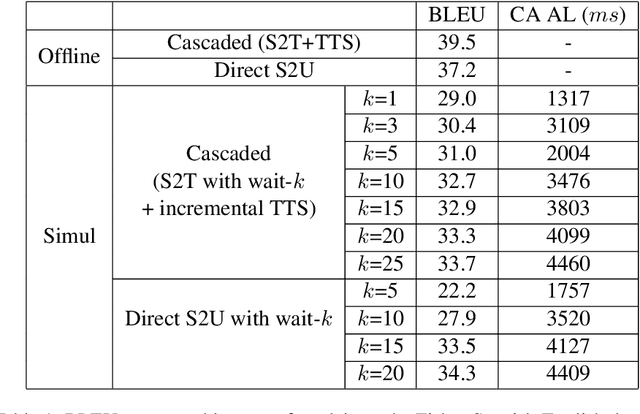
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.
Incremental Speech Synthesis For Speech-To-Speech Translation
Oct 15, 2021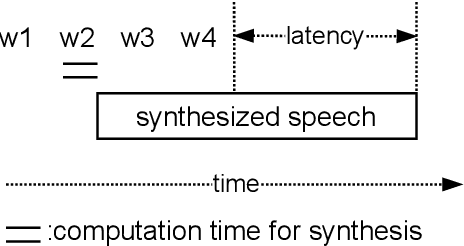
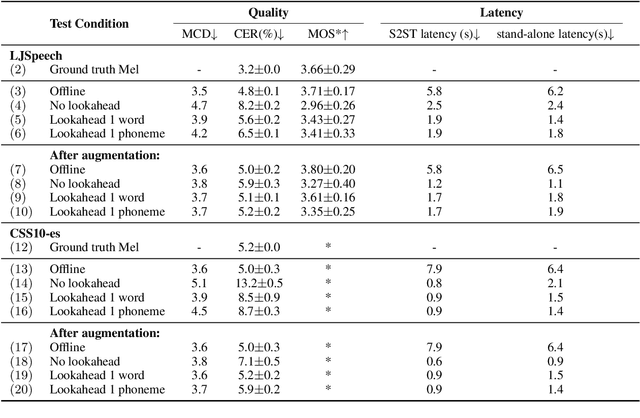

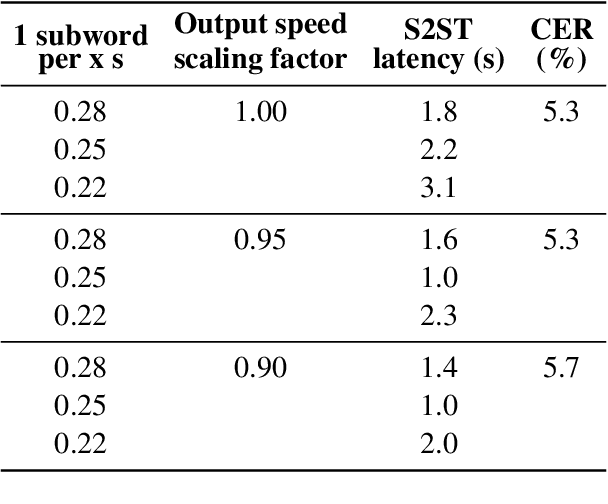
In a speech-to-speech translation (S2ST) pipeline, the text-to-speech (TTS) module is an important component for delivering the translated speech to users. To enable incremental S2ST, the TTS module must be capable of synthesizing and playing utterances while its input text is still streaming in. In this work, we focus on improving the incremental synthesis performance of TTS models. With a simple data augmentation strategy based on prefixes, we are able to improve the incremental TTS quality to approach offline performance. Furthermore, we bring our incremental TTS system to the practical scenario in combination with an upstream simultaneous speech translation system, and show the gains also carry over to this use-case. In addition, we propose latency metrics tailored to S2ST applications, and investigate methods for latency reduction in this context.
fairseq S^2: A Scalable and Integrable Speech Synthesis Toolkit
Sep 14, 2021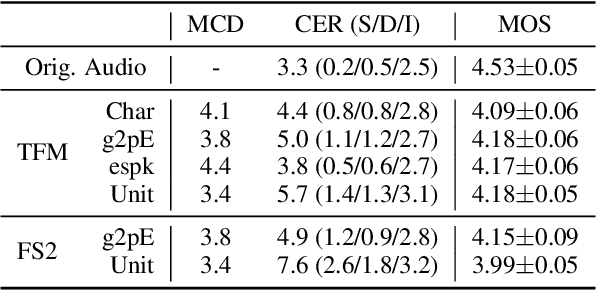
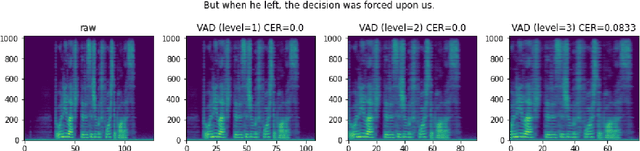

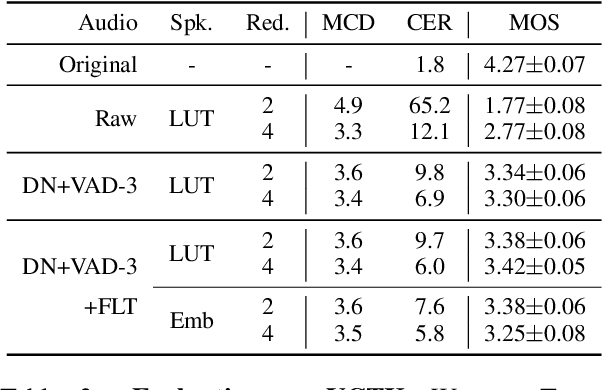
This paper presents fairseq S^2, a fairseq extension for speech synthesis. We implement a number of autoregressive (AR) and non-AR text-to-speech models, and their multi-speaker variants. To enable training speech synthesis models with less curated data, a number of preprocessing tools are built and their importance is shown empirically. To facilitate faster iteration of development and analysis, a suite of automatic metrics is included. Apart from the features added specifically for this extension, fairseq S^2 also benefits from the scalability offered by fairseq and can be easily integrated with other state-of-the-art systems provided in this framework. The code, documentation, and pre-trained models are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_synthesis.
FST: the FAIR Speech Translation System for the IWSLT21 Multilingual Shared Task
Aug 14, 2021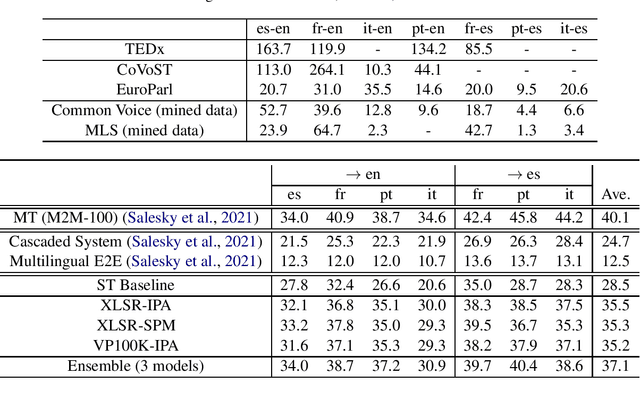
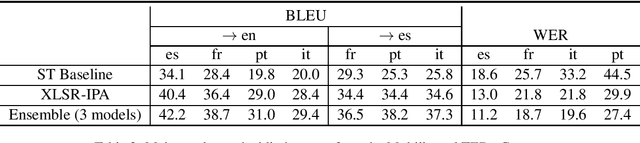
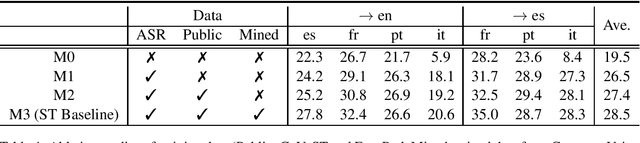
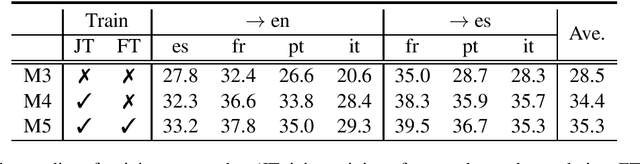
In this paper, we describe our end-to-end multilingual speech translation system submitted to the IWSLT 2021 evaluation campaign on the Multilingual Speech Translation shared task. Our system is built by leveraging transfer learning across modalities, tasks and languages. First, we leverage general-purpose multilingual modules pretrained with large amounts of unlabelled and labelled data. We further enable knowledge transfer from the text task to the speech task by training two tasks jointly. Finally, our multilingual model is finetuned on speech translation task-specific data to achieve the best translation results. Experimental results show our system outperforms the reported systems, including both end-to-end and cascaded based approaches, by a large margin. In some translation directions, our speech translation results evaluated on the public Multilingual TEDx test set are even comparable with the ones from a strong text-to-text translation system, which uses the oracle speech transcripts as input.
Improving Speech Translation by Understanding and Learning from the Auxiliary Text Translation Task
Jul 12, 2021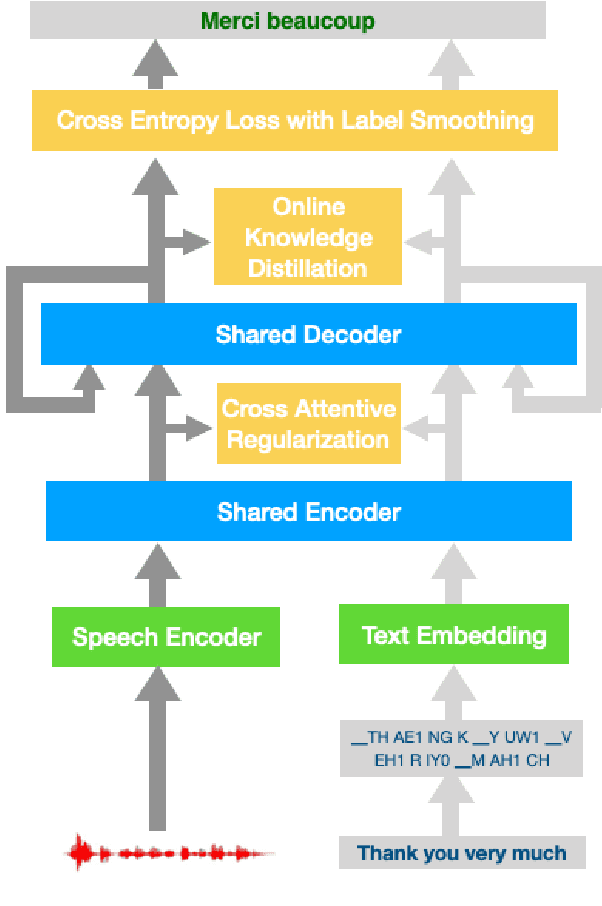
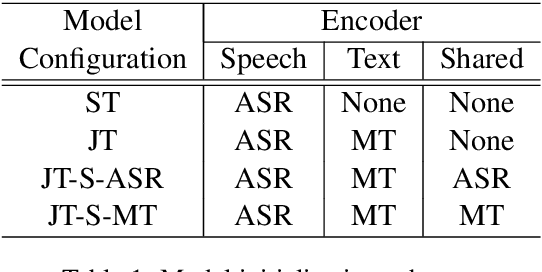
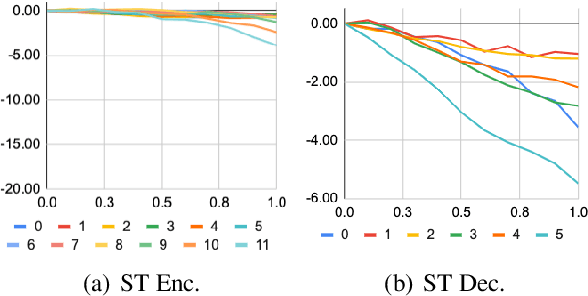
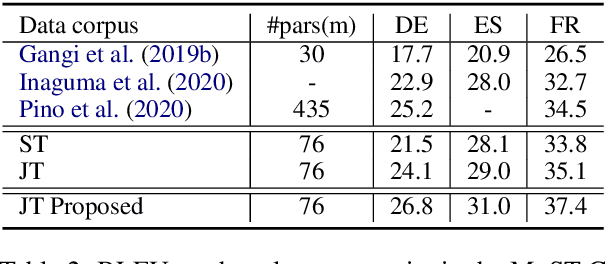
Pretraining and multitask learning are widely used to improve the speech to text translation performance. In this study, we are interested in training a speech to text translation model along with an auxiliary text to text translation task. We conduct a detailed analysis to understand the impact of the auxiliary task on the primary task within the multitask learning framework. Our analysis confirms that multitask learning tends to generate similar decoder representations from different modalities and preserve more information from the pretrained text translation modules. We observe minimal negative transfer effect between the two tasks and sharing more parameters is helpful to transfer knowledge from the text task to the speech task. The analysis also reveals that the modality representation difference at the top decoder layers is still not negligible, and those layers are critical for the translation quality. Inspired by these findings, we propose three methods to improve translation quality. First, a parameter sharing and initialization strategy is proposed to enhance information sharing between the tasks. Second, a novel attention-based regularization is proposed for the encoders and pulls the representations from different modalities closer. Third, an online knowledge distillation is proposed to enhance the knowledge transfer from the text to the speech task. Our experiments show that the proposed approach improves translation performance by more than 2 BLEU over a strong baseline and achieves state-of-the-art results on the \textsc{MuST-C} English-German, English-French and English-Spanish language pairs.
Direct speech-to-speech translation with discrete units
Jul 12, 2021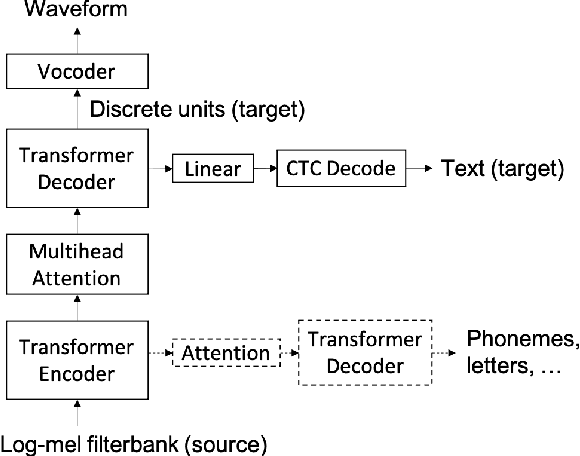
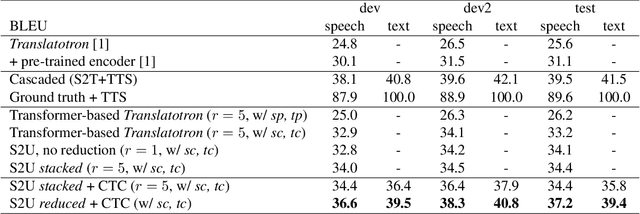
We present a direct speech-to-speech translation (S2ST) model that translates speech from one language to speech in another language without relying on intermediate text generation. Previous work addresses the problem by training an attention-based sequence-to-sequence model that maps source speech spectrograms into target spectrograms. To tackle the challenge of modeling continuous spectrogram features of the target speech, we propose to predict the self-supervised discrete representations learned from an unlabeled speech corpus instead. When target text transcripts are available, we design a multitask learning framework with joint speech and text training that enables the model to generate dual mode output (speech and text) simultaneously in the same inference pass. Experiments on the Fisher Spanish-English dataset show that predicting discrete units and joint speech and text training improve model performance by 11 BLEU compared with a baseline that predicts spectrograms and bridges 83% of the performance gap towards a cascaded system. When trained without any text transcripts, our model achieves similar performance as a baseline that predicts spectrograms and is trained with text data.
Pay Better Attention to Attention: Head Selection in Multilingual and Multi-Domain Sequence Modeling
Jun 21, 2021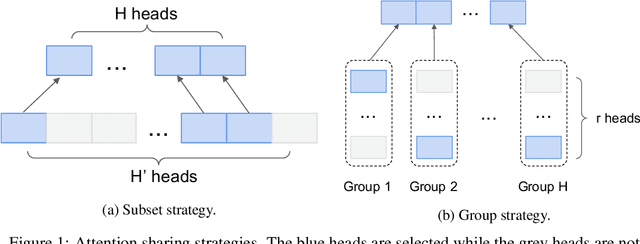
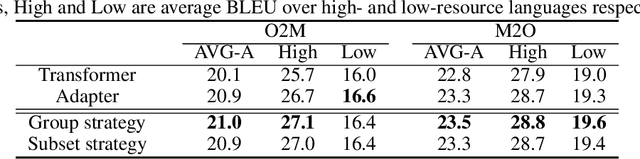

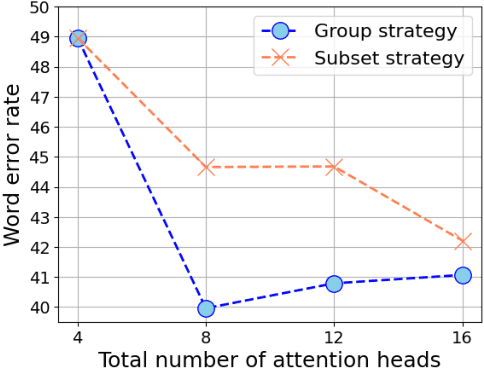
Multi-head attention has each of the attention heads collect salient information from different parts of an input sequence, making it a powerful mechanism for sequence modeling. Multilingual and multi-domain learning are common scenarios for sequence modeling, where the key challenge is to maximize positive transfer and mitigate negative transfer across languages and domains. In this paper, we find that non-selective attention sharing is sub-optimal for achieving good generalization across all languages and domains. We further propose attention sharing strategies to facilitate parameter sharing and specialization in multilingual and multi-domain sequence modeling. Our approach automatically learns shared and specialized attention heads for different languages and domains to mitigate their interference. Evaluated in various tasks including speech recognition, text-to-text and speech-to-text translation, the proposed attention sharing strategies consistently bring gains to sequence models built upon multi-head attention. For speech-to-text translation, our approach yields an average of $+2.0$ BLEU over $13$ language directions in multilingual setting and $+2.0$ BLEU over $3$ domains in multi-domain setting.