 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 7: Everyday Knowledge Across Diverse Languages and Cultures
May 04, 2026We present our shared task on evaluating the adaptability of LLMs and NLP systems across multiple languages and cultures. The task data consist of an extended version of our manually constructed BLEnD benchmark (Myung et al. 2024), covering more than 30 language-culture pairs, predominantly representing low-resource languages spoken across multiple continents. As the task is designed strictly for evaluation, participants were not permitted to use the data for training, fine-tuning, few-shot learning, or any other form of model modification. Our task includes two tracks: (a) Short-Answer Questions (SAQ) and (b) Multiple-Choice Questions (MCQ). Participants were required to predict labels and were allowed to submit any NLP system and adopt diverse modelling strategies, provided that the benchmark was used solely for evaluation. The task attracted more than 140 registered participants, and we received final submissions from 62 teams, along with 19 system description papers. We report the results and present an analysis of the best-performing systems and the most commonly adopted approaches. Furthermore, we discuss shared insights into open questions and challenges related to evaluation, misalignment, and methodological perspectives on model behaviour in low-resource languages and for under-represented cultures.
Why are all LLMs Obsessed with Japanese Culture? On the Hidden Cultural and Regional Biases of LLMs
Apr 23, 2026LLMs have been showing limitations when it comes to cultural coverage and competence, and in some cases show regional biases such as amplifying Western and Anglocentric viewpoints. While there have been works analysing the cultural capabilities of LLMs, there has not been specific work on highlighting LLM regional preferences when it comes to cultural-related questions. In this work, we propose a new dataset based on a comprehensive taxonomy of Culture-Related Open Questions (CROQ). The results show that, contrary to previous cultural bias work, LLMs show a clear tendency towards countries such as Japan. Moveover, our results show that when prompting in languages such as English or other high-resource ones, LLMs tend to provide more diverse outputs and show less inclinations towards answering questions highlighting countries for which the input language is an official language. Finally, we also investigate at which point of LLM training this cultural bias emerges, with our results suggesting that the first clear signs appear after supervised fine-tuning, and not during pre-training.
Instructing Large Language Models for Low-Resource Languages: A Systematic Study for Basque
Jun 09, 2025



Instructing language models with user intent requires large instruction datasets, which are only available for a limited set of languages. In this paper, we explore alternatives to conventional instruction adaptation pipelines in low-resource scenarios. We assume a realistic scenario for low-resource languages, where only the following are available: corpora in the target language, existing open-weight multilingual base and instructed backbone LLMs, and synthetically generated instructions sampled from the instructed backbone. We present a comprehensive set of experiments for Basque that systematically study different combinations of these components evaluated on benchmarks and human preferences from 1,680 participants. Our conclusions show that target language corpora are essential, with synthetic instructions yielding robust models, and, most importantly, that using as backbone an instruction-tuned model outperforms using a base non-instructed model, and improved results when scaling up. Using Llama 3.1 instruct 70B as backbone our model comes near frontier models of much larger sizes for Basque, without using any Basque data apart from the 1.2B word corpora. We release code, models, instruction datasets, and human preferences to support full reproducibility in future research on low-resource language adaptation.
Political Leaning Inference through Plurinational Scenarios
Jun 12, 2024



Social media users express their political preferences via interaction with other users, by spontaneous declarations or by participation in communities within the network. This makes a social network such as Twitter a valuable data source to study computational science approaches to political learning inference. In this work we focus on three diverse regions in Spain (Basque Country, Catalonia and Galicia) to explore various methods for multi-party categorization, required to analyze evolving and complex political landscapes, and compare it with binary left-right approaches. We use a two-step method involving unsupervised user representations obtained from the retweets and their subsequent use for political leaning detection. Comprehensive experimentation on a newly collected and curated dataset comprising labeled users and their interactions demonstrate the effectiveness of using Relational Embeddings as representation method for political ideology detection in both binary and multi-party frameworks, even with limited training data. Finally, data visualization illustrates the ability of the Relational Embeddings to capture intricate intra-group and inter-group political affinities.
Relational Embeddings for Language Independent Stance Detection
Oct 11, 2022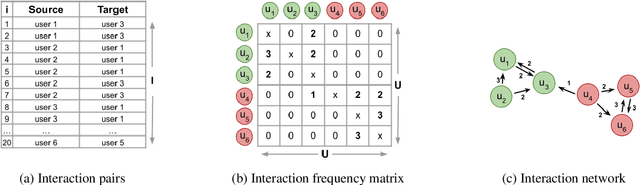
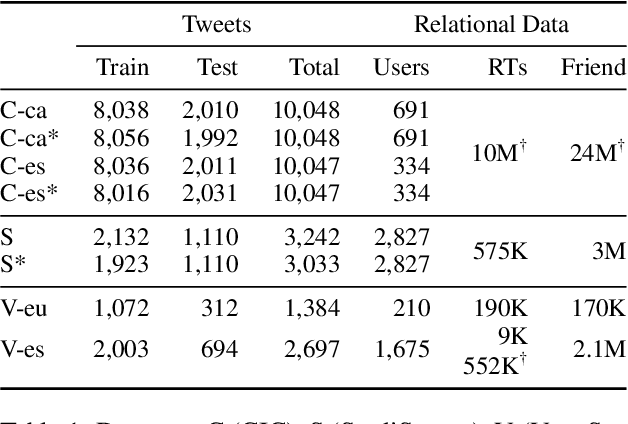
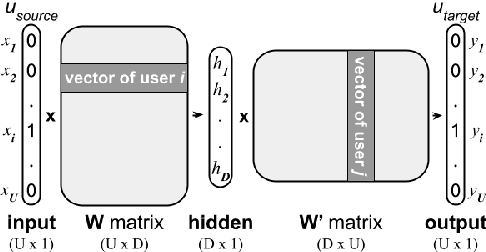
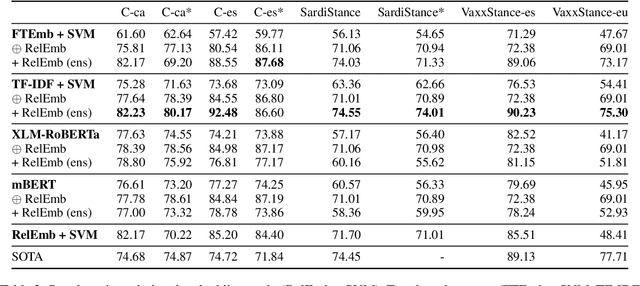
The large majority of the research performed on stance detection has been focused on developing more or less sophisticated text classification systems, even when many benchmarks are based on social network data such as Twitter. This paper aims to take on the stance detection task by placing the emphasis not so much on the text itself but on the interaction data available on social networks. More specifically, we propose a new method to leverage social information such as friends and retweets by generating relational embeddings, namely, dense vector representations of interaction pairs. Our method can be applied to any language and target without any manual tuning. Our experiments on seven publicly available datasets and four different languages show that combining our relational embeddings with textual methods helps to substantially improve performance, obtaining best results for six out of seven evaluation settings, outperforming strong baselines based on large pre-trained language models.