 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation, Found in Embeddings: Sign Language Translation and Alignment
Dec 08, 2025


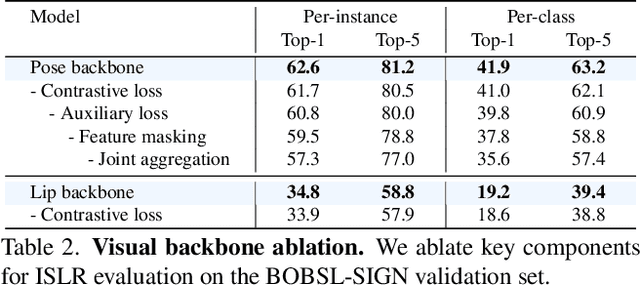
Our aim is to develop a unified model for sign language understanding, that performs sign language translation (SLT) and sign-subtitle alignment (SSA). Together, these two tasks enable the conversion of continuous signing videos into spoken language text and also the temporal alignment of signing with subtitles -- both essential for practical communication, large-scale corpus construction, and educational applications. To achieve this, our approach is built upon three components: (i) a lightweight visual backbone that captures manual and non-manual cues from human keypoints and lip-region images while preserving signer privacy; (ii) a Sliding Perceiver mapping network that aggregates consecutive visual features into word-level embeddings to bridge the vision-text gap; and (iii) a multi-task scalable training strategy that jointly optimises SLT and SSA, reinforcing both linguistic and temporal alignment. To promote cross-linguistic generalisation, we pretrain our model on large-scale sign-text corpora covering British Sign Language (BSL) and American Sign Language (ASL) from the BOBSL and YouTube-SL-25 datasets. With this multilingual pretraining and strong model design, we achieve state-of-the-art results on the challenging BOBSL (BSL) dataset for both SLT and SSA. Our model also demonstrates robust zero-shot generalisation and finetuned SLT performance on How2Sign (ASL), highlighting the potential of scalable translation across different sign languages.
Dub-S2ST: Textless Speech-to-Speech Translation for Seamless Dubbing
May 27, 2025



This paper introduces a cross-lingual dubbing system that translates speech from one language to another while preserving key characteristics such as duration, speaker identity, and speaking speed. Despite the strong translation quality of existing speech translation approaches, they often overlook the transfer of speech patterns, leading to mismatches with source speech and limiting their suitability for dubbing applications. To address this, we propose a discrete diffusion-based speech-to-unit translation model with explicit duration control, enabling time-aligned translation. We then synthesize speech based on the predicted units and source identity with a conditional flow matching model. Additionally, we introduce a unit-based speed adaptation mechanism that guides the translation model to produce speech at a rate consistent with the source, without relying on any text. Extensive experiments demonstrate that our framework generates natural and fluent translations that align with the original speech's duration and speaking pace, while achieving competitive translation performance.
AVCD: Mitigating Hallucinations in Audio-Visual Large Language Models through Contrastive Decoding
May 27, 2025Hallucination remains a major challenge in multimodal large language models (MLLMs). To address this, various contrastive decoding (CD) methods have been proposed that contrasts original logits with hallucinated logits generated from perturbed inputs. While CD has shown promise in vision-language models (VLMs), it is not well-suited for AV-LLMs, where hallucinations often emerge from both unimodal and cross-modal combinations involving audio, video, and language. These intricate interactions call for a more adaptive and modality-aware decoding strategy. In this paper, we propose Audio-Visual Contrastive Decoding (AVCD)-a novel, training-free decoding framework designed to model trimodal interactions and suppress modality-induced hallucinations in AV-LLMs. Unlike previous CD methods in VLMs that corrupt a fixed modality, AVCD leverages attention distributions to dynamically identify less dominant modalities and applies attentive masking to generate perturbed output logits. To support CD in a trimodal setting, we also reformulate the original CD framework to jointly handle audio, visual, and textual inputs. Finally, to improve efficiency, we introduce entropy-guided adaptive decoding, which selectively skips unnecessary decoding steps based on the model's confidence in its predictions. Extensive experiments demonstrate that AVCD consistently outperforms existing decoding methods. Especially, on the AVHBench dataset, it improves accuracy by 6% for VideoLLaMA2 and 11% for video-SALMONN, demonstrating strong robustness and generalizability.
Fork-Merge Decoding: Enhancing Multimodal Understanding in Audio-Visual Large Language Models
May 27, 2025The goal of this work is to enhance balanced multimodal understanding in audio-visual large language models (AV-LLMs) by addressing modality bias without requiring additional training. In current AV-LLMs, audio and video features are typically processed jointly in the decoder. While this strategy facilitates unified multimodal understanding, it may introduce modality bias, where the model tends to over-rely on one modality due to imbalanced training signals. To mitigate this, we propose Fork-Merge Decoding (FMD), a simple yet effective inference-time strategy that requires no additional training or architectural modifications. FMD first performs modality-specific reasoning by processing audio-only and video-only inputs through the early decoder layers (a fork phase), and then merges the resulting hidden states for joint reasoning in the remaining layers (a merge phase). This approach promotes balanced modality contributions and leverages complementary information across modalities. We evaluate our method on two representative AV-LLMs, VideoLLaMA2 and video-SALMONN, using three benchmark datasets. Experimental results demonstrate consistent performance improvements on tasks focused on audio, video, and combined audio-visual reasoning, demonstrating the effectiveness of inference-time interventions for robust multimodal understanding.
Accelerating Diffusion-based Text-to-Speech Model Training with Dual Modality Alignment
May 26, 2025The goal of this paper is to optimize the training process of diffusion-based text-to-speech models. While recent studies have achieved remarkable advancements, their training demands substantial time and computational costs, largely due to the implicit guidance of diffusion models in learning complex intermediate representations. To address this, we propose A-DMA, an effective strategy for Accelerating training with Dual Modality Alignment. Our method introduces a novel alignment pipeline leveraging both text and speech modalities: text-guided alignment, which incorporates contextual representations, and speech-guided alignment, which refines semantic representations. By aligning hidden states with discriminative features, our training scheme reduces the reliance on diffusion models for learning complex representations. Extensive experiments demonstrate that A-DMA doubles the convergence speed while achieving superior performance over baselines. Code and demo samples are available at: https://github.com/ZhikangNiu/A-DMA
SEED: Speaker Embedding Enhancement Diffusion Model
May 22, 2025A primary challenge when deploying speaker recognition systems in real-world applications is performance degradation caused by environmental mismatch. We propose a diffusion-based method that takes speaker embeddings extracted from a pre-trained speaker recognition model and generates refined embeddings. For training, our approach progressively adds Gaussian noise to both clean and noisy speaker embeddings extracted from clean and noisy speech, respectively, via forward process of a diffusion model, and then reconstructs them to clean embeddings in the reverse process. While inferencing, all embeddings are regenerated via diffusion process. Our method needs neither speaker label nor any modification to the existing speaker recognition pipeline. Experiments on evaluation sets simulating environment mismatch scenarios show that our method can improve recognition accuracy by up to 19.6% over baseline models while retaining performance on conventional scenarios. We publish our code here https://github.com/kaistmm/seed-pytorch
Test-Time Augmentation for Pose-invariant Face Recognition
May 14, 2025The goal of this paper is to enhance face recognition performance by augmenting head poses during the testing phase. Existing methods often rely on training on frontalised images or learning pose-invariant representations, yet both approaches typically require re-training and testing for each dataset, involving a substantial amount of effort. In contrast, this study proposes Pose-TTA, a novel approach that aligns faces at inference time without additional training. To achieve this, we employ a portrait animator that transfers the source image identity into the pose of a driving image. Instead of frontalising a side-profile face -- which can introduce distortion -- Pose-TTA generates matching side-profile images for comparison, thereby reducing identity information loss. Furthermore, we propose a weighted feature aggregation strategy to address any distortions or biases arising from the synthetic data, thus enhancing the reliability of the augmented images. Extensive experiments on diverse datasets and with various pre-trained face recognition models demonstrate that Pose-TTA consistently improves inference performance. Moreover, our method is straightforward to integrate into existing face recognition pipelines, as it requires no retraining or fine-tuning of the underlying recognition models.
Hearing and Seeing Through CLIP: A Framework for Self-Supervised Sound Source Localization
May 08, 2025



Large-scale vision-language models demonstrate strong multimodal alignment and generalization across diverse tasks. Among them, CLIP stands out as one of the most successful approaches. In this work, we extend the application of CLIP to sound source localization, proposing a self-supervised method operates without explicit text input. We introduce a framework that maps audios into tokens compatible with CLIP's text encoder, producing audio-driven embeddings. These embeddings are used to generate sounding region masks, from which visual features are extracted and aligned with the audio embeddings through a contrastive audio-visual correspondence objective. Our findings show that alignment knowledge of pre-trained multimodal foundation model enables our method to generate more complete and compact localization for sounding objects. We further propose an LLM-guided extension that distills object-aware audio-visual scene understanding into the model during training to enhance alignment. Extensive experiments across five diverse tasks demonstrate that our method, in all variants, outperforms state-of-the-art approaches and achieves strong generalization in zero-shot settings.
AlignDiT: Multimodal Aligned Diffusion Transformer for Synchronized Speech Generation
Apr 29, 2025In this paper, we address the task of multimodal-to-speech generation, which aims to synthesize high-quality speech from multiple input modalities: text, video, and reference audio. This task has gained increasing attention due to its wide range of applications, such as film production, dubbing, and virtual avatars. Despite recent progress, existing methods still suffer from limitations in speech intelligibility, audio-video synchronization, speech naturalness, and voice similarity to the reference speaker. To address these challenges, we propose AlignDiT, a multimodal Aligned Diffusion Transformer that generates accurate, synchronized, and natural-sounding speech from aligned multimodal inputs. Built upon the in-context learning capability of the DiT architecture, AlignDiT explores three effective strategies to align multimodal representations. Furthermore, we introduce a novel multimodal classifier-free guidance mechanism that allows the model to adaptively balance information from each modality during speech synthesis. Extensive experiments demonstrate that AlignDiT significantly outperforms existing methods across multiple benchmarks in terms of quality, synchronization, and speaker similarity. Moreover, AlignDiT exhibits strong generalization capability across various multimodal tasks, such as video-to-speech synthesis and visual forced alignment, consistently achieving state-of-the-art performance. The demo page is available at https://mm.kaist.ac.kr/projects/AlignDiT .
VoiceCraft-Dub: Automated Video Dubbing with Neural Codec Language Models
Apr 03, 2025We present VoiceCraft-Dub, a novel approach for automated video dubbing that synthesizes high-quality speech from text and facial cues. This task has broad applications in filmmaking, multimedia creation, and assisting voice-impaired individuals. Building on the success of Neural Codec Language Models (NCLMs) for speech synthesis, our method extends their capabilities by incorporating video features, ensuring that synthesized speech is time-synchronized and expressively aligned with facial movements while preserving natural prosody. To inject visual cues, we design adapters to align facial features with the NCLM token space and introduce audio-visual fusion layers to merge audio-visual information within the NCLM framework. Additionally, we curate CelebV-Dub, a new dataset of expressive, real-world videos specifically designed for automated video dubbing. Extensive experiments show that our model achieves high-quality, intelligible, and natural speech synthesis with accurate lip synchronization, outperforming existing methods in human perception and performing favorably in objective evaluations. We also adapt VoiceCraft-Dub for the video-to-speech task, demonstrating its versatility for various applications.