 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Initializations for Optimizing Coordinate-Based Neural Representations
Dec 03, 2020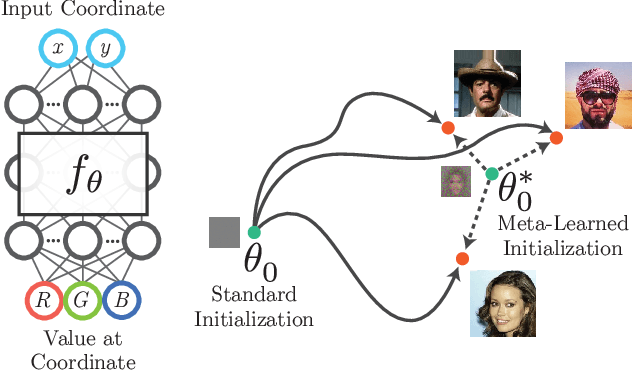


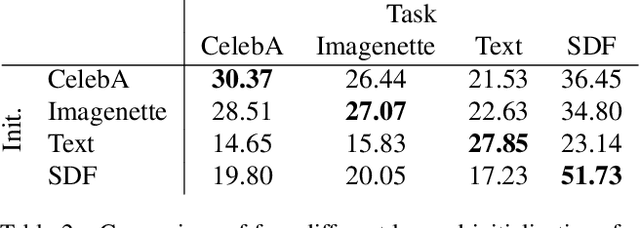
Coordinate-based neural representations have shown significant promise as an alternative to discrete, array-based representations for complex low dimensional signals. However, optimizing a coordinate-based network from randomly initialized weights for each new signal is inefficient. We propose applying standard meta-learning algorithms to learn the initial weight parameters for these fully-connected networks based on the underlying class of signals being represented (e.g., images of faces or 3D models of chairs). Despite requiring only a minor change in implementation, using these learned initial weights enables faster convergence during optimization and can serve as a strong prior over the signal class being modeled, resulting in better generalization when only partial observations of a given signal are available. We explore these benefits across a variety of tasks, including representing 2D images, reconstructing CT scans, and recovering 3D shapes and scenes from 2D image observations.
Single-Image Lens Flare Removal
Nov 26, 2020
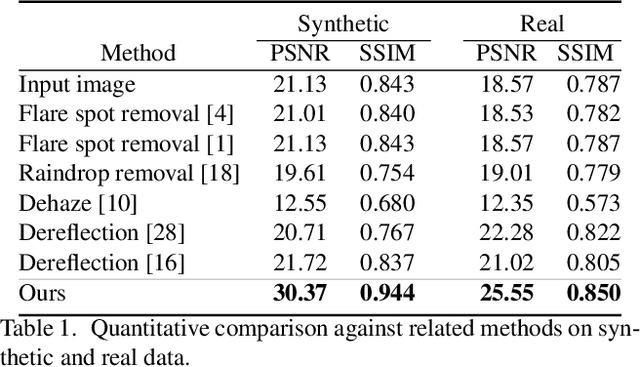
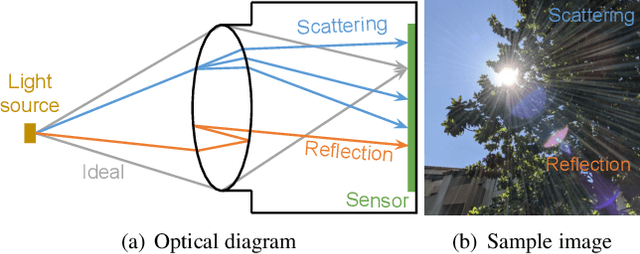
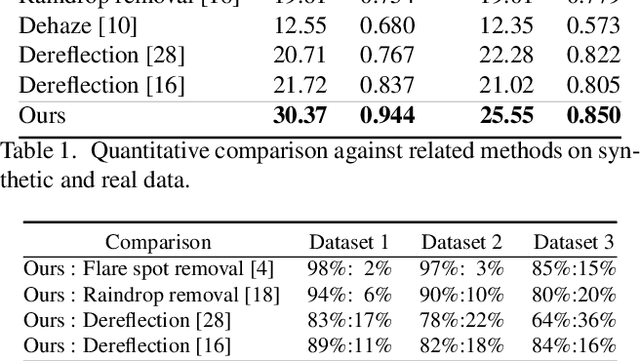
Lens flare is a common artifact in photographs occurring when the camera is pointed at a strong light source. It is caused by either multiple reflections within the lens or scattering due to scratches or dust on the lens, and may appear in a wide variety of patterns: halos, streaks, color bleeding, haze, etc. The diversity in its appearance makes flare removal extremely challenging. Existing software methods make strong assumptions about the artifacts' geometry or brightness, and thus only handle a small subset of flares. We take a principled approach to explicitly model the optical causes of flare, which leads to a novel semi-synthetic pipeline for generating flare-corrupted images from both empirical and wave-optics-simulated lens flares. Using the semi-synthetic data generated by this pipeline, we build a neural network to remove lens flare. Experiments show that our model generalizes well to real lens flares captured by different devices, and outperforms start-of-the-art methods by 3dB in PSNR.
Deformable Neural Radiance Fields
Nov 26, 2020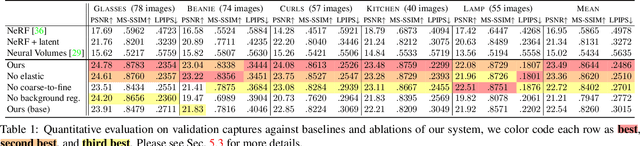


We present the first method capable of photorealistically reconstructing a non-rigidly deforming scene using photos/videos captured casually from mobile phones. Our approach -- D-NeRF -- augments neural radiance fields (NeRF) by optimizing an additional continuous volumetric deformation field that warps each observed point into a canonical 5D NeRF. We observe that these NeRF-like deformation fields are prone to local minima, and propose a coarse-to-fine optimization method for coordinate-based models that allows for more robust optimization. By adapting principles from geometry processing and physical simulation to NeRF-like models, we propose an elastic regularization of the deformation field that further improves robustness. We show that D-NeRF can turn casually captured selfie photos/videos into deformable NeRF models that allow for photorealistic renderings of the subject from arbitrary viewpoints, which we dub "nerfies." We evaluate our method by collecting data using a rig with two mobile phones that take time-synchronized photos, yielding train/validation images of the same pose at different viewpoints. We show that our method faithfully reconstructs non-rigidly deforming scenes and reproduces unseen views with high fidelity.
Cross-Camera Convolutional Color Constancy
Nov 24, 2020
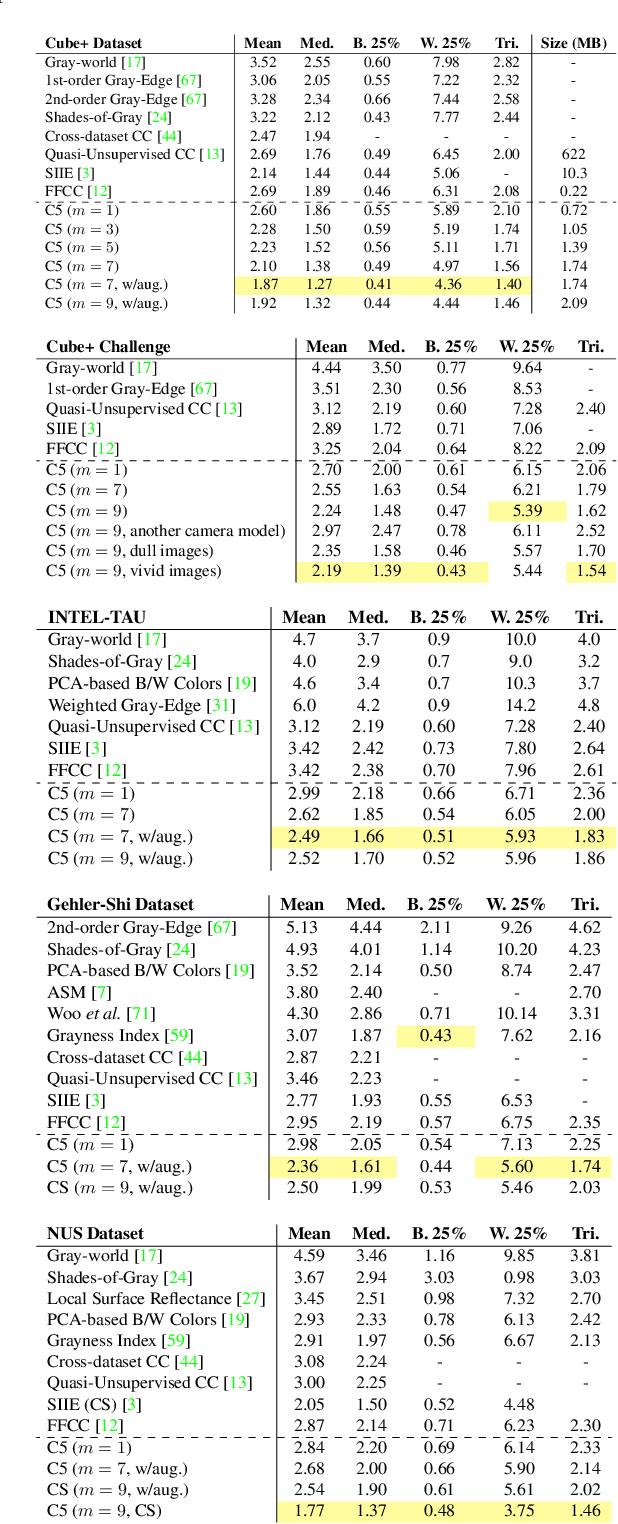
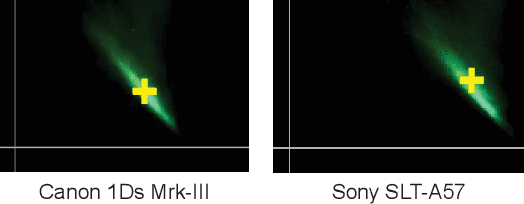
We present "Cross-Camera Convolutional Color Constancy" (C5), a learning-based method, trained on images from multiple cameras, that accurately estimates a scene's illuminant color from raw images captured by a new camera previously unseen during training. C5 is a hypernetwork-like extension of the convolutional color constancy (CCC) approach: C5 learns to generate the weights of a CCC model that is then evaluated on the input image, with the CCC weights dynamically adapted to different input content. Unlike prior cross-camera color constancy models, which are usually designed to be agnostic to the spectral properties of test-set images from unobserved cameras, C5 approaches this problem through the lens of transductive inference: additional unlabeled images are provided as input to the model at test time, which allows the model to calibrate itself to the spectral properties of the test-set camera during inference. C5 achieves state-of-the-art accuracy for cross-camera color constancy on several datasets, is fast to evaluate (~7 and ~90 ms per image on a GPU or CPU, respectively), and requires little memory (~2 MB), and, thus, is a practical solution to the problem of calibration-free automatic white balance for mobile photography.
Light Stage Super-Resolution: Continuous High-Frequency Relighting
Oct 17, 2020
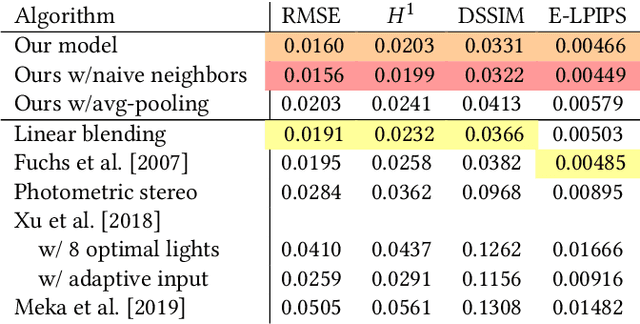
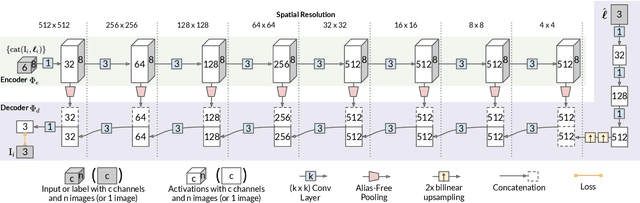
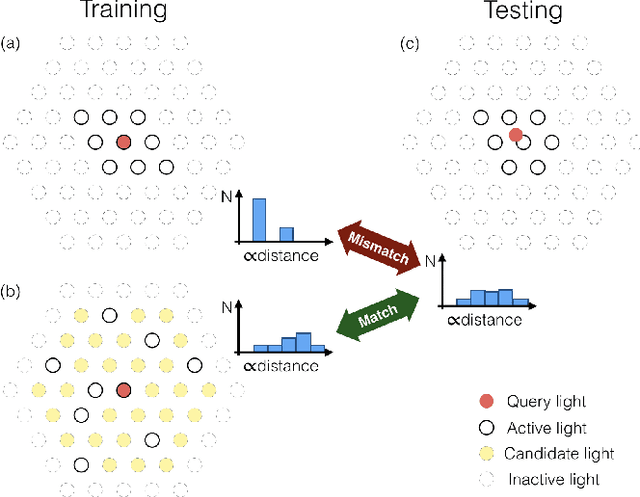
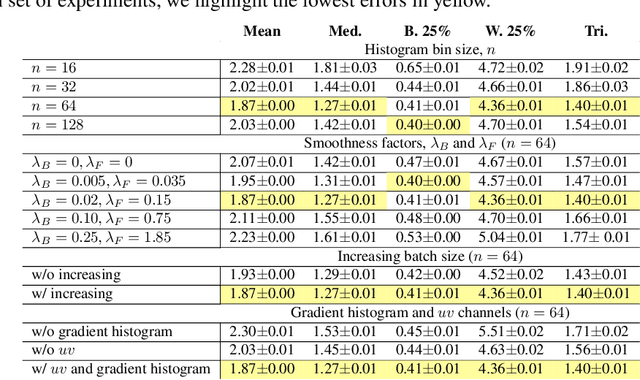
The light stage has been widely used in computer graphics for the past two decades, primarily to enable the relighting of human faces. By capturing the appearance of the human subject under different light sources, one obtains the light transport matrix of that subject, which enables image-based relighting in novel environments. However, due to the finite number of lights in the stage, the light transport matrix only represents a sparse sampling on the entire sphere. As a consequence, relighting the subject with a point light or a directional source that does not coincide exactly with one of the lights in the stage requires interpolation and resampling the images corresponding to nearby lights, and this leads to ghosting shadows, aliased specularities, and other artifacts. To ameliorate these artifacts and produce better results under arbitrary high-frequency lighting, this paper proposes a learning-based solution for the "super-resolution" of scans of human faces taken from a light stage. Given an arbitrary "query" light direction, our method aggregates the captured images corresponding to neighboring lights in the stage, and uses a neural network to synthesize a rendering of the face that appears to be illuminated by a "virtual" light source at the query location. This neural network must circumvent the inherent aliasing and regularity of the light stage data that was used for training, which we accomplish through the use of regularized traditional interpolation methods within our network. Our learned model is able to produce renderings for arbitrary light directions that exhibit realistic shadows and specular highlights, and is able to generalize across a wide variety of subjects.
A Convenient Generalization of Schlick's Bias and Gain Functions
Oct 17, 2020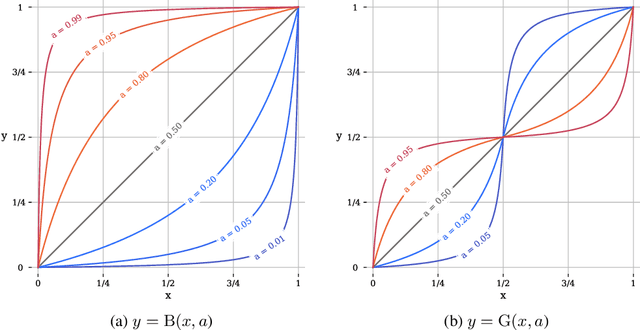
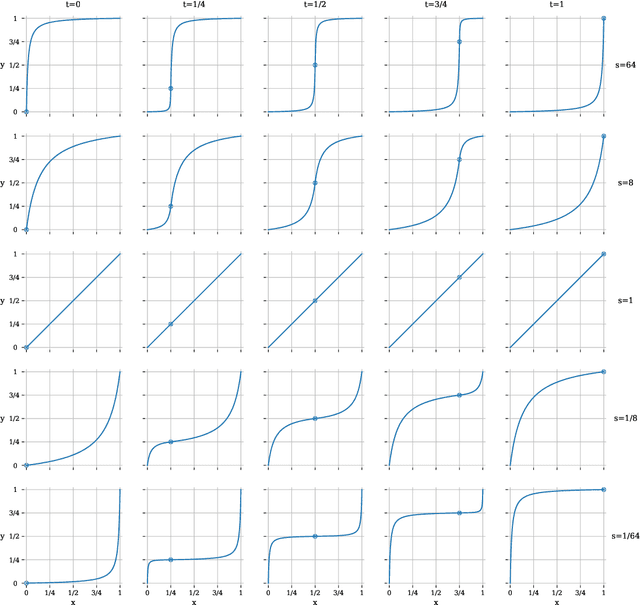
We present a generalization of Schlick's bias and gain functions -- simple parametric curve-shaped functions for inputs in [0, 1]. Our single function includes both bias and gain as special cases, and is able to describe other smooth and monotonic curves with variable degrees of asymmetry.
Shape, Illumination, and Reflectance from Shading
Oct 07, 2020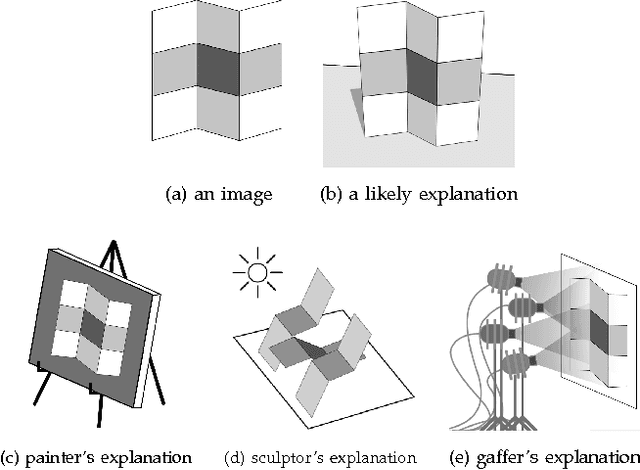
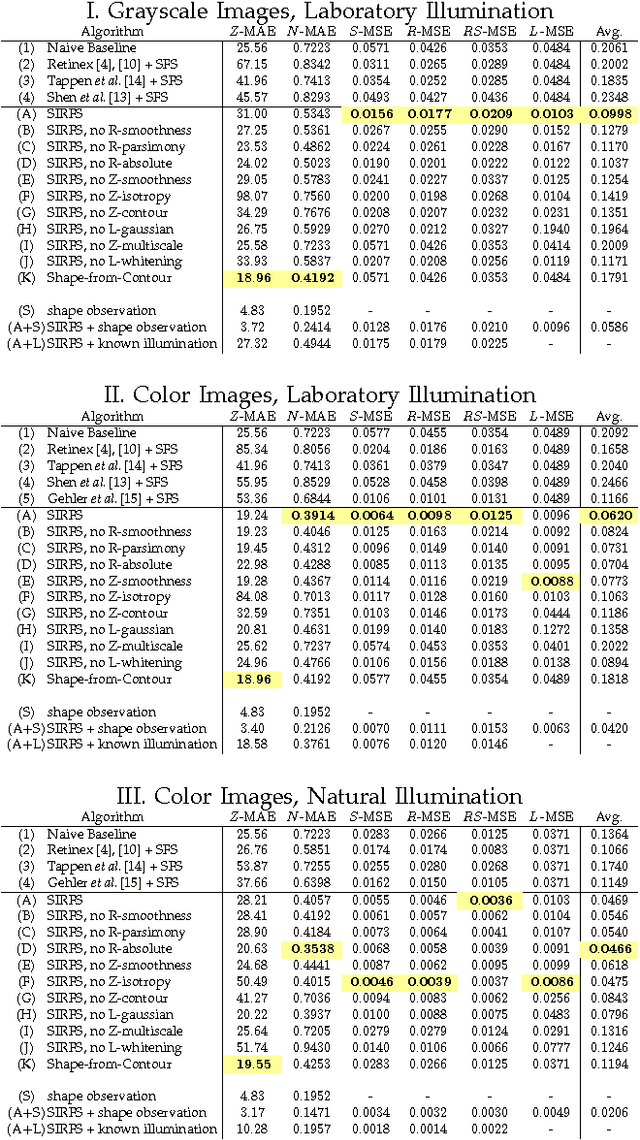
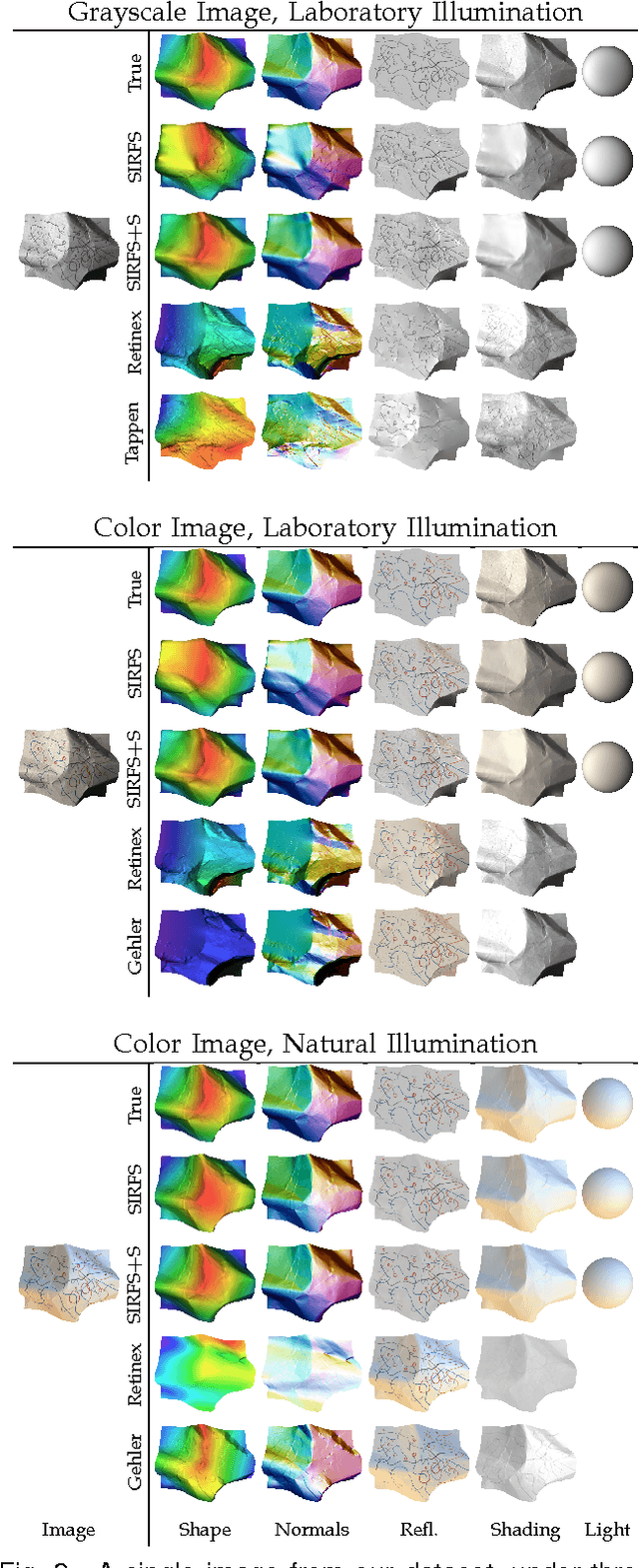
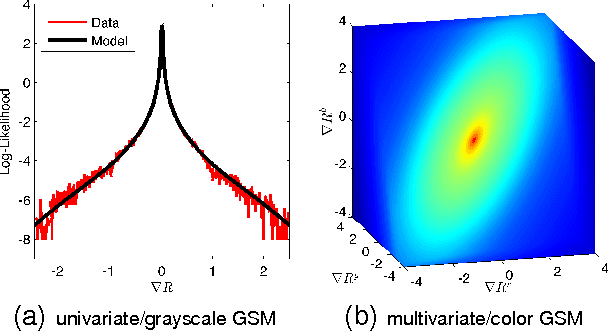
A fundamental problem in computer vision is that of inferring the intrinsic, 3D structure of the world from flat, 2D images of that world. Traditional methods for recovering scene properties such as shape, reflectance, or illumination rely on multiple observations of the same scene to overconstrain the problem. Recovering these same properties from a single image seems almost impossible in comparison -- there are an infinite number of shapes, paint, and lights that exactly reproduce a single image. However, certain explanations are more likely than others: surfaces tend to be smooth, paint tends to be uniform, and illumination tends to be natural. We therefore pose this problem as one of statistical inference, and define an optimization problem that searches for the *most likely* explanation of a single image. Our technique can be viewed as a superset of several classic computer vision problems (shape-from-shading, intrinsic images, color constancy, illumination estimation, etc) and outperforms all previous solutions to those constituent problems.
Learned Dual-View Reflection Removal
Oct 01, 2020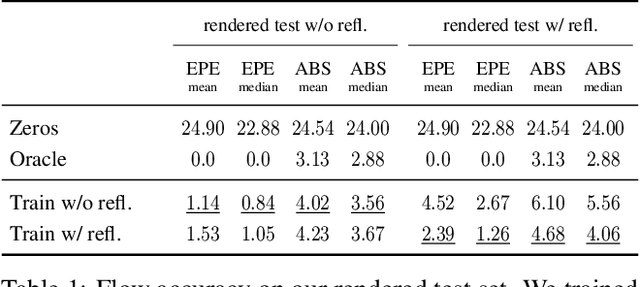


Traditional reflection removal algorithms either use a single image as input, which suffers from intrinsic ambiguities, or use multiple images from a moving camera, which is inconvenient for users. We instead propose a learning-based dereflection algorithm that uses stereo images as input. This is an effective trade-off between the two extremes: the parallax between two views provides cues to remove reflections, and two views are easy to capture due to the adoption of stereo cameras in smartphones. Our model consists of a learning-based reflection-invariant flow model for dual-view registration, and a learned synthesis model for combining aligned image pairs. Because no dataset for dual-view reflection removal exists, we render a synthetic dataset of dual-views with and without reflections for use in training. Our evaluation on an additional real-world dataset of stereo pairs shows that our algorithm outperforms existing single-image and multi-image dereflection approaches.
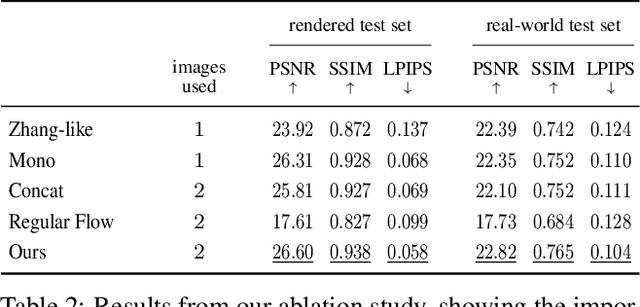
Neural Light Transport for Relighting and View Synthesis
Aug 20, 2020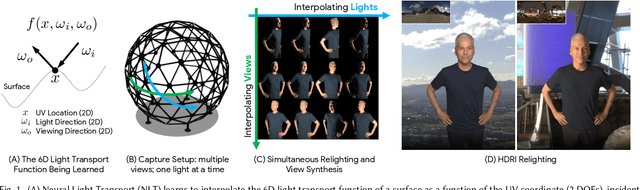
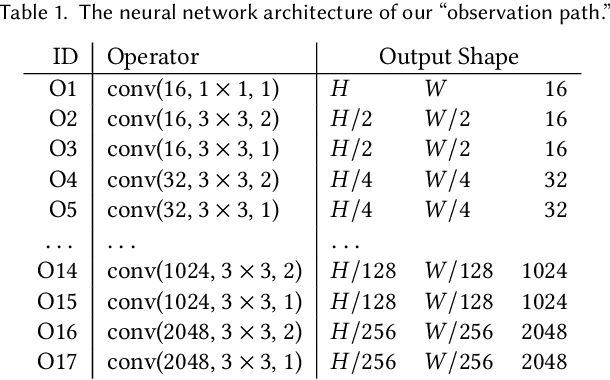

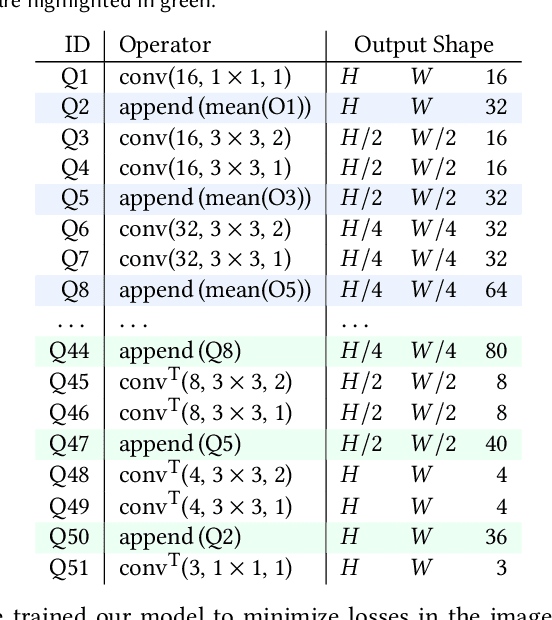
The light transport (LT) of a scene describes how it appears under different lighting and viewing directions, and complete knowledge of a scene's LT enables the synthesis of novel views under arbitrary lighting. In this paper, we focus on image-based LT acquisition, primarily for human bodies within a light stage setup. We propose a semi-parametric approach to learn a neural representation of LT that is embedded in the space of a texture atlas of known geometric properties, and model all non-diffuse and global LT as residuals added to a physically-accurate diffuse base rendering. In particular, we show how to fuse previously seen observations of illuminants and views to synthesize a new image of the same scene under a desired lighting condition from a chosen viewpoint. This strategy allows the network to learn complex material effects (such as subsurface scattering) and global illumination, while guaranteeing the physical correctness of the diffuse LT (such as hard shadows). With this learned LT, one can relight the scene photorealistically with a directional light or an HDRI map, synthesize novel views with view-dependent effects, or do both simultaneously, all in a unified framework using a set of sparse, previously seen observations. Qualitative and quantitative experiments demonstrate that our neural LT (NLT) outperforms state-of-the-art solutions for relighting and view synthesis, without separate treatment for both problems that prior work requires.
A Generalization of Otsu's Method and Minimum Error Thresholding
Aug 19, 2020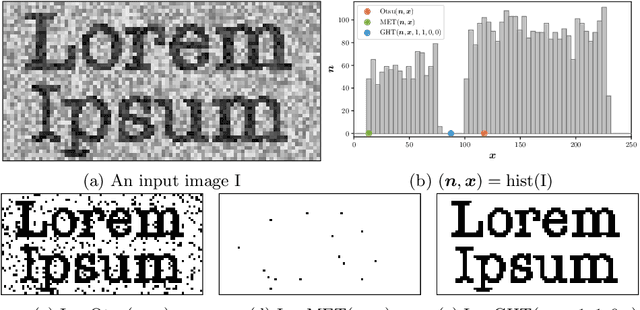
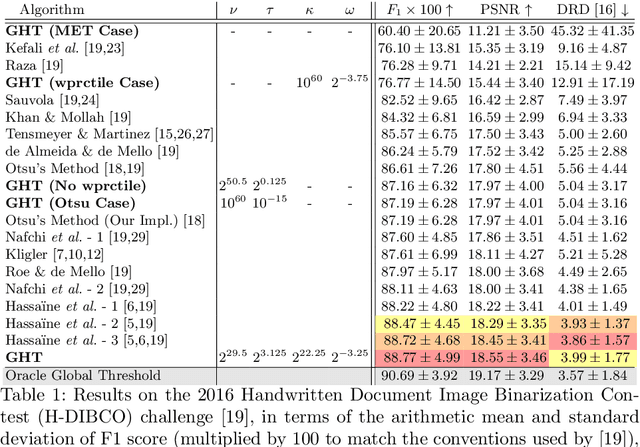
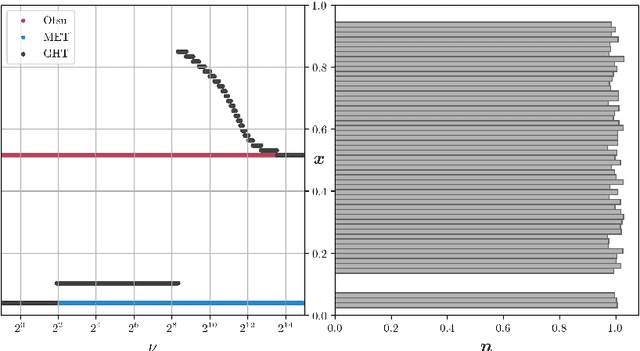
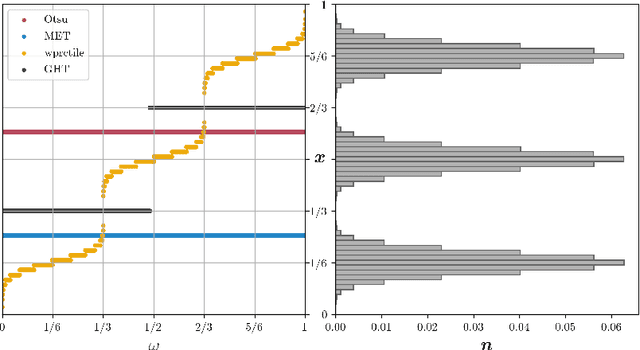
We present Generalized Histogram Thresholding (GHT), a simple, fast, and effective technique for histogram-based image thresholding. GHT works by performing approximate maximum a posteriori estimation of a mixture of Gaussians with appropriate priors. We demonstrate that GHT subsumes three classic thresholding techniques as special cases: Otsu's method, Minimum Error Thresholding (MET), and weighted percentile thresholding. GHT thereby enables the continuous interpolation between those three algorithms, which allows thresholding accuracy to be improved significantly. GHT also provides a clarifying interpretation of the common practice of coarsening a histogram's bin width during thresholding. We show that GHT outperforms or matches the performance of all algorithms on a recent challenge for handwritten document image binarization (including deep neural networks trained to produce per-pixel binarizations), and can be implemented in a dozen lines of code or as a trivial modification to Otsu's method or MET.