 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Gradient Unrolling for Large-Scale Bi-level Optimization
Jun 20, 2024



Bi-level optimization (BO) has become a fundamental mathematical framework for addressing hierarchical machine learning problems. As deep learning models continue to grow in size, the demand for scalable bi-level optimization solutions has become increasingly critical. Traditional gradient-based bi-level optimization algorithms, due to their inherent characteristics, are ill-suited to meet the demands of large-scale applications. In this paper, we introduce $\textbf{F}$orward $\textbf{G}$radient $\textbf{U}$nrolling with $\textbf{F}$orward $\textbf{F}$radient, abbreviated as $(\textbf{FG})^2\textbf{U}$, which achieves an unbiased stochastic approximation of the meta gradient for bi-level optimization. $(\text{FG})^2\text{U}$ circumvents the memory and approximation issues associated with classical bi-level optimization approaches, and delivers significantly more accurate gradient estimates than existing large-scale bi-level optimization approaches. Additionally, $(\text{FG})^2\text{U}$ is inherently designed to support parallel computing, enabling it to effectively leverage large-scale distributed computing systems to achieve significant computational efficiency. In practice, $(\text{FG})^2\text{U}$ and other methods can be strategically placed at different stages of the training process to achieve a more cost-effective two-phase paradigm. Further, $(\text{FG})^2\text{U}$ is easy to implement within popular deep learning frameworks, and can be conveniently adapted to address more challenging zeroth-order bi-level optimization scenarios. We provide a thorough convergence analysis and a comprehensive practical discussion for $(\text{FG})^2\text{U}$, complemented by extensive empirical evaluations, showcasing its superior performance in diverse large-scale bi-level optimization tasks.
No-Regret Algorithms for Safe Bayesian Optimization with Monotonicity Constraints
Jun 05, 2024



We consider the problem of sequentially maximizing an unknown function $f$ over a set of actions of the form $(s,\mathbf{x})$, where the selected actions must satisfy a safety constraint with respect to an unknown safety function $g$. We model $f$ and $g$ as lying in a reproducing kernel Hilbert space (RKHS), which facilitates the use of Gaussian process methods. While existing works for this setting have provided algorithms that are guaranteed to identify a near-optimal safe action, the problem of attaining low cumulative regret has remained largely unexplored, with a key challenge being that expanding the safe region can incur high regret. To address this challenge, we show that if $g$ is monotone with respect to just the single variable $s$ (with no such constraint on $f$), sublinear regret becomes achievable with our proposed algorithm. In addition, we show that a modified version of our algorithm is able to attain sublinear regret (for suitably defined notions of regret) for the task of finding a near-optimal $s$ corresponding to every $\mathbf{x}$, as opposed to only finding the global safe optimum. Our findings are supported with empirical evaluations on various objective and safety functions.
Kernelized Normalizing Constant Estimation: Bridging Bayesian Quadrature and Bayesian Optimization
Jan 11, 2024In this paper, we study the problem of estimating the normalizing constant $\int e^{-\lambda f(x)}dx$ through queries to the black-box function $f$, where $f$ belongs to a reproducing kernel Hilbert space (RKHS), and $\lambda$ is a problem parameter. We show that to estimate the normalizing constant within a small relative error, the level of difficulty depends on the value of $\lambda$: When $\lambda$ approaches zero, the problem is similar to Bayesian quadrature (BQ), while when $\lambda$ approaches infinity, the problem is similar to Bayesian optimization (BO). More generally, the problem varies between BQ and BO. We find that this pattern holds true even when the function evaluations are noisy, bringing new aspects to this topic. Our findings are supported by both algorithm-independent lower bounds and algorithmic upper bounds, as well as simulation studies conducted on a variety of benchmark functions.
Approximate Message Passing with Rigorous Guarantees for Pooled Data and Quantitative Group Testing
Sep 27, 2023In the pooled data problem, the goal is to identify the categories associated with a large collection of items via a sequence of pooled tests. Each pooled test reveals the number of items of each category within the pool. We study an approximate message passing (AMP) algorithm for estimating the categories and rigorously characterize its performance, in both the noiseless and noisy settings. For the noiseless setting, we show that the AMP algorithm is equivalent to one recently proposed by El Alaoui et al. Our results provide a rigorous version of their performance guarantees, previously obtained via non-rigorous techniques. For the case of pooled data with two categories, known as quantitative group testing (QGT), we use the AMP guarantees to compute precise limiting values of the false positive rate and the false negative rate. Though the pooled data problem and QGT are both instances of estimation in a linear model, existing AMP theory cannot be directly applied since the design matrices are binary valued. The key technical ingredient in our result is a rigorous analysis of AMP for generalized linear models defined via generalized white noise design matrices. This result, established using a recent universality result of Wang et al., is of independent interest. Our theoretical results are validated by numerical simulations. For comparison, we propose estimators based on convex relaxation and iterative thresholding, without providing theoretical guarantees. Our simulations indicate that AMP outperforms the convex programming estimator for a range of QGT scenarios, but the convex program performs better for pooled data with three categories.
Concomitant Group Testing
Sep 08, 2023



In this paper, we introduce a variation of the group testing problem capturing the idea that a positive test requires a combination of multiple ``types'' of item. Specifically, we assume that there are multiple disjoint \emph{semi-defective sets}, and a test is positive if and only if it contains at least one item from each of these sets. The goal is to reliably identify all of the semi-defective sets using as few tests as possible, and we refer to this problem as \textit{Concomitant Group Testing} (ConcGT). We derive a variety of algorithms for this task, focusing primarily on the case that there are two semi-defective sets. Our algorithms are distinguished by (i) whether they are deterministic (zero-error) or randomized (small-error), and (ii) whether they are non-adaptive, fully adaptive, or have limited adaptivity (e.g., 2 or 3 stages). Both our deterministic adaptive algorithm and our randomized algorithms (non-adaptive or limited adaptivity) are order-optimal in broad scaling regimes of interest, and improve significantly over baseline results that are based on solving a more general problem as an intermediate step (e.g., hypergraph learning).
Communication-Constrained Bandits under Additive Gaussian Noise
Apr 25, 2023We study a distributed stochastic multi-armed bandit where a client supplies the learner with communication-constrained feedback based on the rewards for the corresponding arm pulls. In our setup, the client must encode the rewards such that the second moment of the encoded rewards is no more than $P$, and this encoded reward is further corrupted by additive Gaussian noise of variance $\sigma^2$; the learner only has access to this corrupted reward. For this setting, we derive an information-theoretic lower bound of $\Omega\left(\sqrt{\frac{KT}{\mathtt{SNR} \wedge1}} \right)$ on the minimax regret of any scheme, where $ \mathtt{SNR} := \frac{P}{\sigma^2}$, and $K$ and $T$ are the number of arms and time horizon, respectively. Furthermore, we propose a multi-phase bandit algorithm, $\mathtt{UE\text{-}UCB++}$, which matches this lower bound to a minor additive factor. $\mathtt{UE\text{-}UCB++}$ performs uniform exploration in its initial phases and then utilizes the {\em upper confidence bound }(UCB) bandit algorithm in its final phase. An interesting feature of $\mathtt{UE\text{-}UCB++}$ is that the coarser estimates of the mean rewards formed during a uniform exploration phase help to refine the encoding protocol in the next phase, leading to more accurate mean estimates of the rewards in the subsequent phase. This positive reinforcement cycle is critical to reducing the number of uniform exploration rounds and closely matching our lower bound.
Regret Bounds for Noise-Free Cascaded Kernelized Bandits
Nov 10, 2022We consider optimizing a function network in the noise-free grey-box setting with RKHS function classes, where the exact intermediate results are observable. We assume that the structure of the network is known (but not the underlying functions comprising it), and we study three types of structures: (1) chain: a cascade of scalar-valued functions, (2) multi-output chain: a cascade of vector-valued functions, and (3) feed-forward network: a fully connected feed-forward network of scalar-valued functions. We propose a sequential upper confidence bound based algorithm GPN-UCB along with a general theoretical upper bound on the cumulative regret. For the Mat\'ern kernel, we additionally propose a non-adaptive sampling based method along with its theoretical upper bound on the simple regret. We also provide algorithm-independent lower bounds on the simple regret and cumulative regret, showing that GPN-UCB is near-optimal for chains and multi-output chains in broad cases of interest.
Benefits of Monotonicity in Safe Exploration with Gaussian Processes
Nov 03, 2022



We consider the problem of sequentially maximising an unknown function over a set of actions while ensuring that every sampled point has a function value below a given safety threshold. We model the function using kernel-based and Gaussian process methods, while differing from previous works in our assumption that the function is monotonically increasing with respect to a safety variable. This assumption is motivated by various practical applications such as adaptive clinical trial design and robotics. Taking inspiration from the GP-UCB and SafeOpt algorithms, we propose an algorithm, monotone safe UCB (M-SafeUCB) for this task. We show that M-SafeUCB enjoys theoretical guarantees in terms of safety, a suitably-defined regret notion, and approximately finding the entire safe boundary. In addition, we illustrate that the monotonicity assumption yields significant benefits in terms of both the guarantees obtained and the algorithmic simplicity. We support our theoretical findings by performing empirical evaluations on a variety of functions.
Max-Quantile Grouped Infinite-Arm Bandits
Oct 04, 2022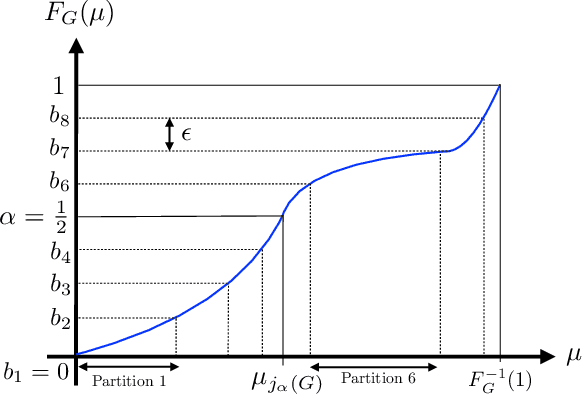
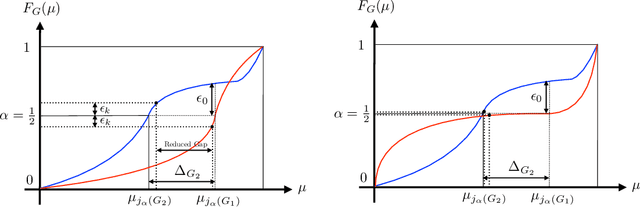
In this paper, we consider a bandit problem in which there are a number of groups each consisting of infinitely many arms. Whenever a new arm is requested from a given group, its mean reward is drawn from an unknown reservoir distribution (different for each group), and the uncertainty in the arm's mean reward can only be reduced via subsequent pulls of the arm. The goal is to identify the infinite-arm group whose reservoir distribution has the highest $(1-\alpha)$-quantile (e.g., median if $\alpha = \frac{1}{2}$), using as few total arm pulls as possible. We introduce a two-step algorithm that first requests a fixed number of arms from each group and then runs a finite-arm grouped max-quantile bandit algorithm. We characterize both the instance-dependent and worst-case regret, and provide a matching lower bound for the latter, while discussing various strengths, weaknesses, algorithmic improvements, and potential lower bounds associated with our instance-dependent upper bounds.
Theoretical Perspectives on Deep Learning Methods in Inverse Problems
Jun 29, 2022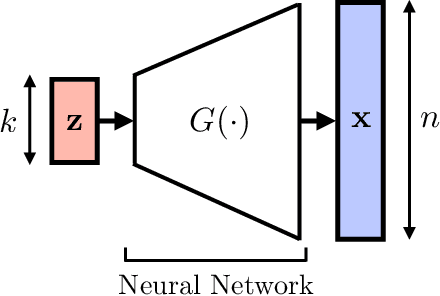
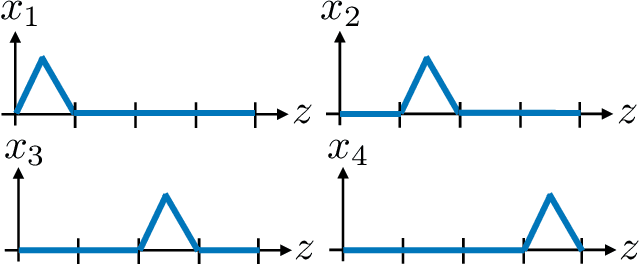
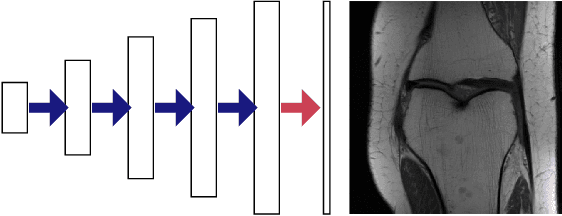
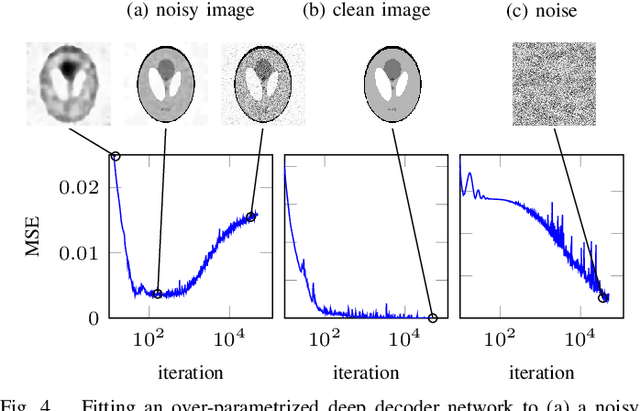
In recent years, there have been significant advances in the use of deep learning methods in inverse problems such as denoising, compressive sensing, inpainting, and super-resolution. While this line of works has predominantly been driven by practical algorithms and experiments, it has also given rise to a variety of intriguing theoretical problems. In this paper, we survey some of the prominent theoretical developments in this line of works, focusing in particular on generative priors, untrained neural network priors, and unfolding algorithms. In addition to summarizing existing results in these topics, we highlight several ongoing challenges and open problems.