 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Imitation Learning
Dec 04, 2017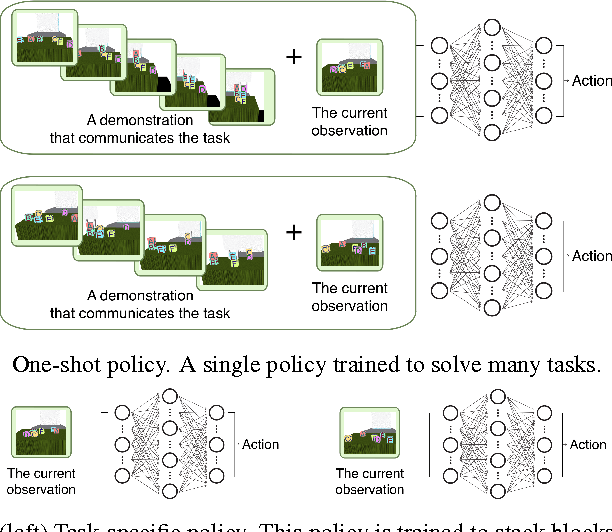
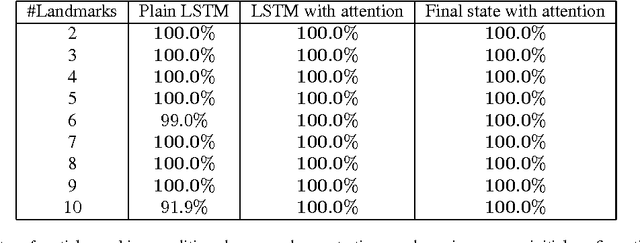
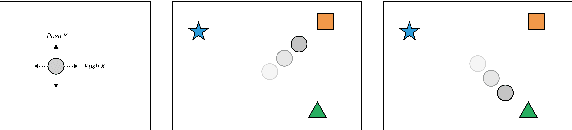
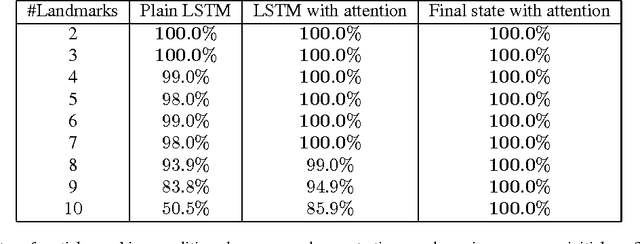
Imitation learning has been commonly applied to solve different tasks in isolation. This usually requires either careful feature engineering, or a significant number of samples. This is far from what we desire: ideally, robots should be able to learn from very few demonstrations of any given task, and instantly generalize to new situations of the same task, without requiring task-specific engineering. In this paper, we propose a meta-learning framework for achieving such capability, which we call one-shot imitation learning. Specifically, we consider the setting where there is a very large set of tasks, and each task has many instantiations. For example, a task could be to stack all blocks on a table into a single tower, another task could be to place all blocks on a table into two-block towers, etc. In each case, different instances of the task would consist of different sets of blocks with different initial states. At training time, our algorithm is presented with pairs of demonstrations for a subset of all tasks. A neural net is trained that takes as input one demonstration and the current state (which initially is the initial state of the other demonstration of the pair), and outputs an action with the goal that the resulting sequence of states and actions matches as closely as possible with the second demonstration. At test time, a demonstration of a single instance of a new task is presented, and the neural net is expected to perform well on new instances of this new task. The use of soft attention allows the model to generalize to conditions and tasks unseen in the training data. We anticipate that by training this model on a much greater variety of tasks and settings, we will obtain a general system that can turn any demonstrations into robust policies that can accomplish an overwhelming variety of tasks. Videos available at https://bit.ly/nips2017-oneshot .
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
Mar 20, 2017
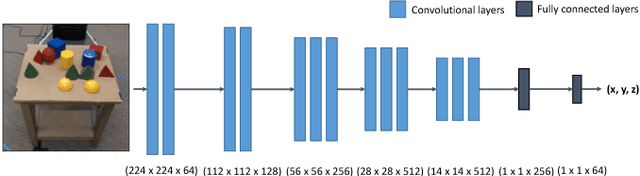

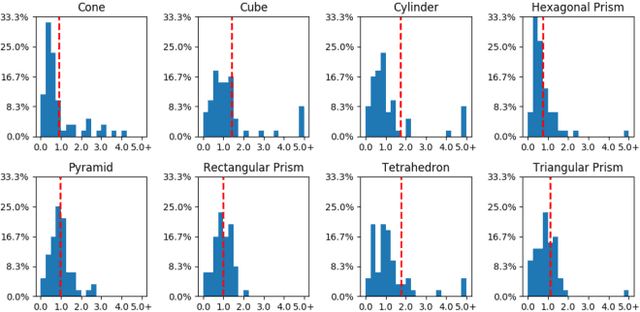
Bridging the 'reality gap' that separates simulated robotics from experiments on hardware could accelerate robotic research through improved data availability. This paper explores domain randomization, a simple technique for training models on simulated images that transfer to real images by randomizing rendering in the simulator. With enough variability in the simulator, the real world may appear to the model as just another variation. We focus on the task of object localization, which is a stepping stone to general robotic manipulation skills. We find that it is possible to train a real-world object detector that is accurate to $1.5$cm and robust to distractors and partial occlusions using only data from a simulator with non-realistic random textures. To demonstrate the capabilities of our detectors, we show they can be used to perform grasping in a cluttered environment. To our knowledge, this is the first successful transfer of a deep neural network trained only on simulated RGB images (without pre-training on real images) to the real world for the purpose of robotic control.
Transfer from Simulation to Real World through Learning Deep Inverse Dynamics Model
Oct 11, 2016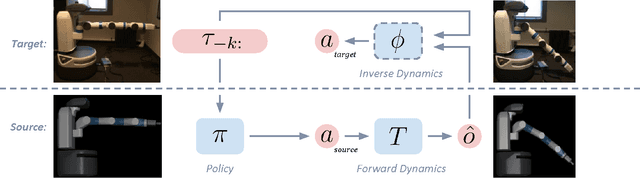

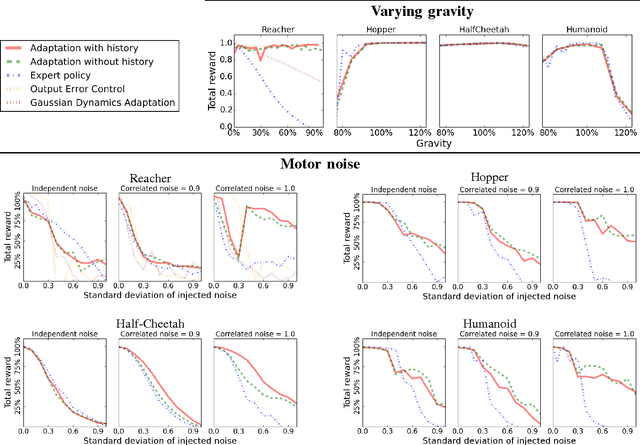
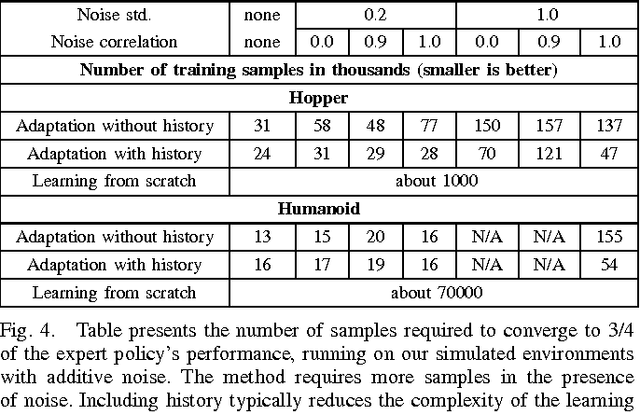
Developing control policies in simulation is often more practical and safer than directly running experiments in the real world. This applies to policies obtained from planning and optimization, and even more so to policies obtained from reinforcement learning, which is often very data demanding. However, a policy that succeeds in simulation often doesn't work when deployed on a real robot. Nevertheless, often the overall gist of what the policy does in simulation remains valid in the real world. In this paper we investigate such settings, where the sequence of states traversed in simulation remains reasonable for the real world, even if the details of the controls are not, as could be the case when the key differences lie in detailed friction, contact, mass and geometry properties. During execution, at each time step our approach computes what the simulation-based control policy would do, but then, rather than executing these controls on the real robot, our approach computes what the simulation expects the resulting next state(s) will be, and then relies on a learned deep inverse dynamics model to decide which real-world action is most suitable to achieve those next states. Deep models are only as good as their training data, and we also propose an approach for data collection to (incrementally) learn the deep inverse dynamics model. Our experiments shows our approach compares favorably with various baselines that have been developed for dealing with simulation to real world model discrepancy, including output error control and Gaussian dynamics adaptation.
OpenAI Gym
Jun 05, 2016
OpenAI Gym is a toolkit for reinforcement learning research. It includes a growing collection of benchmark problems that expose a common interface, and a website where people can share their results and compare the performance of algorithms. This whitepaper discusses the components of OpenAI Gym and the design decisions that went into the software.