 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Direct Optimization for Scene Understanding
Dec 18, 2018
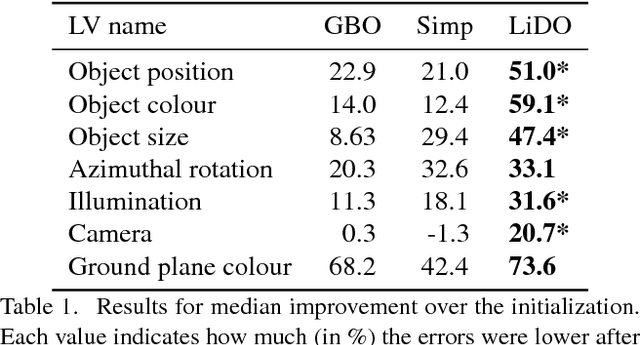
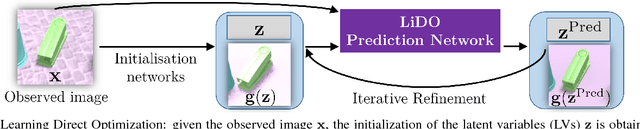
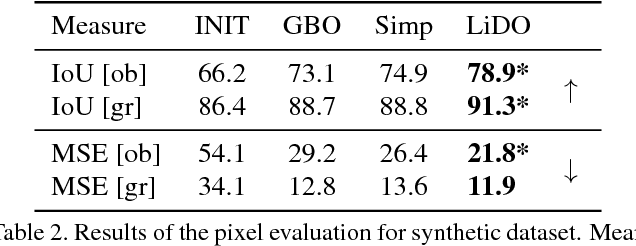
We introduce a Learning Direct Optimization method for the refinement of a latent variable model that describes input image x. Our goal is to explain a single image x with a 3D computer graphics model having scene graph latent variables z (such as object appearance, camera position). Given a current estimate of z we can render a prediction of the image g(z), which can be compared to the image x. The standard way to proceed is then to measure the error E(x, g(z)) between the two, and use an optimizer to minimize the error. Our novel Learning Direct Optimization (LiDO) approach trains a Prediction Network to predict an update directly to correct z, rather than minimizing the error with respect to z. Experiments show that our LiDO method converges rapidly as it does not need to perform a search on the error landscape, produces better solutions, and is able to handle the mismatch between the data and the fitted scene model. We apply the LiDO to a realistic synthetic dataset, and show that the method transfers to work well with real images.
Gaussian Attention Model and Its Application to Knowledge Base Embedding and Question Answering
Nov 30, 2016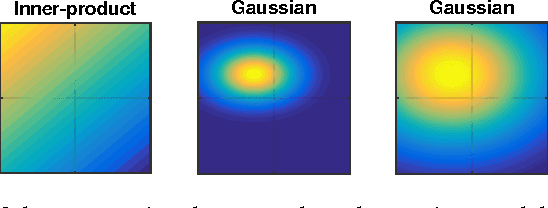
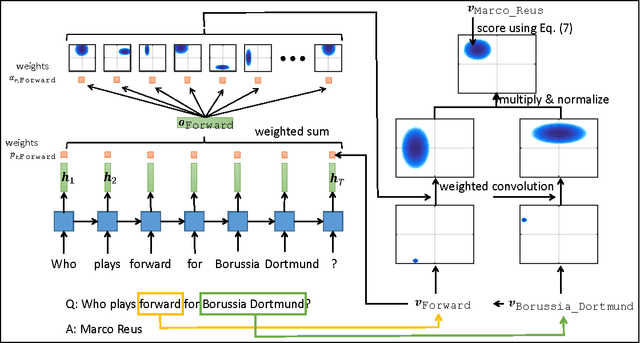
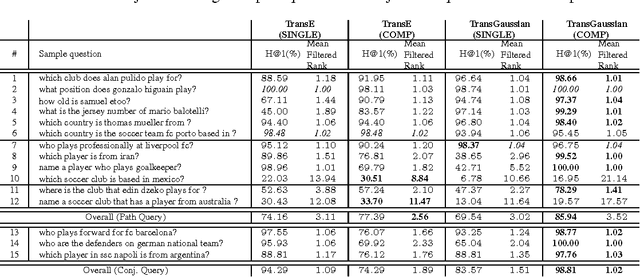
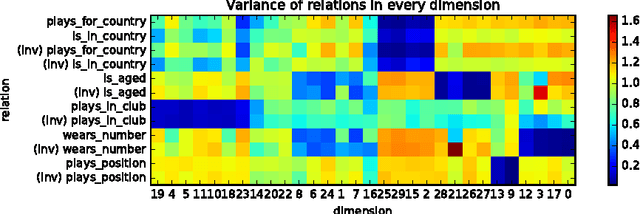
We propose the Gaussian attention model for content-based neural memory access. With the proposed attention model, a neural network has the additional degree of freedom to control the focus of its attention from a laser sharp attention to a broad attention. It is applicable whenever we can assume that the distance in the latent space reflects some notion of semantics. We use the proposed attention model as a scoring function for the embedding of a knowledge base into a continuous vector space and then train a model that performs question answering about the entities in the knowledge base. The proposed attention model can handle both the propagation of uncertainty when following a series of relations and also the conjunction of conditions in a natural way. On a dataset of soccer players who participated in the FIFA World Cup 2014, we demonstrate that our model can handle both path queries and conjunctive queries well.
Consensus Message Passing for Layered Graphical Models
Jan 26, 2015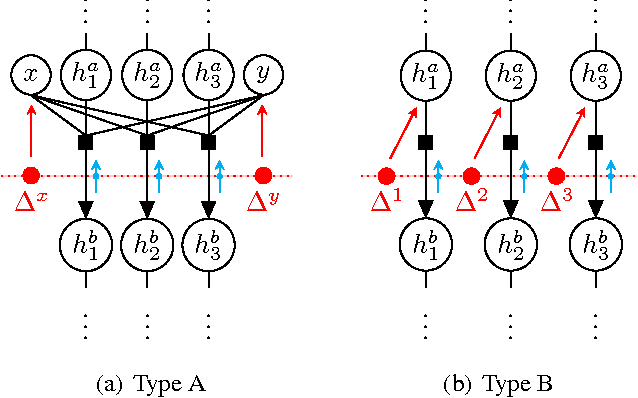
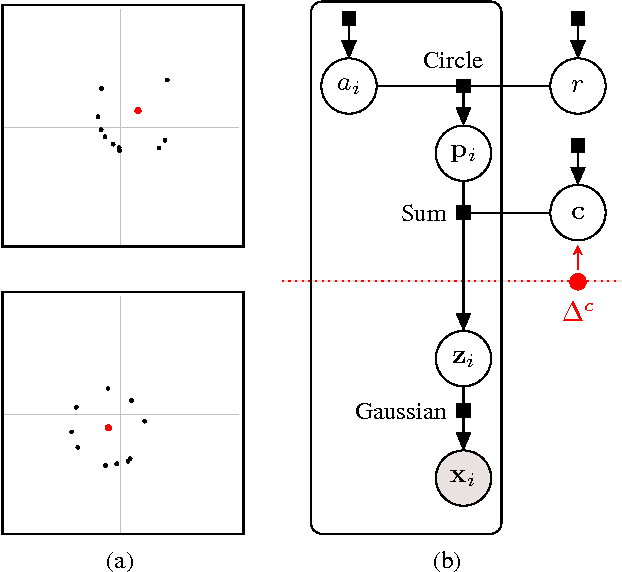
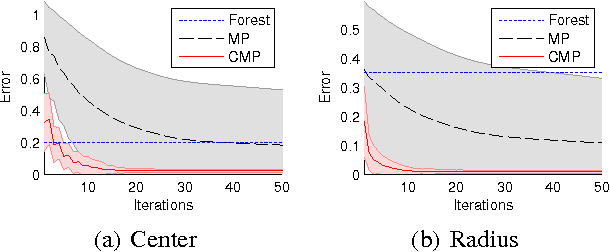
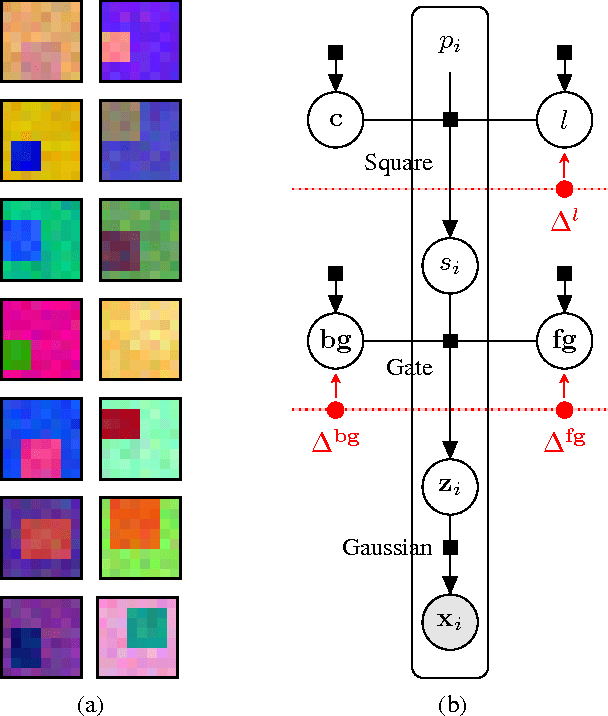
Generative models provide a powerful framework for probabilistic reasoning. However, in many domains their use has been hampered by the practical difficulties of inference. This is particularly the case in computer vision, where models of the imaging process tend to be large, loopy and layered. For this reason bottom-up conditional models have traditionally dominated in such domains. We find that widely-used, general-purpose message passing inference algorithms such as Expectation Propagation (EP) and Variational Message Passing (VMP) fail on the simplest of vision models. With these models in mind, we introduce a modification to message passing that learns to exploit their layered structure by passing 'consensus' messages that guide inference towards good solutions. Experiments on a variety of problems show that the proposed technique leads to significantly more accurate inference results, not only when compared to standard EP and VMP, but also when compared to competitive bottom-up conditional models.
Weakly Supervised Learning of Foreground-Background Segmentation using Masked RBMs
Jul 19, 2011
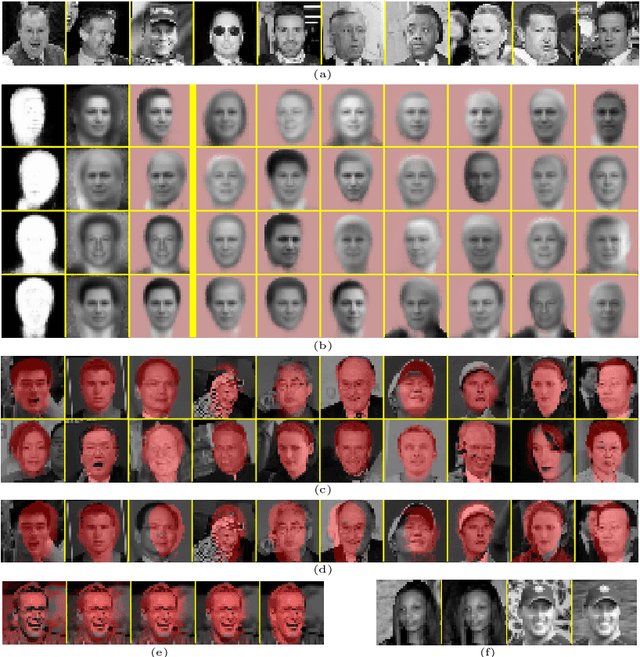
We propose an extension of the Restricted Boltzmann Machine (RBM) that allows the joint shape and appearance of foreground objects in cluttered images to be modeled independently of the background. We present a learning scheme that learns this representation directly from cluttered images with only very weak supervision. The model generates plausible samples and performs foreground-background segmentation. We demonstrate that representing foreground objects independently of the background can be beneficial in recognition tasks.