 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Direct Optimization for Scene Understanding
Dec 18, 2018
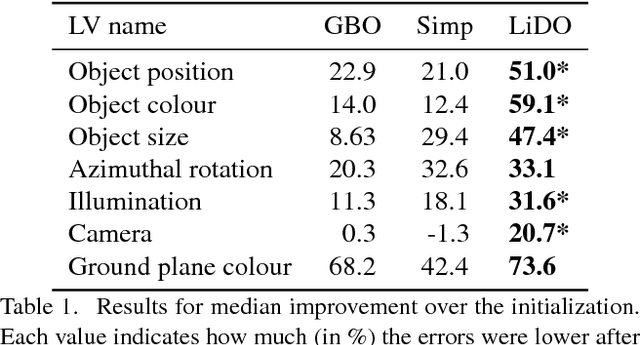
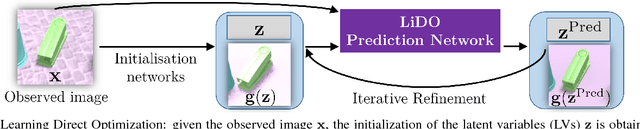
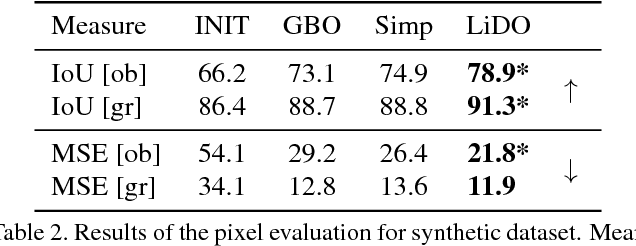
We introduce a Learning Direct Optimization method for the refinement of a latent variable model that describes input image x. Our goal is to explain a single image x with a 3D computer graphics model having scene graph latent variables z (such as object appearance, camera position). Given a current estimate of z we can render a prediction of the image g(z), which can be compared to the image x. The standard way to proceed is then to measure the error E(x, g(z)) between the two, and use an optimizer to minimize the error. Our novel Learning Direct Optimization (LiDO) approach trains a Prediction Network to predict an update directly to correct z, rather than minimizing the error with respect to z. Experiments show that our LiDO method converges rapidly as it does not need to perform a search on the error landscape, produces better solutions, and is able to handle the mismatch between the data and the fitted scene model. We apply the LiDO to a realistic synthetic dataset, and show that the method transfers to work well with real images.
Challenges in Representation Learning: A report on three machine learning contests
Jul 01, 2013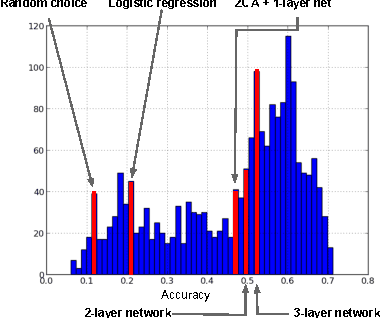

The ICML 2013 Workshop on Challenges in Representation Learning focused on three challenges: the black box learning challenge, the facial expression recognition challenge, and the multimodal learning challenge. We describe the datasets created for these challenges and summarize the results of the competitions. We provide suggestions for organizers of future challenges and some comments on what kind of knowledge can be gained from machine learning competitions.