 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gold Standard Dataset for the Reviewer Assignment Problem
Mar 23, 2023Many peer-review venues are either using or looking to use algorithms to assign submissions to reviewers. The crux of such automated approaches is the notion of the "similarity score"--a numerical estimate of the expertise of a reviewer in reviewing a paper--and many algorithms have been proposed to compute these scores. However, these algorithms have not been subjected to a principled comparison, making it difficult for stakeholders to choose the algorithm in an evidence-based manner. The key challenge in comparing existing algorithms and developing better algorithms is the lack of the publicly available gold-standard data that would be needed to perform reproducible research. We address this challenge by collecting a novel dataset of similarity scores that we release to the research community. Our dataset consists of 477 self-reported expertise scores provided by 58 researchers who evaluated their expertise in reviewing papers they have read previously. We use this data to compare several popular algorithms employed in computer science conferences and come up with recommendations for stakeholders. Our main findings are as follows. First, all algorithms make a non-trivial amount of error. For the task of ordering two papers in terms of their relevance for a reviewer, the error rates range from 12%-30% in easy cases to 36%-43% in hard cases, highlighting the vital need for more research on the similarity-computation problem. Second, most existing algorithms are designed to work with titles and abstracts of papers, and in this regime the Specter+MFR algorithm performs best. Third, to improve performance, it may be important to develop modern deep-learning based algorithms that can make use of the full texts of papers: the classical TD-IDF algorithm enhanced with full texts of papers is on par with the deep-learning based Specter+MFR that cannot make use of this information.
Paraphrasing evades detectors of AI-generated text, but retrieval is an effective defense
Mar 23, 2023



To detect the deployment of large language models for malicious use cases (e.g., fake content creation or academic plagiarism), several approaches have recently been proposed for identifying AI-generated text via watermarks or statistical irregularities. How robust are these detection algorithms to paraphrases of AI-generated text? To stress test these detectors, we first train an 11B parameter paraphrase generation model (DIPPER) that can paraphrase paragraphs, optionally leveraging surrounding text (e.g., user-written prompts) as context. DIPPER also uses scalar knobs to control the amount of lexical diversity and reordering in the paraphrases. Paraphrasing text generated by three large language models (including GPT3.5-davinci-003) with DIPPER successfully evades several detectors, including watermarking, GPTZero, DetectGPT, and OpenAI's text classifier. For example, DIPPER drops the detection accuracy of DetectGPT from 70.3% to 4.6% (at a constant false positive rate of 1%), without appreciably modifying the input semantics. To increase the robustness of AI-generated text detection to paraphrase attacks, we introduce a simple defense that relies on retrieving semantically-similar generations and must be maintained by a language model API provider. Given a candidate text, our algorithm searches a database of sequences previously generated by the API, looking for sequences that match the candidate text within a certain threshold. We empirically verify our defense using a database of 15M generations from a fine-tuned T5-XXL model and find that it can detect 80% to 97% of paraphrased generations across different settings, while only classifying 1% of human-written sequences as AI-generated. We will open source our code, model and data for future research.
Beyond Contrastive Learning: A Variational Generative Model for Multilingual Retrieval
Dec 21, 2022Contrastive learning has been successfully used for retrieval of semantically aligned sentences, but it often requires large batch sizes or careful engineering to work well. In this paper, we instead propose a generative model for learning multilingual text embeddings which can be used to retrieve or score sentence pairs. Our model operates on parallel data in $N$ languages and, through an approximation we introduce, efficiently encourages source separation in this multilingual setting, separating semantic information that is shared between translations from stylistic or language-specific variation. We show careful large-scale comparisons between contrastive and generation-based approaches for learning multilingual text embeddings, a comparison that has not been done to the best of our knowledge despite the popularity of these approaches. We evaluate this method on a suite of tasks including semantic similarity, bitext mining, and cross-lingual question retrieval -- the last of which we introduce in this paper. Overall, our Variational Multilingual Source-Separation Transformer (VMSST) model outperforms both a strong contrastive and generative baseline on these tasks.
Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature
Oct 25, 2022



Literary translation is a culturally significant task, but it is bottlenecked by the small number of qualified literary translators relative to the many untranslated works published around the world. Machine translation (MT) holds potential to complement the work of human translators by improving both training procedures and their overall efficiency. Literary translation is less constrained than more traditional MT settings since translators must balance meaning equivalence, readability, and critical interpretability in the target language. This property, along with the complex discourse-level context present in literary texts, also makes literary MT more challenging to computationally model and evaluate. To explore this task, we collect a dataset (Par3) of non-English language novels in the public domain, each aligned at the paragraph level to both human and automatic English translations. Using Par3, we discover that expert literary translators prefer reference human translations over machine-translated paragraphs at a rate of 84%, while state-of-the-art automatic MT metrics do not correlate with those preferences. The experts note that MT outputs contain not only mistranslations, but also discourse-disrupting errors and stylistic inconsistencies. To address these problems, we train a post-editing model whose output is preferred over normal MT output at a rate of 69% by experts. We publicly release Par3 at https://github.com/katherinethai/par3/ to spur future research into literary MT.
QA Is the New KR: Question-Answer Pairs as Knowledge Bases
Jul 01, 2022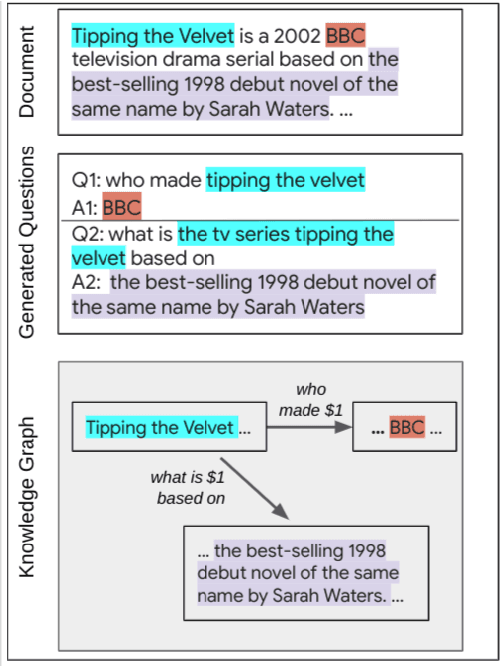
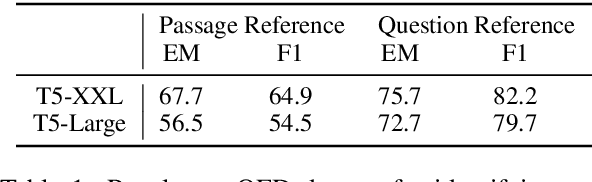
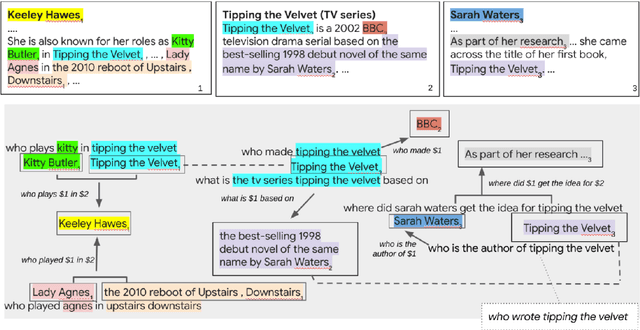
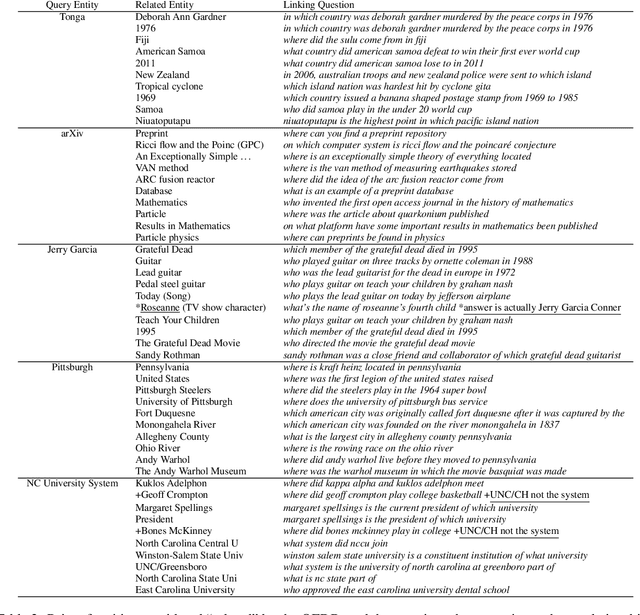
In this position paper, we propose a new approach to generating a type of knowledge base (KB) from text, based on question generation and entity linking. We argue that the proposed type of KB has many of the key advantages of a traditional symbolic KB: in particular, it consists of small modular components, which can be combined compositionally to answer complex queries, including relational queries and queries involving "multi-hop" inferences. However, unlike a traditional KB, this information store is well-aligned with common user information needs.
RankGen: Improving Text Generation with Large Ranking Models
May 19, 2022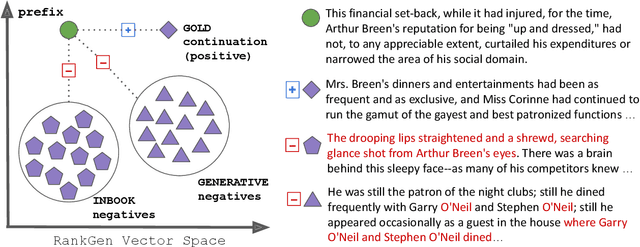
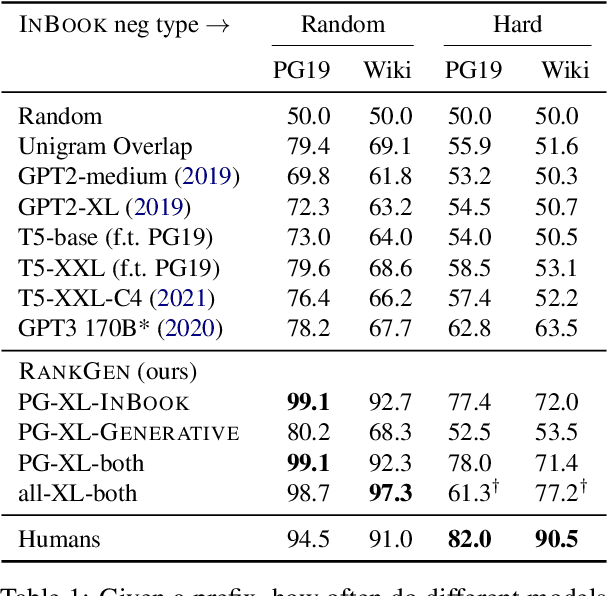
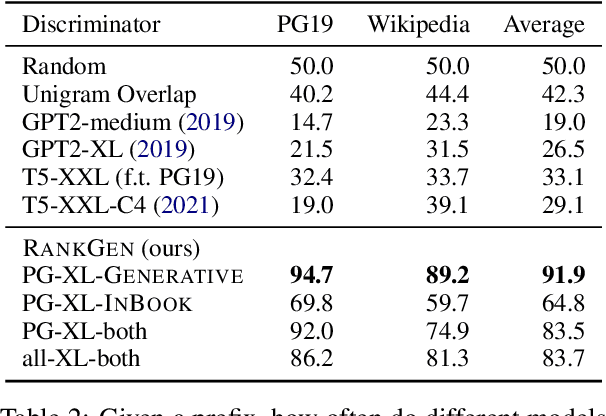
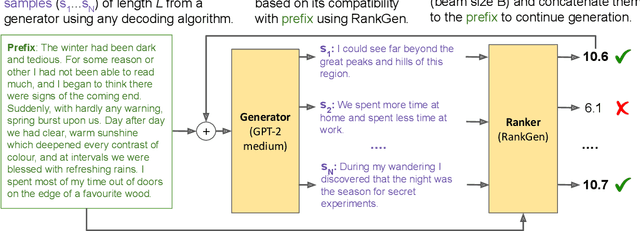
Given an input sequence (or prefix), modern language models often assign high probabilities to output sequences that are repetitive, incoherent, or irrelevant to the prefix; as such, model-generated text also contains such artifacts. To address these issues, we present RankGen, an encoder model (1.2B parameters) that scores model generations given a prefix. RankGen can be flexibly incorporated as a scoring function in beam search and used to decode from any pretrained language model. We train RankGen using large-scale contrastive learning to map a prefix close to the ground-truth sequence that follows it and far away from two types of negatives: (1) random sequences from the same document as the prefix, and, which discourage topically-similar but irrelevant generations; (2) sequences generated from a large language model conditioned on the prefix, which discourage repetition and hallucination. Experiments across four different language models (345M-11B parameters) and two domains show that RankGen significantly outperforms decoding algorithms like nucleus, top-k, and typical sampling on both automatic metrics (85.0 vs 77.3 MAUVE) as well as human evaluations with English writers (74.5% human preference over nucleus sampling). Analysis reveals that RankGen outputs are more relevant to the prefix and improve continuity and coherence compared to baselines. We open source our model checkpoints, code, and human preferences with detailed explanations for future research.
Faithful to the Document or to the World? Mitigating Hallucinations via Entity-linked Knowledge in Abstractive Summarization
Apr 28, 2022
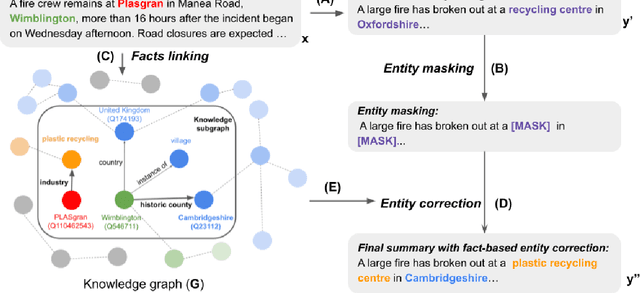
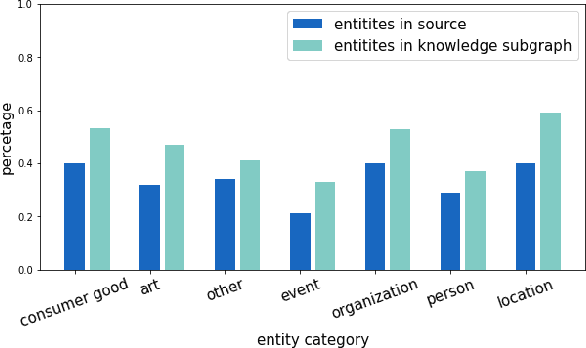
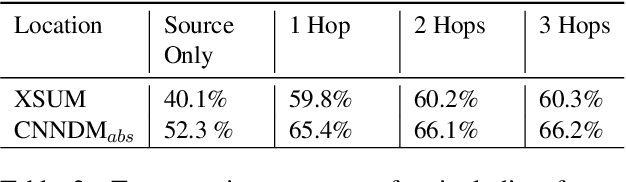
Despite recent advances in abstractive summarization, current summarization systems still suffer from content hallucinations where models generate text that is either irrelevant or contradictory to the source document. However, prior work has been predicated on the assumption that any generated facts not appearing explicitly in the source are undesired hallucinations. Methods have been proposed to address this scenario by ultimately improving `faithfulness' to the source document, but in reality, there is a large portion of entities in the gold reference targets that are not directly in the source. In this work, we show that these entities are not aberrations, but they instead require utilizing external world knowledge to infer reasoning paths from entities in the source. We show that by utilizing an external knowledge base, we can improve the faithfulness of summaries without simply making them more extractive, and additionally, we show that external knowledge bases linked from the source can benefit the factuality of generated summaries.
Augmenting Pre-trained Language Models with QA-Memory for Open-Domain Question Answering
Apr 10, 2022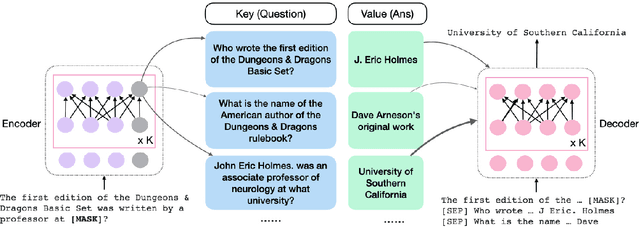
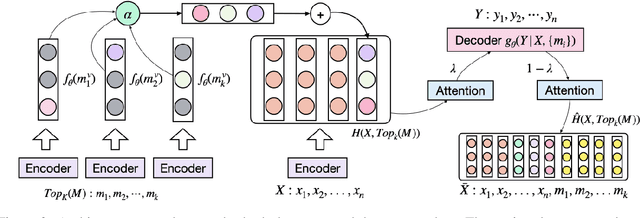
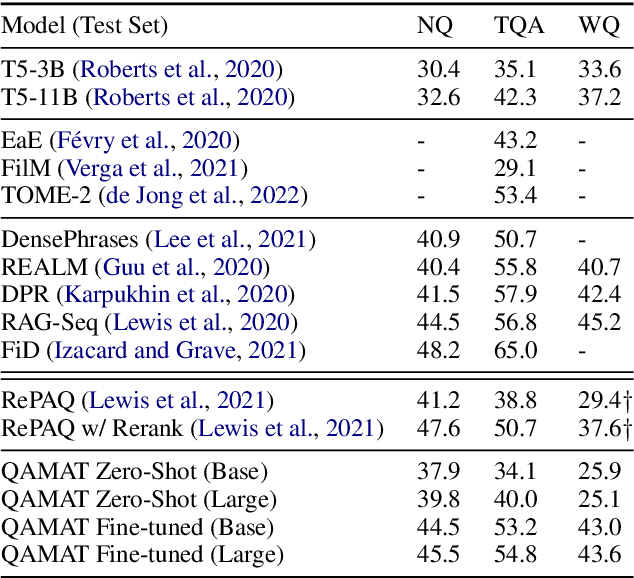
Retrieval augmented language models have recently become the standard for knowledge intensive tasks. Rather than relying purely on latent semantics within the parameters of large neural models, these methods enlist a semi-parametric memory to encode an index of knowledge for the model to retrieve over. Most prior work has employed text passages as the unit of knowledge, which has high coverage at the cost of interpretability, controllability, and efficiency. The opposite properties arise in other methods which have instead relied on knowledge base (KB) facts. At the same time, more recent work has demonstrated the effectiveness of storing and retrieving from an index of Q-A pairs derived from text \citep{lewis2021paq}. This approach yields a high coverage knowledge representation that maintains KB-like properties due to its representations being more atomic units of information. In this work we push this line of research further by proposing a question-answer augmented encoder-decoder model and accompanying pretraining strategy. This yields an end-to-end system that not only outperforms prior QA retrieval methods on single-hop QA tasks but also enables compositional reasoning, as demonstrated by strong performance on two multi-hop QA datasets. Together, these methods improve the ability to interpret and control the model while narrowing the performance gap with passage retrieval systems.
Improving the Diversity of Unsupervised Paraphrasing with Embedding Outputs
Oct 25, 2021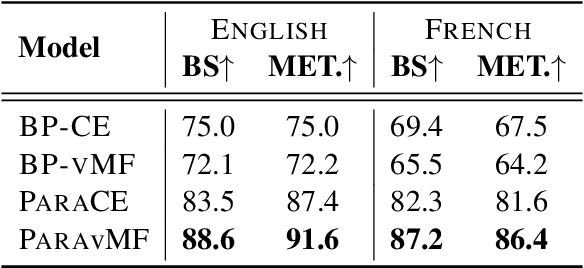
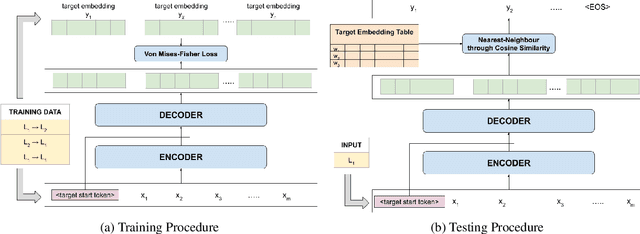
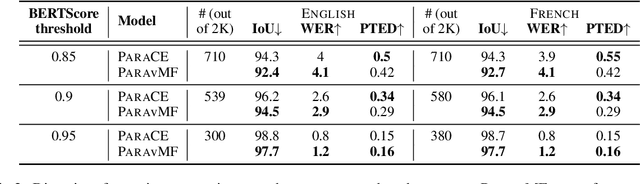
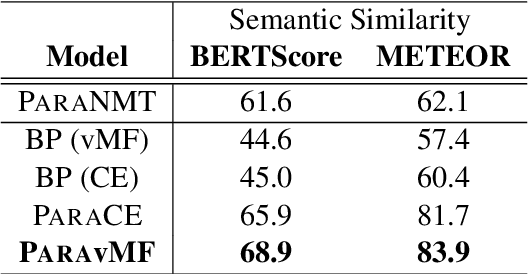
We present a novel technique for zero-shot paraphrase generation. The key contribution is an end-to-end multilingual paraphrasing model that is trained using translated parallel corpora to generate paraphrases into "meaning spaces" -- replacing the final softmax layer with word embeddings. This architectural modification, plus a training procedure that incorporates an autoencoding objective, enables effective parameter sharing across languages for more fluent monolingual rewriting, and facilitates fluency and diversity in generation. Our continuous-output paraphrase generation models outperform zero-shot paraphrasing baselines when evaluated on two languages using a battery of computational metrics as well as in human assessment.
On The Ingredients of an Effective Zero-shot Semantic Parser
Oct 15, 2021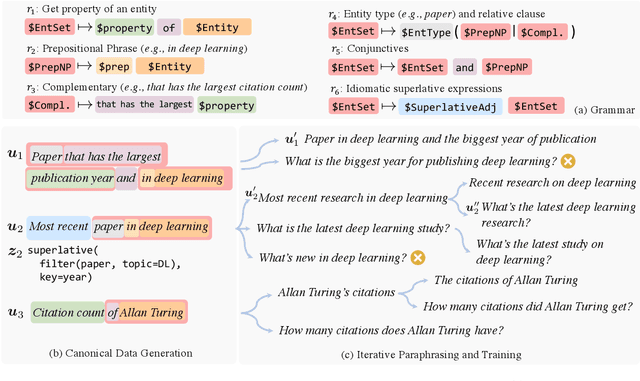
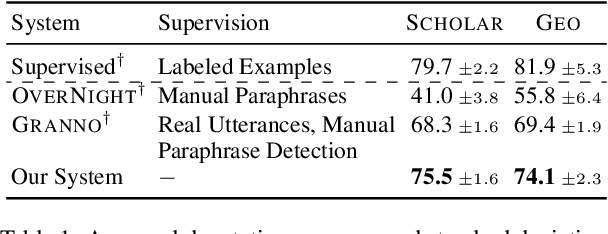
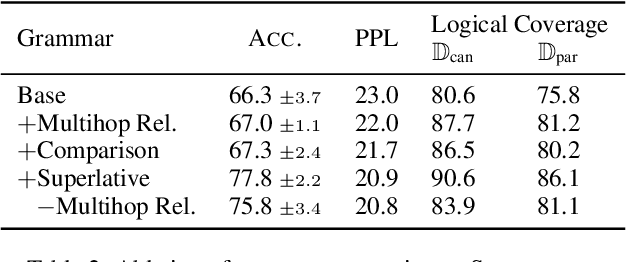

Semantic parsers map natural language utterances into meaning representations (e.g., programs). Such models are typically bottlenecked by the paucity of training data due to the required laborious annotation efforts. Recent studies have performed zero-shot learning by synthesizing training examples of canonical utterances and programs from a grammar, and further paraphrasing these utterances to improve linguistic diversity. However, such synthetic examples cannot fully capture patterns in real data. In this paper we analyze zero-shot parsers through the lenses of the language and logical gaps (Herzig and Berant, 2019), which quantify the discrepancy of language and programmatic patterns between the canonical examples and real-world user-issued ones. We propose bridging these gaps using improved grammars, stronger paraphrasers, and efficient learning methods using canonical examples that most likely reflect real user intents. Our model achieves strong performance on two semantic parsing benchmarks (Scholar, Geo) with zero labeled data.