 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Error Correction Network for Compressed Sensing MRI
Mar 23, 2018
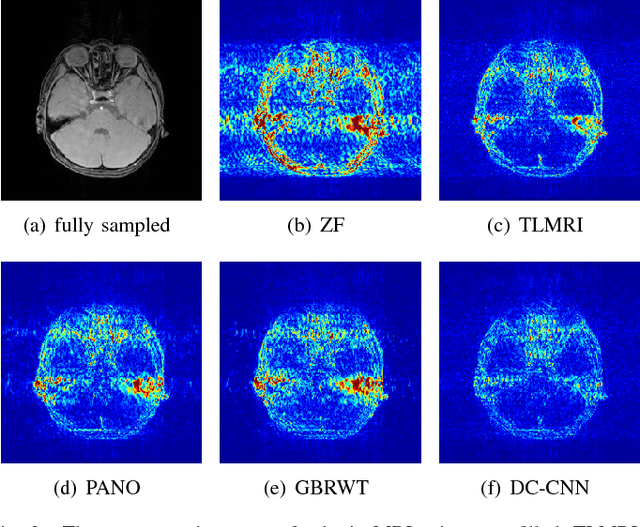

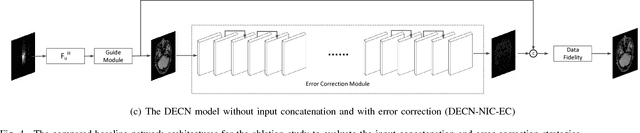
Compressed sensing for magnetic resonance imaging (CS-MRI) exploits image sparsity properties to reconstruct MRI from very few Fourier k-space measurements. The goal is to minimize any structural errors in the reconstruction that could have a negative impact on its diagnostic quality. To this end, we propose a deep error correction network (DECN) for CS-MRI. The DECN model consists of three parts, which we refer to as modules: a guide, or template, module, an error correction module, and a data fidelity module. Existing CS-MRI algorithms can serve as the template module for guiding the reconstruction. Using this template as a guide, the error correction module learns a convolutional neural network (CNN) to map the k-space data in a way that adjusts for the reconstruction error of the template image. Our experimental results show the proposed DECN CS-MRI reconstruction framework can considerably improve upon existing inversion algorithms by supplementing with an error-correcting CNN.
Online Forecasting Matrix Factorization
Dec 23, 2017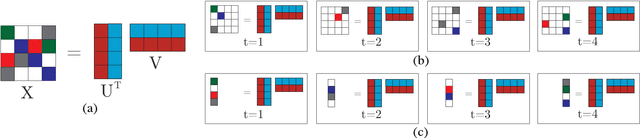
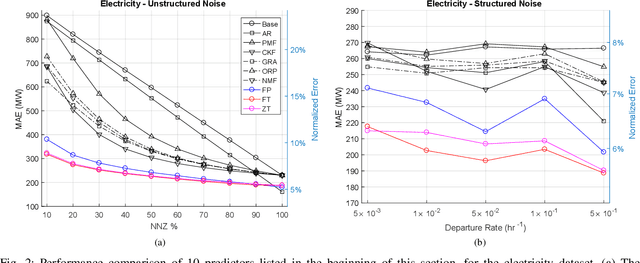
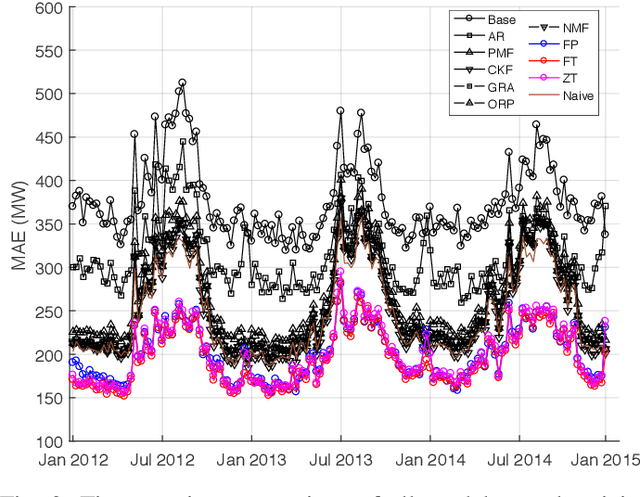
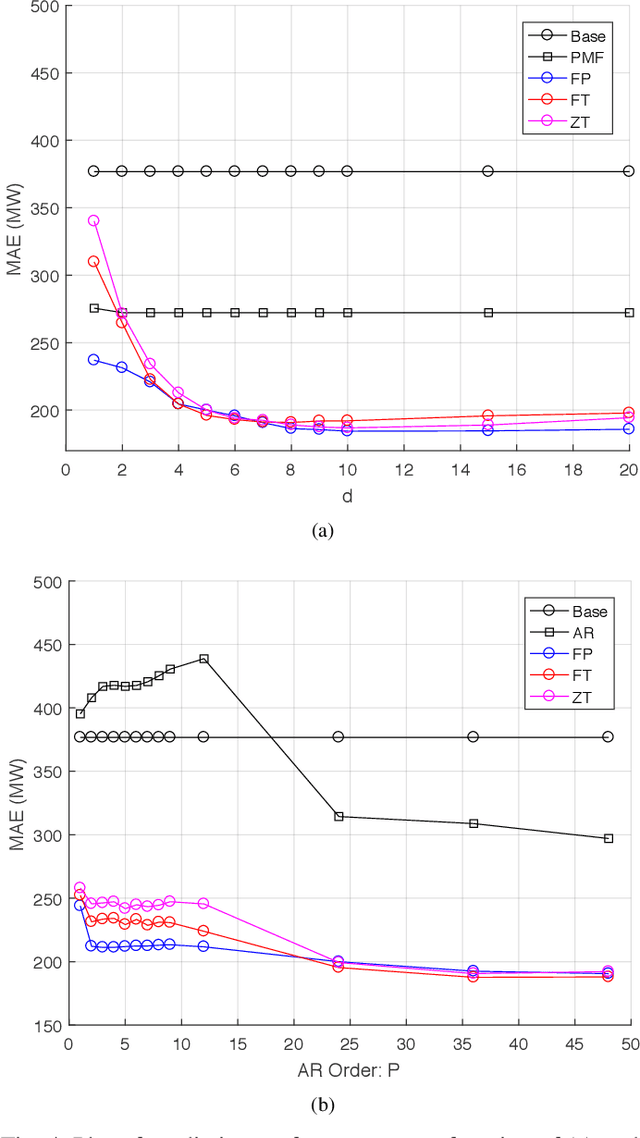
In this paper the problem of forecasting high dimensional time series is considered. Such time series can be modeled as matrices where each column denotes a measurement. In addition, when missing values are present, low rank matrix factorization approaches are suitable for predicting future values. This paper formally defines and analyzes the forecasting problem in the online setting, i.e. where the data arrives as a stream and only a single pass is allowed. We present and analyze novel matrix factorization techniques which can learn low-dimensional embeddings effectively in an online manner. Based on these embeddings a recursive minimum mean square error estimator is derived, which learns an autoregressive model on them. Experiments with two real datasets with tens of millions of measurements show the benefits of the proposed approach.
Variational Inference via $χ$-Upper Bound Minimization
Nov 12, 2017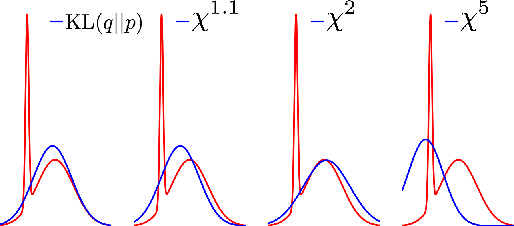
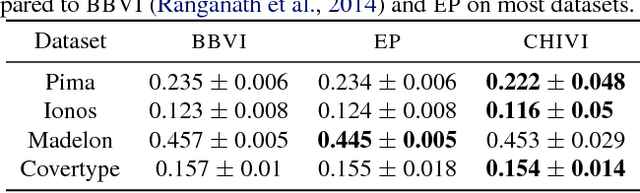
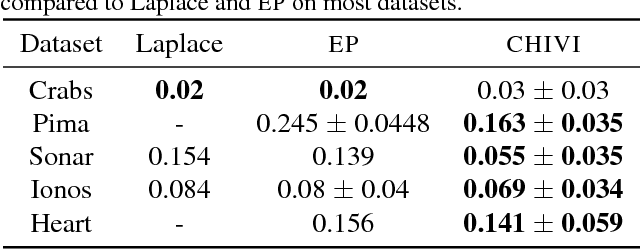

Variational inference (VI) is widely used as an efficient alternative to Markov chain Monte Carlo. It posits a family of approximating distributions $q$ and finds the closest member to the exact posterior $p$. Closeness is usually measured via a divergence $D(q || p)$ from $q$ to $p$. While successful, this approach also has problems. Notably, it typically leads to underestimation of the posterior variance. In this paper we propose CHIVI, a black-box variational inference algorithm that minimizes $D_{\chi}(p || q)$, the $\chi$-divergence from $p$ to $q$. CHIVI minimizes an upper bound of the model evidence, which we term the $\chi$ upper bound (CUBO). Minimizing the CUBO leads to improved posterior uncertainty, and it can also be used with the classical VI lower bound (ELBO) to provide a sandwich estimate of the model evidence. We study CHIVI on three models: probit regression, Gaussian process classification, and a Cox process model of basketball plays. When compared to expectation propagation and classical VI, CHIVI produces better error rates and more accurate estimates of posterior variance.
Hyperspectral Image Classification with Markov Random Fields and a Convolutional Neural Network
Nov 12, 2017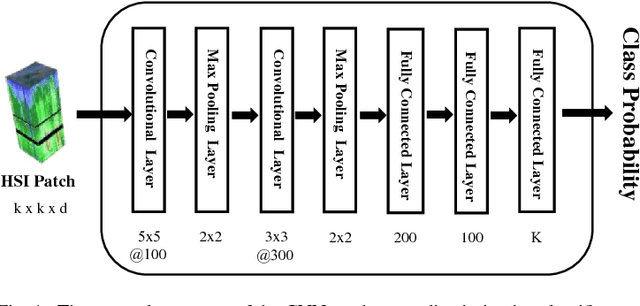
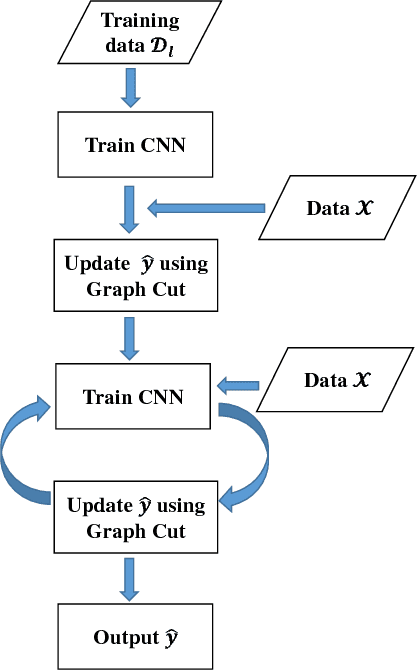


This paper presents a new supervised classification algorithm for remotely sensed hyperspectral image (HSI) which integrates spectral and spatial information in a unified Bayesian framework. First, we formulate the HSI classification problem from a Bayesian perspective. Then, we adopt a convolutional neural network (CNN) to learn the posterior class distributions using a patch-wise training strategy to better use the spatial information. Next, spatial information is further considered by placing a spatial smoothness prior on the labels. Finally, we iteratively update the CNN parameters using stochastic gradient decent (SGD) and update the class labels of all pixel vectors using an alpha-expansion min-cut-based algorithm. Compared with other state-of-the-art methods, the proposed classification method achieves better performance on one synthetic dataset and two benchmark HSI datasets in a number of experimental settings.
Location Dependent Dirichlet Processes
Jul 02, 2017
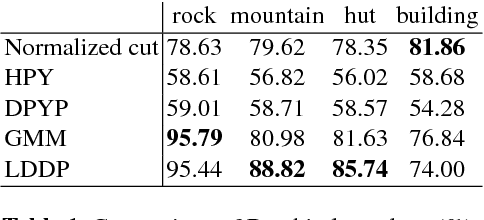

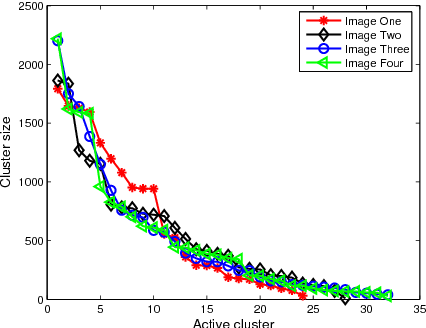
Dirichlet processes (DP) are widely applied in Bayesian nonparametric modeling. However, in their basic form they do not directly integrate dependency information among data arising from space and time. In this paper, we propose location dependent Dirichlet processes (LDDP) which incorporate nonparametric Gaussian processes in the DP modeling framework to model such dependencies. We develop the LDDP in the context of mixture modeling, and develop a mean field variational inference algorithm for this mixture model. The effectiveness of the proposed modeling framework is shown on an image segmentation task.
Nonlinear Kalman Filtering with Divergence Minimization
May 01, 2017



We consider the nonlinear Kalman filtering problem using Kullback-Leibler (KL) and $\alpha$-divergence measures as optimization criteria. Unlike linear Kalman filters, nonlinear Kalman filters do not have closed form Gaussian posteriors because of a lack of conjugacy due to the nonlinearity in the likelihood. In this paper we propose novel algorithms to optimize the forward and reverse forms of the KL divergence, as well as the alpha-divergence which contains these two as limiting cases. Unlike previous approaches, our algorithms do not make approximations to the divergences being optimized, but use Monte Carlo integration techniques to derive unbiased algorithms for direct optimization. We assess performance on radar and sensor tracking, and options pricing problems, showing general improvement over the UKF and EKF, as well as competitive performance with particle filtering.
TopicRNN: A Recurrent Neural Network with Long-Range Semantic Dependency
Feb 27, 2017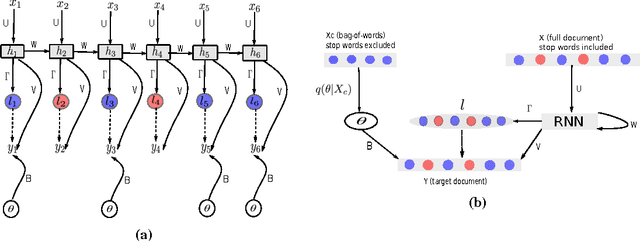
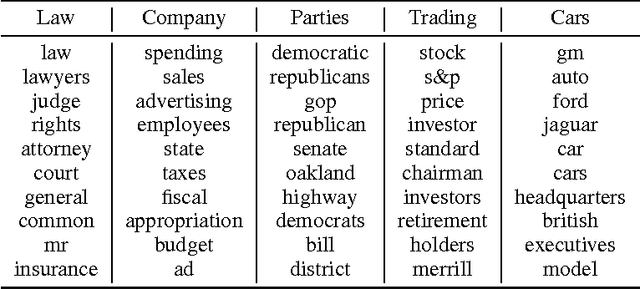
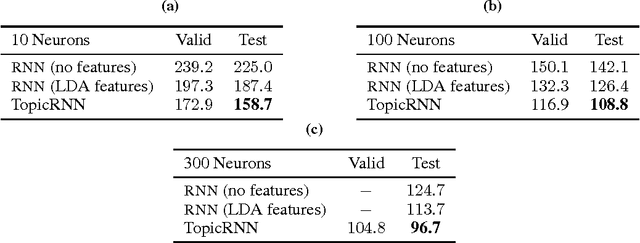

In this paper, we propose TopicRNN, a recurrent neural network (RNN)-based language model designed to directly capture the global semantic meaning relating words in a document via latent topics. Because of their sequential nature, RNNs are good at capturing the local structure of a word sequence - both semantic and syntactic - but might face difficulty remembering long-range dependencies. Intuitively, these long-range dependencies are of semantic nature. In contrast, latent topic models are able to capture the global underlying semantic structure of a document but do not account for word ordering. The proposed TopicRNN model integrates the merits of RNNs and latent topic models: it captures local (syntactic) dependencies using an RNN and global (semantic) dependencies using latent topics. Unlike previous work on contextual RNN language modeling, our model is learned end-to-end. Empirical results on word prediction show that TopicRNN outperforms existing contextual RNN baselines. In addition, TopicRNN can be used as an unsupervised feature extractor for documents. We do this for sentiment analysis on the IMDB movie review dataset and report an error rate of $6.28\%$. This is comparable to the state-of-the-art $5.91\%$ resulting from a semi-supervised approach. Finally, TopicRNN also yields sensible topics, making it a useful alternative to document models such as latent Dirichlet allocation.
Clearing the Skies: A deep network architecture for single-image rain removal
Feb 06, 2017



We introduce a deep network architecture called DerainNet for removing rain streaks from an image. Based on the deep convolutional neural network (CNN), we directly learn the mapping relationship between rainy and clean image detail layers from data. Because we do not possess the ground truth corresponding to real-world rainy images, we synthesize images with rain for training. In contrast to other common strategies that increase depth or breadth of the network, we use image processing domain knowledge to modify the objective function and improve deraining with a modestly-sized CNN. Specifically, we train our DerainNet on the detail (high-pass) layer rather than in the image domain. Though DerainNet is trained on synthetic data, we find that the learned network translates very effectively to real-world images for testing. Moreover, we augment the CNN framework with image enhancement to improve the visual results. Compared with state-of-the-art single image de-raining methods, our method has improved rain removal and much faster computation time after network training.
Bayesian Poisson Tensor Factorization for Inferring Multilateral Relations from Sparse Dyadic Event Counts
Jun 10, 2015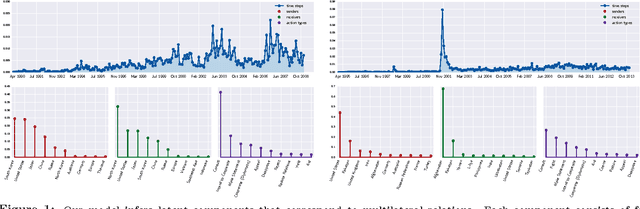
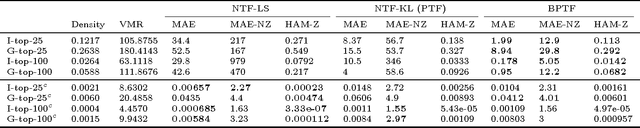
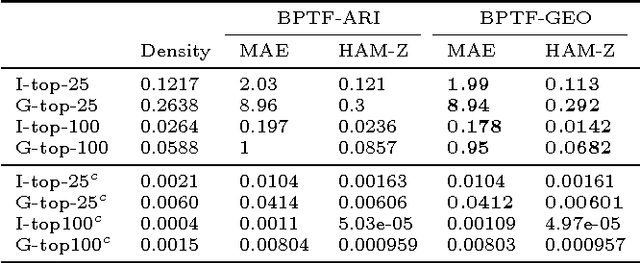
We present a Bayesian tensor factorization model for inferring latent group structures from dynamic pairwise interaction patterns. For decades, political scientists have collected and analyzed records of the form "country $i$ took action $a$ toward country $j$ at time $t$"---known as dyadic events---in order to form and test theories of international relations. We represent these event data as a tensor of counts and develop Bayesian Poisson tensor factorization to infer a low-dimensional, interpretable representation of their salient patterns. We demonstrate that our model's predictive performance is better than that of standard non-negative tensor factorization methods. We also provide a comparison of our variational updates to their maximum likelihood counterparts. In doing so, we identify a better way to form point estimates of the latent factors than that typically used in Bayesian Poisson matrix factorization. Finally, we showcase our model as an exploratory analysis tool for political scientists. We show that the inferred latent factor matrices capture interpretable multilateral relations that both conform to and inform our knowledge of international affairs.
Stochastic Annealing for Variational Inference
May 25, 2015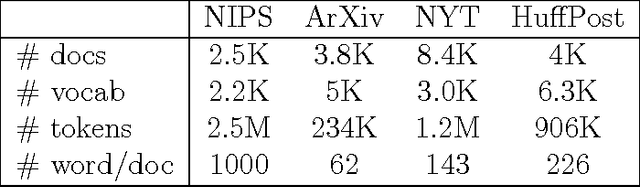
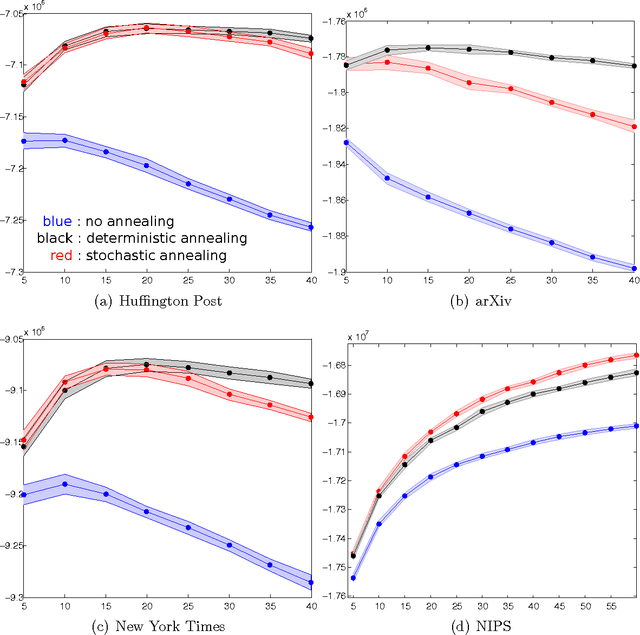
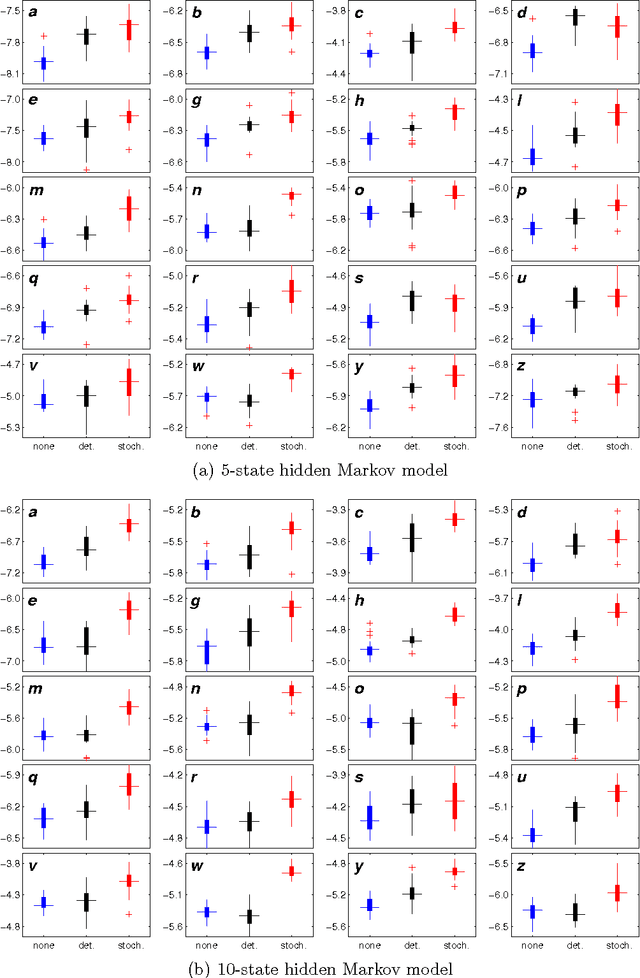
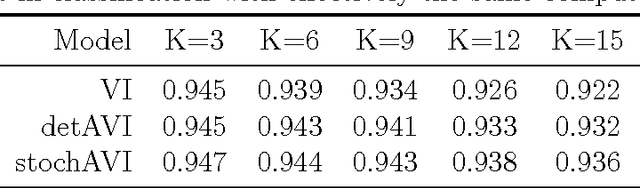
We empirically evaluate a stochastic annealing strategy for Bayesian posterior optimization with variational inference. Variational inference is a deterministic approach to approximate posterior inference in Bayesian models in which a typically non-convex objective function is locally optimized over the parameters of the approximating distribution. We investigate an annealing method for optimizing this objective with the aim of finding a better local optimal solution and compare with deterministic annealing methods and no annealing. We show that stochastic annealing can provide clear improvement on the GMM and HMM, while performance on LDA tends to favor deterministic annealing methods.