 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Adaptation to Classifiers: A Causal Perspective
Nov 01, 2019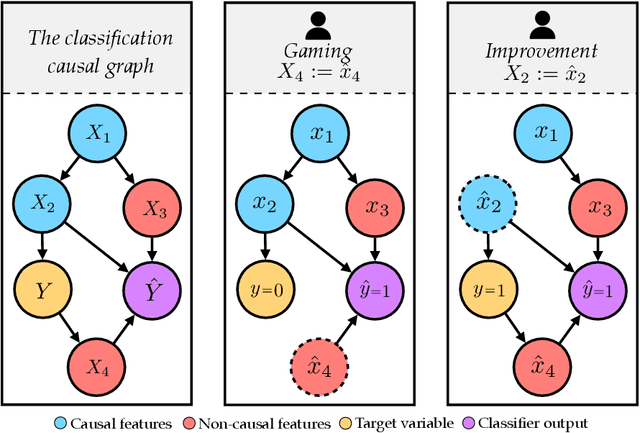
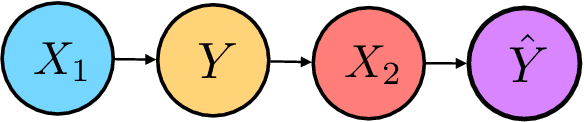
Consequential decision-making incentivizes individuals to adapt their behavior to the specifics of the decision rule. A long line of work has therefore sought to understand and anticipate adaptation, both to prevent strategic individuals from "gaming" the decision rule and to explicitly motivate individuals to improve. In this work, we frame the problem of adaptation as performing interventions in a causal graph. With this causal perspective, we make several contributions. First, we articulate a formal distinction between gaming and improvement. Second, we formalize strategic classification in a new way that recognizes that the individual may improve, rather than only game. In this setting, we show that it is beneficial for the decision-maker to incentivize improvement. Third, we give a reduction from causal inference to designing incentivizes for improvement. This shows that designing good incentives, while desirable, is at least as hard as causal inference.
Test-Time Training for Out-of-Distribution Generalization
Oct 25, 2019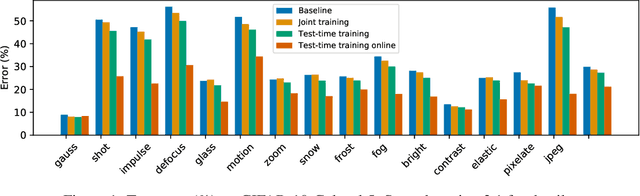
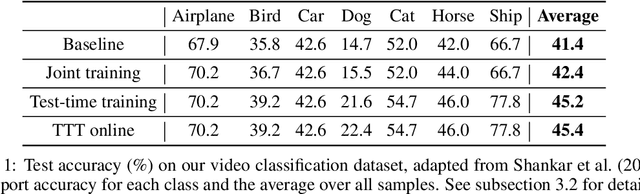
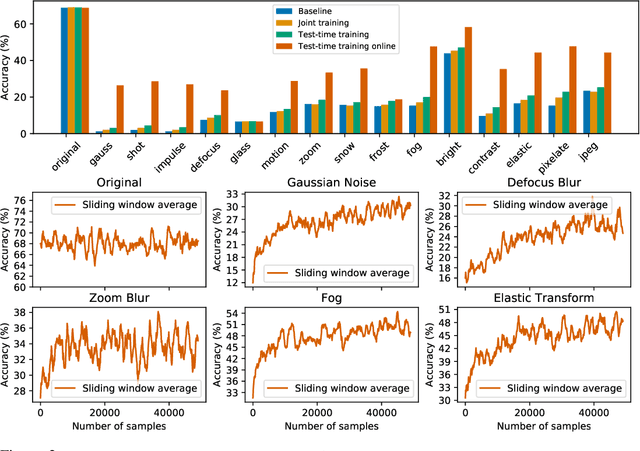
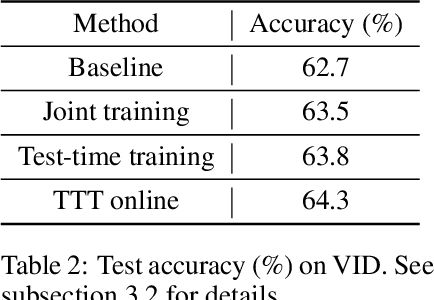
We introduce a general approach, called test-time training, for improving the performance of predictive models when test and training data come from different distributions. Test-time training turns a single unlabeled test instance into a self-supervised learning problem, on which we update the model parameters before making a prediction on this instance. We show that this simple idea leads to surprising improvements on diverse image classification benchmarks aimed at evaluating robustness to distribution shifts. Theoretical investigations on a convex model reveal helpful intuitions for when we can expect our approach to help.
Model Similarity Mitigates Test Set Overuse
May 29, 2019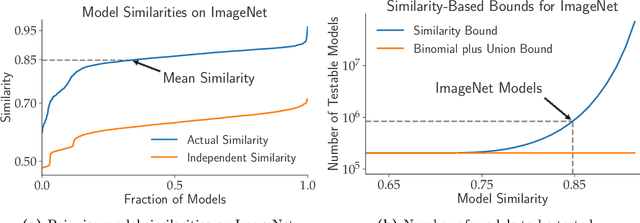
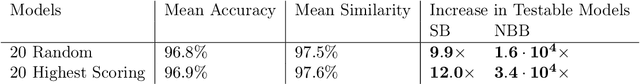
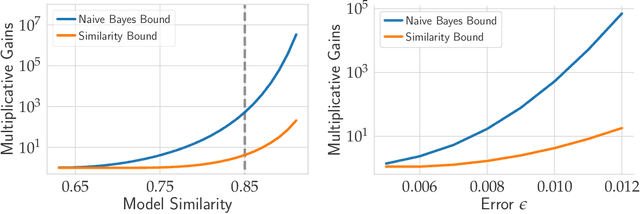
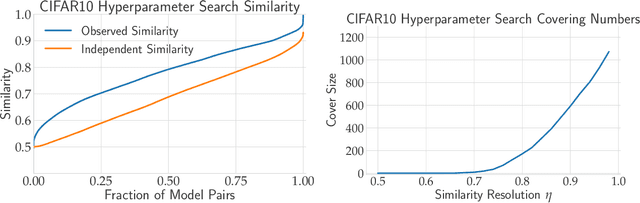
Excessive reuse of test data has become commonplace in today's machine learning workflows. Popular benchmarks, competitions, industrial scale tuning, among other applications, all involve test data reuse beyond guidance by statistical confidence bounds. Nonetheless, recent replication studies give evidence that popular benchmarks continue to support progress despite years of extensive reuse. We proffer a new explanation for the apparent longevity of test data: Many proposed models are similar in their predictions and we prove that this similarity mitigates overfitting. Specifically, we show empirically that models proposed for the ImageNet ILSVRC benchmark agree in their predictions well beyond what we can conclude from their accuracy levels alone. Likewise, models created by large scale hyperparameter search enjoy high levels of similarity. Motivated by these empirical observations, we give a non-asymptotic generalization bound that takes similarity into account, leading to meaningful confidence bounds in practical settings.
The Social Cost of Strategic Classification
Aug 25, 2018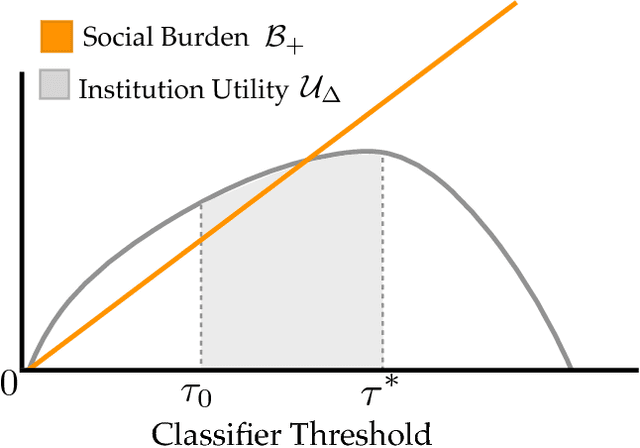
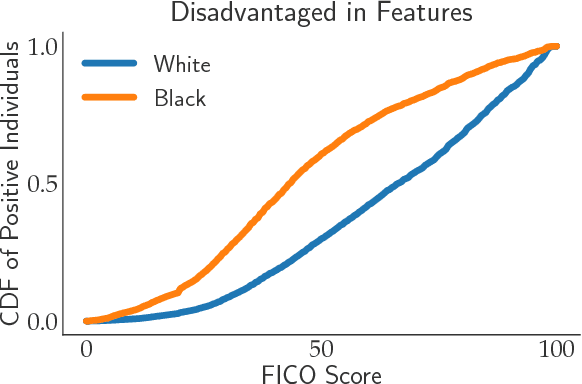
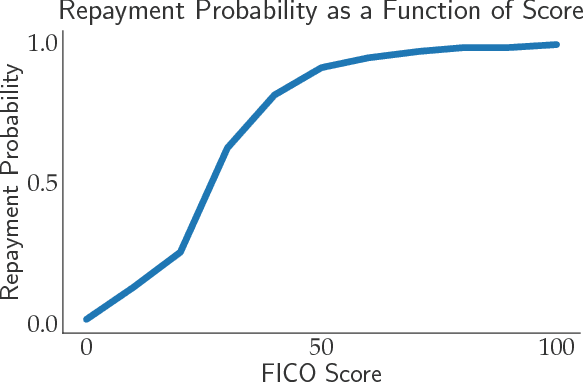
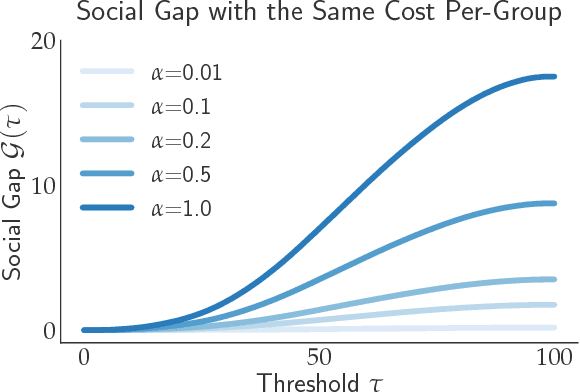
Consequential decision-making typically incentivizes individuals to behave strategically, tailoring their behavior to the specifics of the decision rule. A long line of work has therefore sought to counteract strategic behavior by designing more conservative decision boundaries in an effort to increase robustness to the effects of strategic covariate shift. We show that these efforts benefit the institutional decision maker at the expense of the individuals being classified. Introducing a notion of social burden, we prove that any increase in institutional utility necessarily leads to a corresponding increase in social burden. Moreover, we show that the negative externalities of strategic classification can disproportionately harm disadvantaged groups in the population. Our results highlight that strategy-robustness must be weighed against considerations of social welfare and fairness.
When Recurrent Models Don't Need To Be Recurrent
May 29, 2018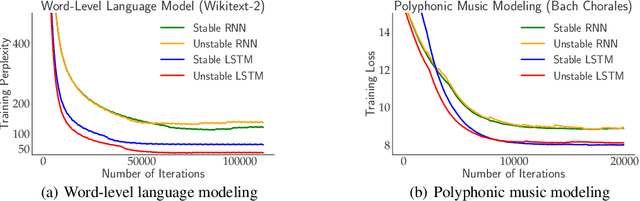
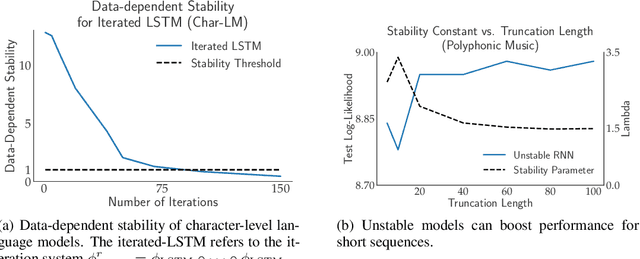
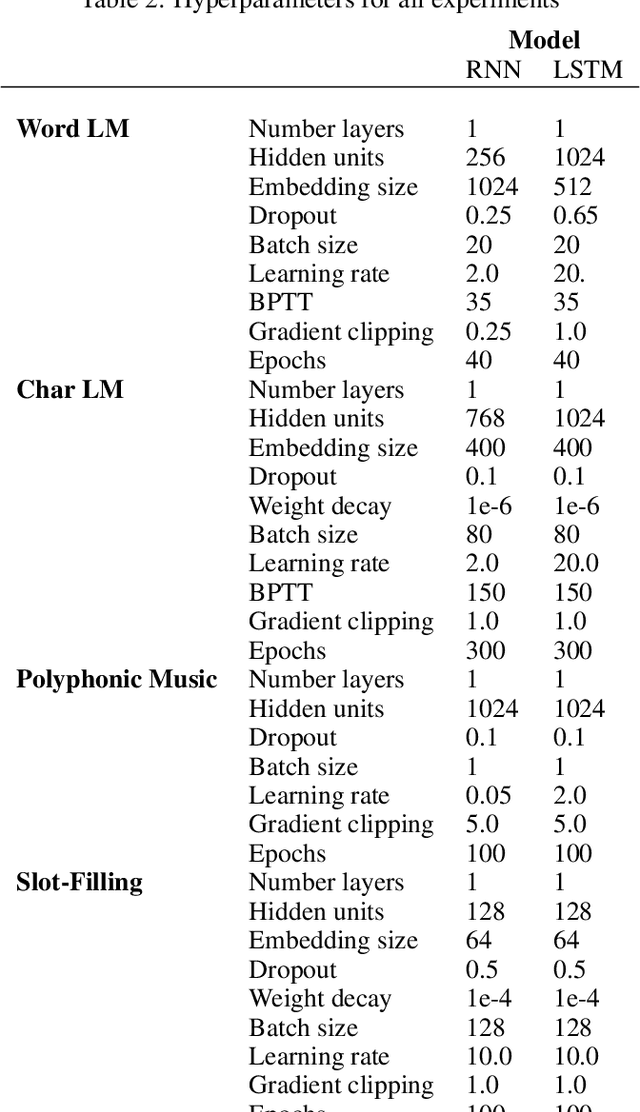
We prove stable recurrent neural networks are well approximated by feed-forward networks for the purpose of both inference and training by gradient descent. Our result applies to a broad range of non-linear recurrent neural networks under a natural stability condition, which we observe is also necessary. Complementing our theoretical findings, we verify the conclusions of our theory on both real and synthetic tasks. Furthermore, we demonstrate recurrent models satisfying the stability assumption of our theory can have excellent performance on real sequence learning tasks.
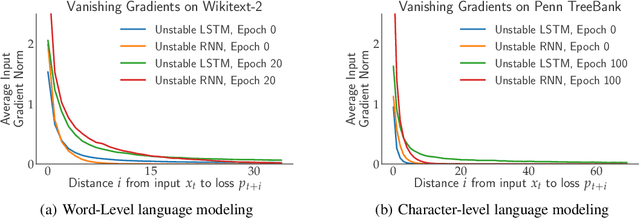
Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning
Feb 22, 2018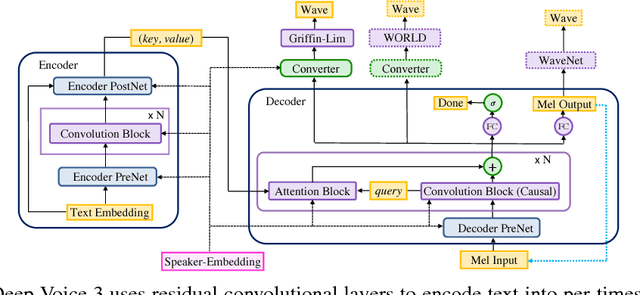

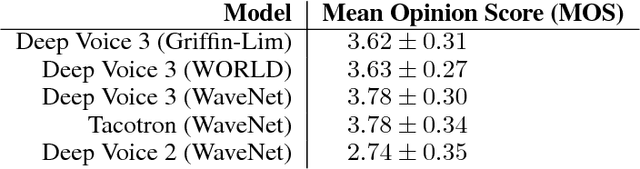
We present Deep Voice 3, a fully-convolutional attention-based neural text-to-speech (TTS) system. Deep Voice 3 matches state-of-the-art neural speech synthesis systems in naturalness while training ten times faster. We scale Deep Voice 3 to data set sizes unprecedented for TTS, training on more than eight hundred hours of audio from over two thousand speakers. In addition, we identify common error modes of attention-based speech synthesis networks, demonstrate how to mitigate them, and compare several different waveform synthesis methods. We also describe how to scale inference to ten million queries per day on one single-GPU server.
Deep Voice 2: Multi-Speaker Neural Text-to-Speech
Sep 20, 2017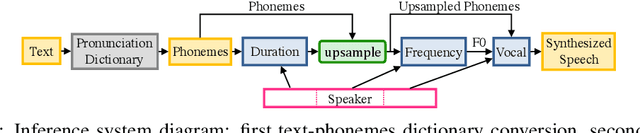
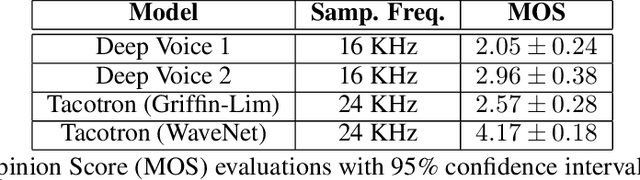
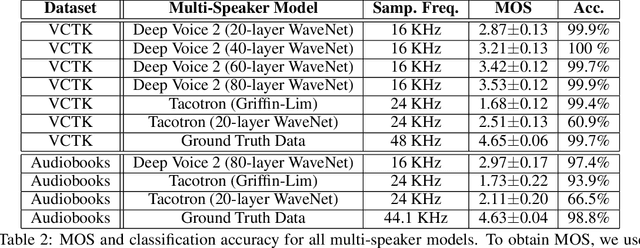
We introduce a technique for augmenting neural text-to-speech (TTS) with lowdimensional trainable speaker embeddings to generate different voices from a single model. As a starting point, we show improvements over the two state-ofthe-art approaches for single-speaker neural TTS: Deep Voice 1 and Tacotron. We introduce Deep Voice 2, which is based on a similar pipeline with Deep Voice 1, but constructed with higher performance building blocks and demonstrates a significant audio quality improvement over Deep Voice 1. We improve Tacotron by introducing a post-processing neural vocoder, and demonstrate a significant audio quality improvement. We then demonstrate our technique for multi-speaker speech synthesis for both Deep Voice 2 and Tacotron on two multi-speaker TTS datasets. We show that a single neural TTS system can learn hundreds of unique voices from less than half an hour of data per speaker, while achieving high audio quality synthesis and preserving the speaker identities almost perfectly.
Globally Normalized Reader
Sep 08, 2017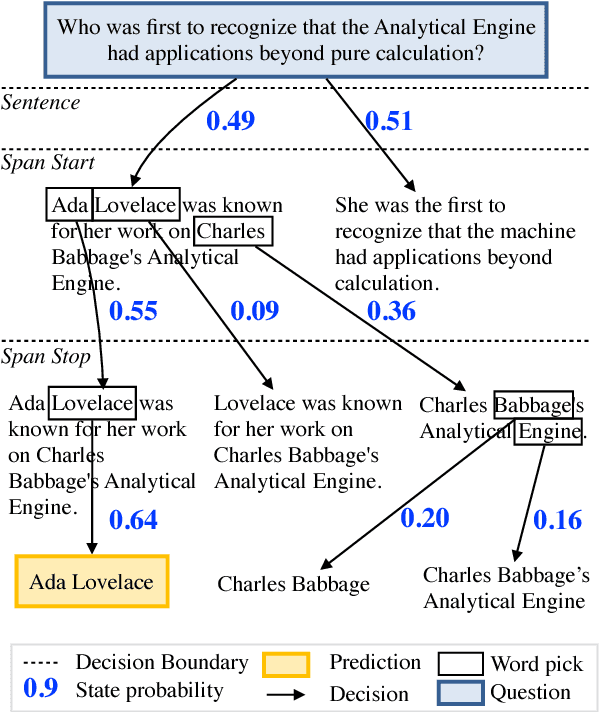
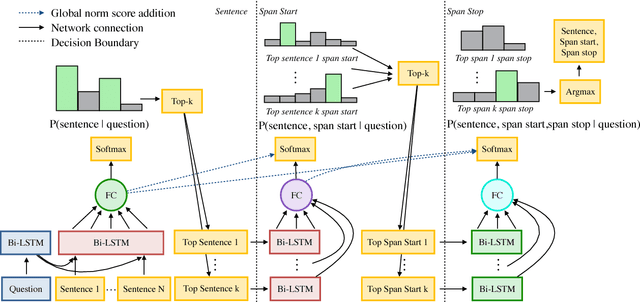
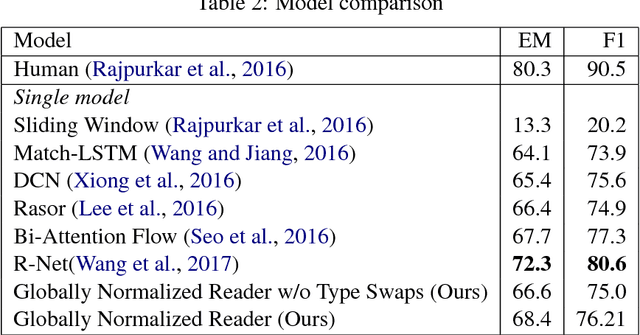
Rapid progress has been made towards question answering (QA) systems that can extract answers from text. Existing neural approaches make use of expensive bi-directional attention mechanisms or score all possible answer spans, limiting scalability. We propose instead to cast extractive QA as an iterative search problem: select the answer's sentence, start word, and end word. This representation reduces the space of each search step and allows computation to be conditionally allocated to promising search paths. We show that globally normalizing the decision process and back-propagating through beam search makes this representation viable and learning efficient. We empirically demonstrate the benefits of this approach using our model, Globally Normalized Reader (GNR), which achieves the second highest single model performance on the Stanford Question Answering Dataset (68.4 EM, 76.21 F1 dev) and is 24.7x faster than bi-attention-flow. We also introduce a data-augmentation method to produce semantically valid examples by aligning named entities to a knowledge base and swapping them with new entities of the same type. This method improves the performance of all models considered in this work and is of independent interest for a variety of NLP tasks.
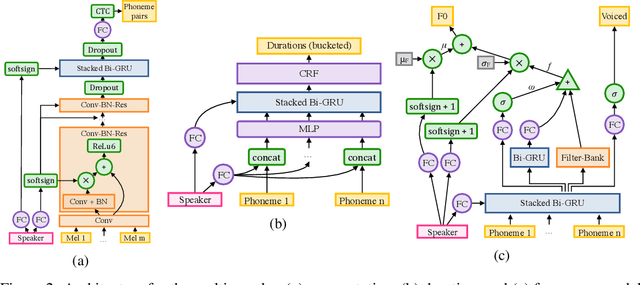
Deep Voice: Real-time Neural Text-to-Speech
Mar 07, 2017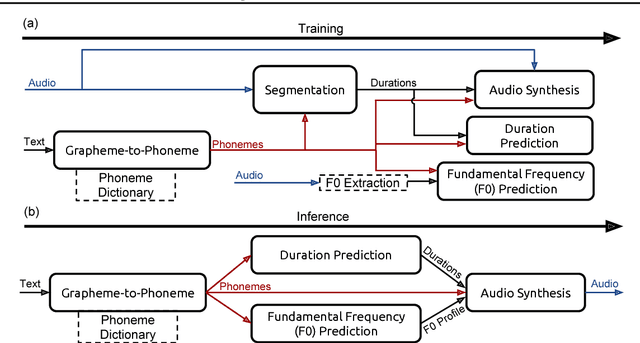
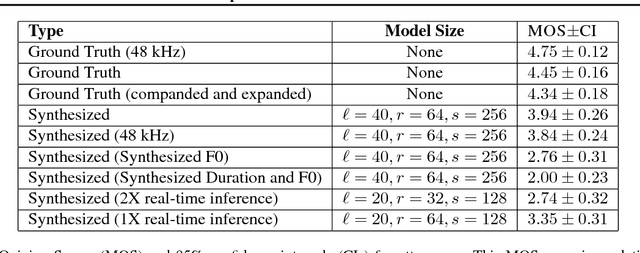
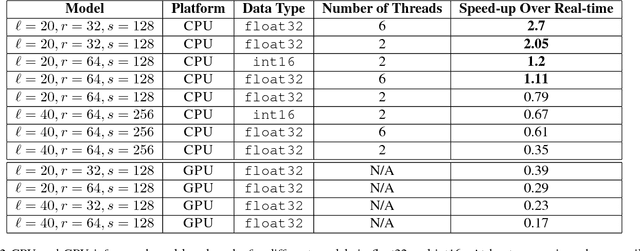
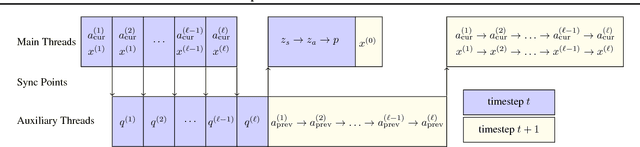
We present Deep Voice, a production-quality text-to-speech system constructed entirely from deep neural networks. Deep Voice lays the groundwork for truly end-to-end neural speech synthesis. The system comprises five major building blocks: a segmentation model for locating phoneme boundaries, a grapheme-to-phoneme conversion model, a phoneme duration prediction model, a fundamental frequency prediction model, and an audio synthesis model. For the segmentation model, we propose a novel way of performing phoneme boundary detection with deep neural networks using connectionist temporal classification (CTC) loss. For the audio synthesis model, we implement a variant of WaveNet that requires fewer parameters and trains faster than the original. By using a neural network for each component, our system is simpler and more flexible than traditional text-to-speech systems, where each component requires laborious feature engineering and extensive domain expertise. Finally, we show that inference with our system can be performed faster than real time and describe optimized WaveNet inference kernels on both CPU and GPU that achieve up to 400x speedups over existing implementations.
Traversing Knowledge Graphs in Vector Space
Aug 19, 2015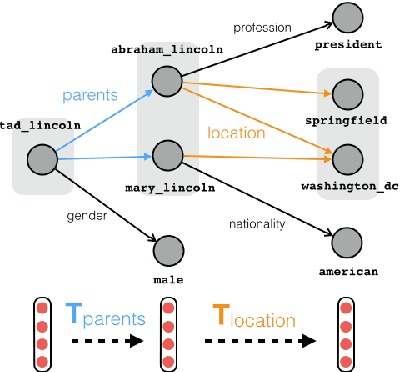
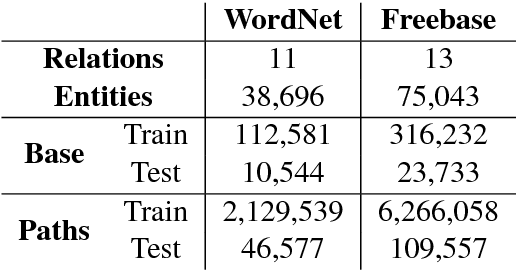
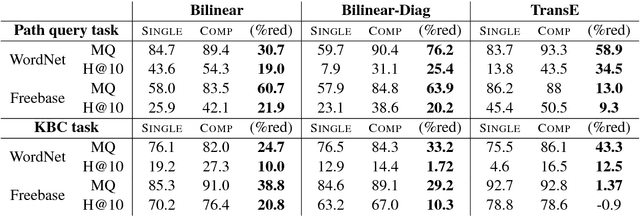
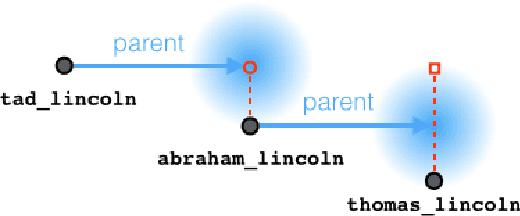
Path queries on a knowledge graph can be used to answer compositional questions such as "What languages are spoken by people living in Lisbon?". However, knowledge graphs often have missing facts (edges) which disrupts path queries. Recent models for knowledge base completion impute missing facts by embedding knowledge graphs in vector spaces. We show that these models can be recursively applied to answer path queries, but that they suffer from cascading errors. This motivates a new "compositional" training objective, which dramatically improves all models' ability to answer path queries, in some cases more than doubling accuracy. On a standard knowledge base completion task, we also demonstrate that compositional training acts as a novel form of structural regularization, reliably improving performance across all base models (reducing errors by up to 43%) and achieving new state-of-the-art results.