 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixRep: Hidden Representation Mixup for Low-Resource Speech Recognition
Oct 27, 2023



In this paper, we present MixRep, a simple and effective data augmentation strategy based on mixup for low-resource ASR. MixRep interpolates the feature dimensions of hidden representations in the neural network that can be applied to both the acoustic feature input and the output of each layer, which generalizes the previous MixSpeech method. Further, we propose to combine the mixup with a regularization along the time axis of the input, which is shown as complementary. We apply MixRep to a Conformer encoder of an E2E LAS architecture trained with a joint CTC loss. We experiment on the WSJ dataset and subsets of the SWB dataset, covering reading and telephony conversational speech. Experimental results show that MixRep consistently outperforms other regularization methods for low-resource ASR. Compared to a strong SpecAugment baseline, MixRep achieves a +6.5\% and a +6.7\% relative WER reduction on the eval92 set and the Callhome part of the eval'2000 set.
Advanced accent/dialect identification and accentedness assessment with multi-embedding models and automatic speech recognition
Oct 17, 2023Accurately classifying accents and assessing accentedness in non-native speakers are both challenging tasks due to the complexity and diversity of accent and dialect variations. In this study, embeddings from advanced pre-trained language identification (LID) and speaker identification (SID) models are leveraged to improve the accuracy of accent classification and non-native accentedness assessment. Findings demonstrate that employing pre-trained LID and SID models effectively encodes accent/dialect information in speech. Furthermore, the LID and SID encoded accent information complement an end-to-end accent identification (AID) model trained from scratch. By incorporating all three embeddings, the proposed multi-embedding AID system achieves superior accuracy in accent identification. Next, we investigate leveraging automatic speech recognition (ASR) and accent identification models to explore accentedness estimation. The ASR model is an end-to-end connectionist temporal classification (CTC) model trained exclusively with en-US utterances. The ASR error rate and en-US output of the AID model are leveraged as objective accentedness scores. Evaluation results demonstrate a strong correlation between the scores estimated by the two models. Additionally, a robust correlation between the objective accentedness scores and subjective scores based on human perception is demonstrated, providing evidence for the reliability and validity of utilizing AID-based and ASR-based systems for accentedness assessment in non-native speech.
What Can an Accent Identifier Learn? Probing Phonetic and Prosodic Information in a Wav2vec2-based Accent Identification Model
Jun 10, 2023



This study is focused on understanding and quantifying the change in phoneme and prosody information encoded in the Self-Supervised Learning (SSL) model, brought by an accent identification (AID) fine-tuning task. This problem is addressed based on model probing. Specifically, we conduct a systematic layer-wise analysis of the representations of the Transformer layers on a phoneme correlation task, and a novel word-level prosody prediction task. We compare the probing performance of the pre-trained and fine-tuned SSL models. Results show that the AID fine-tuning task steers the top 2 layers to learn richer phoneme and prosody representation. These changes share some similarities with the effects of fine-tuning with an Automatic Speech Recognition task. In addition, we observe strong accent-specific phoneme representations in layer 9. To sum up, this study provides insights into the understanding of SSL features and their interactions with fine-tuning tasks.
Improving Transformer-based Networks With Locality For Automatic Speaker Verification
Feb 28, 2023



Recently, Transformer-based architectures have been explored for speaker embedding extraction. Although the Transformer employs the self-attention mechanism to efficiently model the global interaction between token embeddings, it is inadequate for capturing short-range local context, which is essential for the accurate extraction of speaker information. In this study, we enhance the Transformer with the enhanced locality modeling in two directions. First, we propose the Locality-Enhanced Conformer (LE-Confomer) by introducing depth-wise convolution and channel-wise attention into the Conformer blocks. Second, we present the Speaker Swin Transformer (SST) by adapting the Swin Transformer, originally proposed for vision tasks, into speaker embedding network. We evaluate the proposed approaches on the VoxCeleb datasets and a large-scale Microsoft internal multilingual (MS-internal) dataset. The proposed models achieve 0.75% EER on VoxCeleb 1 test set, outperforming the previously proposed Transformer-based models and CNN-based models, such as ResNet34 and ECAPA-TDNN. When trained on the MS-internal dataset, the proposed models achieve promising results with 14.6% relative reduction in EER over the Res2Net50 model.
Complex-Valued Time-Frequency Self-Attention for Speech Dereverberation
Nov 22, 2022



Several speech processing systems have demonstrated considerable performance improvements when deep complex neural networks (DCNN) are coupled with self-attention (SA) networks. However, the majority of DCNN-based studies on speech dereverberation that employ self-attention do not explicitly account for the inter-dependencies between real and imaginary features when computing attention. In this study, we propose a complex-valued T-F attention (TFA) module that models spectral and temporal dependencies by computing two-dimensional attention maps across time and frequency dimensions. We validate the effectiveness of our proposed complex-valued TFA module with the deep complex convolutional recurrent network (DCCRN) using the REVERB challenge corpus. Experimental findings indicate that integrating our complex-TFA module with DCCRN improves overall speech quality and performance of back-end speech applications, such as automatic speech recognition, compared to earlier approaches for self-attention.
Filterbank Learning for Small-Footprint Keyword Spotting Robust to Noise
Nov 19, 2022



In the context of keyword spotting (KWS), the replacement of handcrafted speech features by learnable features has not yielded superior KWS performance. In this study, we demonstrate that filterbank learning outperforms handcrafted speech features for KWS whenever the number of filterbank channels is severely decreased. Reducing the number of channels might yield certain KWS performance drop, but also a substantial energy consumption reduction, which is key when deploying common always-on KWS on low-resource devices. Experimental results on a noisy version of the Google Speech Commands Dataset show that filterbank learning adapts to noise characteristics to provide a higher degree of robustness to noise, especially when dropout is integrated. Thus, switching from typically used 40-channel log-Mel features to 8-channel learned features leads to a relative KWS accuracy loss of only 3.5% while simultaneously achieving a 6.3x energy consumption reduction.
Audio Anti-spoofing Using a Simple Attention Module and Joint Optimization Based on Additive Angular Margin Loss and Meta-learning
Nov 17, 2022Automatic speaker verification systems are vulnerable to a variety of access threats, prompting research into the formulation of effective spoofing detection systems to act as a gate to filter out such spoofing attacks. This study introduces a simple attention module to infer 3-dim attention weights for the feature map in a convolutional layer, which then optimizes an energy function to determine each neuron's importance. With the advancement of both voice conversion and speech synthesis technologies, unseen spoofing attacks are constantly emerging to limit spoofing detection system performance. Here, we propose a joint optimization approach based on the weighted additive angular margin loss for binary classification, with a meta-learning training framework to develop an efficient system that is robust to a wide range of spoofing attacks for model generalization enhancement. As a result, when compared to current state-of-the-art systems, our proposed approach delivers a competitive result with a pooled EER of 0.99% and min t-DCF of 0.0289.
Multi-source Domain Adaptation for Text-independent Forensic Speaker Recognition
Nov 17, 2022Adapting speaker recognition systems to new environments is a widely-used technique to improve a well-performing model learned from large-scale data towards a task-specific small-scale data scenarios. However, previous studies focus on single domain adaptation, which neglects a more practical scenario where training data are collected from multiple acoustic domains needed in forensic scenarios. Audio analysis for forensic speaker recognition offers unique challenges in model training with multi-domain training data due to location/scenario uncertainty and diversity mismatch between reference and naturalistic field recordings. It is also difficult to directly employ small-scale domain-specific data to train complex neural network architectures due to domain mismatch and performance loss. Fine-tuning is a commonly-used method for adaptation in order to retrain the model with weights initialized from a well-trained model. Alternatively, in this study, three novel adaptation methods based on domain adversarial training, discrepancy minimization, and moment-matching approaches are proposed to further promote adaptation performance across multiple acoustic domains. A comprehensive set of experiments are conducted to demonstrate that: 1) diverse acoustic environments do impact speaker recognition performance, which could advance research in audio forensics, 2) domain adversarial training learns the discriminative features which are also invariant to shifts between domains, 3) discrepancy-minimizing adaptation achieves effective performance simultaneously across multiple acoustic domains, and 4) moment-matching adaptation along with dynamic distribution alignment also significantly promotes speaker recognition performance on each domain, especially for the LENA-field domain with noise compared to all other systems.
Fearless Steps Challenge Phase-1 Evaluation Plan
Nov 03, 2022The Fearless Steps Challenge 2019 Phase-1 (FSC-P1) is the inaugural Challenge of the Fearless Steps Initiative hosted by the Center for Robust Speech Systems (CRSS) at the University of Texas at Dallas. The goal of this Challenge is to evaluate the performance of state-of-the-art speech and language systems for large task-oriented teams with naturalistic audio in challenging environments. Researchers may select to participate in any single or multiple of these challenge tasks. Researchers may also choose to employ the FEARLESS STEPS corpus for other related speech applications. All participants are encouraged to submit their solutions and results for consideration in the ISCA INTERSPEECH-2019 special session.
Learning ASR pathways: A sparse multilingual ASR model
Sep 13, 2022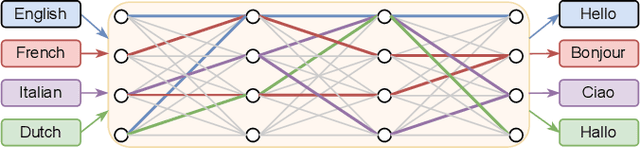
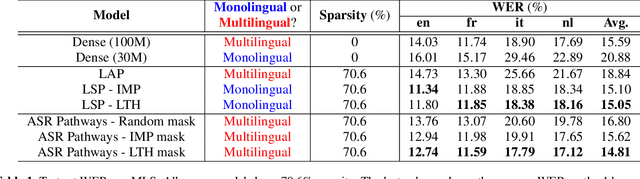
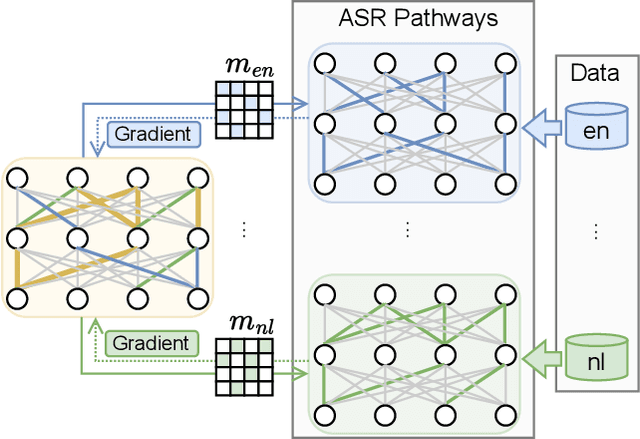
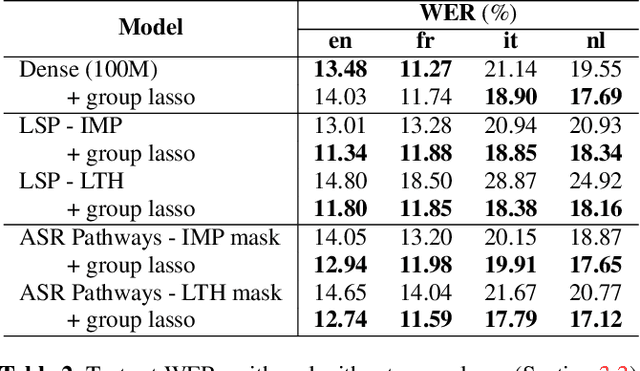
Neural network pruning can be effectively applied to compress automatic speech recognition (ASR) models. However, in multilingual ASR, performing language-agnostic pruning may lead to severe performance degradation on some languages because language-agnostic pruning masks may not fit all languages and discard important language-specific parameters. In this work, we present ASR pathways, a sparse multilingual ASR model that activates language-specific sub-networks ("pathways"), such that the parameters for each language are learned explicitly. With the overlapping sub-networks, the shared parameters can also enable knowledge transfer for lower resource languages via joint multilingual training. We propose a novel algorithm to learn ASR pathways, and evaluate the proposed method on 4 languages with a streaming RNN-T model. Our proposed ASR pathways outperform both dense models (-5.0% average WER) and a language-agnostically pruned model (-21.4% average WER), and provide better performance on low-resource languages compared to the monolingual sparse models.