 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centric Autonomous Systems With LLMs for User Command Reasoning
Nov 14, 2023The evolution of autonomous driving has made remarkable advancements in recent years, evolving into a tangible reality. However, a human-centric large-scale adoption hinges on meeting a variety of multifaceted requirements. To ensure that the autonomous system meets the user's intent, it is essential to accurately discern and interpret user commands, especially in complex or emergency situations. To this end, we propose to leverage the reasoning capabilities of Large Language Models (LLMs) to infer system requirements from in-cabin users' commands. Through a series of experiments that include different LLM models and prompt designs, we explore the few-shot multivariate binary classification accuracy of system requirements from natural language textual commands. We confirm the general ability of LLMs to understand and reason about prompts but underline that their effectiveness is conditioned on the quality of both the LLM model and the design of appropriate sequential prompts. Code and models are public with the link \url{https://github.com/KTH-RPL/DriveCmd_LLM}.
RMP: A Random Mask Pretrain Framework for Motion Prediction
Sep 16, 2023



As the pretraining technique is growing in popularity, little work has been done on pretrained learning-based motion prediction methods in autonomous driving. In this paper, we propose a framework to formalize the pretraining task for trajectory prediction of traffic participants. Within our framework, inspired by the random masked model in natural language processing (NLP) and computer vision (CV), objects' positions at random timesteps are masked and then filled in by the learned neural network (NN). By changing the mask profile, our framework can easily switch among a range of motion-related tasks. We show that our proposed pretraining framework is able to deal with noisy inputs and improves the motion prediction accuracy and miss rate, especially for objects occluded over time by evaluating it on Argoverse and NuScenes datasets.
Simultaneous Trajectory Estimation and Mapping for Autonomous Underwater Proximity Operations
Sep 15, 2023



Due to the challenges regarding the limits of their endurance and autonomous capabilities, underwater docking for autonomous underwater vehicles (AUVs) has become a topic of interest for many academic and commercial applications. Herein, we take on the problem of state estimation during an autonomous underwater docking mission. Docking operations typically involve only two actors, a chaser and a target. We leverage the similarities to proximity operations (prox-ops) from spacecraft robotic missions to frame the diverse docking scenarios with a set of phases the chaser undergoes on the way to its target. We use factor graphs to generalize the underlying estimation problem for arbitrary underwater prox-ops. To showcase our framework, we use this factor graph approach to model an underwater homing scenario with an active target as a Simultaneous Localization and Mapping problem. Using basic AUV navigation sensors, relative Ultra-short Baseline measurements, and the assumption of constant dynamics for the target, we derive factors that constrain the chaser's state and the position and trajectory of the target. We detail our front- and back-end software implementation using open-source software and libraries, and verify its performance with both simulated and field experiments. Obtained results show an overall increase in performance against the unprocessed measurements, regardless of the presence of an adversarial target whose dynamics void the modeled assumptions. However, challenges with unmodeled noise parameters and stringent target motion assumptions shed light on limitations that must be addressed to enhance the accuracy and consistency of the proposed approach.
Evaluation of a Canonical Image Representation for Sidescan Sonar
Apr 18, 2023



Acoustic sensors play an important role in autonomous underwater vehicles (AUVs). Sidescan sonar (SSS) detects a wide range and provides photo-realistic images in high resolution. However, SSS projects the 3D seafloor to 2D images, which are distorted by the AUV's altitude, target's range and sensor's resolution. As a result, the same physical area can show significant visual differences in SSS images from different survey lines, causing difficulties in tasks such as pixel correspondence and template matching. In this paper, a canonical transformation method consisting of intensity correction and slant range correction is proposed to decrease the above distortion. The intensity correction includes beam pattern correction and incident angle correction using three different Lambertian laws (cos, cos2, cot), whereas the slant range correction removes the nadir zone and projects the position of SSS elements into equally horizontally spaced, view-point independent bins. The proposed method is evaluated on real data collected by a HUGIN AUV, with manually-annotated pixel correspondence as ground truth reference. Experimental results on patch pairs compare similarity measures and keypoint descriptor matching. The results show that the canonical transformation can improve the patch similarity, as well as SIFT descriptor matching accuracy in different images where the same physical area was ensonified.
A Fully-automatic Side-scan Sonar SLAM Framework
Apr 04, 2023



Side-scan sonar (SSS) is a lightweight acoustic sensor that is frequently deployed on autonomous underwater vehicles (AUV) to provide high-resolution seafloor image. However, using side-scan images to perform simultaneous localization and mapping (SLAM) remains a challenge due to lack of 3D bathymetric information and the lack of discriminant features in the sidescan images. To tackle this, we propose a feature-based SLAM framework using side-scan sonar, which is able to automatically detect and robustly match keypoints between paired side-scan images. We then use the detected correspondences as constraints to optimize the AUV pose trajectory. The proposed method is evaluated on real data collected by a Hugin AUV, using as a ground truth reference both manually-annotated keypoints and a 3D bathymetry mesh from multibeam echosounder (MBES). Experimental results demonstrate that our approach is able to reduce drifts compared to the dead-reckoning system. The framework is made publicly available for the benefit of the community.
Online Stochastic Variational Gaussian Process Mapping for Large-Scale SLAM in Real Time
Nov 10, 2022Autonomous underwater vehicles (AUVs) are becoming standard tools for underwater exploration and seabed mapping in both scientific and industrial applications \cite{graham2022rapid, stenius2022system}. Their capacity to dive untethered allows them to reach areas inaccessible to surface vessels and to collect data more closely to the seafloor, regardless of the water depth. However, their navigation autonomy remains bounded by the accuracy of their dead reckoning (DR) estimate of their global position, severely limited in the absence of a priori maps of the area and GPS signal. Global localization systems equivalent to the later exists for the underwater domain, such as LBL or USBL. However they involve expensive external infrastructure and their reliability decreases with the distance to the AUV, making them unsuitable for deep sea surveys.
Data-driven Loop Closure Detection in Bathymetric Point Clouds for Underwater SLAM
Sep 18, 2022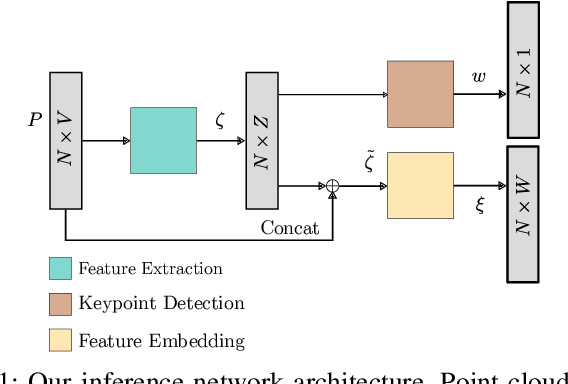
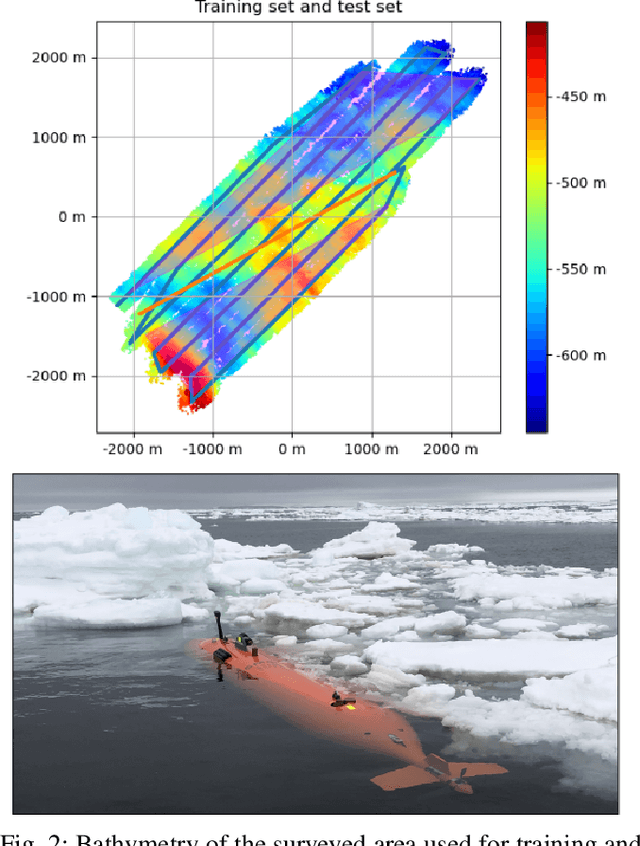
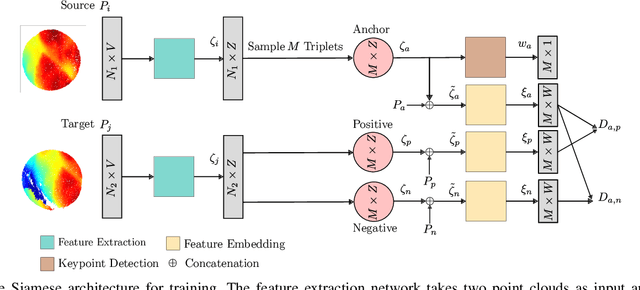
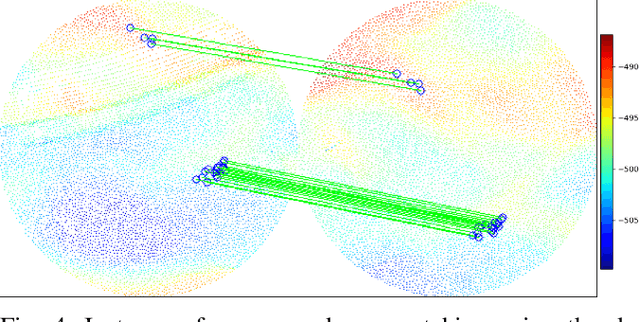
Simultaneous localization and mapping (SLAM) frameworks for autonomous navigation rely on robust data association to identify loop closures for back-end trajectory optimization. In the case of autonomous underwater vehicles (AUVs) equipped with multibeam echosounders (MBES), data association is particularly challenging due to the scarcity of identifiable landmarks in the seabed, the large drift in dead-reckoning navigation estimates to which AUVs are prone and the low resolution characteristic of MBES data. Deep learning solutions to loop closure detection have shown excellent performance on data from more structured environments. However, their transfer to the seabed domain is not immediate and efforts to port them are hindered by the lack of bathymetric datasets. Thus, in this paper we propose a neural network architecture aimed to showcase the potential of adapting such techniques to correspondence matching in bathymetric data. We train our framework on real bathymetry from an AUV mission and evaluate its performance on the tasks of loop closure detection and coarse point cloud alignment. Finally, we show its potential against a more traditional method and release both its implementation and the dataset used.
Neural Shape-from-Shading for Survey-Scale Self-Consistent Bathymetry from Sidescan
Jun 18, 2022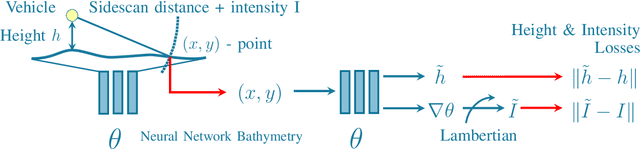

Sidescan sonar is a small and cost-effective sensing solution that can be easily mounted on most vessels. Historically, it has been used to produce high-definition images that experts may use to identify targets on the seafloor or in the water column. While solutions have been proposed to produce bathymetry solely from sidescan, or in conjunction with multibeam, they have had limited impact. This is partly a result of mostly being limited to single sidescan lines. In this paper, we propose a modern, salable solution to create high quality survey-scale bathymetry from many sidescan lines. By incorporating multiple observations of the same place, results can be improved as the estimates reinforce each other. Our method is based on sinusoidal representation networks, a recent advance in neural representation learning. We demonstrate the scalability of the approach by producing bathymetry from a large sidescan survey. The resulting quality is demonstrated by comparing to data collected with a high-precision multibeam sensor.
Towards Differentiable Rendering for Sidescan Sonar Imagery
Jun 15, 2022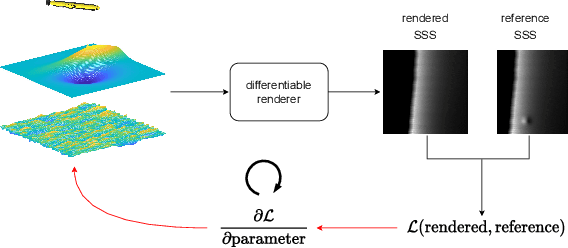
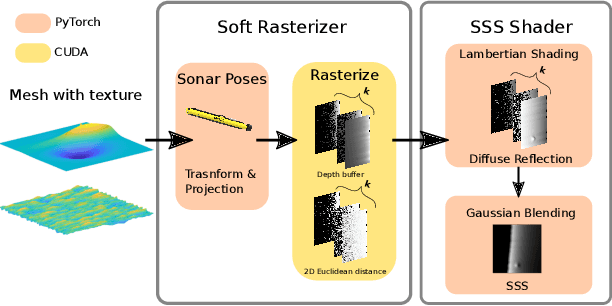
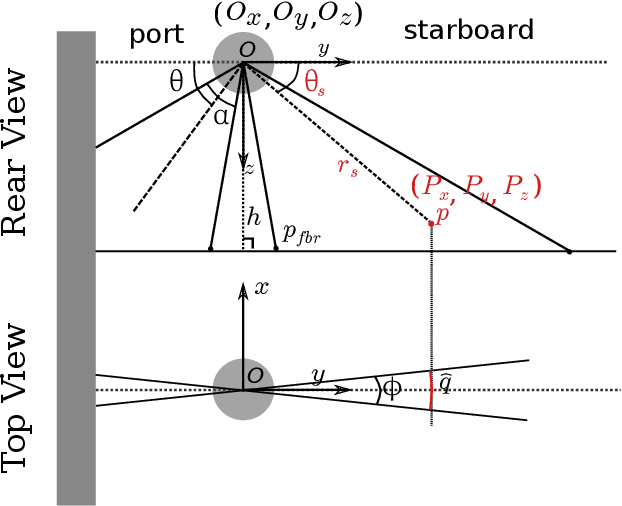
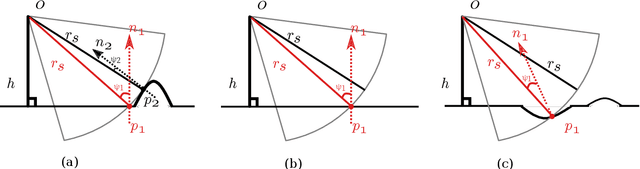
Recent advances in differentiable rendering, which allow calculating the gradients of 2D pixel values with respect to 3D object models, can be applied to estimation of the model parameters by gradient-based optimization with only 2D supervision. It is easy to incorporate deep neural networks into such an optimization pipeline, allowing the leveraging of deep learning techniques. This also largely reduces the requirement for collecting and annotating 3D data, which is very difficult for applications, for example when constructing geometry from 2D sensors. In this work, we propose a differentiable renderer for sidescan sonar imagery. We further demonstrate its ability to solve the inverse problem of directly reconstructing a 3D seafloor mesh from only 2D sidescan sonar data.
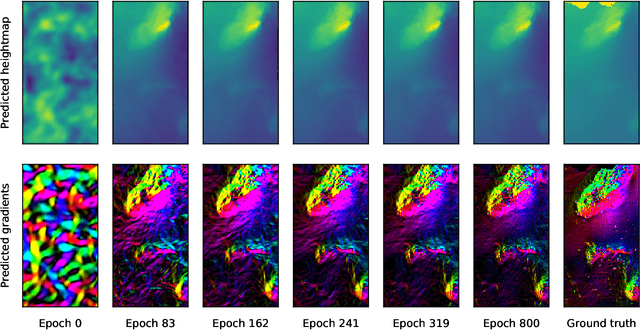
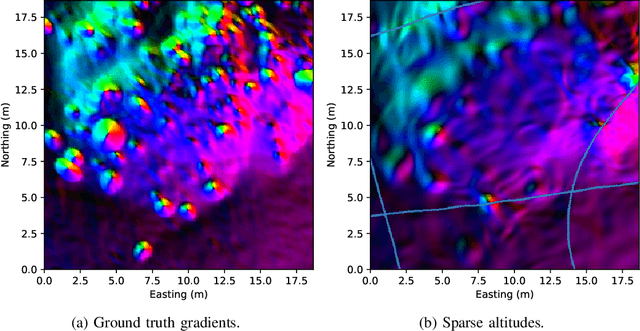
Neural Network Normal Estimation and Bathymetry Reconstruction from Sidescan Sonar
Jun 15, 2022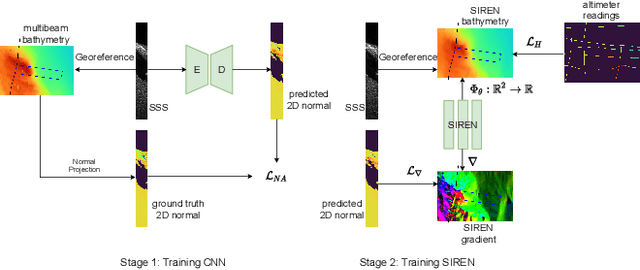
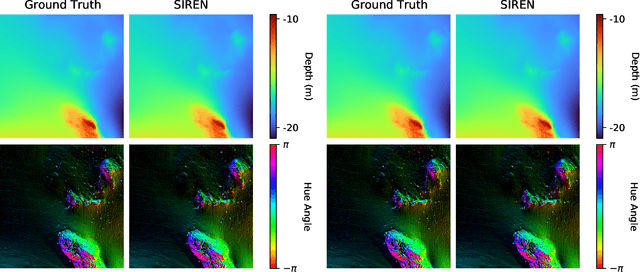
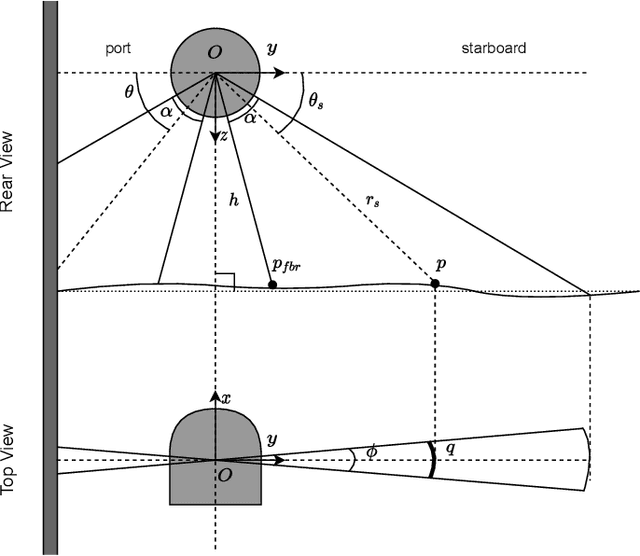
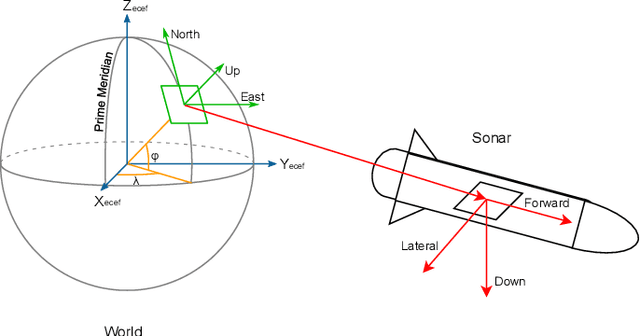
Sidescan sonar intensity encodes information about the changes of surface normal of the seabed. However, other factors such as seabed geometry as well as its material composition also affect the return intensity. One can model these intensity changes in a forward direction from the surface normals from bathymetric map and physical properties to the measured intensity or alternatively one can use an inverse model which starts from the intensities and models the surface normals. Here we use an inverse model which leverages deep learning's ability to learn from data; a convolutional neural network is used to estimate the surface normal from the sidescan. Thus the internal properties of the seabed are only implicitly learned. Once this information is estimated, a bathymetric map can be reconstructed through an optimization framework that also includes altimeter readings to provide a sparse depth profile as a constraint. Implicit neural representation learning was recently proposed to represent the bathymetric map in such an optimization framework. In this article, we use a neural network to represent the map and optimize it under constraints of altimeter points and estimated surface normal from sidescan. By fusing multiple observations from different angles from several sidescan lines, the estimated results are improved through optimization. We demonstrate the efficiency and scalability of the approach by reconstructing a high-quality bathymetry using sidescan data from a large sidescan survey. We compare the proposed data-driven inverse model approach of modeling a sidescan with a forward Lambertian model. We assess the quality of each reconstruction by comparing it with data constructed from a multibeam sensor. We are thus able to discuss the strengths and weaknesses of each approach.