 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Graph-Tokenizing Large Language Models with Reconstructive Graph Instruction Tuning
Mar 02, 2026The remarkable success of large language models (LLMs) has motivated researchers to adapt them as universal predictors for various graph-related tasks, with the ultimate goal of developing a graph foundation model that generalizes diverse scenarios. The key challenge is to align graph data with language spaces so that LLMs can better comprehend graphs. As a popular paradigm, Graph-Tokenizing LLMs (GTokenLLMs) encode complex structures and lengthy texts into a graph token sequence, and then align them with text tokens via language instructions tuning. Despite their initial success, our information-theoretic analysis reveals that existing GTokenLLMs rely solely on text supervision from language instructions, which achieve only implicit graph-text alignment, resulting in a text-dominant bias that underutilizes graph context. To overcome this limitation, we first prove that the alignment objective is upper-bounded by the mutual information between the input graphs and their hidden representations in the LLM, which motivates us to improve this upper bound to achieve better alignment. To this end, we further propose a reconstructive graph instruction tuning pipeline, RGLM. Our key idea is to reconstruct the graph information from the LLM's graph token outputs, explicitly incorporating graph supervision to constrain the alignment process. Technically, we embody RGLM by exploring three distinct variants from two complementary perspectives: RGLM-Decoder from the input space; RGLM-Similarizer and RGLM-Denoiser from the latent space. Additionally, we theoretically analyze the alignment effectiveness of each variant. Extensive experiments on various benchmarks and task scenarios validate the effectiveness of the proposed RGLM, paving the way for new directions in GTokenLLMs' alignment research.
Data-driven Loop Closure Detection in Bathymetric Point Clouds for Underwater SLAM
Sep 18, 2022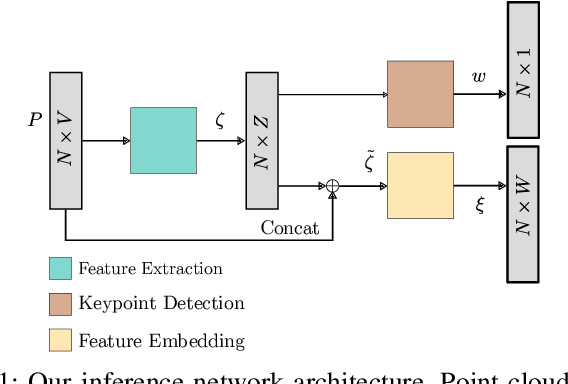
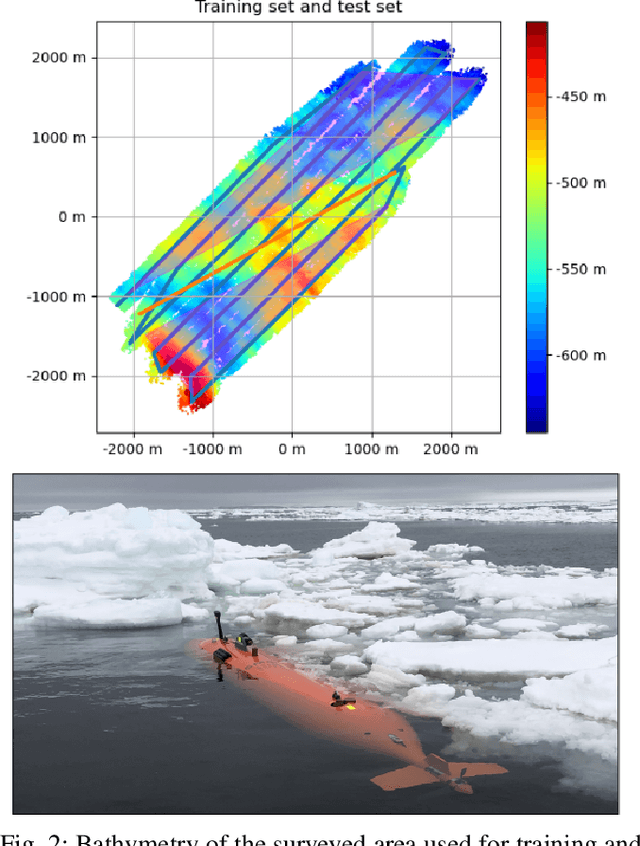
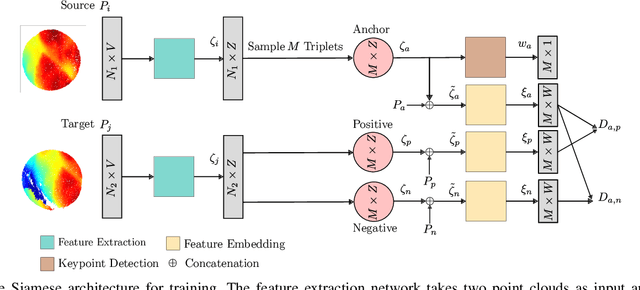
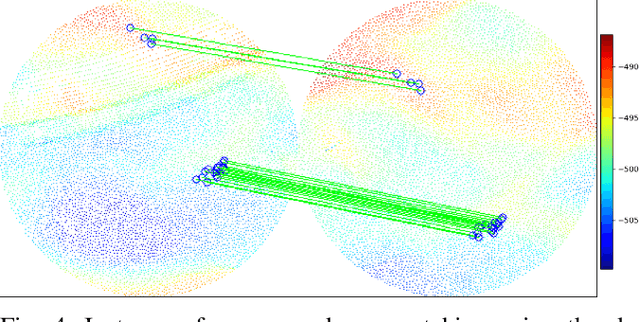
Simultaneous localization and mapping (SLAM) frameworks for autonomous navigation rely on robust data association to identify loop closures for back-end trajectory optimization. In the case of autonomous underwater vehicles (AUVs) equipped with multibeam echosounders (MBES), data association is particularly challenging due to the scarcity of identifiable landmarks in the seabed, the large drift in dead-reckoning navigation estimates to which AUVs are prone and the low resolution characteristic of MBES data. Deep learning solutions to loop closure detection have shown excellent performance on data from more structured environments. However, their transfer to the seabed domain is not immediate and efforts to port them are hindered by the lack of bathymetric datasets. Thus, in this paper we propose a neural network architecture aimed to showcase the potential of adapting such techniques to correspondence matching in bathymetric data. We train our framework on real bathymetry from an AUV mission and evaluate its performance on the tasks of loop closure detection and coarse point cloud alignment. Finally, we show its potential against a more traditional method and release both its implementation and the dataset used.