 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelting Pot 2.0
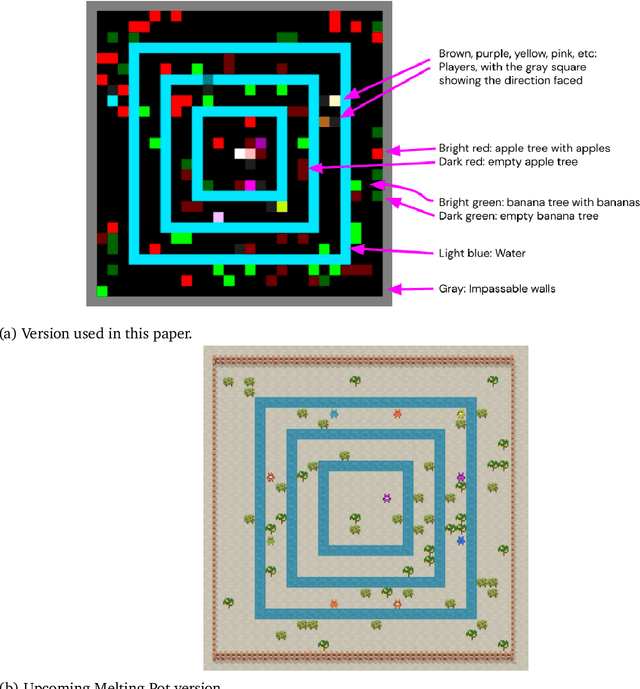
Dec 13, 2022Multi-agent artificial intelligence research promises a path to develop intelligent technologies that are more human-like and more human-compatible than those produced by "solipsistic" approaches, which do not consider interactions between agents. Melting Pot is a research tool developed to facilitate work on multi-agent artificial intelligence, and provides an evaluation protocol that measures generalization to novel social partners in a set of canonical test scenarios. Each scenario pairs a physical environment (a "substrate") with a reference set of co-players (a "background population"), to create a social situation with substantial interdependence between the individuals involved. For instance, some scenarios were inspired by institutional-economics-based accounts of natural resource management and public-good-provision dilemmas. Others were inspired by considerations from evolutionary biology, game theory, and artificial life. Melting Pot aims to cover a maximally diverse set of interdependencies and incentives. It includes the commonly-studied extreme cases of perfectly-competitive (zero-sum) motivations and perfectly-cooperative (shared-reward) motivations, but does not stop with them. As in real-life, a clear majority of scenarios in Melting Pot have mixed incentives. They are neither purely competitive nor purely cooperative and thus demand successful agents be able to navigate the resulting ambiguity. Here we describe Melting Pot 2.0, which revises and expands on Melting Pot. We also introduce support for scenarios with asymmetric roles, and explain how to integrate them into the evaluation protocol. This report also contains: (1) details of all substrates and scenarios; (2) a complete description of all baseline algorithms and results. Our intention is for it to serve as a reference for researchers using Melting Pot 2.0.
The emergence of division of labor through decentralized social sanctioning
Aug 12, 2022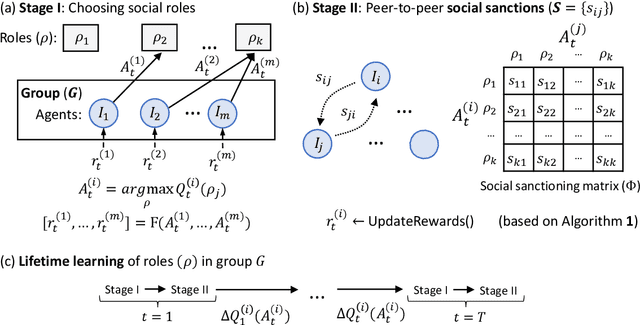

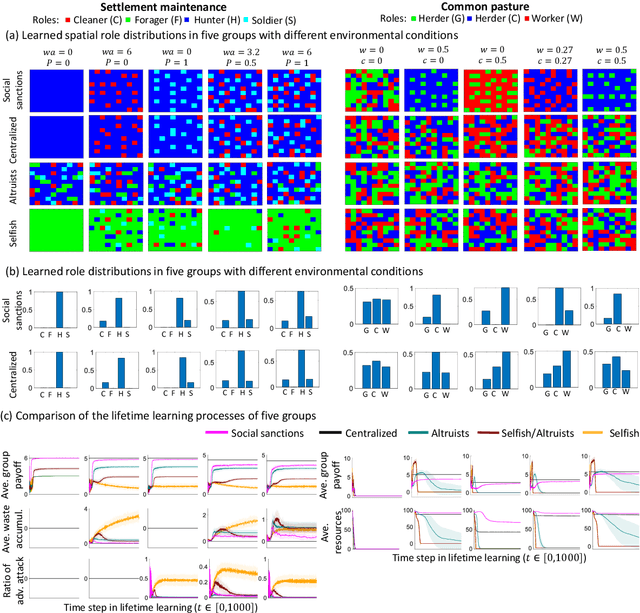
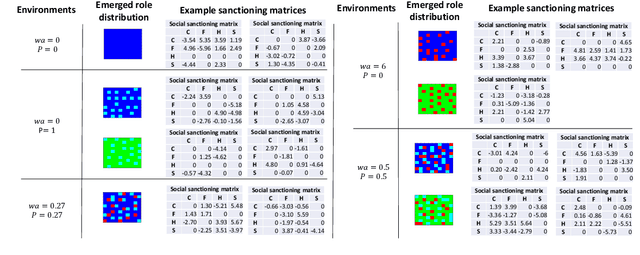
Human ecological success relies on our characteristic ability to flexibly self-organize in cooperative social groups. Successful groups employ substantial specialization and division of labor. Unlike most other animals, humans learn by trial and error during their lives what role to take on. However, when some critical roles are more attractive than others, and individuals are self-interested, then there is a social dilemma: each individual would prefer others take on the critical-but-unremunerative roles so they may remain free to take one that pays better. But disaster occurs if all act thusly and a critical role goes unfilled. In such situations learning an optimum role distribution may not be possible. Consequently, a fundamental question is: how can division of labor emerge in groups of self-interested lifetime-learning individuals? Here we show that by introducing a model of social norms, which we regard as patterns of decentralized social sanctioning, it becomes possible for groups of self-interested individuals to learn a productive division of labor involving all critical roles. Such social norms work by redistributing rewards within the population to disincentivize antisocial roles while incentivizing prosocial roles that do not intrinsically pay as well as others.
Emergent Bartering Behaviour in Multi-Agent Reinforcement Learning
May 13, 2022
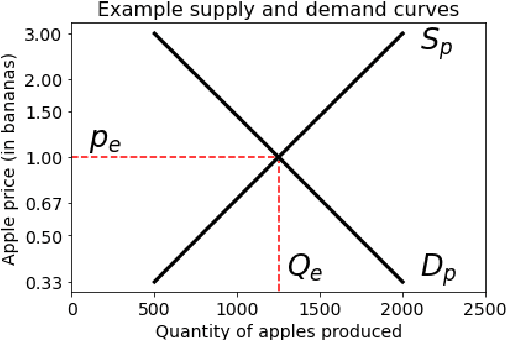

Advances in artificial intelligence often stem from the development of new environments that abstract real-world situations into a form where research can be done conveniently. This paper contributes such an environment based on ideas inspired by elementary Microeconomics. Agents learn to produce resources in a spatially complex world, trade them with one another, and consume those that they prefer. We show that the emergent production, consumption, and pricing behaviors respond to environmental conditions in the directions predicted by supply and demand shifts in Microeconomics. We also demonstrate settings where the agents' emergent prices for goods vary over space, reflecting the local abundance of goods. After the price disparities emerge, some agents then discover a niche of transporting goods between regions with different prevailing prices -- a profitable strategy because they can buy goods where they are cheap and sell them where they are expensive. Finally, in a series of ablation experiments, we investigate how choices in the environmental rewards, bartering actions, agent architecture, and ability to consume tradable goods can either aid or inhibit the emergence of this economic behavior. This work is part of the environment development branch of a research program that aims to build human-like artificial general intelligence through multi-agent interactions in simulated societies. By exploring which environment features are needed for the basic phenomena of elementary microeconomics to emerge automatically from learning, we arrive at an environment that differs from those studied in prior multi-agent reinforcement learning work along several dimensions. For example, the model incorporates heterogeneous tastes and physical abilities, and agents negotiate with one another as a grounded form of communication.
Hidden Agenda: a Social Deduction Game with Diverse Learned Equilibria
Jan 05, 2022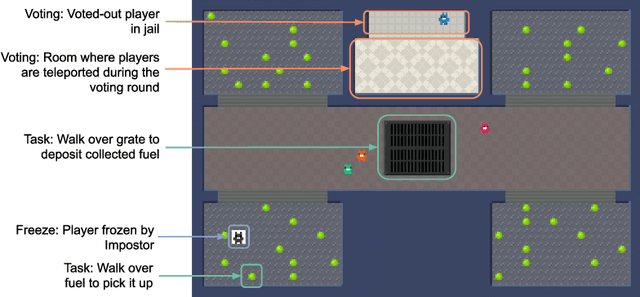

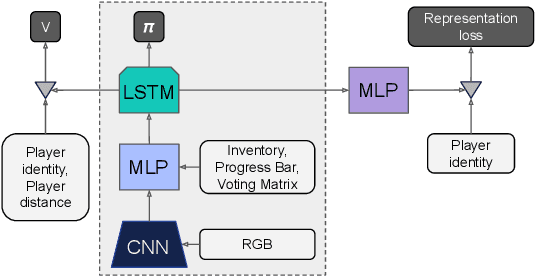
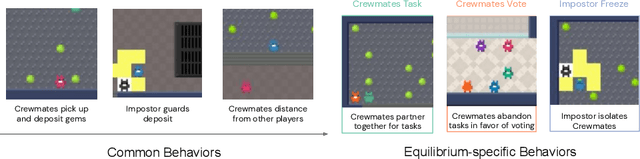
A key challenge in the study of multiagent cooperation is the need for individual agents not only to cooperate effectively, but to decide with whom to cooperate. This is particularly critical in situations when other agents have hidden, possibly misaligned motivations and goals. Social deduction games offer an avenue to study how individuals might learn to synthesize potentially unreliable information about others, and elucidate their true motivations. In this work, we present Hidden Agenda, a two-team social deduction game that provides a 2D environment for studying learning agents in scenarios of unknown team alignment. The environment admits a rich set of strategies for both teams. Reinforcement learning agents trained in Hidden Agenda show that agents can learn a variety of behaviors, including partnering and voting without need for communication in natural language.
Statistical discrimination in learning agents
Oct 21, 2021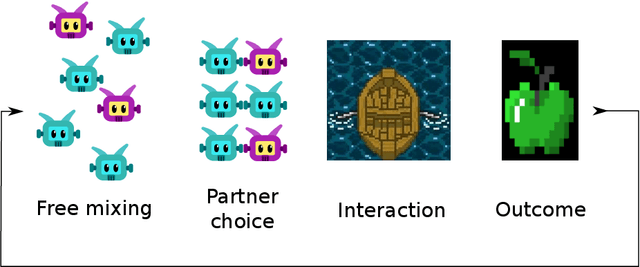
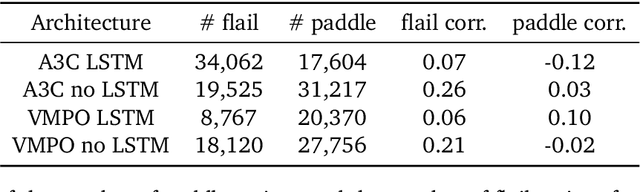
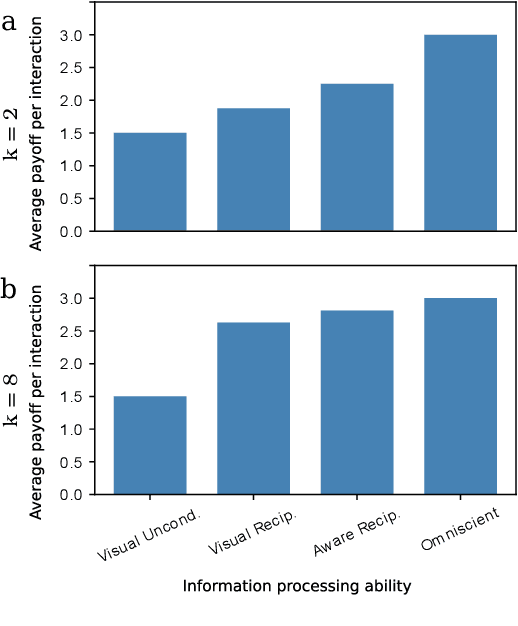
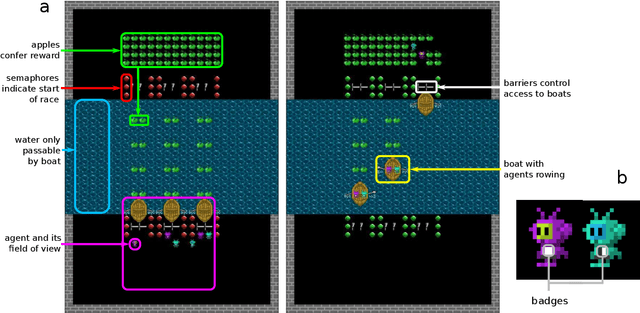
Undesired bias afflicts both human and algorithmic decision making, and may be especially prevalent when information processing trade-offs incentivize the use of heuristics. One primary example is \textit{statistical discrimination} -- selecting social partners based not on their underlying attributes, but on readily perceptible characteristics that covary with their suitability for the task at hand. We present a theoretical model to examine how information processing influences statistical discrimination and test its predictions using multi-agent reinforcement learning with various agent architectures in a partner choice-based social dilemma. As predicted, statistical discrimination emerges in agent policies as a function of both the bias in the training population and of agent architecture. All agents showed substantial statistical discrimination, defaulting to using the readily available correlates instead of the outcome relevant features. We show that less discrimination emerges with agents that use recurrent neural networks, and when their training environment has less bias. However, all agent algorithms we tried still exhibited substantial bias after learning in biased training populations.
Scalable Evaluation of Multi-Agent Reinforcement Learning with Melting Pot
Jul 14, 2021
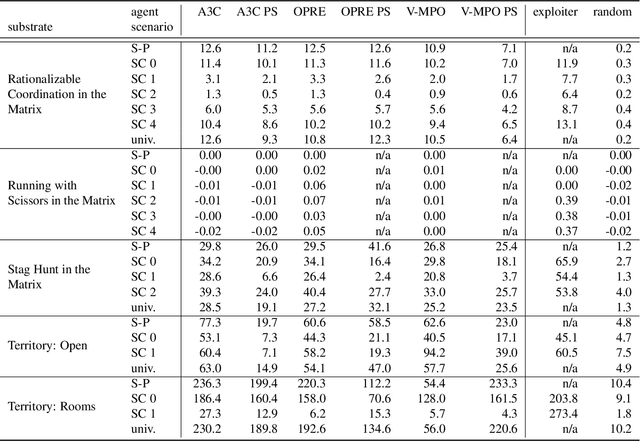
Existing evaluation suites for multi-agent reinforcement learning (MARL) do not assess generalization to novel situations as their primary objective (unlike supervised-learning benchmarks). Our contribution, Melting Pot, is a MARL evaluation suite that fills this gap, and uses reinforcement learning to reduce the human labor required to create novel test scenarios. This works because one agent's behavior constitutes (part of) another agent's environment. To demonstrate scalability, we have created over 80 unique test scenarios covering a broad range of research topics such as social dilemmas, reciprocity, resource sharing, and task partitioning. We apply these test scenarios to standard MARL training algorithms, and demonstrate how Melting Pot reveals weaknesses not apparent from training performance alone.
* Accepted to ICML 2021 and presented as a long talk; 33 pages; 9 figures
Meta-control of social learning strategies
Jun 18, 2021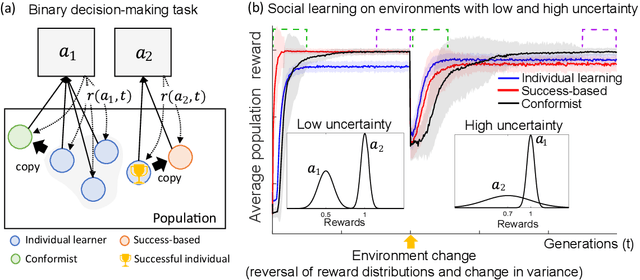

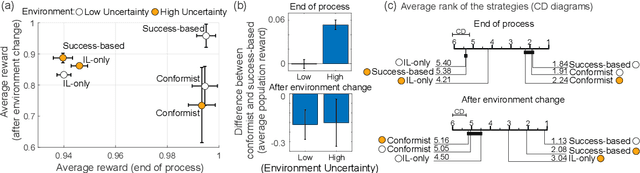

Social learning, copying other's behavior without actual experience, offers a cost-effective means of knowledge acquisition. However, it raises the fundamental question of which individuals have reliable information: successful individuals versus the majority. The former and the latter are known respectively as success-based and conformist social learning strategies. We show here that while the success-based strategy fully exploits the benign environment of low uncertainly, it fails in uncertain environments. On the other hand, the conformist strategy can effectively mitigate this adverse effect. Based on these findings, we hypothesized that meta-control of individual and social learning strategies provides effective and sample-efficient learning in volatile and uncertain environments. Simulations on a set of environments with various levels of volatility and uncertainty confirmed our hypothesis. The results imply that meta-control of social learning affords agents the leverage to resolve environmental uncertainty with minimal exploration cost, by exploiting others' learning as an external knowledge base.
Deep reinforcement learning models the emergent dynamics of human cooperation
Mar 08, 2021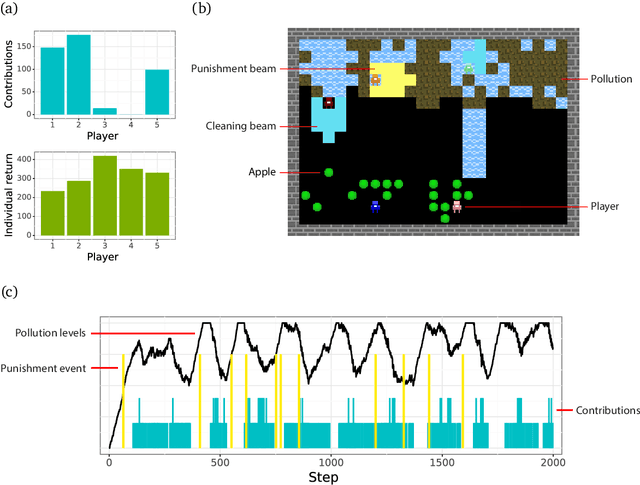
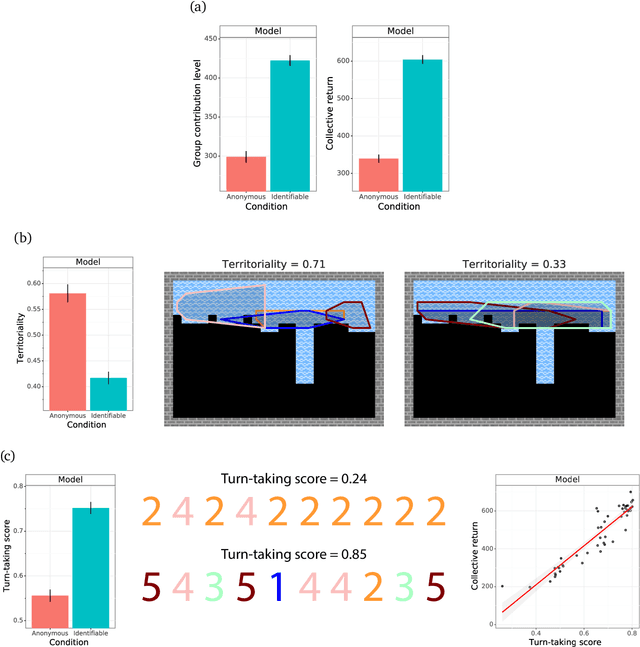
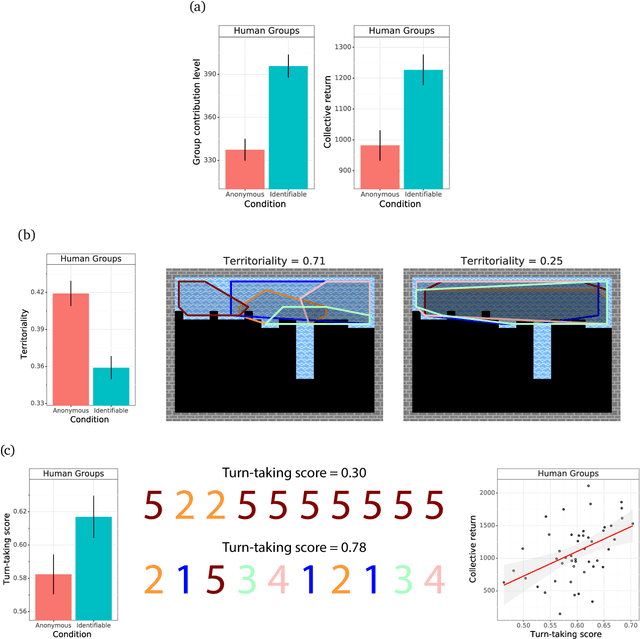
Collective action demands that individuals efficiently coordinate how much, where, and when to cooperate. Laboratory experiments have extensively explored the first part of this process, demonstrating that a variety of social-cognitive mechanisms influence how much individuals choose to invest in group efforts. However, experimental research has been unable to shed light on how social cognitive mechanisms contribute to the where and when of collective action. We leverage multi-agent deep reinforcement learning to model how a social-cognitive mechanism--specifically, the intrinsic motivation to achieve a good reputation--steers group behavior toward specific spatial and temporal strategies for collective action in a social dilemma. We also collect behavioral data from groups of human participants challenged with the same dilemma. The model accurately predicts spatial and temporal patterns of group behavior: in this public goods dilemma, the intrinsic motivation for reputation catalyzes the development of a non-territorial, turn-taking strategy to coordinate collective action.
Quantifying environment and population diversity in multi-agent reinforcement learning
Feb 16, 2021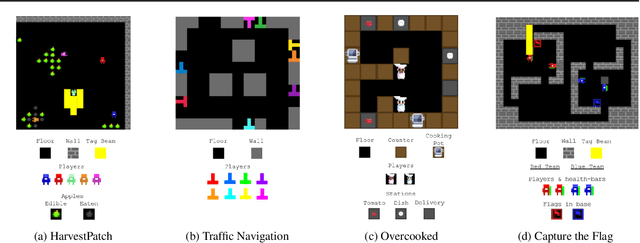

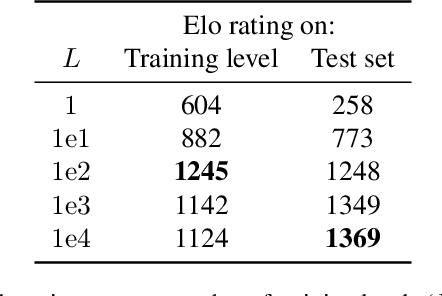
Generalization is a major challenge for multi-agent reinforcement learning. How well does an agent perform when placed in novel environments and in interactions with new co-players? In this paper, we investigate and quantify the relationship between generalization and diversity in the multi-agent domain. Across the range of multi-agent environments considered here, procedurally generating training levels significantly improves agent performance on held-out levels. However, agent performance on the specific levels used in training sometimes declines as a result. To better understand the effects of co-player variation, our experiments introduce a new environment-agnostic measure of behavioral diversity. Results demonstrate that population size and intrinsic motivation are both effective methods of generating greater population diversity. In turn, training with a diverse set of co-players strengthens agent performance in some (but not all) cases.
Modelling Cooperation in Network Games with Spatio-Temporal Complexity
Feb 13, 2021

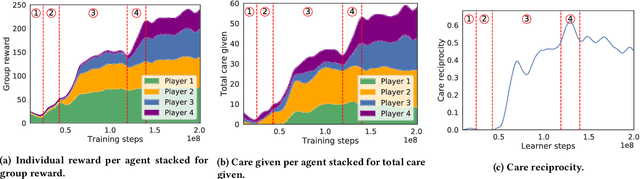
The real world is awash with multi-agent problems that require collective action by self-interested agents, from the routing of packets across a computer network to the management of irrigation systems. Such systems have local incentives for individuals, whose behavior has an impact on the global outcome for the group. Given appropriate mechanisms describing agent interaction, groups may achieve socially beneficial outcomes, even in the face of short-term selfish incentives. In many cases, collective action problems possess an underlying graph structure, whose topology crucially determines the relationship between local decisions and emergent global effects. Such scenarios have received great attention through the lens of network games. However, this abstraction typically collapses important dimensions, such as geometry and time, relevant to the design of mechanisms promoting cooperation. In parallel work, multi-agent deep reinforcement learning has shown great promise in modelling the emergence of self-organized cooperation in complex gridworld domains. Here we apply this paradigm in graph-structured collective action problems. Using multi-agent deep reinforcement learning, we simulate an agent society for a variety of plausible mechanisms, finding clear transitions between different equilibria over time. We define analytic tools inspired by related literatures to measure the social outcomes, and use these to draw conclusions about the efficacy of different environmental interventions. Our methods have implications for mechanism design in both human and artificial agent systems.