 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient Third-Person Imitation from Offline Observation
Feb 27, 2020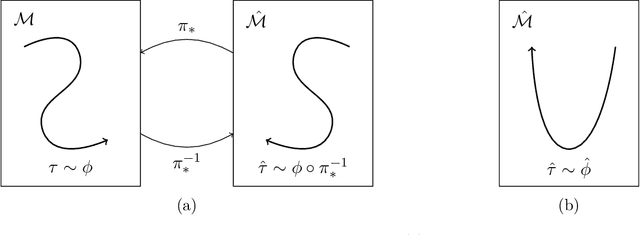
Domain adaptation in imitation learning represents an essential step towards improving generalizability. However, even in the restricted setting of third-person imitation where transfer is between isomorphic Markov Decision Processes, there are no strong guarantees on the performance of transferred policies. We present problem-dependent, statistical learning guarantees for third-person imitation from observation in an offline setting, and a lower bound on performance in the online setting.
Can graph neural networks count substructures?
Feb 27, 2020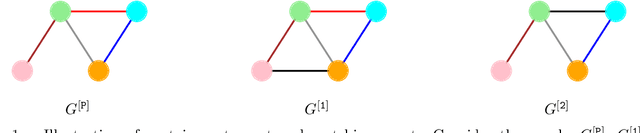
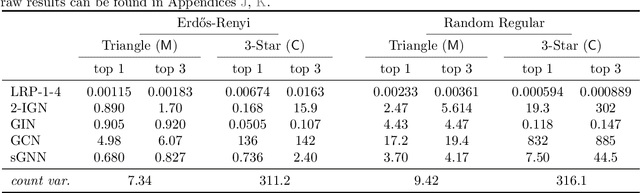

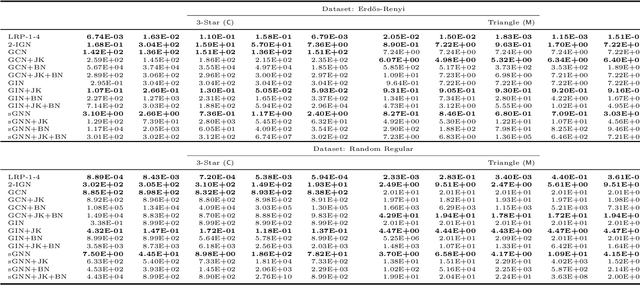
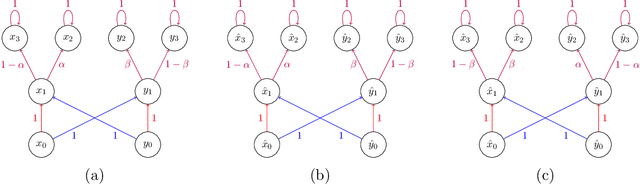
The ability to detect and count certain substructures in graphs is important for solving many tasks on graph-structured data, especially in the contexts of computational chemistry and biology as well as social network analysis. Inspired by this, we propose to study the expressive power of graph neural networks (GNNs) via their ability to count attributed graph substructures, extending recent works that examine their power in graph isomorphism testing and function approximation. We distinguish between two types of substructure counting: matching-count and containment-count, and establish both positive and negative answers for popular GNN architectures. Specifically, we prove that Message Passing Neural Networks (MPNNs), 2-Weisfeiler-Lehman (2-WL) and 2-Invariant Graph Networks (2-IGNs) cannot perform matching-count of substructures consisting of 3 or more nodes, while they can perform containment-count of star-shaped substructures. We also prove positive results for k-WL and k-IGNs as well as negative results for k-WL with limited number of iterations. We then conduct experiments that support the theoretical results for MPNNs and 2-IGNs, and demonstrate that local relational pooling strategies inspired by Murphy et al. (2019) are more effective for substructure counting. In addition, as an intermediary step, we prove that 2-WL and 2-IGNs are equivalent in distinguishing non-isomorphic graphs, partly answering an open problem raised in Maron et al. (2019).
A mean-field analysis of two-player zero-sum games
Feb 24, 2020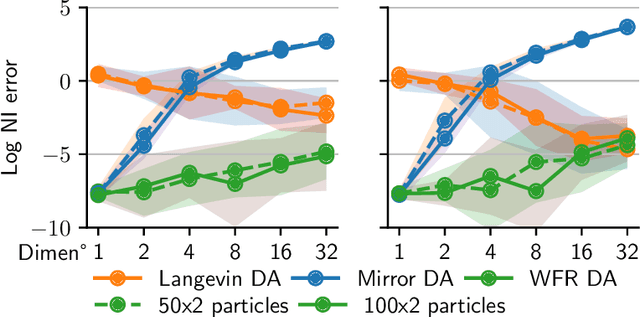
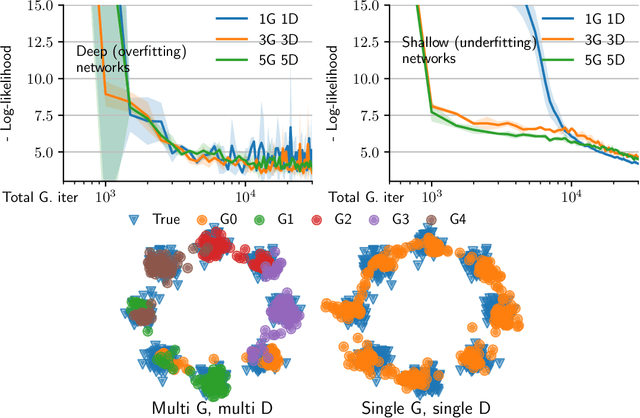

Finding Nash equilibria in two-player zero-sum continuous games is a central problem in machine learning, e.g. for training both GANs and robust models. The existence of pure Nash equilibria requires strong conditions which are not typically met in practice. Mixed Nash equilibria exist in greater generality and may be found using mirror descent. Yet this approach does not scale to high dimensions. To address this limitation, we parametrize mixed strategies as mixtures of particles, whose positions and weights are updated using gradient descent-ascent. We study this dynamics as an interacting gradient flow over measure spaces endowed with the Wasserstein-Fisher-Rao metric. We establish global convergence to an approximate equilibrium for the related Langevin gradient-ascent dynamic. We prove a law of large numbers that relates particle dynamics to mean-field dynamics. Our method identifies mixed equilibria in high dimensions and is demonstrably effective for training mixtures of GANs.
Probing the State of the Art: A Critical Look at Visual Representation Evaluation
Nov 30, 2019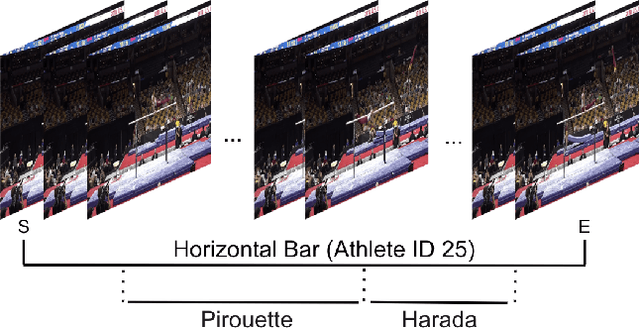
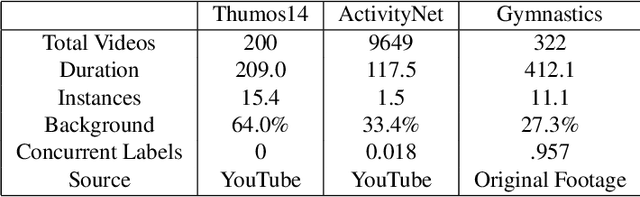
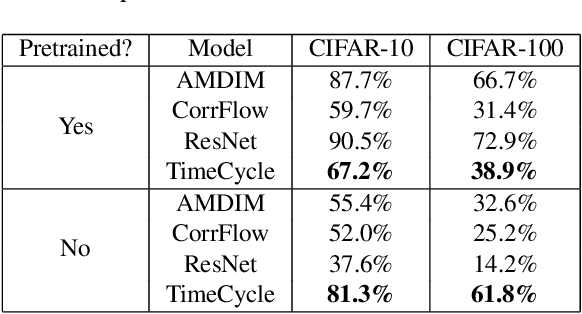
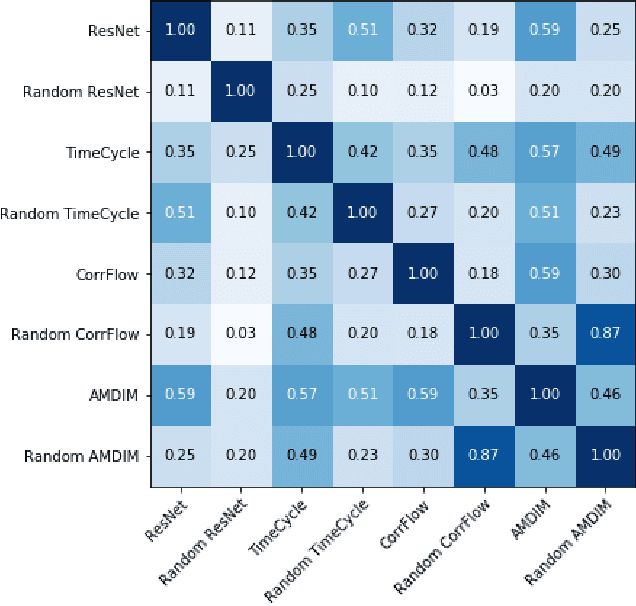
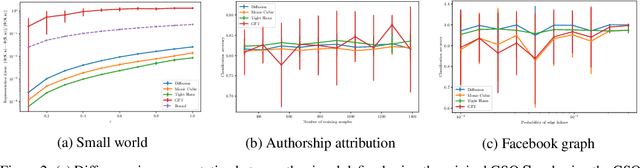
Self-supervised research improved greatly over the past half decade, with much of the growth being driven by objectives that are hard to quantitatively compare. These techniques include colorization, cyclical consistency, and noise-contrastive estimation from image patches. Consequently, the field has settled on a handful of measurements that depend on linear probes to adjudicate which approaches are the best. Our first contribution is to show that this test is insufficient and that models which perform poorly (strongly) on linear classification can perform strongly (weakly) on more involved tasks like temporal activity localization. Our second contribution is to analyze the capabilities of five different representations. And our third contribution is a much needed new dataset for temporal activity localization.
Stability of Graph Neural Networks to Relative Perturbations
Oct 21, 2019
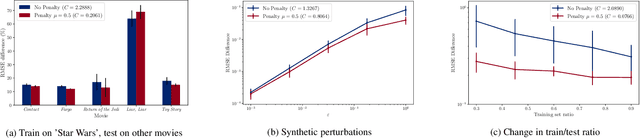
Graph neural networks (GNNs), consisting of a cascade of layers applying a graph convolution followed by a pointwise nonlinearity, have become a powerful architecture to process signals supported on graphs. Graph convolutions (and thus, GNNs), rely heavily on knowledge of the graph for operation. However, in many practical cases the GSO is not known and needs to be estimated, or might change from training time to testing time. In this paper, we are set to study the effect that a change in the underlying graph topology that supports the signal has on the output of a GNN. We prove that graph convolutions with integral Lipschitz filters lead to GNNs whose output change is bounded by the size of the relative change in the topology. Furthermore, we leverage this result to show that the main reason for the success of GNNs is that they are stable architectures capable of discriminating features on high eigenvalues, which is a feat that cannot be achieved by linear graph filters (which are either stable or discriminative, but cannot be both). Finally, we comment on the use of this result to train GNNs with increased stability and run experiments on movie recommendation systems.
Pure and Spurious Critical Points: a Geometric Study of Linear Networks
Oct 03, 2019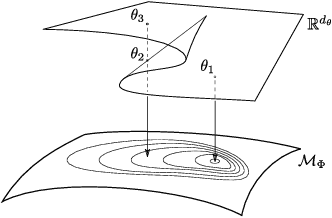
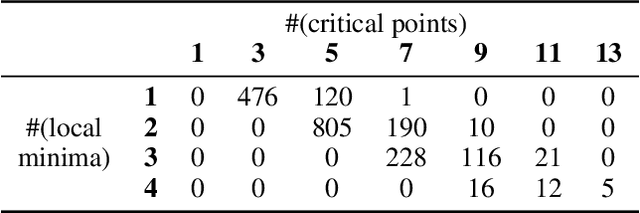
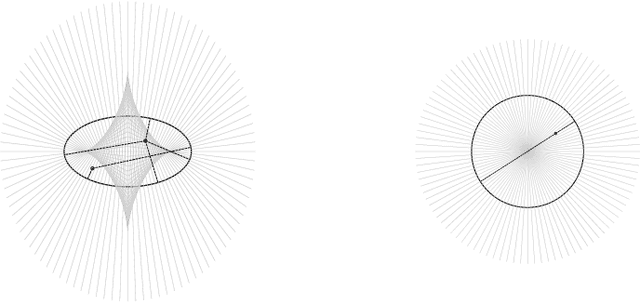
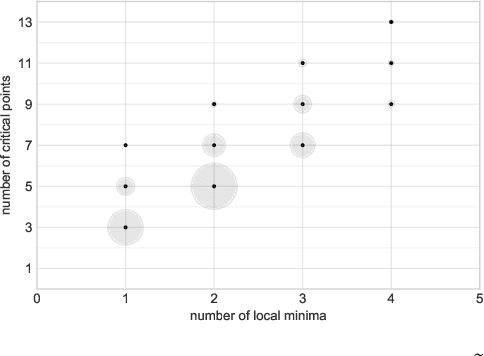
The critical locus of the loss function of a neural network is determined by the geometry of the functional space and by the parameterization of this space by the network's weights. We introduce a natural distinction between pure critical points, which only depend on the functional space, and spurious critical points, which arise from the parameterization. We apply this perspective to revisit and extend the literature on the loss function of linear neural networks. For this type of network, the functional space is either the set of all linear maps from input to output space, or a determinantal variety, i.e., a set of linear maps with bounded rank. We use geometric properties of determinantal varieties to derive new results on the landscape of linear networks with different loss functions and different parameterizations.
Gradient Dynamics of Shallow Univariate ReLU Networks
Jun 18, 2019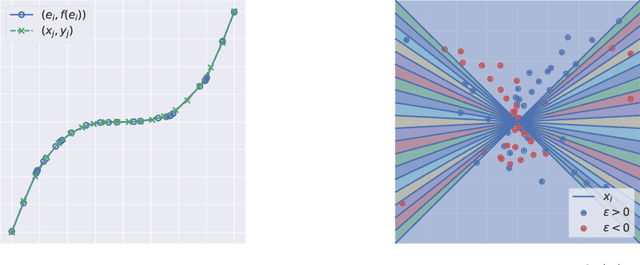
We present a theoretical and empirical study of the gradient dynamics of overparameterized shallow ReLU networks with one-dimensional input, solving least-squares interpolation. We show that the gradient dynamics of such networks are determined by the gradient flow in a non-redundant parameterization of the network function. We examine the principal qualitative features of this gradient flow. In particular, we determine conditions for two learning regimes:kernel and adaptive, which depend both on the relative magnitude of initialization of weights in different layers and the asymptotic behavior of initialization coefficients in the limit of large network widths. We show that learning in the kernel regime yields smooth interpolants, minimizing curvature, and reduces to cubic splines for uniform initializations. Learning in the adaptive regime favors instead linear splines, where knots cluster adaptively at the sample points.
Finding the Needle in the Haystack with Convolutions: on the benefits of architectural bias
Jun 16, 2019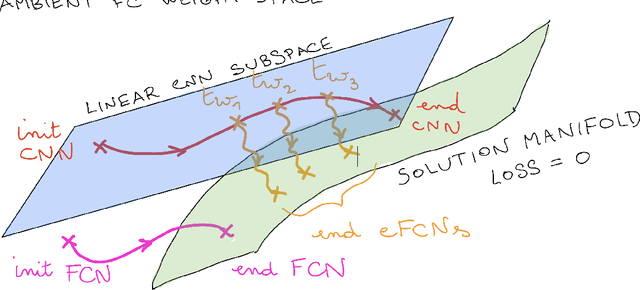
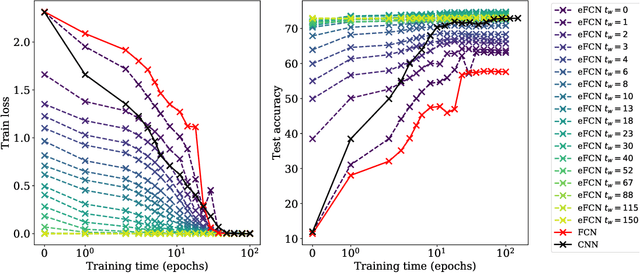
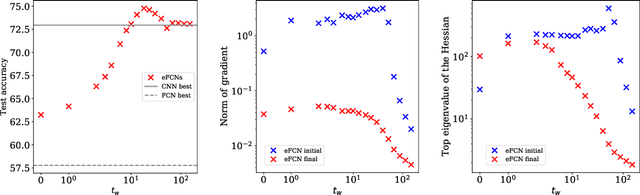
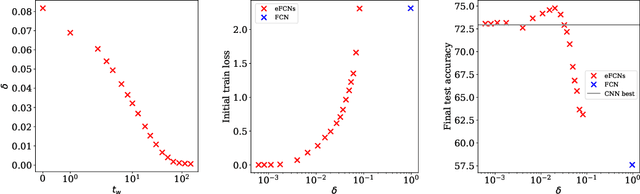
Despite the phenomenal success of deep neural networks in a broad range of learning tasks, there is a lack of theory to understand the way they work. In particular, Convolutional Neural Networks (CNNs) are known to perform much better than Fully-Connected Networks (FCNs) on spatially structured data: the architectural structure of CNNs benefits from prior knowledge on the features of the data, for instance their translation invariance. The aim of this work is to understand this fact through the lens of dynamics in the loss landscape. We introduce a method that maps a CNN to its equivalent FCN (denoted as eFCN). Such an embedding enables the comparison of CNN and FCN training dynamics directly in the FCN space. We use this method to test a new training protocol, which consists in training a CNN, embedding it to FCN space at a certain 'switch time' $t_w$, then resuming the training in FCN space. We observe that for all switch times, the deviation from the CNN subspace is small, and the final performance reached by the eFCN is higher than that reachable by the standard FCN. More surprisingly, for some intermediate switch times, the eFCN even outperforms the CNN it stemmed from. The practical interest of our protocol is limited by the very large size of the highly sparse eFCN. However, it offers an interesting insight into the persistence of the architectural bias under the stochastic gradient dynamics even in the presence of a huge number of additional degrees of freedom. It shows the existence of some rare basins in the FCN space associated with very good generalization. These can be accessed thanks to the CNN prior, and are otherwise missed.
Stability of Graph Scattering Transforms
Jun 11, 2019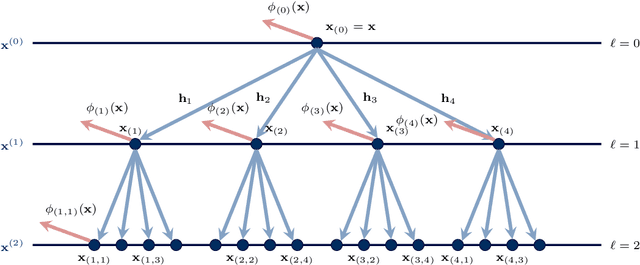
Scattering transforms are non-trainable deep convolutional architectures that exploit the multi-scale resolution of a wavelet filter bank to obtain an appropriate representation of data. More importantly, they are proven invariant to translations, and stable to perturbations that are close to translations. This stability property dons the scattering transform with a robustness to small changes in the metric domain of the data. When considering network data, regular convolutions do not hold since the data domain presents an irregular structure given by the network topology. In this work, we extend scattering transforms to network data by using multiresolution graph wavelets, whose computation can be obtained by means of graph convolutions. Furthermore, we prove that the resulting graph scattering transforms are stable to metric perturbations of the underlying network. This renders graph scattering transforms robust to changes on the network topology, making it particularly useful for cases of transfer learning, topology estimation or time-varying graphs.
Extra-gradient with player sampling for provable fast convergence in n-player games
Jun 04, 2019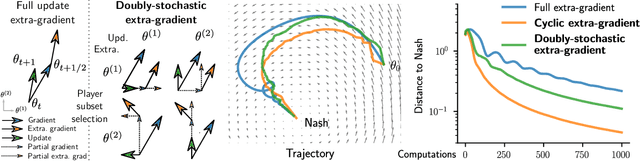
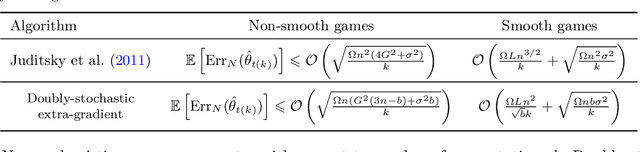
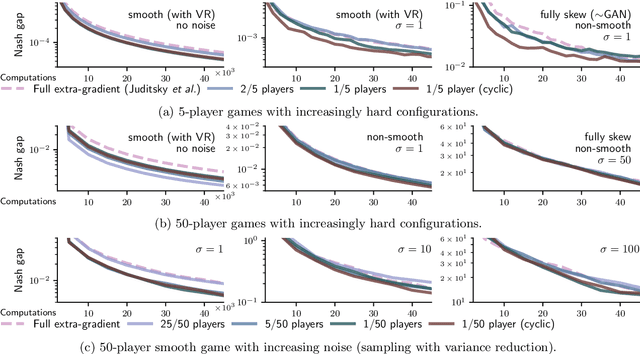

Data-driven model training is increasingly relying on finding Nash equilibria with provable techniques, e.g., for GANs and multi-agent RL. In this paper, we analyse a new extra-gradient method, that performs gradient extrapolations and updates on a random subset of players at each iteration. This approach provably exhibits the same rate of convergence as full extra-gradient in non-smooth convex games. We propose an additional variance reduction mechanism for this to hold for smooth convex games. Our approach makes extrapolation amenable to massive multiplayer settings, and brings empirical speed-ups, in particular when using cyclic sampling schemes. We demonstrate the efficiency of player sampling on large-scale non-smooth and non-strictly convex games. We show that the joint use of extrapolation and player sampling allows to train better GANs on CIFAR10.