 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts
Jun 06, 2022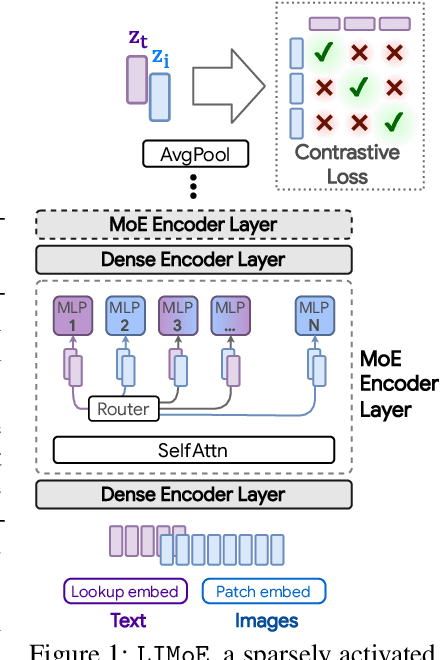
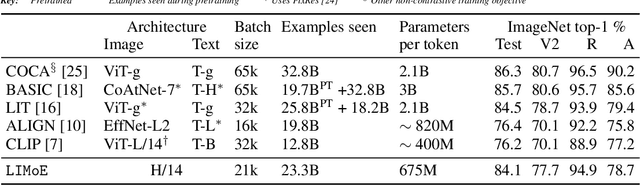


Large sparsely-activated models have obtained excellent performance in multiple domains. However, such models are typically trained on a single modality at a time. We present the Language-Image MoE, LIMoE, a sparse mixture of experts model capable of multimodal learning. LIMoE accepts both images and text simultaneously, while being trained using a contrastive loss. MoEs are a natural fit for a multimodal backbone, since expert layers can learn an appropriate partitioning of modalities. However, new challenges arise; in particular, training stability and balanced expert utilization, for which we propose an entropy-based regularization scheme. Across multiple scales, we demonstrate remarkable performance improvement over dense models of equivalent computational cost. LIMoE-L/16 trained comparably to CLIP-L/14 achieves 78.6% zero-shot ImageNet accuracy (vs. 76.2%), and when further scaled to H/14 (with additional data) it achieves 84.1%, comparable to state-of-the-art methods which use larger custom per-modality backbones and pre-training schemes. We analyse the quantitative and qualitative behavior of LIMoE, and demonstrate phenomena such as differing treatment of the modalities and the organic emergence of modality-specific experts.
Learning to Merge Tokens in Vision Transformers
Feb 24, 2022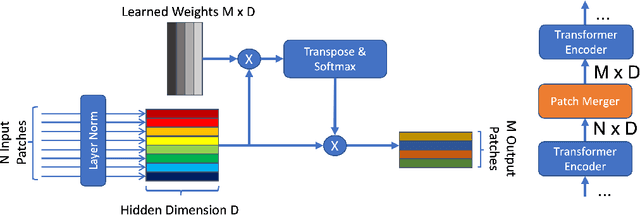
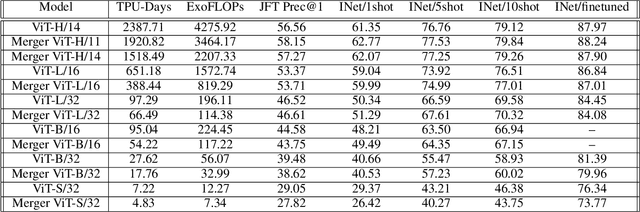
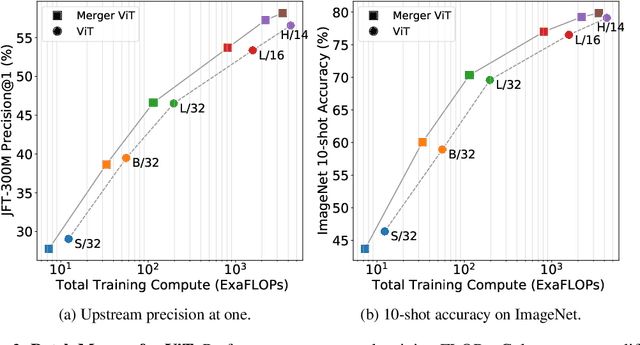
Transformers are widely applied to solve natural language understanding and computer vision tasks. While scaling up these architectures leads to improved performance, it often comes at the expense of much higher computational costs. In order for large-scale models to remain practical in real-world systems, there is a need for reducing their computational overhead. In this work, we present the PatchMerger, a simple module that reduces the number of patches or tokens the network has to process by merging them between two consecutive intermediate layers. We show that the PatchMerger achieves a significant speedup across various model sizes while matching the original performance both upstream and downstream after fine-tuning.
Sparse MoEs meet Efficient Ensembles
Oct 07, 2021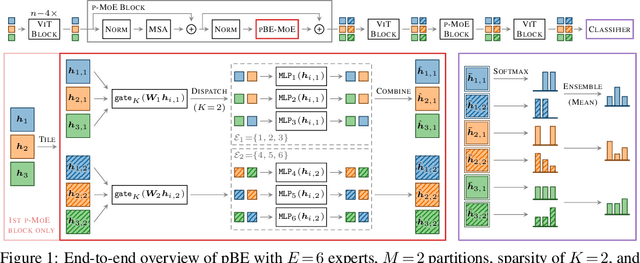

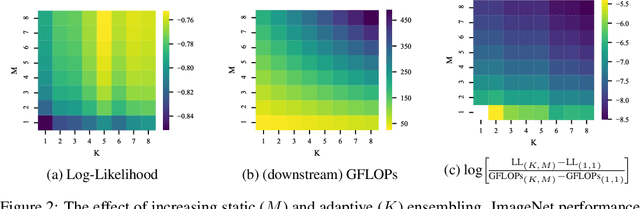
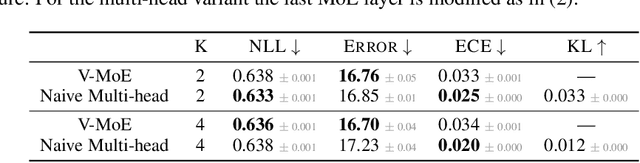
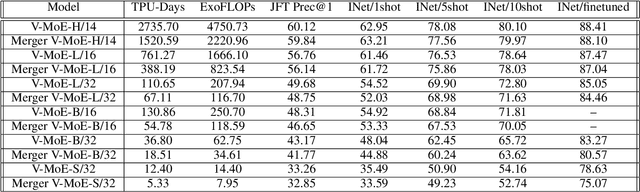
Machine learning models based on the aggregated outputs of submodels, either at the activation or prediction levels, lead to strong performance. We study the interplay of two popular classes of such models: ensembles of neural networks and sparse mixture of experts (sparse MoEs). First, we show that these two approaches have complementary features whose combination is beneficial. Then, we present partitioned batch ensembles, an efficient ensemble of sparse MoEs that takes the best of both classes of models. Extensive experiments on fine-tuned vision transformers demonstrate the accuracy, log-likelihood, few-shot learning, robustness, and uncertainty calibration improvements of our approach over several challenging baselines. Partitioned batch ensembles not only scale to models with up to 2.7B parameters, but also provide larger performance gains for larger models.
Scaling Vision with Sparse Mixture of Experts
Jun 10, 2021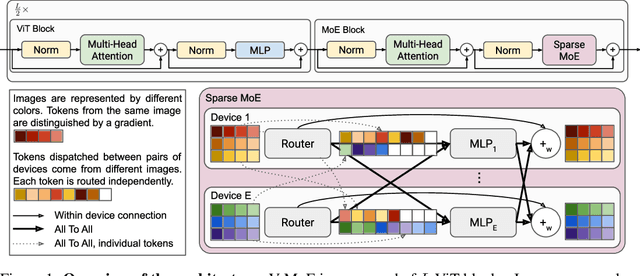
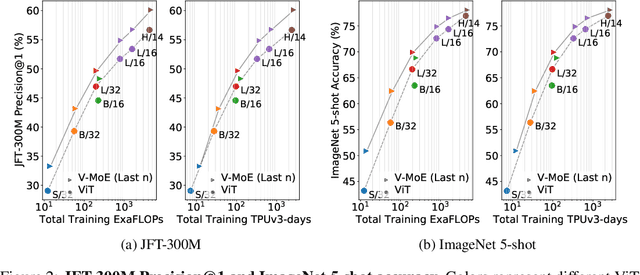

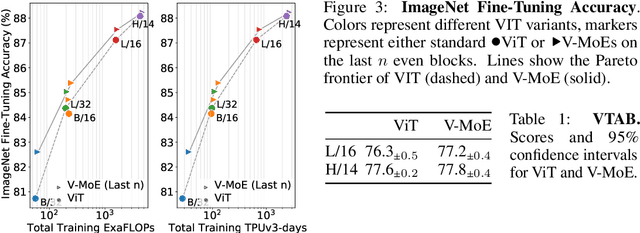
Sparsely-gated Mixture of Experts networks (MoEs) have demonstrated excellent scalability in Natural Language Processing. In Computer Vision, however, almost all performant networks are "dense", that is, every input is processed by every parameter. We present a Vision MoE (V-MoE), a sparse version of the Vision Transformer, that is scalable and competitive with the largest dense networks. When applied to image recognition, V-MoE matches the performance of state-of-the-art networks, while requiring as little as half of the compute at inference time. Further, we propose an extension to the routing algorithm that can prioritize subsets of each input across the entire batch, leading to adaptive per-image compute. This allows V-MoE to trade-off performance and compute smoothly at test-time. Finally, we demonstrate the potential of V-MoE to scale vision models, and train a 15B parameter model that attains 90.35% on ImageNet.
Deep Ensembles for Low-Data Transfer Learning
Oct 19, 2020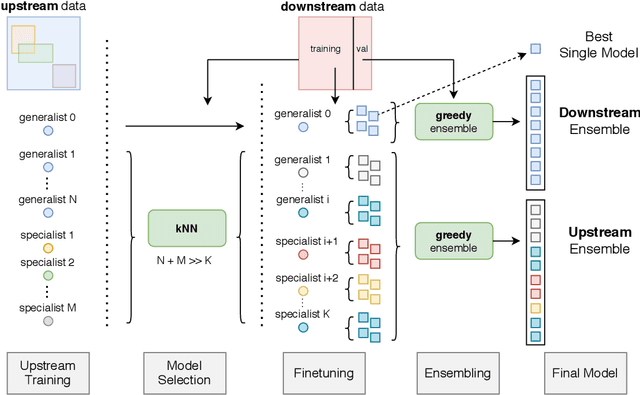
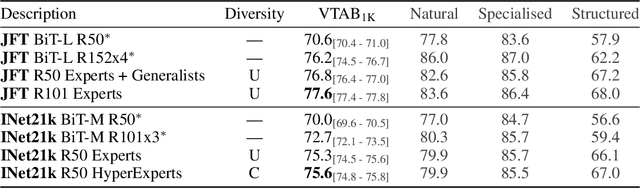
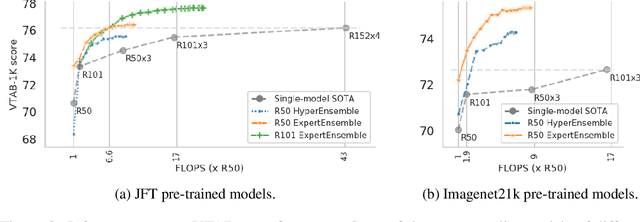
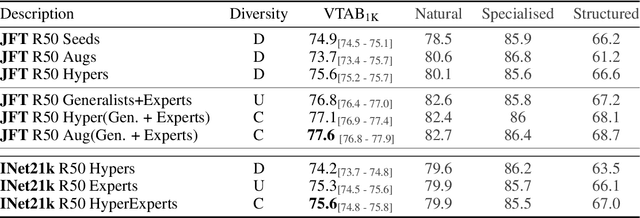
In the low-data regime, it is difficult to train good supervised models from scratch. Instead practitioners turn to pre-trained models, leveraging transfer learning. Ensembling is an empirically and theoretically appealing way to construct powerful predictive models, but the predominant approach of training multiple deep networks with different random initialisations collides with the need for transfer via pre-trained weights. In this work, we study different ways of creating ensembles from pre-trained models. We show that the nature of pre-training itself is a performant source of diversity, and propose a practical algorithm that efficiently identifies a subset of pre-trained models for any downstream dataset. The approach is simple: Use nearest-neighbour accuracy to rank pre-trained models, fine-tune the best ones with a small hyperparameter sweep, and greedily construct an ensemble to minimise validation cross-entropy. When evaluated together with strong baselines on 19 different downstream tasks (the Visual Task Adaptation Benchmark), this achieves state-of-the-art performance at a much lower inference budget, even when selecting from over 2,000 pre-trained models. We also assess our ensembles on ImageNet variants and show improved robustness to distribution shift.
Which Model to Transfer? Finding the Needle in the Growing Haystack
Oct 13, 2020
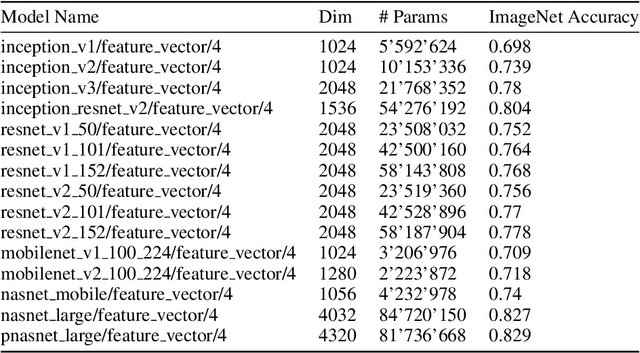
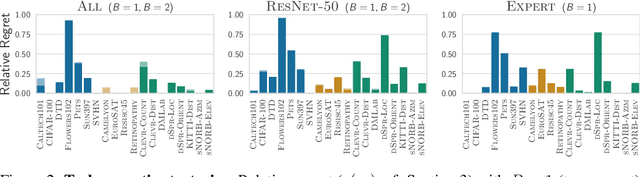
Transfer learning has been recently popularized as a data-efficient alternative to training models from scratch, in particular in vision and NLP where it provides a remarkably solid baseline. The emergence of rich model repositories, such as TensorFlow Hub, enables the practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. We provide a formalization of this problem through a familiar notion of regret and introduce the predominant strategies, namely task-agnostic (e.g. picking the highest scoring ImageNet model) and task-aware search strategies (such as linear or kNN evaluation). We conduct a large-scale empirical study and show that both task-agnostic and task-aware methods can yield high regret. We then propose a simple and computationally efficient hybrid search strategy which outperforms the existing approaches. We highlight the practical benefits of the proposed solution on a set of 19 diverse vision tasks.
Scalable Transfer Learning with Expert Models
Sep 28, 2020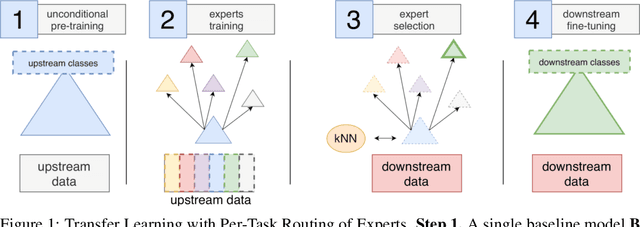
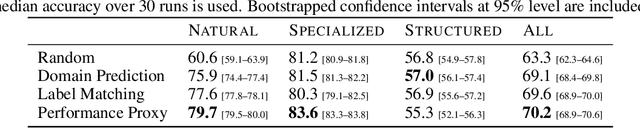
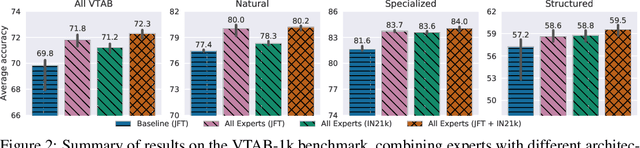
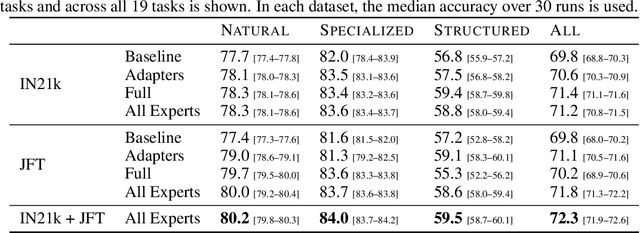
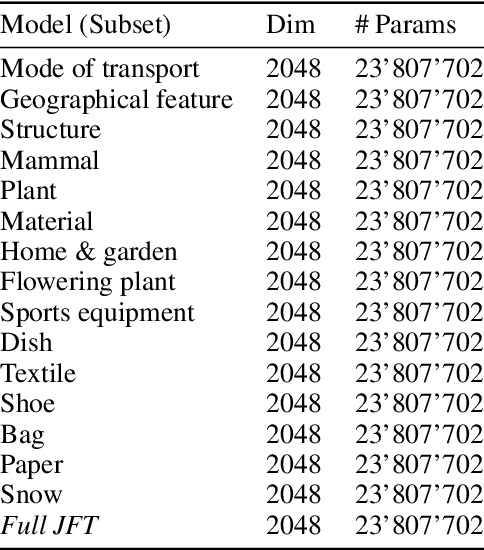
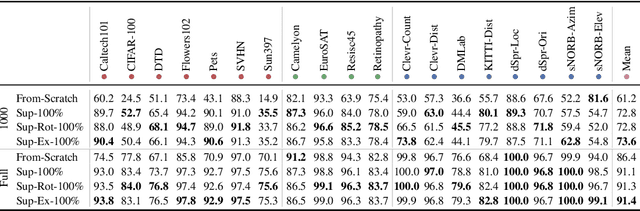
Transfer of pre-trained representations can improve sample efficiency and reduce computational requirements for new tasks. However, representations used for transfer are usually generic, and are not tailored to a particular distribution of downstream tasks. We explore the use of expert representations for transfer with a simple, yet effective, strategy. We train a diverse set of experts by exploiting existing label structures, and use cheap-to-compute performance proxies to select the relevant expert for each target task. This strategy scales the process of transferring to new tasks, since it does not revisit the pre-training data during transfer. Accordingly, it requires little extra compute per target task, and results in a speed-up of 2-3 orders of magnitude compared to competing approaches. Further, we provide an adapter-based architecture able to compress many experts into a single model. We evaluate our approach on two different data sources and demonstrate that it outperforms baselines on over 20 diverse vision tasks in both cases.
On Robustness and Transferability of Convolutional Neural Networks
Jul 16, 2020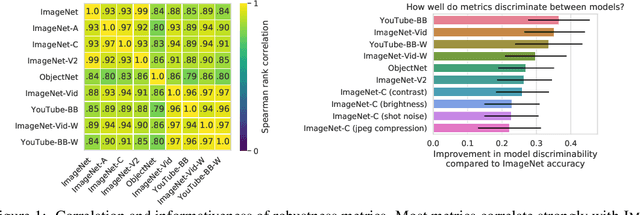

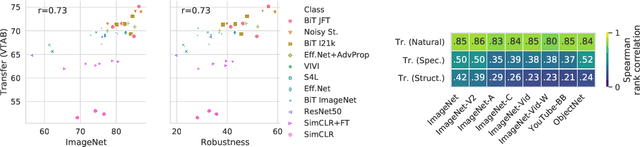
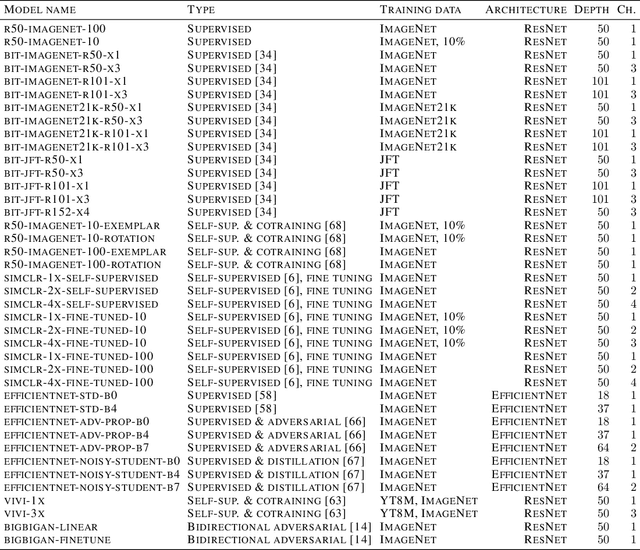
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we revisit the out-of-distribution and transfer performance of modern image classification CNNs and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset we use for a systematic analysis across common factors of variation. \end{abstract}
Large Scale Learning of General Visual Representations for Transfer
Dec 24, 2019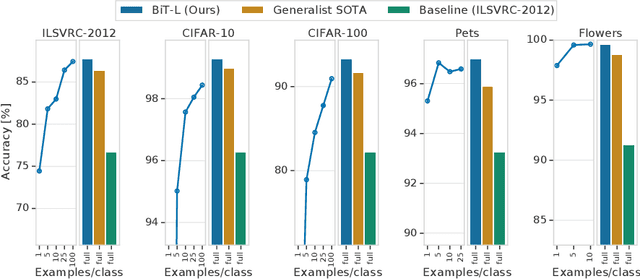

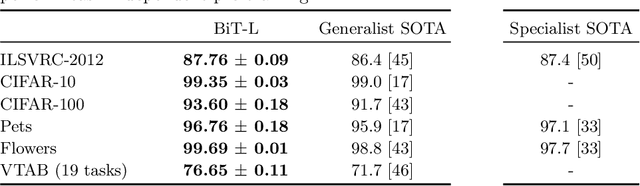
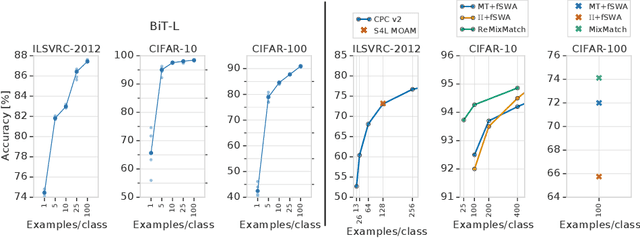
Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the weights on the target task. We scale up pre-training, and create a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes - from 10 to 1M labeled examples. BiT achieves 87.8% top-1 accuracy on ILSVRC-2012, 99.3% on CIFAR-10, and 76.7% on the Visual Task Adaptation Benchmark (which includes 19 tasks). On small datasets, BiT attains 86.4% on ILSVRC-2012 with 25 examples per class, and 97.6% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.
The Visual Task Adaptation Benchmark
Oct 01, 2019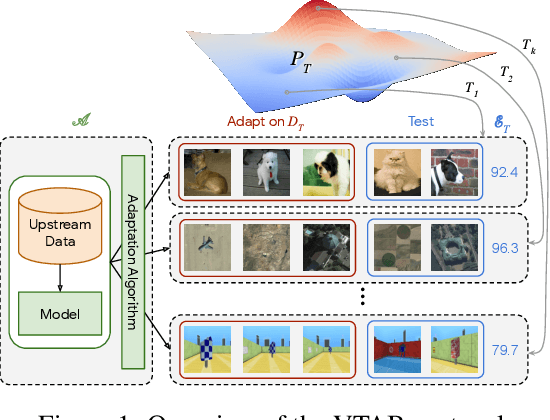
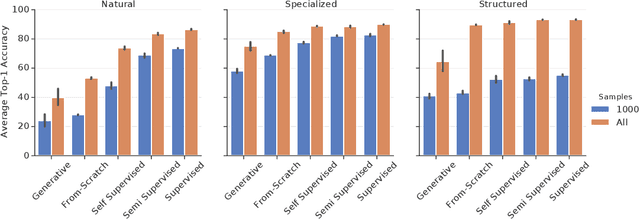
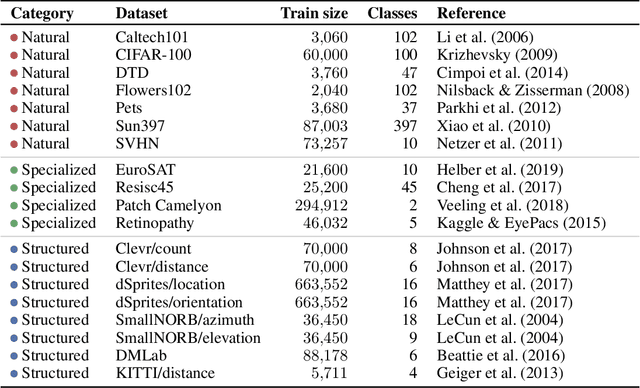
Representation learning promises to unlock deep learning for the long tail of vision tasks without expansive labelled datasets. Yet, the absence of a unified yardstick to evaluate general visual representations hinders progress. Many sub-fields promise representations, but each has different evaluation protocols that are either too constrained (linear classification), limited in scope (ImageNet, CIFAR, Pascal-VOC), or only loosely related to representation quality (generation). We present the Visual Task Adaptation Benchmark (VTAB): a diverse, realistic, and challenging benchmark to evaluate representations. VTAB embodies one principle: good representations adapt to unseen tasks with few examples. We run a large VTAB study of popular algorithms, answering questions like: How effective are ImageNet representation on non-standard datasets? Are generative models competitive? Is self-supervision useful if one already has labels?