 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Functional Perspective on Learning Symmetric Functions with Neural Networks
Aug 16, 2020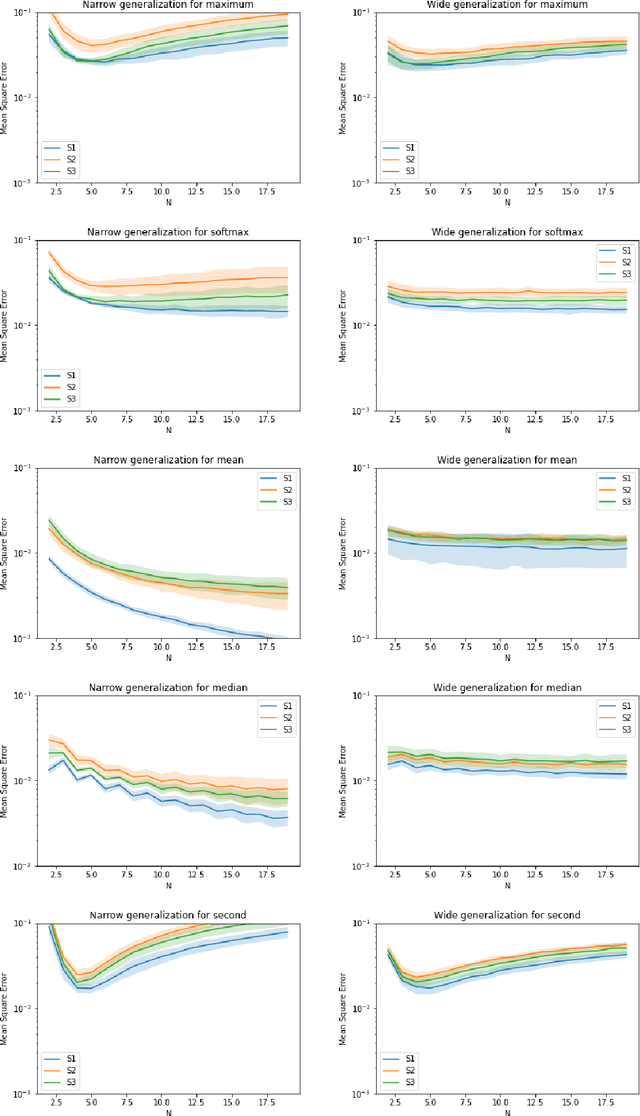
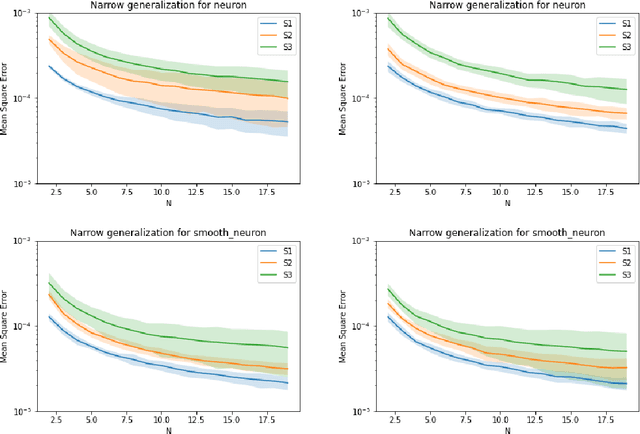
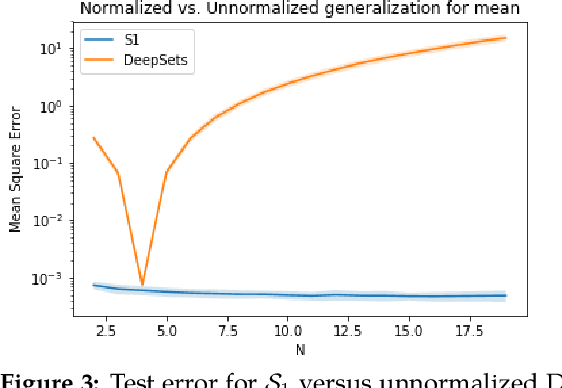
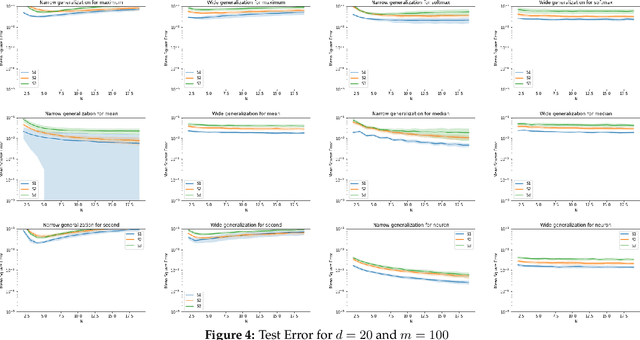
Symmetric functions, which take as input an unordered, fixed-size set, are known to be universally representable by neural networks that enforce permutation invariance. However, these architectures only give guarantees for fixed input sizes, yet in many practical scenarios, such as particle physics, a relevant notion of generalization should include varying the input size. In this paper, we embed symmetric functions (of any size) as functions over probability measures, and study the ability of neural networks defined over this space of measures to represent and learn in that space. By focusing on shallow architectures, we establish approximation and generalization bounds under different choices of regularization (such as RKHS and variation norms), that capture a hierarchy of functional spaces with increasing amount of non-linear learning. The resulting models can be learnt efficiently and enjoy generalization guarantees that extend across input sizes, as we verify empirically.
Depth separation for reduced deep networks in nonlinear model reduction: Distilling shock waves in nonlinear hyperbolic problems
Jul 28, 2020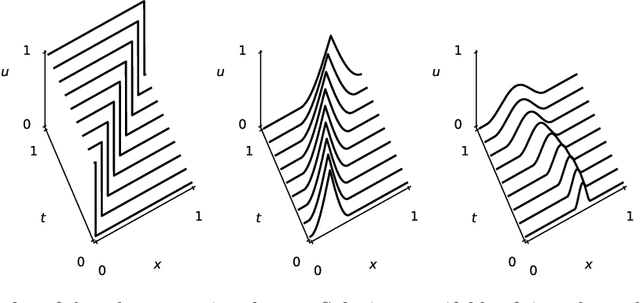
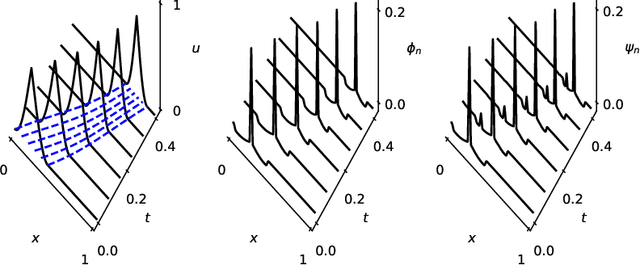
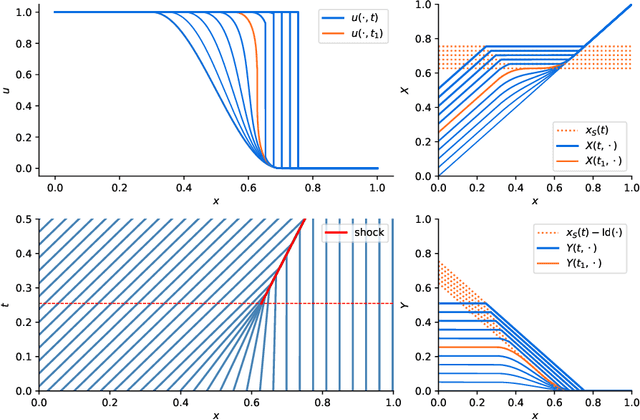
Classical reduced models are low-rank approximations using a fixed basis designed to achieve dimensionality reduction of large-scale systems. In this work, we introduce reduced deep networks, a generalization of classical reduced models formulated as deep neural networks. We prove depth separation results showing that reduced deep networks approximate solutions of parametrized hyperbolic partial differential equations with approximation error $\epsilon$ with $\mathcal{O}(|\log(\epsilon)|)$ degrees of freedom, even in the nonlinear setting where solutions exhibit shock waves. We also show that classical reduced models achieve exponentially worse approximation rates by establishing lower bounds on the relevant Kolmogorov $N$-widths.
In-Distribution Interpretability for Challenging Modalities
Jul 07, 2020
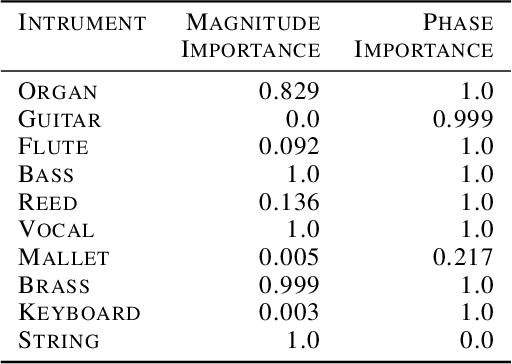
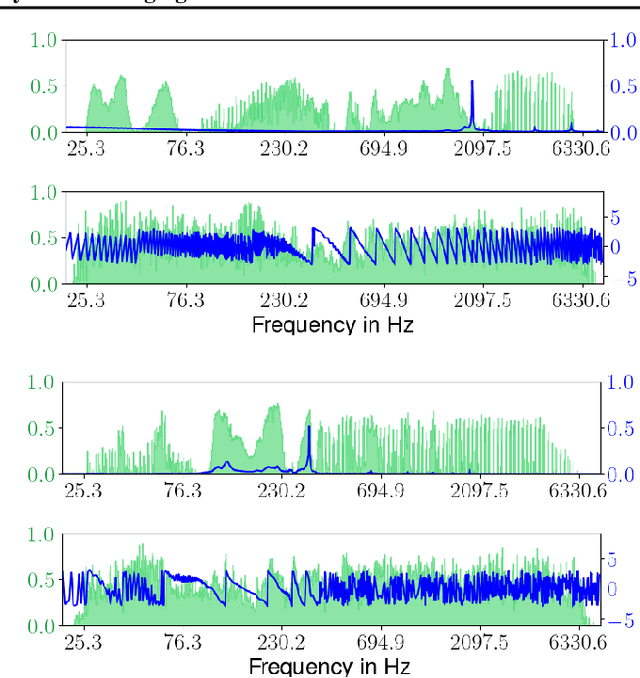
It is widely recognized that the predictions of deep neural networks are difficult to parse relative to simpler approaches. However, the development of methods to investigate the mode of operation of such models has advanced rapidly in the past few years. Recent work introduced an intuitive framework which utilizes generative models to improve on the meaningfulness of such explanations. In this work, we display the flexibility of this method to interpret diverse and challenging modalities: music and physical simulations of urban environments.
Overfitting and Optimization in Offline Policy Learning
Jun 27, 2020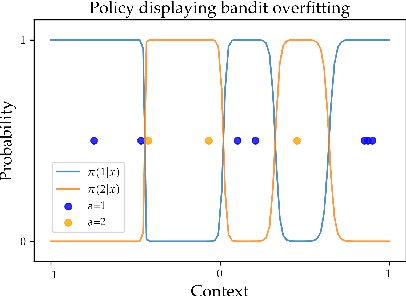
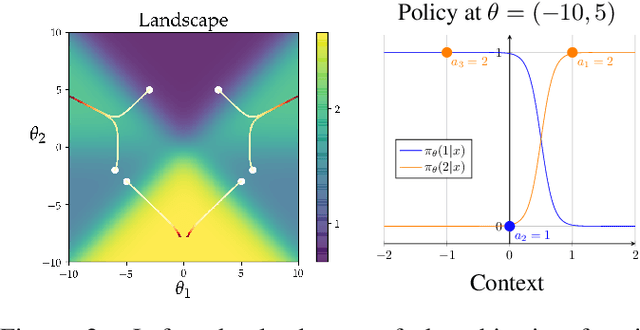
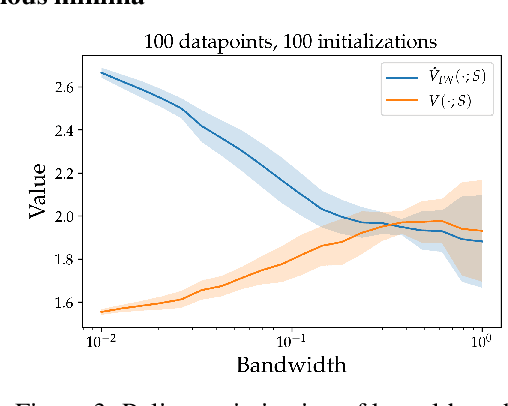
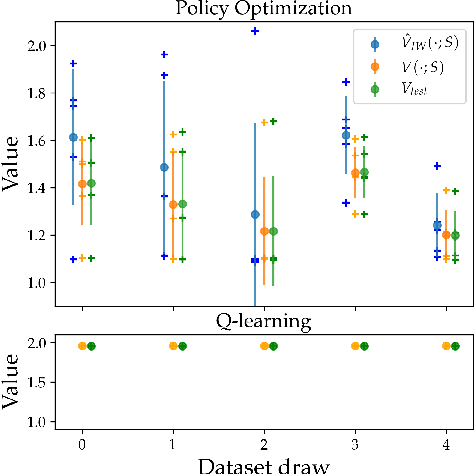
We consider the task of policy learning from an offline dataset generated by some behavior policy. We analyze the two most prominent families of algorithms for this task: policy optimization and Q-learning. We demonstrate that policy optimization suffers from two problems, overfitting and spurious minima, that do not appear in Q-learning or full-feedback problems (i.e. cost-sensitive classification). Specifically, we describe the phenomenon of ``bandit overfitting'' in which an algorithm overfits based on the actions observed in the dataset, and show that it affects policy optimization but not Q-learning. Moreover, we show that the policy optimization objective suffers from spurious minima even with linear policies, whereas the Q-learning objective is convex for linear models. We empirically verify the existence of both problems in realistic datasets with neural network models.
Neural Splines: Fitting 3D Surfaces with Infinitely-Wide Neural Networks
Jun 24, 2020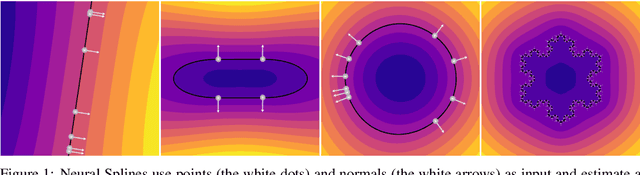

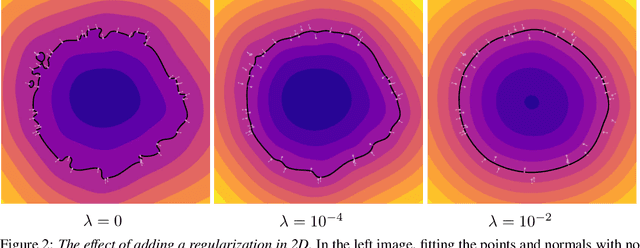
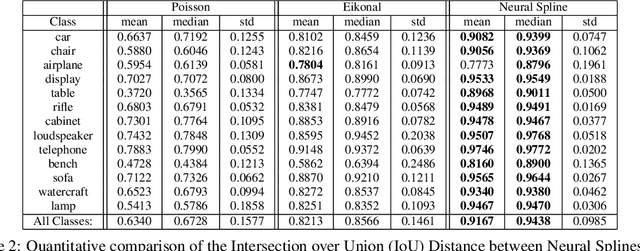
We present Neural Splines, a technique for 3D surface reconstruction that is based on random feature kernels arising from infinitely-wide shallow ReLU networks. Our method achieves state-of-the-art results, outperforming Screened Poisson Surface Reconstruction and modern neural network based techniques. Because our approach is based on a simple kernel formulation, it is fast to run and easy to analyze. We provide explicit analytical expressions for our kernel and argue that our formulation can be seen as a generalization of cubic spline interpolation to higher dimensions. In particular, the RKHS norm associated with our kernel biases toward smooth interpolants. Finally, we formulate Screened Poisson Surface Reconstruction as a kernel method and derive an analytic expression for its norm in the corresponding RKHS.
On Sparsity in Overparametrised Shallow ReLU Networks
Jun 18, 2020The analysis of neural network training beyond their linearization regime remains an outstanding open question, even in the simplest setup of a single hidden-layer. The limit of infinitely wide networks provides an appealing route forward through the mean-field perspective, but a key challenge is to bring learning guarantees back to the finite-neuron setting, where practical algorithms operate. Towards closing this gap, and focusing on shallow neural networks, in this work we study the ability of different regularisation strategies to capture solutions requiring only a finite amount of neurons, even on the infinitely wide regime. Specifically, we consider (i) a form of implicit regularisation obtained by injecting noise into training targets [Blanc et al.~19], and (ii) the variation-norm regularisation [Bach~17], compatible with the mean-field scaling. Under mild assumptions on the activation function (satisfied for instance with ReLUs), we establish that both schemes are minimised by functions having only a finite number of neurons, irrespective of the amount of overparametrisation. We study the consequences of such property and describe the settings where one form of regularisation is favorable over the other.
IDEAL: Inexact DEcentralized Accelerated Augmented Lagrangian Method
Jun 11, 2020
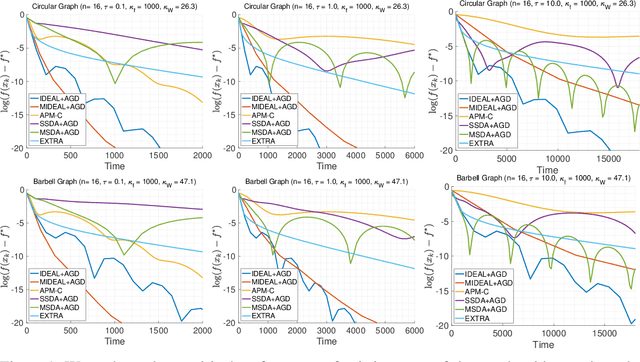

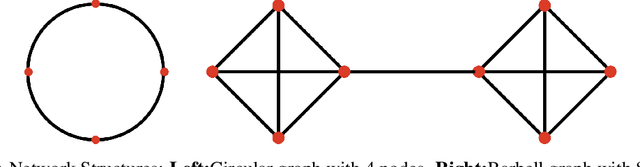
We introduce a framework for designing primal methods under the decentralized optimization setting where local functions are smooth and strongly convex. Our approach consists of approximately solving a sequence of sub-problems induced by the accelerated augmented Lagrangian method, thereby providing a systematic way for deriving several well-known decentralized algorithms including EXTRA arXiv:1404.6264 and SSDA arXiv:1702.08704. When coupled with accelerated gradient descent, our framework yields a novel primal algorithm whose convergence rate is optimal and matched by recently derived lower bounds. We provide experimental results that demonstrate the effectiveness of the proposed algorithm on highly ill-conditioned problems.
Continuous LWE
May 19, 2020
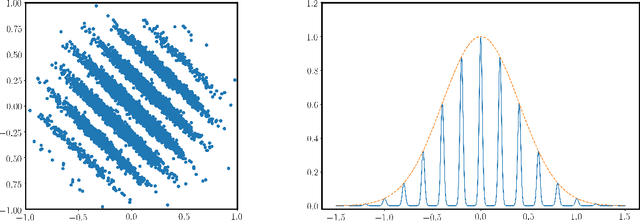
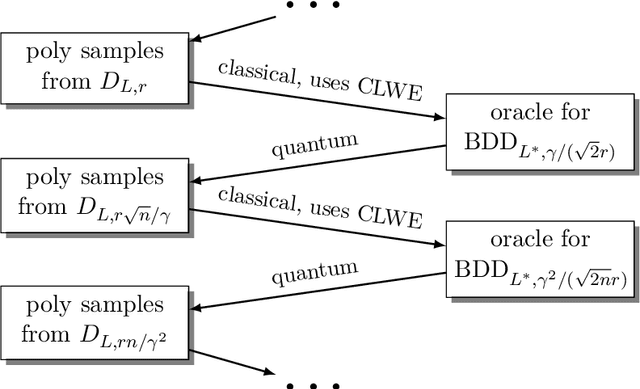
We introduce a continuous analogue of the Learning with Errors (LWE) problem, which we name CLWE. We give a polynomial-time quantum reduction from worst-case lattice problems to CLWE, showing that CLWE enjoys similar hardness guarantees to those of LWE. Alternatively, our result can also be seen as opening new avenues of (quantum) attacks on lattice problems. Our work resolves an open problem regarding the computational complexity of learning mixtures of Gaussians without separability assumptions (Diakonikolas 2016, Moitra 2018). As an additional motivation, (a slight variant of) CLWE was considered in the context of robust machine learning (Diakonikolas et al.~FOCS 2017), where hardness in the statistical query (SQ) model was shown; our work addresses the open question regarding its computational hardness (Bubeck et al.~ICML 2019).
A Permutation-Equivariant Neural Network Architecture For Auction Design
Mar 02, 2020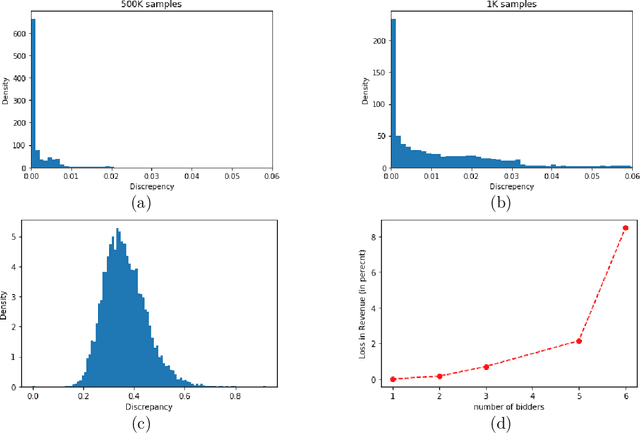
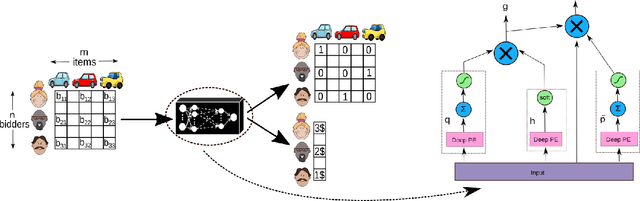
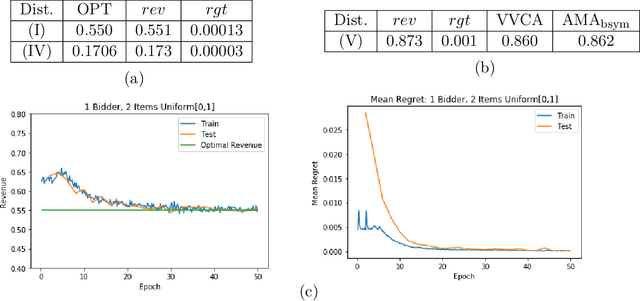
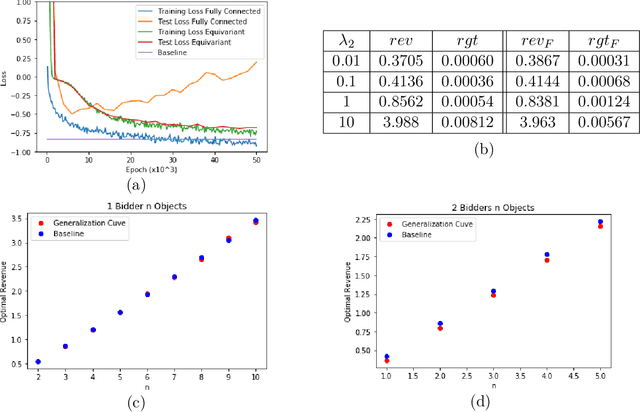
Designing an incentive compatible auction that maximizes expected revenue is a central problem in Auction Design. Theoretical approaches to the problem have hit some limits in the past decades and analytical solutions are known for only a few simple settings. Computational approaches to the problem through the use of LPs have their own set of limitations. Building on the success of deep learning, a new approach was recently proposed by D\"utting et al., 2017 in which the auction is modeled by a feed-forward neural network and the design problem is framed as a learning problem. The neural architectures used in that work are general purpose and do not take advantage of any of the symmetries the problem could present, such as permutation equivariance. In this work, we consider auction design problems that have permutation-equivariant symmetry and construct a neural architecture that is capable of perfectly recovering the permutation-equivariant optimal mechanism, which we show is not possible with the previous architecture. We demonstrate that permutation-equivariant architectures are not only capable of recovering previous results, they also have better generalization properties.
Provably Efficient Third-Person Imitation from Offline Observation
Feb 27, 2020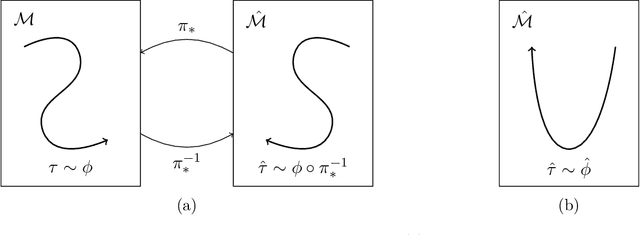
Domain adaptation in imitation learning represents an essential step towards improving generalizability. However, even in the restricted setting of third-person imitation where transfer is between isomorphic Markov Decision Processes, there are no strong guarantees on the performance of transferred policies. We present problem-dependent, statistical learning guarantees for third-person imitation from observation in an offline setting, and a lower bound on performance in the online setting.