 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Visual Classification via Progressive Multi-Granularity Training of Jigsaw Patches
Mar 10, 2020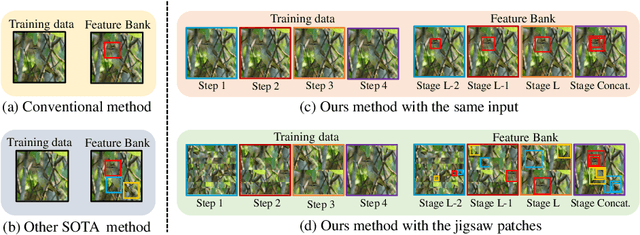
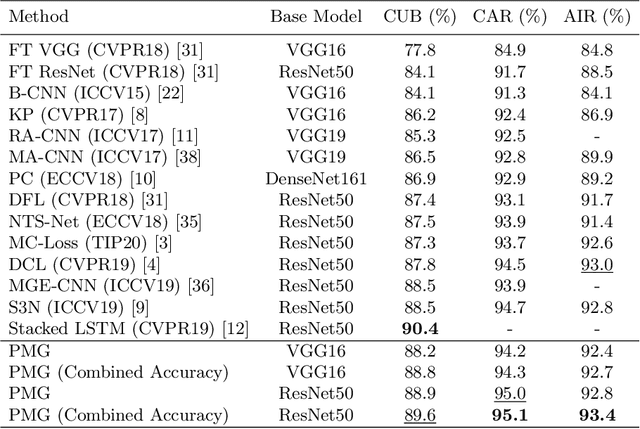
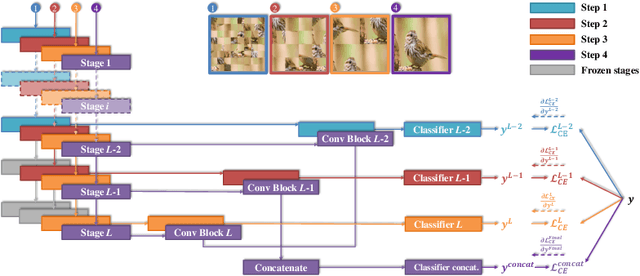
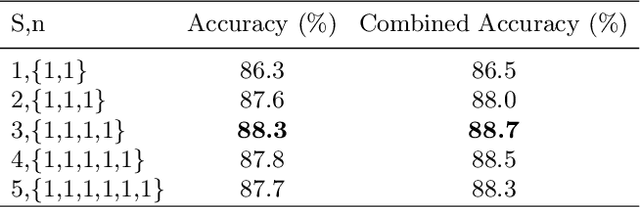
Fine-grained visual classification (FGVC) is much more challenging than traditional classification tasks due to the inherently subtle intra-class object variations. Recent works mainly tackle this problem by focusing on how to locate the most discriminative parts, more complementary parts, and parts of various granularities. However, less effort has been placed to which granularities are the most discriminative and how to fuse information cross multi-granularity. In this work, we propose a novel framework for fine-grained visual classification to tackle these problems. In particular, we propose: (i) a novel progressive training strategy that adds new layers in each training step to exploit information based on the smaller granularity information found at the last step and the previous stage. (ii) a simple jigsaw puzzle generator to form images contain information of different granularity levels. We obtain state-of-the-art performances on several standard FGVC benchmark datasets, where the proposed method consistently outperforms existing methods or delivers competitive results. The code will be available at https://github.com/RuoyiDu/PMG-Progressive-Multi-Granularity-Training.
Channel Attention with Embedding Gaussian Process: A Probabilistic Methodology
Mar 10, 2020
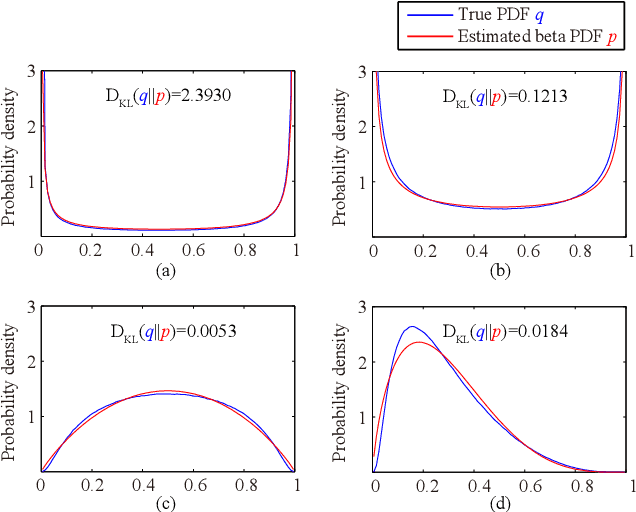
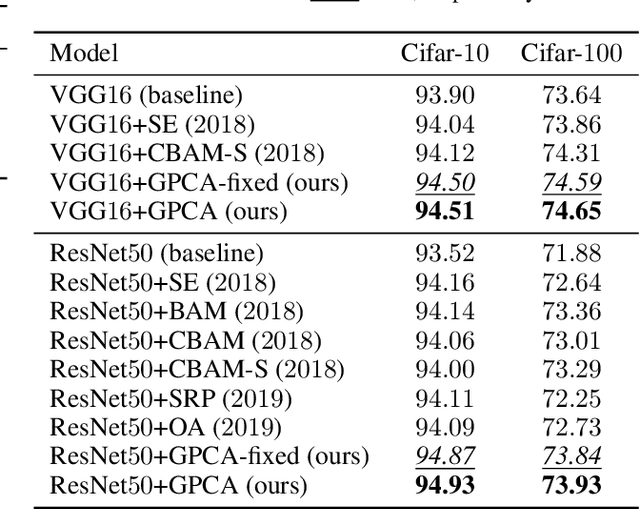
Channel attention mechanisms, as the key components of some modern convolutional neural networks (CNNs) architectures, have been commonly used in many visual tasks for effective performance improvement. It is able to reinforce the informative channels and to suppress useless channels of feature maps obtained by CNNs. Recently, different attention modules have been proposed, which are implemented in various ways. However, they are mainly based on convolution and pooling operations, which are lack of intuitive and reasonable insights about the principles that they are based on. Moreover, the ways that they improve the performance of the CNNs is not clear either. In this paper, we propose a Gaussian process embedded channel attention (GPCA) module and interpret the channel attention intuitively and reasonably in a probabilistic way. The GPCA module is able to model the correlations from channels which are assumed as beta distributed variables with Gaussian process prior. As the beta distribution is intractably integrated into the end-to-end training of the CNNs, we utilize an appropriate approximation of the beta distribution to make the distribution assumption implemented easily. In this case, the proposed GPCA module can be integrated into the end-to-end training of the CNNs. Experimental results demonstrate that the proposed GPCA module can improve the accuracies of image classification on four widely used datasets.
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification
Feb 11, 2020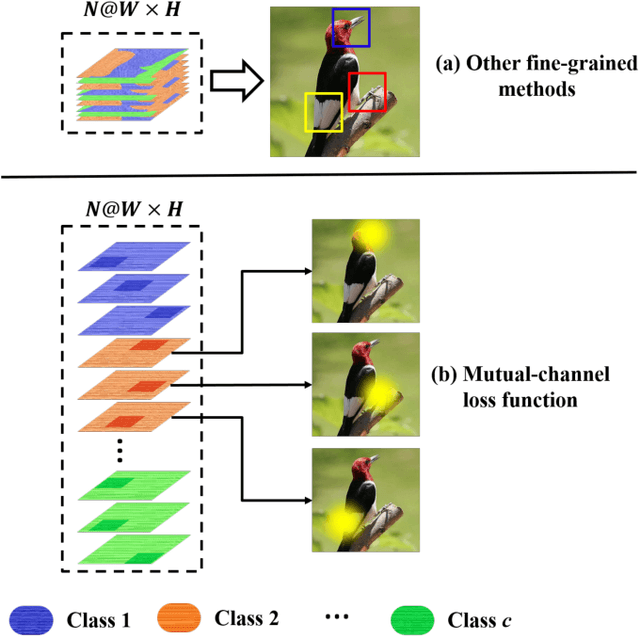
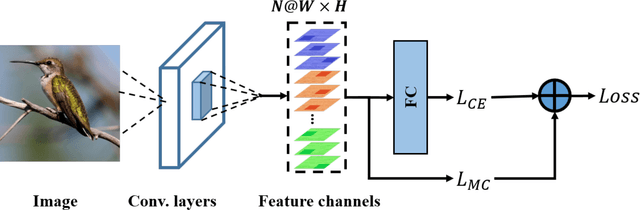
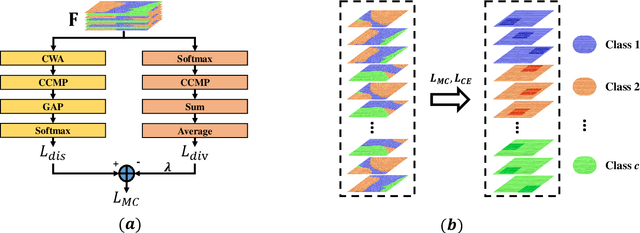
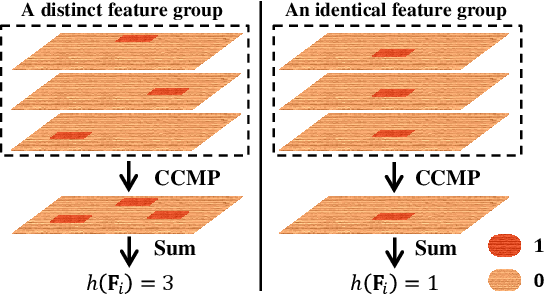
Key for solving fine-grained image categorization is finding discriminate and local regions that correspond to subtle visual traits. Great strides have been made, with complex networks designed specifically to learn part-level discriminate feature representations. In this paper, we show it is possible to cultivate subtle details without the need for overly complicated network designs or training mechanisms -- a single loss is all it takes. The main trick lies with how we delve into individual feature channels early on, as opposed to the convention of starting from a consolidated feature map. The proposed loss function, termed as mutual-channel loss (MC-Loss), consists of two channel-specific components: a discriminality component and a diversity component. The discriminality component forces all feature channels belonging to the same class to be discriminative, through a novel channel-wise attention mechanism. The diversity component additionally constraints channels so that they become mutually exclusive on spatial-wise. The end result is therefore a set of feature channels that each reflects different locally discriminative regions for a specific class. The MC-Loss can be trained end-to-end, without the need for any bounding-box/part annotations, and yields highly discriminative regions during inference. Experimental results show our MC-Loss when implemented on top of common base networks can achieve state-of-the-art performance on all four fine-grained categorization datasets (CUB-Birds, FGVC-Aircraft, Flowers-102, and Stanford-Cars). Ablative studies further demonstrate the superiority of MC-Loss when compared with other recently proposed general-purpose losses for visual classification, on two different base networks. Code available at https://github.com/dongliangchang/Mutual-Channel-Loss
Weakly Supervised Attention Pyramid Convolutional Neural Network for Fine-Grained Visual Classification
Feb 09, 2020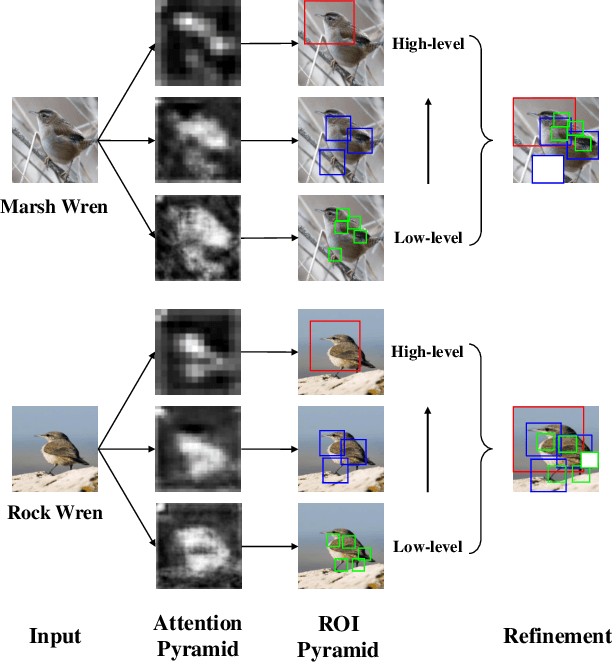
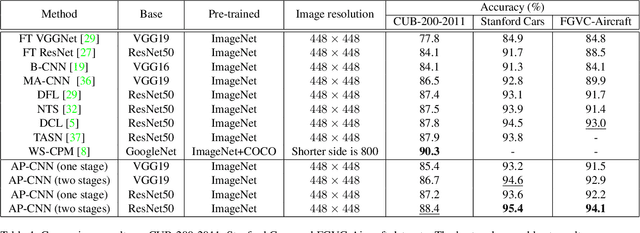
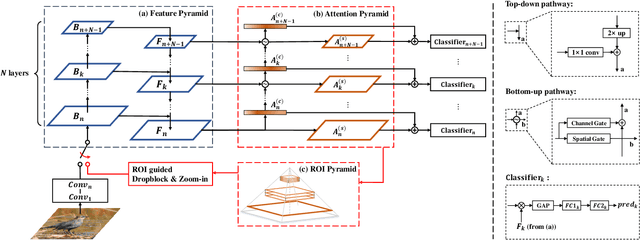

Classifying the sub-categories of an object from the same super-category (e.g. bird species, car and aircraft models) in fine-grained visual classification (FGVC) highly relies on discriminative feature representation and accurate region localization. Existing approaches mainly focus on distilling information from high-level features. In this paper, however, we show that by integrating low-level information (e.g. color, edge junctions, texture patterns), performance can be improved with enhanced feature representation and accurately located discriminative regions. Our solution, named Attention Pyramid Convolutional Neural Network (AP-CNN), consists of a) a pyramidal hierarchy structure with a top-down feature pathway and a bottom-up attention pathway, and hence learns both high-level semantic and low-level detailed feature representation, and b) an ROI guided refinement strategy with ROI guided dropblock and ROI guided zoom-in, which refines features with discriminative local regions enhanced and background noises eliminated. The proposed AP-CNN can be trained end-to-end, without the need of additional bounding box/part annotations. Extensive experiments on three commonly used FGVC datasets (CUB-200-2011, Stanford Cars, and FGVC-Aircraft) demonstrate that our approach can achieve state-of-the-art performance. Code available at \url{http://dwz1.cc/ci8so8a}
Impacts of Weather Conditions on District Heat System
Aug 02, 2018
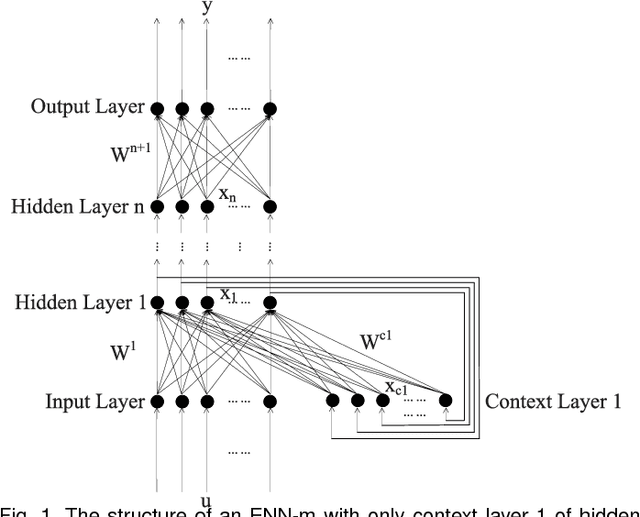

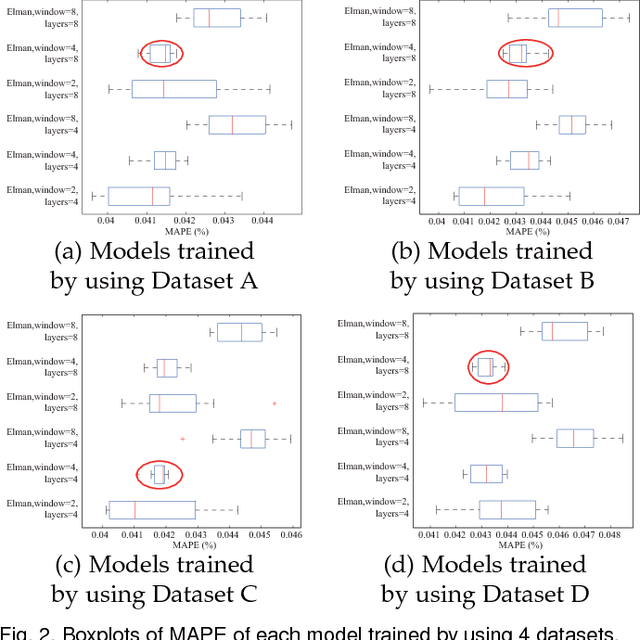
Using artificial neural network for the prediction of heat demand has attracted more and more attention. Weather conditions, such as ambient temperature, wind speed and direct solar irradiance, have been identified as key input parameters. In order to further improve the model accuracy, it is of great importance to understand the influence of different parameters. Based on an Elman neural network (ENN), this paper investigates the impact of direct solar irradiance and wind speed on predicting the heat demand of a district heating network. Results show that including wind speed can generally result in a lower overall mean absolute percentage error (MAPE) (6.43%) than including direct solar irradiance (6.47%); while including direct solar irradiance can achieve a lower maximum absolute deviation (71.8%) than including wind speed (81.53%). In addition, even though including both wind speed and direct solar irradiance shows the best overall performance (MAPE=6.35%).
Mobile big data analysis with machine learning
Aug 02, 2018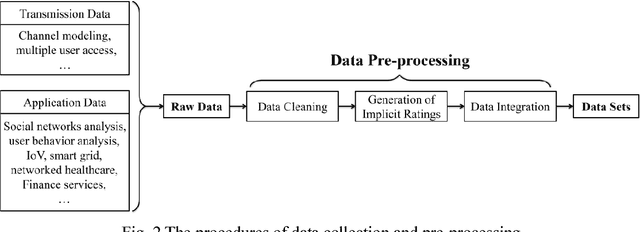

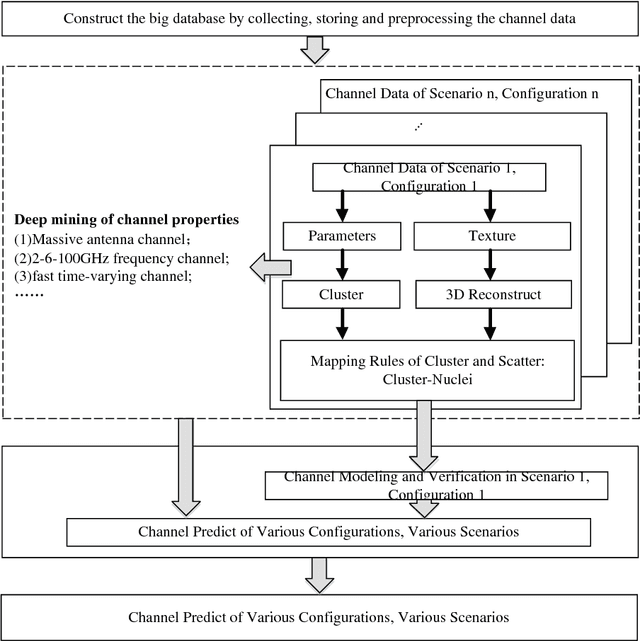
This paper investigates to identify the requirement and the development of machine learning-based mobile big data analysis through discussing the insights of challenges in the mobile big data (MBD). Furthermore, it reviews the state-of-the-art applications of data analysis in the area of MBD. Firstly, we introduce the development of MBD. Secondly, the frequently adopted methods of data analysis are reviewed. Three typical applications of MBD analysis, namely wireless channel modeling, human online and offline behavior analysis, and speech recognition in the internet of vehicles, are introduced respectively. Finally, we summarize the main challenges and future development directions of mobile big data analysis.
SEA: A Combined Model for Heat Demand Prediction
Jul 28, 2018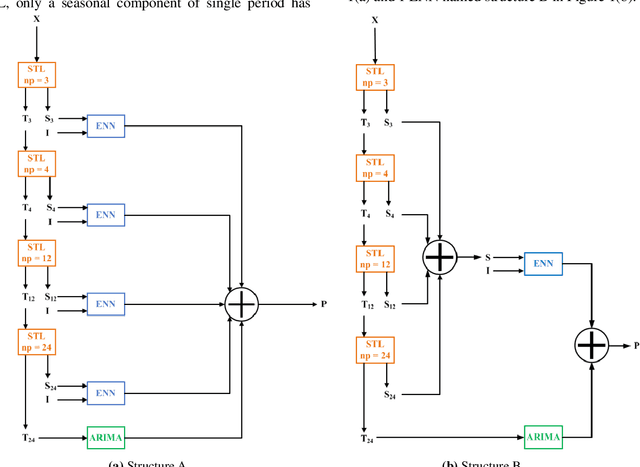
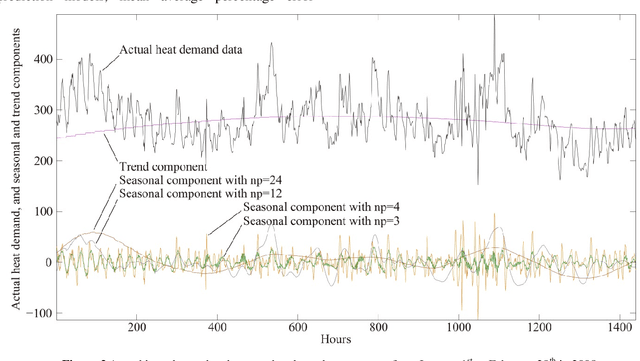
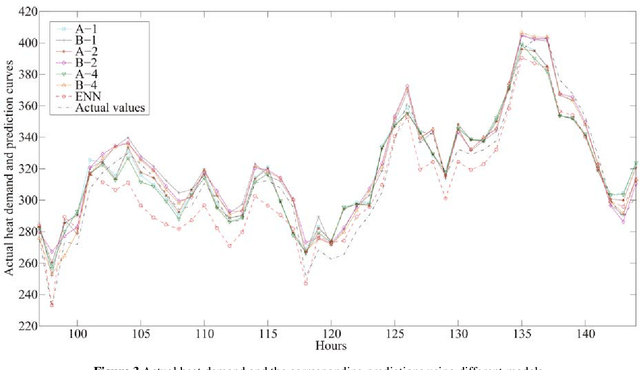
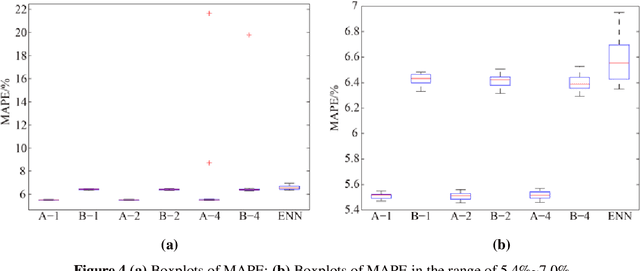
Heat demand prediction is a prominent research topic in the area of intelligent energy networks. It has been well recognized that periodicity is one of the important characteristics of heat demand. Seasonal-trend decomposition based on LOESS (STL) algorithm can analyze the periodicity of a heat demand series, and decompose the series into seasonal and trend components. Then, predicting the seasonal and trend components respectively, and combining their predictions together as the heat demand prediction is a possible way to predict heat demand. In this paper, STL-ENN-ARIMA (SEA), a combined model, was proposed based on the combination of the Elman neural network (ENN) and the autoregressive integrated moving average (ARIMA) model, which are commonly applied to heat demand prediction. ENN and ARIMA are used to predict seasonal and trend components, respectively. Experimental results demonstrate that the proposed SEA model has a promising performance.
BALSON: Bayesian Least Squares Optimization with Nonnegative L1-Norm Constraint
Jul 08, 2018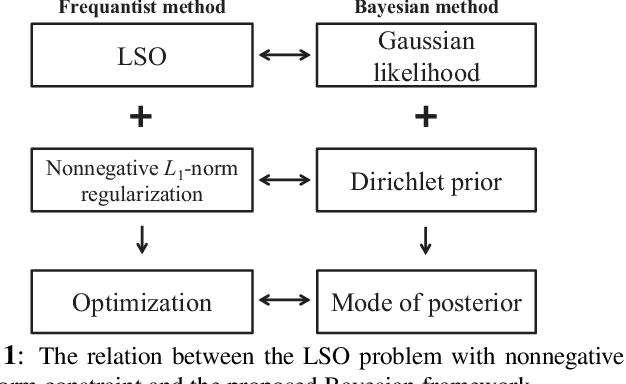
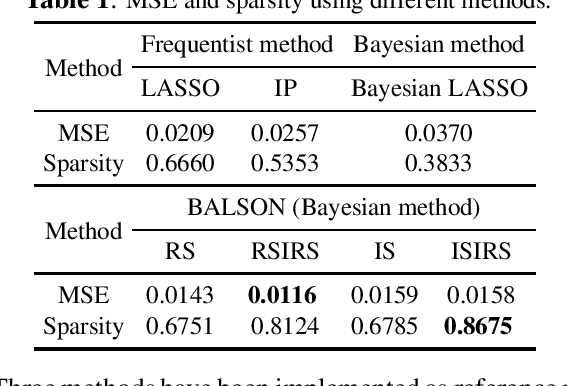
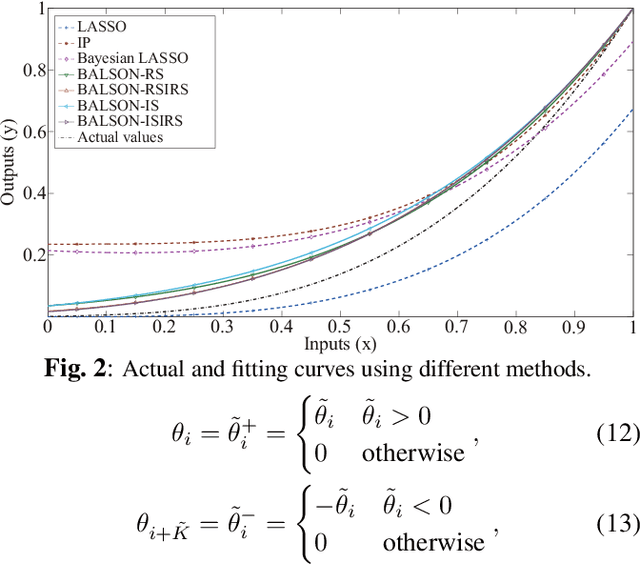
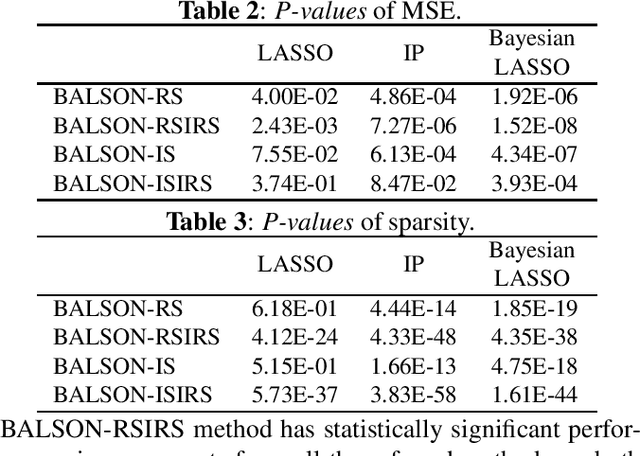
A Bayesian approach termed BAyesian Least Squares Optimization with Nonnegative L1-norm constraint (BALSON) is proposed. The error distribution of data fitting is described by Gaussian likelihood. The parameter distribution is assumed to be a Dirichlet distribution. With the Bayes rule, searching for the optimal parameters is equivalent to finding the mode of the posterior distribution. In order to explicitly characterize the nonnegative L1-norm constraint of the parameters, we further approximate the true posterior distribution by a Dirichlet distribution. We estimate the statistics of the approximating Dirichlet posterior distribution by sampling methods. Four sampling methods have been introduced. With the estimated posterior distributions, the original parameters can be effectively reconstructed in polynomial fitting problems, and the BALSON framework is found to perform better than conventional methods.