 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Discriminative Features with Multiple Granularities for Person Re-Identification
Aug 14, 2018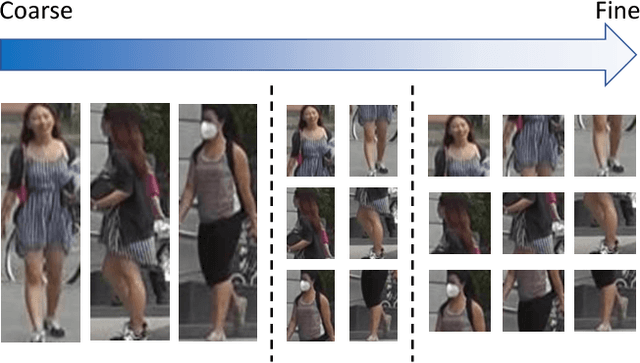
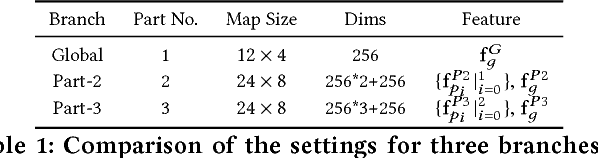
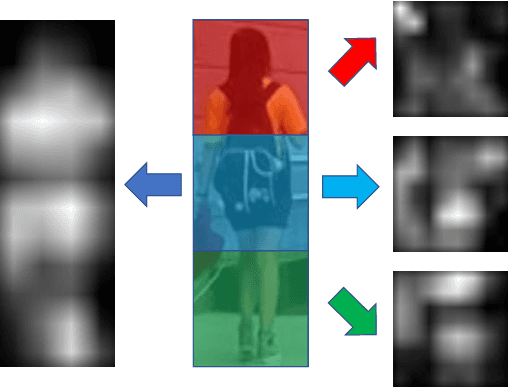
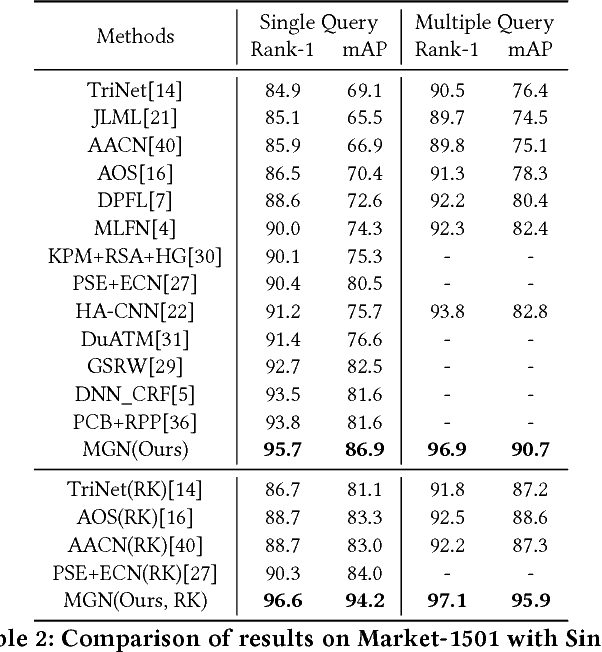
The combination of global and partial features has been an essential solution to improve discriminative performances in person re-identification (Re-ID) tasks. Previous part-based methods mainly focus on locating regions with specific pre-defined semantics to learn local representations, which increases learning difficulty but not efficient or robust to scenarios with large variances. In this paper, we propose an end-to-end feature learning strategy integrating discriminative information with various granularities. We carefully design the Multiple Granularity Network (MGN), a multi-branch deep network architecture consisting of one branch for global feature representations and two branches for local feature representations. Instead of learning on semantic regions, we uniformly partition the images into several stripes, and vary the number of parts in different local branches to obtain local feature representations with multiple granularities. Comprehensive experiments implemented on the mainstream evaluation datasets including Market-1501, DukeMTMC-reid and CUHK03 indicate that our method has robustly achieved state-of-the-art performances and outperformed any existing approaches by a large margin. For example, on Market-1501 dataset in single query mode, we achieve a state-of-the-art result of Rank-1/mAP=96.6%/94.2% after re-ranking.
IcoRating: A Deep-Learning System for Scam ICO Identification
Mar 08, 2018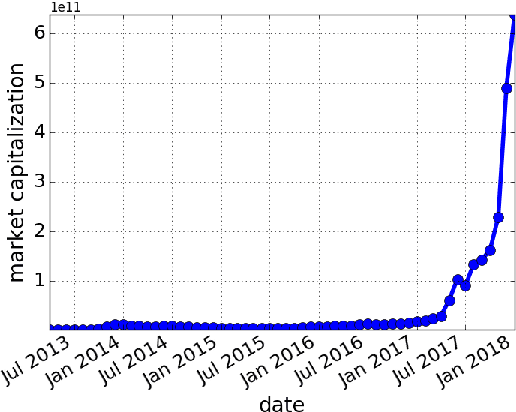
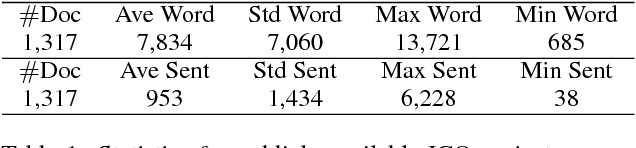
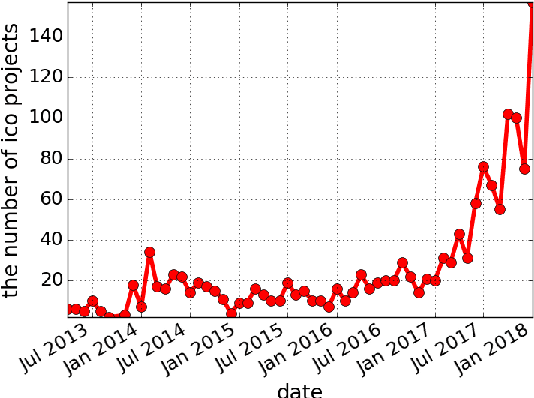
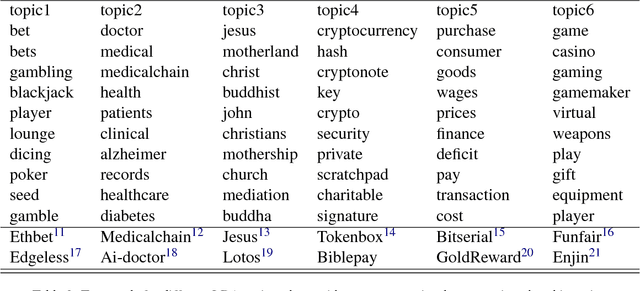
Cryptocurrencies (or digital tokens, digital currencies, e.g., BTC, ETH, XRP, NEO) have been rapidly gaining ground in use, value, and understanding among the public, bringing astonishing profits to investors. Unlike other money and banking systems, most digital tokens do not require central authorities. Being decentralized poses significant challenges for credit rating. Most ICOs are currently not subject to government regulations, which makes a reliable credit rating system for ICO projects necessary and urgent. In this paper, we introduce IcoRating, the first learning--based cryptocurrency rating system. We exploit natural-language processing techniques to analyze various aspects of 2,251 digital currencies to date, such as white paper content, founding teams, Github repositories, websites, etc. Supervised learning models are used to correlate the life span and the price change of cryptocurrencies with these features. For the best setting, the proposed system is able to identify scam ICO projects with 0.83 precision. We hope this work will help investors identify scam ICOs and attract more efforts in automatically evaluating and analyzing ICO projects.
Adversarial Learning for Neural Dialogue Generation
Sep 24, 2017


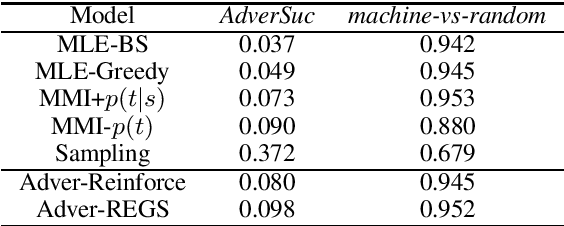
In this paper, drawing intuition from the Turing test, we propose using adversarial training for open-domain dialogue generation: the system is trained to produce sequences that are indistinguishable from human-generated dialogue utterances. We cast the task as a reinforcement learning (RL) problem where we jointly train two systems, a generative model to produce response sequences, and a discriminator---analagous to the human evaluator in the Turing test--- to distinguish between the human-generated dialogues and the machine-generated ones. The outputs from the discriminator are then used as rewards for the generative model, pushing the system to generate dialogues that mostly resemble human dialogues. In addition to adversarial training we describe a model for adversarial {\em evaluation} that uses success in fooling an adversary as a dialogue evaluation metric, while avoiding a number of potential pitfalls. Experimental results on several metrics, including adversarial evaluation, demonstrate that the adversarially-trained system generates higher-quality responses than previous baselines.
Neural Net Models for Open-Domain Discourse Coherence
Sep 24, 2017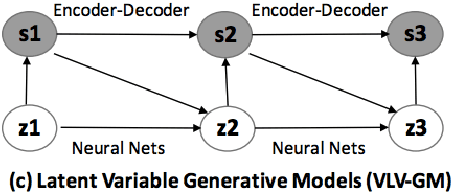
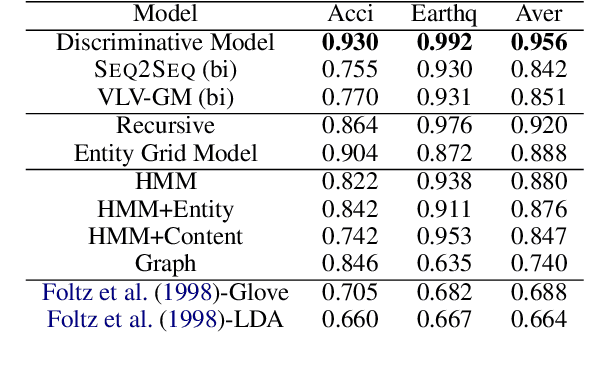
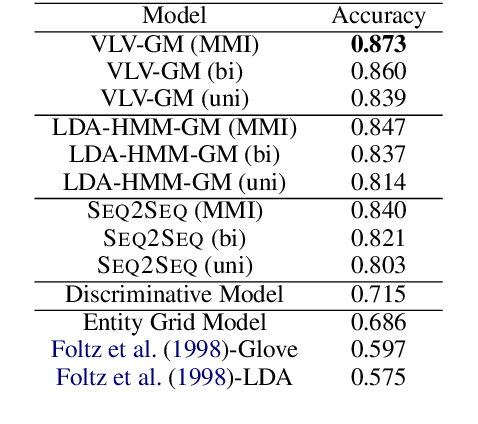

Discourse coherence is strongly associated with text quality, making it important to natural language generation and understanding. Yet existing models of coherence focus on measuring individual aspects of coherence (lexical overlap, rhetorical structure, entity centering) in narrow domains. In this paper, we describe domain-independent neural models of discourse coherence that are capable of measuring multiple aspects of coherence in existing sentences and can maintain coherence while generating new sentences. We study both discriminative models that learn to distinguish coherent from incoherent discourse, and generative models that produce coherent text, including a novel neural latent-variable Markovian generative model that captures the latent discourse dependencies between sentences in a text. Our work achieves state-of-the-art performance on multiple coherence evaluations, and marks an initial step in generating coherent texts given discourse contexts.
Learning multi-faceted representations of individuals from heterogeneous evidence using neural networks
May 11, 2017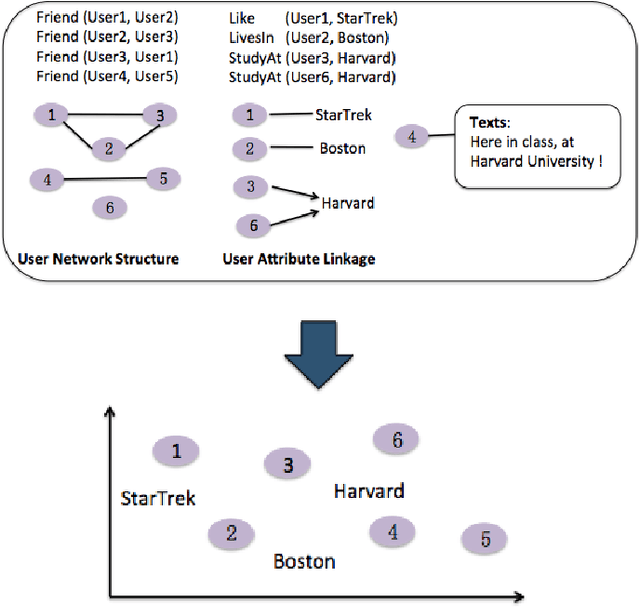
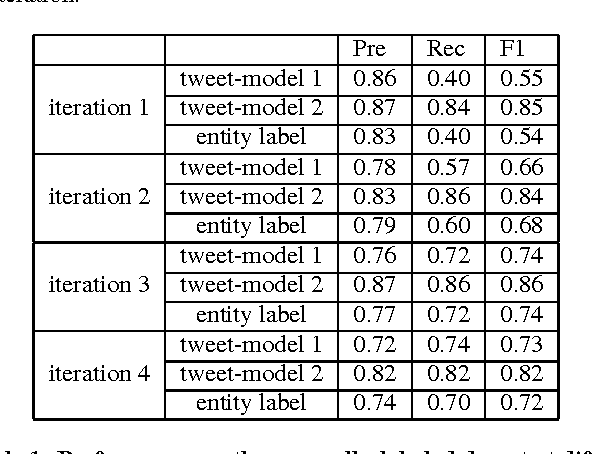
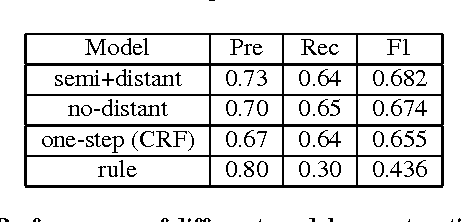
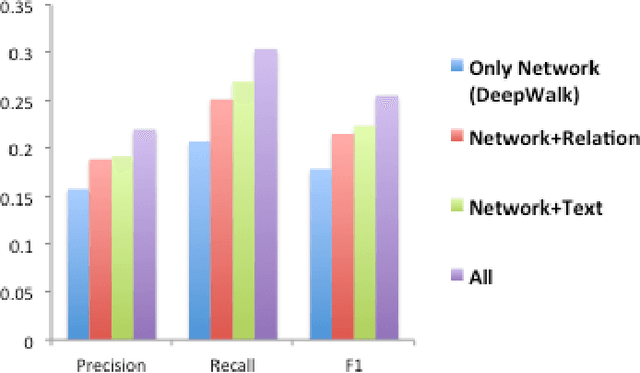
Inferring latent attributes of people online is an important social computing task, but requires integrating the many heterogeneous sources of information available on the web. We propose learning individual representations of people using neural nets to integrate rich linguistic and network evidence gathered from social media. The algorithm is able to combine diverse cues, such as the text a person writes, their attributes (e.g. gender, employer, education, location) and social relations to other people. We show that by integrating both textual and network evidence, these representations offer improved performance at four important tasks in social media inference on Twitter: predicting (1) gender, (2) occupation, (3) location, and (4) friendships for users. Our approach scales to large datasets and the learned representations can be used as general features in and have the potential to benefit a large number of downstream tasks including link prediction, community detection, or probabilistic reasoning over social networks.
Data Noising as Smoothing in Neural Network Language Models
Mar 07, 2017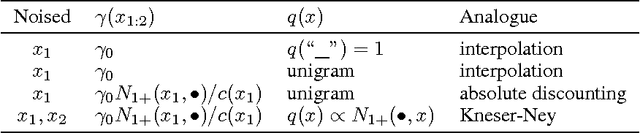
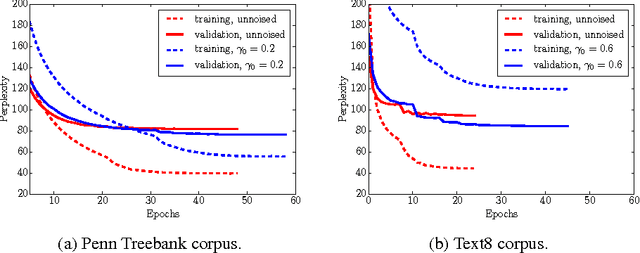
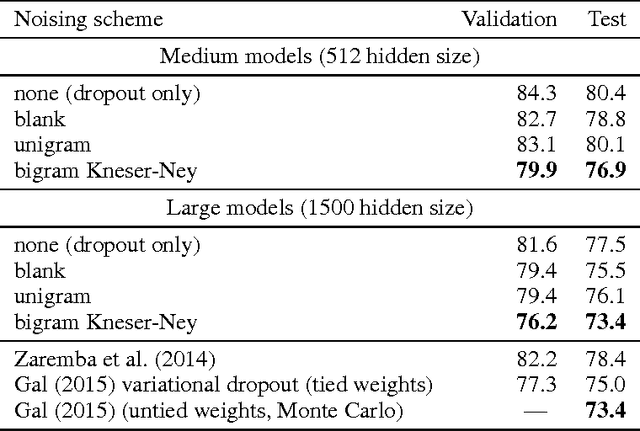
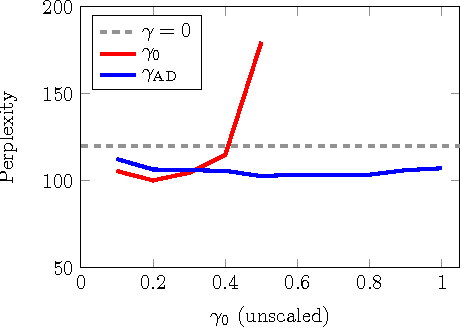
Data noising is an effective technique for regularizing neural network models. While noising is widely adopted in application domains such as vision and speech, commonly used noising primitives have not been developed for discrete sequence-level settings such as language modeling. In this paper, we derive a connection between input noising in neural network language models and smoothing in $n$-gram models. Using this connection, we draw upon ideas from smoothing to develop effective noising schemes. We demonstrate performance gains when applying the proposed schemes to language modeling and machine translation. Finally, we provide empirical analysis validating the relationship between noising and smoothing.
Data Distillation for Controlling Specificity in Dialogue Generation
Feb 22, 2017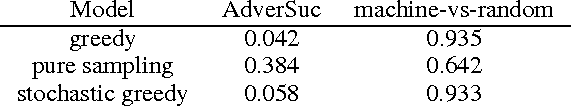
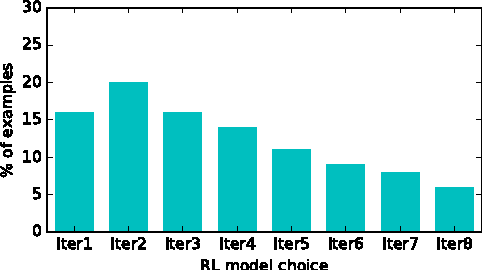
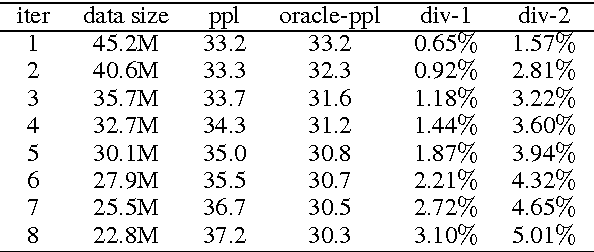
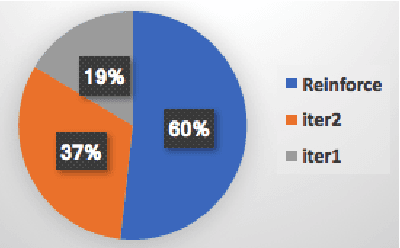
People speak at different levels of specificity in different situations. Depending on their knowledge, interlocutors, mood, etc.} A conversational agent should have this ability and know when to be specific and when to be general. We propose an approach that gives a neural network--based conversational agent this ability. Our approach involves alternating between \emph{data distillation} and model training : removing training examples that are closest to the responses most commonly produced by the model trained from the last round and then retrain the model on the remaining dataset. Dialogue generation models trained with different degrees of data distillation manifest different levels of specificity. We then train a reinforcement learning system for selecting among this pool of generation models, to choose the best level of specificity for a given input. Compared to the original generative model trained without distillation, the proposed system is capable of generating more interesting and higher-quality responses, in addition to appropriately adjusting specificity depending on the context. Our research constitutes a specific case of a broader approach involving training multiple subsystems from a single dataset distinguished by differences in a specific property one wishes to model. We show that from such a set of subsystems, one can use reinforcement learning to build a system that tailors its output to different input contexts at test time.
Learning through Dialogue Interactions by Asking Questions
Feb 13, 2017
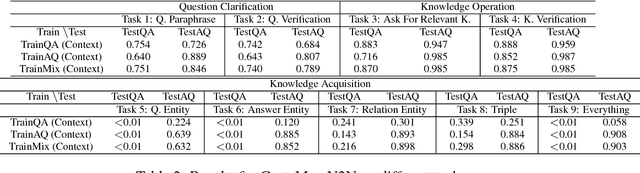

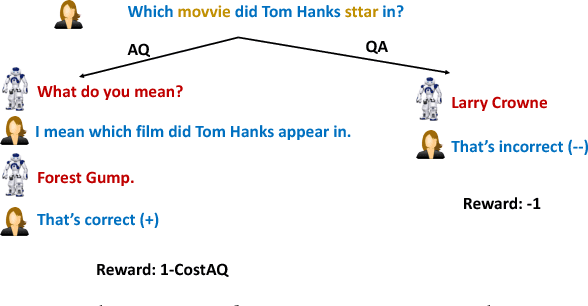
A good dialogue agent should have the ability to interact with users by both responding to questions and by asking questions, and importantly to learn from both types of interaction. In this work, we explore this direction by designing a simulator and a set of synthetic tasks in the movie domain that allow such interactions between a learner and a teacher. We investigate how a learner can benefit from asking questions in both offline and online reinforcement learning settings, and demonstrate that the learner improves when asking questions. Finally, real experiments with Mechanical Turk validate the approach. Our work represents a first step in developing such end-to-end learned interactive dialogue agents.
Learning to Decode for Future Success
Feb 03, 2017
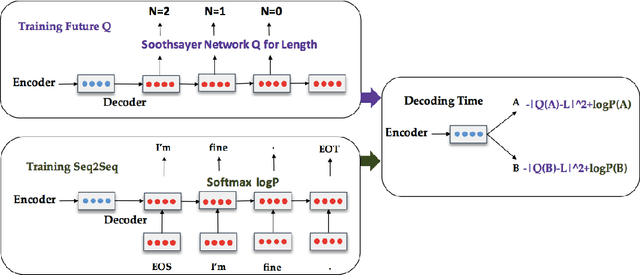


We introduce a simple, general strategy to manipulate the behavior of a neural decoder that enables it to generate outputs that have specific properties of interest (e.g., sequences of a pre-specified length). The model can be thought of as a simple version of the actor-critic model that uses an interpolation of the actor (the MLE-based token generation policy) and the critic (a value function that estimates the future values of the desired property) for decision making. We demonstrate that the approach is able to incorporate a variety of properties that cannot be handled by standard neural sequence decoders, such as sequence length and backward probability (probability of sources given targets), in addition to yielding consistent improvements in abstractive summarization and machine translation when the property to be optimized is BLEU or ROUGE scores.
Dialogue Learning With Human-In-The-Loop
Jan 13, 2017
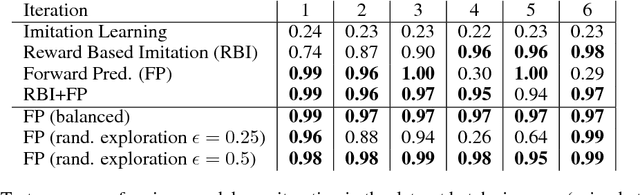
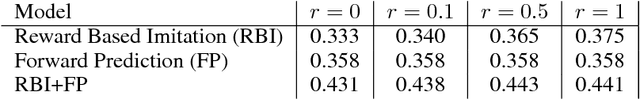
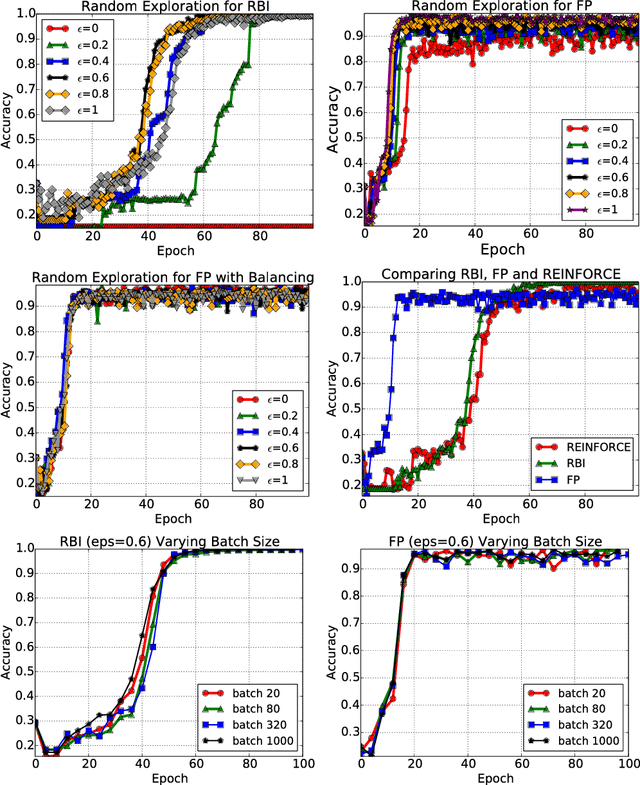
An important aspect of developing conversational agents is to give a bot the ability to improve through communicating with humans and to learn from the mistakes that it makes. Most research has focused on learning from fixed training sets of labeled data rather than interacting with a dialogue partner in an online fashion. In this paper we explore this direction in a reinforcement learning setting where the bot improves its question-answering ability from feedback a teacher gives following its generated responses. We build a simulator that tests various aspects of such learning in a synthetic environment, and introduce models that work in this regime. Finally, real experiments with Mechanical Turk validate the approach.