 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Persona-dependent LLM Alignment for the Moral Machine Experiment
Apr 15, 2025Deploying large language models (LLMs) with agency in real-world applications raises critical questions about how these models will behave. In particular, how will their decisions align with humans when faced with moral dilemmas? This study examines the alignment between LLM-driven decisions and human judgment in various contexts of the moral machine experiment, including personas reflecting different sociodemographics. We find that the moral decisions of LLMs vary substantially by persona, showing greater shifts in moral decisions for critical tasks than humans. Our data also indicate an interesting partisan sorting phenomenon, where political persona predominates the direction and degree of LLM decisions. We discuss the ethical implications and risks associated with deploying these models in applications that involve moral decisions.
Uncovering Factor Level Preferences to Improve Human-Model Alignment
Oct 09, 2024



Despite advancements in Large Language Model (LLM) alignment, understanding the reasons behind LLM preferences remains crucial for bridging the gap between desired and actual behavior. LLMs often exhibit biases or tendencies that diverge from human preferences, such as favoring certain writing styles or producing overly verbose outputs. However, current methods for evaluating preference alignment often lack explainability, relying on coarse-grained comparisons. To address this, we introduce PROFILE (PRObing Factors of InfLuence for Explainability), a novel framework that uncovers and quantifies the influence of specific factors driving preferences. PROFILE's factor level analysis explains the 'why' behind human-model alignment and misalignment, offering insights into the direction of model improvement. We apply PROFILE to analyze human and LLM preferences across three tasks: summarization, helpful response generation, and document-based question-answering. Our factor level analysis reveals a substantial discrepancy between human and LLM preferences in generation tasks, whereas LLMs show strong alignment with human preferences in evaluation tasks. We demonstrate how leveraging factor level insights, including addressing misaligned factors or exploiting the generation-evaluation gap, can improve alignment with human preferences. This work underscores the importance of explainable preference analysis and highlights PROFILE's potential to provide valuable training signals, driving further improvements in human-model alignment.
Perceptions to Beliefs: Exploring Precursory Inferences for Theory of Mind in Large Language Models
Jul 09, 2024While humans naturally develop theory of mind (ToM), the capability to understand other people's mental states and beliefs, state-of-the-art large language models (LLMs) underperform on simple ToM benchmarks. We posit that we can extend our understanding of LLMs' ToM abilities by evaluating key human ToM precursors -- perception inference and perception-to-belief inference -- in LLMs. We introduce two datasets, Percept-ToMi and Percept-FANToM, to evaluate these precursory inferences for ToM in LLMs by annotating characters' perceptions on ToMi and FANToM, respectively. Our evaluation of eight state-of-the-art LLMs reveals that the models generally perform well in perception inference while exhibiting limited capability in perception-to-belief inference (e.g., lack of inhibitory control). Based on these results, we present PercepToM, a novel ToM method leveraging LLMs' strong perception inference capability while supplementing their limited perception-to-belief inference. Experimental results demonstrate that PercepToM significantly enhances LLM's performance, especially in false belief scenarios.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
KoBBQ: Korean Bias Benchmark for Question Answering
Jul 31, 2023The BBQ (Bias Benchmark for Question Answering) dataset enables the evaluation of the social biases that language models (LMs) exhibit in downstream tasks. However, it is challenging to adapt BBQ to languages other than English as social biases are culturally dependent. In this paper, we devise a process to construct a non-English bias benchmark dataset by leveraging the English BBQ dataset in a culturally adaptive way and present the KoBBQ dataset for evaluating biases in Question Answering (QA) tasks in Korean. We identify samples from BBQ into three classes: Simply-Translated (can be used directly after cultural translation), Target-Modified (requires localization in target groups), and Sample-Removed (does not fit Korean culture). We further enhance the cultural relevance to Korean culture by adding four new categories of bias specific to Korean culture and newly creating samples based on Korean literature. KoBBQ consists of 246 templates and 4,740 samples across 12 categories of social bias. Using KoBBQ, we measure the accuracy and bias scores of several state-of-the-art multilingual LMs. We demonstrate the differences in the bias of LMs in Korean and English, clarifying the need for hand-crafted data considering cultural differences.
Learning Bill Similarity with Annotated and Augmented Corpora of Bills
Sep 14, 2021

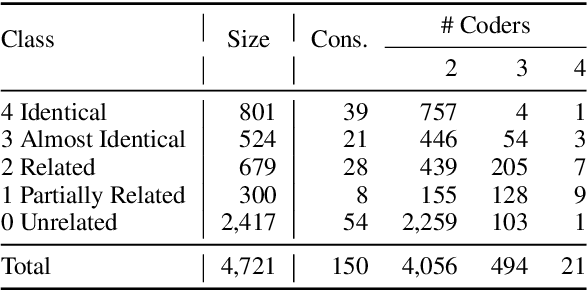

Bill writing is a critical element of representative democracy. However, it is often overlooked that most legislative bills are derived, or even directly copied, from other bills. Despite the significance of bill-to-bill linkages for understanding the legislative process, existing approaches fail to address semantic similarities across bills, let alone reordering or paraphrasing which are prevalent in legal document writing. In this paper, we overcome these limitations by proposing a 5-class classification task that closely reflects the nature of the bill generation process. In doing so, we construct a human-labeled dataset of 4,721 bill-to-bill relationships at the subsection-level and release this annotated dataset to the research community. To augment the dataset, we generate synthetic data with varying degrees of similarity, mimicking the complex bill writing process. We use BERT variants and apply multi-stage training, sequentially fine-tuning our models with synthetic and human-labeled datasets. We find that the predictive performance significantly improves when training with both human-labeled and synthetic data. Finally, we apply our trained model to infer section- and bill-level similarities. Our analysis shows that the proposed methodology successfully captures the similarities across legal documents at various levels of aggregation.
Efficient Contrastive Learning via Novel Data Augmentation and Curriculum Learning
Sep 10, 2021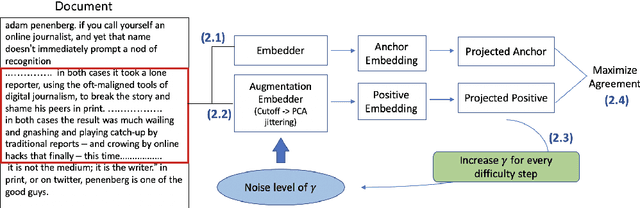

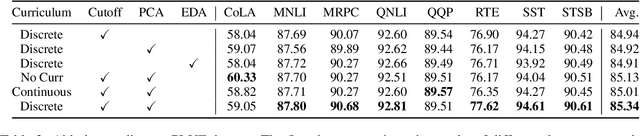
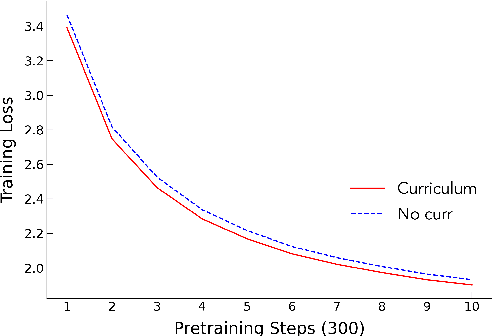
We introduce EfficientCL, a memory-efficient continual pretraining method that applies contrastive learning with novel data augmentation and curriculum learning. For data augmentation, we stack two types of operation sequentially: cutoff and PCA jittering. While pretraining steps proceed, we apply curriculum learning by incrementing the augmentation degree for each difficulty step. After data augmentation is finished, contrastive learning is applied on projected embeddings of original and augmented examples. When finetuned on GLUE benchmark, our model outperforms baseline models, especially for sentence-level tasks. Additionally, this improvement is capable with only 70% of computational memory compared to the baseline model.
Toward Dimensional Emotion Detection from Categorical Emotion Annotations
Nov 06, 2019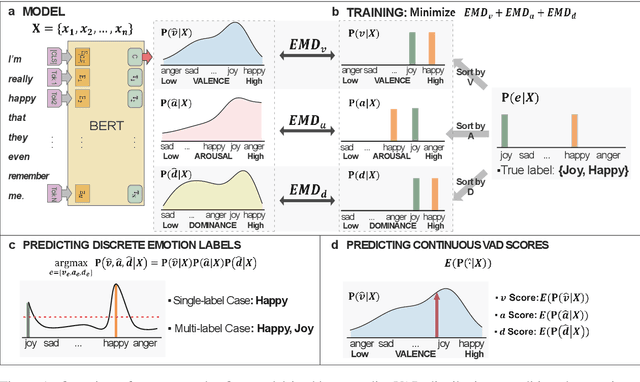
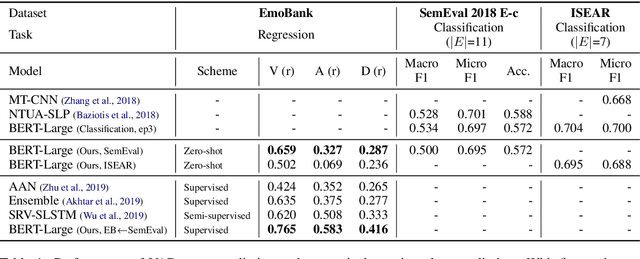
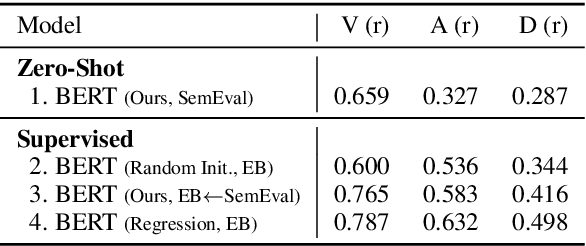
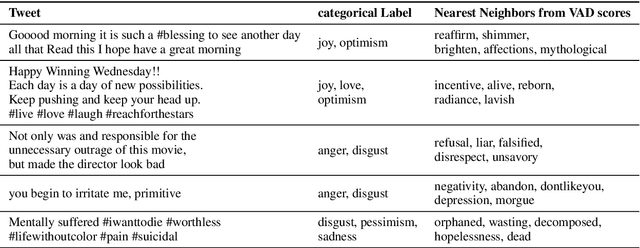
We propose a framework which makes a model predict fine-grained dimensional emotions (valence-arousal-dominance, VAD) trained on corpus annotated with coarse-grained categorical emotions. We train a model by minimizing EMD distances between predicted VAD score distribution and \textit{sorted} categorical emotion distributions in terms of VAD, as a proxy of target VAD score distributions. With our model, we can simultaneously classify a given sentence to categorical emotions as well as predict VAD scores. We use pre-trained BERT-Large and fine-tune on SemEval dataset (11 categorical emotions) and evaluate on EmoBank (VAD dimensional emotions), in order to show our approach reaches comparable performance to that of the state-of-the-art classifiers in categorical emotion classification task and significant positive correlations with ground truth VAD scores. Also, if one continues training our model with supervision of VAD labels, it outperforms state-of-the-art VAD regression models. We further present examples showing our model can annotate emotional words suitable for a given text even those words are not seen as categorical labels during training.