 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRolling Shutter Camera Synchronization with Sub-millisecond Accuracy
Feb 28, 2019
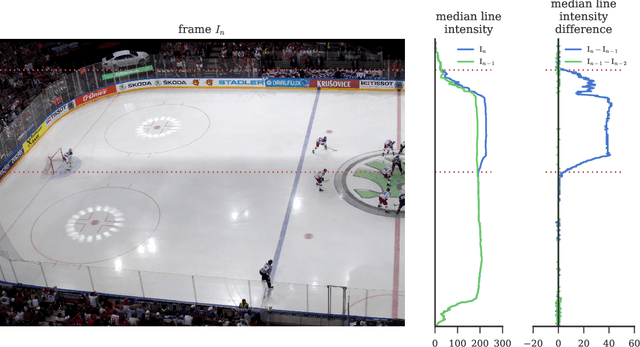
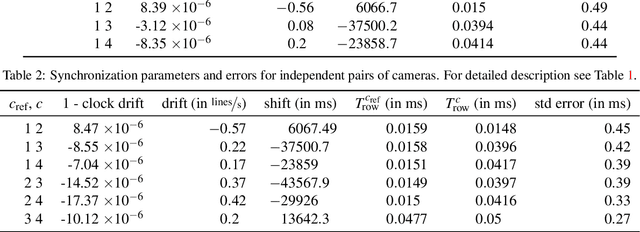
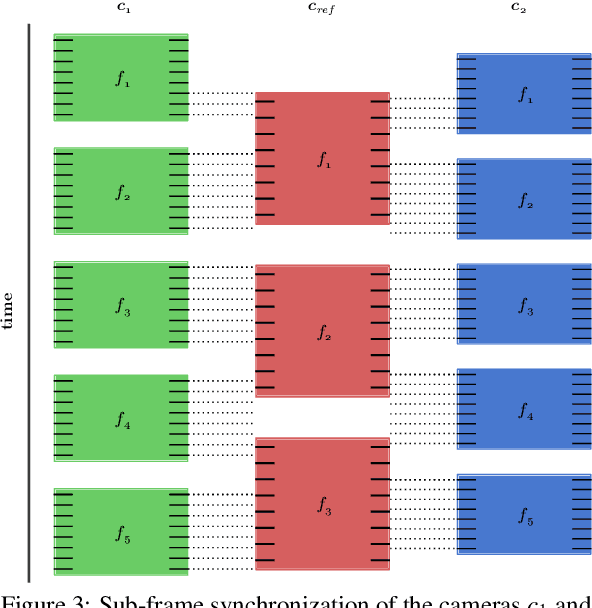
A simple method for synchronization of video streams with a precision better than one millisecond is proposed. The method is applicable to any number of rolling shutter cameras and when a few photographic flashes or other abrupt lighting changes are present in the video. The approach exploits the rolling shutter sensor property that every sensor row starts its exposure with a small delay after the onset of the previous row. The cameras may have different frame rates and resolutions, and need not have overlapping fields of view. The method was validated on five minutes of four streams from an ice hockey match. The found transformation maps events visible in all cameras to a reference time with a standard deviation of the temporal error in the range of 0.3 to 0.5 milliseconds. The quality of the synchronization is demonstrated on temporally and spatially overlapping images of a fast moving puck observed in two cameras.
* 8 pages, 10 figures, published at VISAPP 2017
Flash Lightens Gray Pixels
Feb 27, 2019

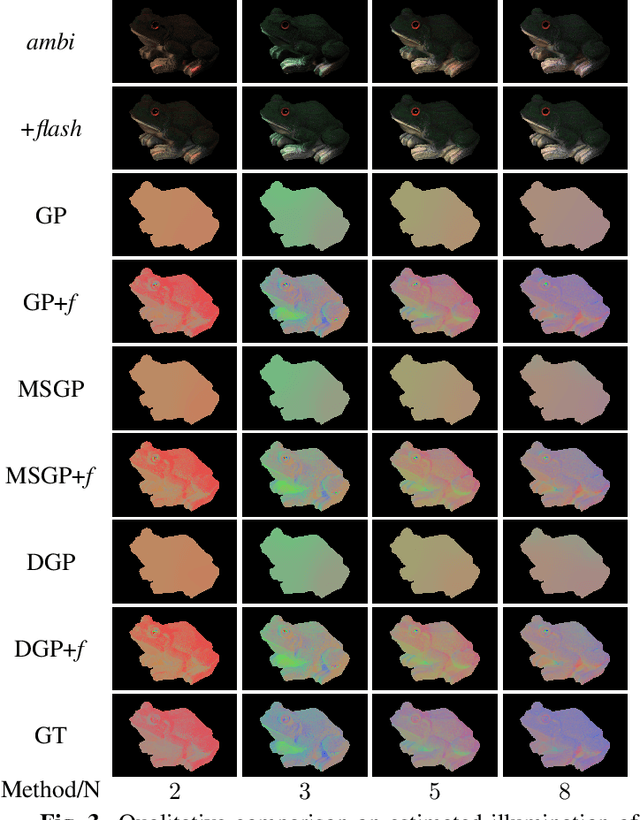

In the real world, a scene is usually cast by multiple illuminants and herein we address the problem of spatial illumination estimation. Our solution is based on detecting gray pixels with the help of flash photography. We show that flash photography significantly improves the performance of gray pixel detection without illuminant prior, training data or calibration of the flash. We also introduce a novel flash photography dataset generated from the MIT intrinsic dataset.
On Finding Gray Pixels
Jan 12, 2019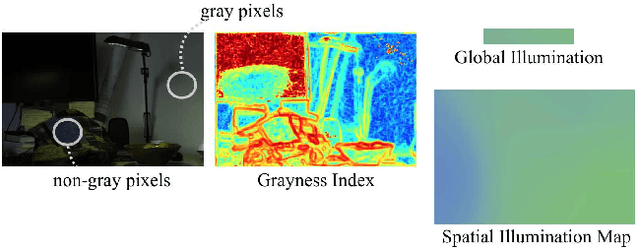
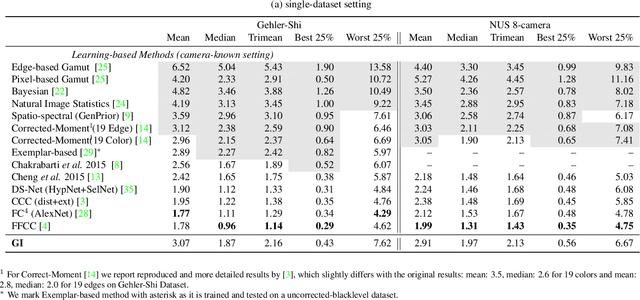

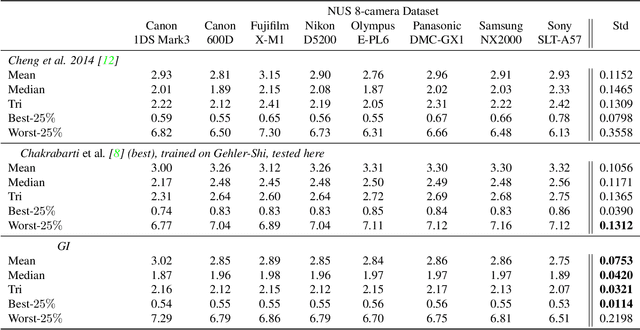
We propose a novel grayness index for finding gray pixels and demonstrate its effectiveness and efficiency in illumination estimation. The grayness index, GI in short, is derived using the Dichromatic Reflection Model and is learning-free. The proposed GI allows estimating one or multiple illumination sources in color-biased images. On standard single-illumination and multiple-illumination estimation benchmarks, GI outperforms state-of-the-art statistical methods and many recent deep net methods. GI is simple and fast, written in a few dozen lines, processing a 1080p image in about 0.4 seconds with a non-optimized Matlab code.
Object Tracking by Reconstruction with View-Specific Discriminative Correlation Filters
Nov 27, 2018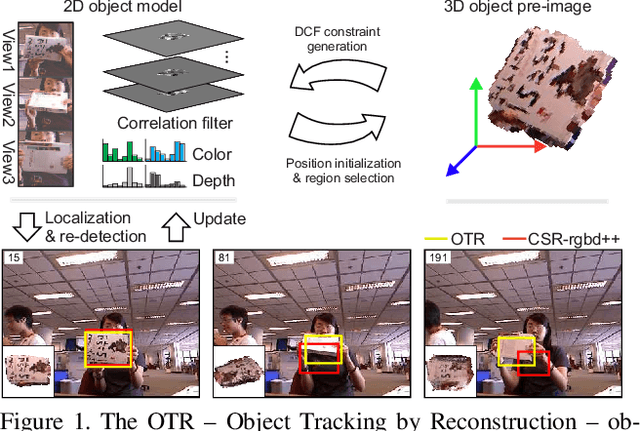
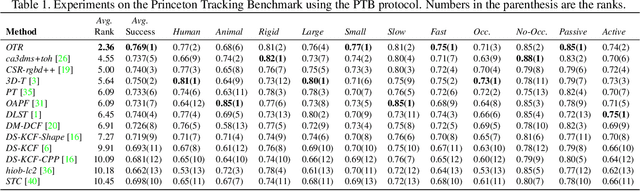
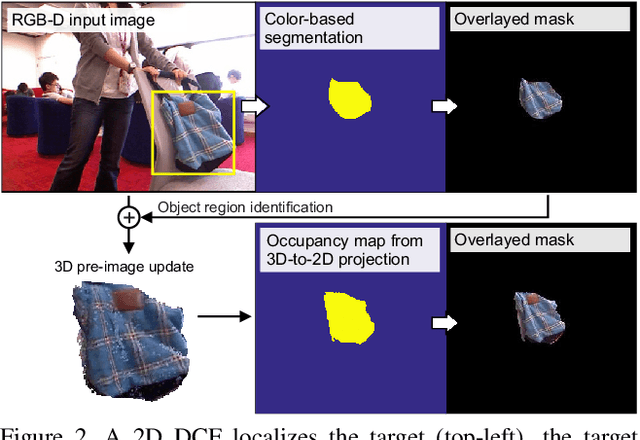
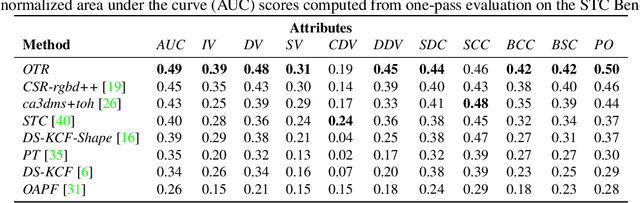
Standard RGB-D trackers treat the target as an inherently 2D structure, which makes modelling appearance changes related even to simple out-of-plane rotation highly challenging. We address this limitation by proposing a novel long-term RGB-D tracker - Object Tracking by Reconstruction (OTR). The tracker performs online 3D target reconstruction to facilitate robust learning of a set of view-specific discriminative correlation filters (DCFs). The 3D reconstruction supports two performance-enhancing features: (i) generation of accurate spatial support for constrained DCF learning from its 2D projection and (ii) point cloud based estimation of 3D pose change for selection and storage of view-specific DCFs which are used to robustly localize the target after out-of-view rotation or heavy occlusion. Extensive evaluation of OTR on the challenging Princeton RGB-D tracking and STC Benchmarks shows it outperforms the state-of-the-art by a large margin.
LSD$_2$ - Joint Denoising and Deblurring of Short and Long Exposure Images with Convolutional Neural Networks
Nov 23, 2018
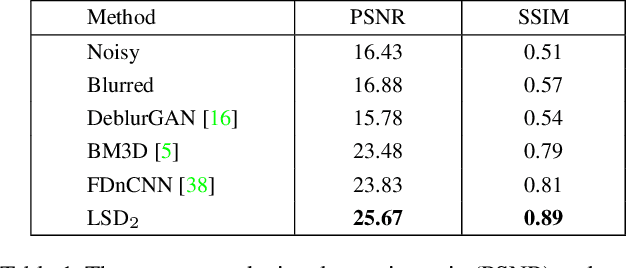

This paper addresses the challenging problem of acquiring high-quality photographs with handheld smartphone cameras in low-light imaging conditions. We propose an approach based on capturing pairs of short and long exposure images in rapid succession and fusing them into a single high-quality photograph using a convolutional neural network. The network input consists of a pair of images, where the short exposure image is typically noisy and has poor colors due to low lighting and the long exposure image is susceptible to motion blur when the camera or scene objects are moving. The network is trained using a combination of real and simulated data and we propose a novel approach for generating realistic synthetic short-long exposure image pairs. Our approach is the first one to address the joint denoising and deblurring problem using deep networks. It outperforms the existing denoising and deblurring methods in this task and allows to produce good images in extremely challenging conditions. Our source code, pretrained models and data will be made publicly available to facilitate future research.
A Summary of the 4th International Workshop on Recovering 6D Object Pose
Oct 09, 2018
This document summarizes the 4th International Workshop on Recovering 6D Object Pose which was organized in conjunction with ECCV 2018 in Munich. The workshop featured four invited talks, oral and poster presentations of accepted workshop papers, and an introduction of the BOP benchmark for 6D object pose estimation. The workshop was attended by 100+ people working on relevant topics in both academia and industry who shared up-to-date advances and discussed open problems.
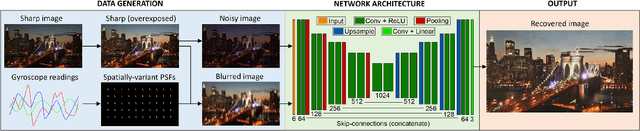
Inertial-aided Motion Deblurring with Deep Networks
Oct 01, 2018
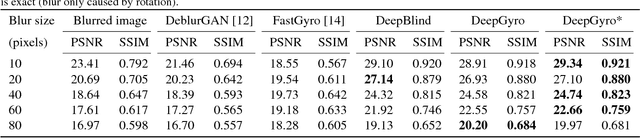

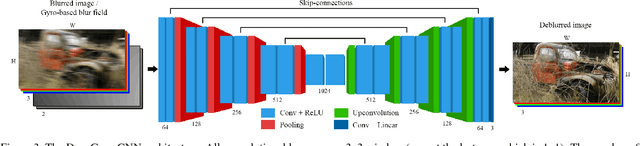
We propose an inertial-aided deblurring method that incorporates gyroscope measurements into a convolutional neural network (CNN). With the help of inertial measurements, it can handle extremely strong and spatially-variant motion blur. At the same time, the image data is used to overcome the limitations of gyro-based blur estimation. To train our network, we also introduce a novel way of generating realistic training data using the gyroscope. The evaluation shows a clear improvement in visual quality over the state-of-the-art while achieving real-time performance. Furthermore, the method is shown to improve the performance of existing feature detectors and descriptors against the motion blur.
Repeatability Is Not Enough: Learning Affine Regions via Discriminability
Aug 28, 2018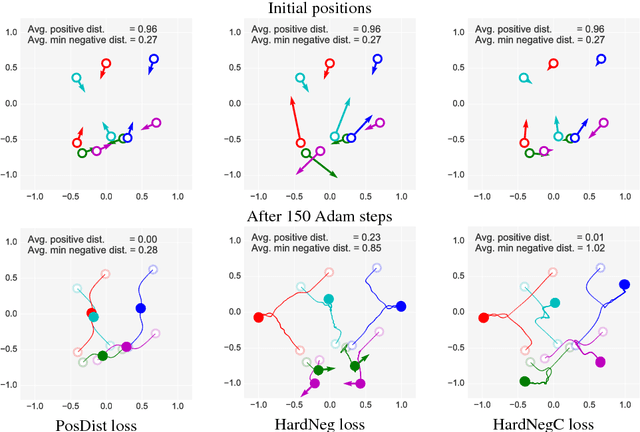
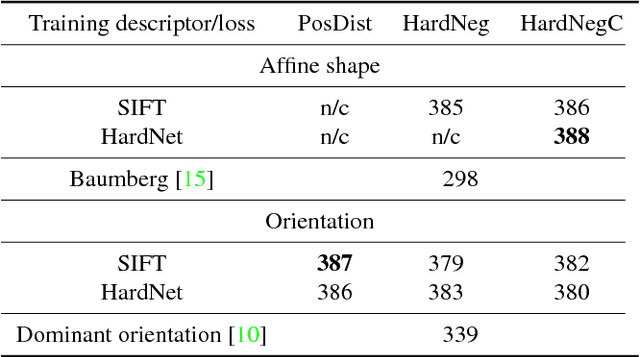
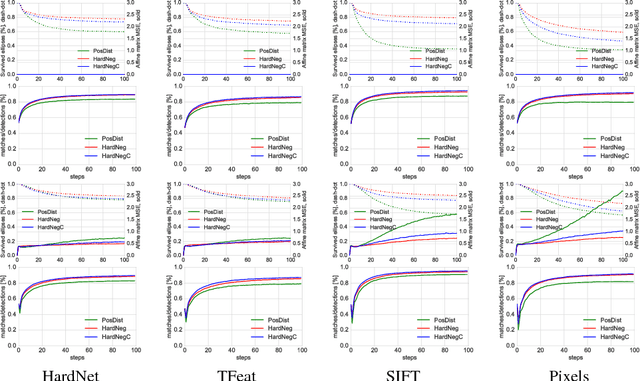
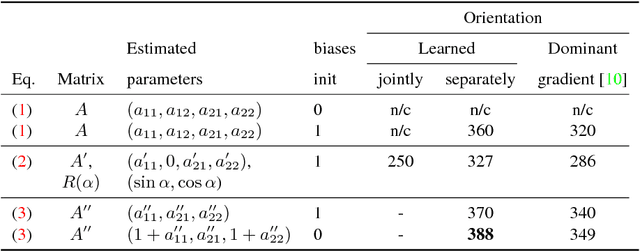
A method for learning local affine-covariant regions is presented. We show that maximizing geometric repeatability does not lead to local regions, a.k.a features,that are reliably matched and this necessitates descriptor-based learning. We explore factors that influence such learning and registration: the loss function, descriptor type, geometric parametrization and the trade-off between matchability and geometric accuracy and propose a novel hard negative-constant loss function for learning of affine regions. The affine shape estimator -- AffNet -- trained with the hard negative-constant loss outperforms the state-of-the-art in bag-of-words image retrieval and wide baseline stereo. The proposed training process does not require precisely geometrically aligned patches.The source codes and trained weights are available at https://github.com/ducha-aiki/affnet
BOP: Benchmark for 6D Object Pose Estimation
Aug 24, 2018
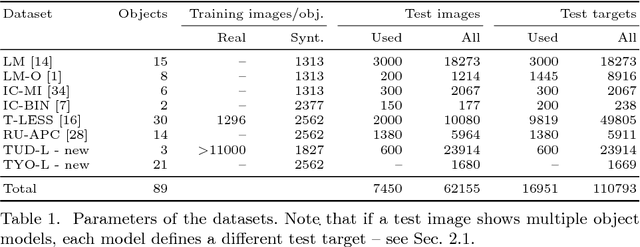

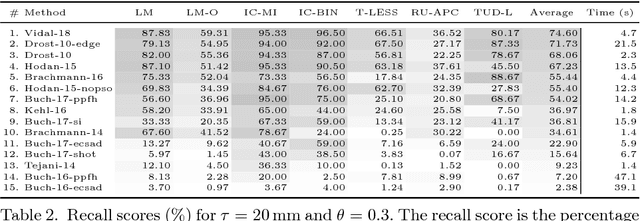
We propose a benchmark for 6D pose estimation of a rigid object from a single RGB-D input image. The training data consists of a texture-mapped 3D object model or images of the object in known 6D poses. The benchmark comprises of: i) eight datasets in a unified format that cover different practical scenarios, including two new datasets focusing on varying lighting conditions, ii) an evaluation methodology with a pose-error function that deals with pose ambiguities, iii) a comprehensive evaluation of 15 diverse recent methods that captures the status quo of the field, and iv) an online evaluation system that is open for continuous submission of new results. The evaluation shows that methods based on point-pair features currently perform best, outperforming template matching methods, learning-based methods and methods based on 3D local features. The project website is available at bop.felk.cvut.cz.
Performance Analysis and Robustification of Single-query 6-DoF Camera Pose Estimation
Aug 17, 2018

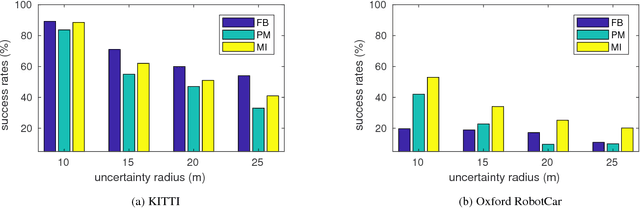
We consider a single-query 6-DoF camera pose estimation with reference images and a point cloud, i.e. the problem of estimating the position and orientation of a camera by using reference images and a point cloud. In this work, we perform a systematic comparison of three state-of-the-art strategies for 6-DoF camera pose estimation, i.e. feature-based, photometric-based and mutual-information-based approaches. The performance of the studied methods is evaluated on two standard datasets in terms of success rate, translation error and max orientation error. Building on the results analysis, we propose a hybrid approach that combines feature-based and mutual-information-based pose estimation methods since it provides complementary properties for pose estimation. Experiments show that (1) in cases with large environmental variance, the hybrid approach outperforms feature-based and mutual-information-based approaches by an average of 25.1% and 5.8% in terms of success rate, respectively; (2) in cases where query and reference images are captured at similar imaging conditions, the hybrid approach performs similarly as the feature-based approach, but outperforms both photometric-based and mutual-information-based approaches with a clear margin; (3) the feature-based approach is consistently more accurate than mutual-information-based and photometric-based approaches when at least 4 consistent matching points are found between the query and reference images.