 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Monocular Depth Estimation with Lightweight 3D Point Fusion
Dec 18, 2020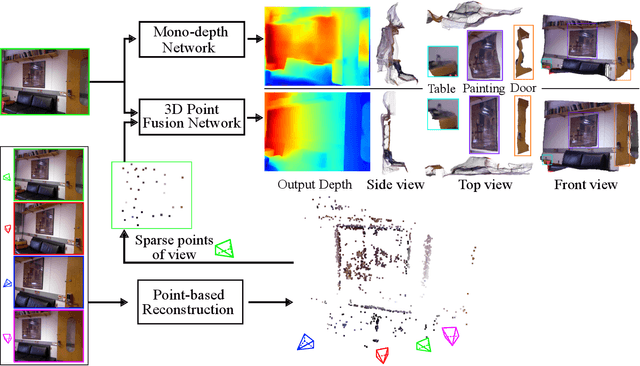
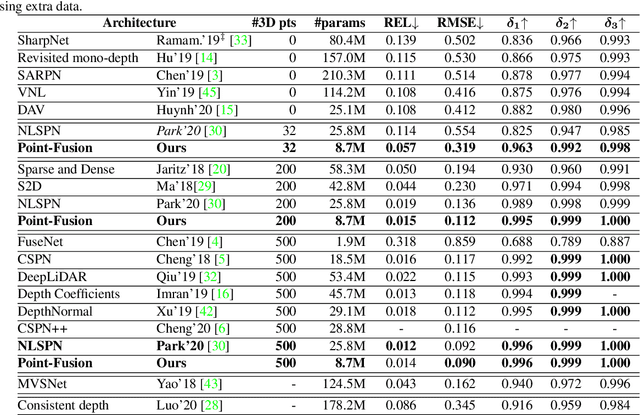
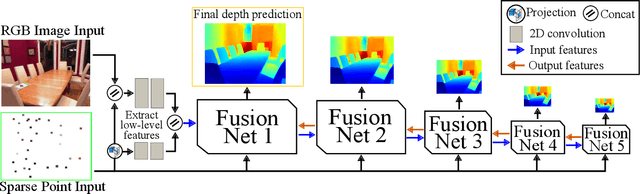
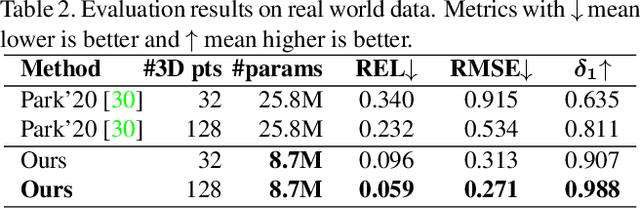
In this paper, we address the problem of fusing monocular depth estimation with a conventional multi-view stereo or SLAM to exploit the best of both worlds, that is, the accurate dense depth of the first one and lightweightness of the second one. More specifically, we use a conventional pipeline to produce a sparse 3D point cloud that is fed to a monocular depth estimation network to enhance its performance. In this way, we can achieve accuracy similar to multi-view stereo with a considerably smaller number of weights. We also show that even as few as 32 points is sufficient to outperform the best monocular depth estimation methods, and around 200 points to gain full advantage of the additional information. Moreover, we demonstrate the efficacy of our approach by integrating it with a SLAM system built-in on mobile devices.
FMODetect: Robust Detection and Trajectory Estimation of Fast Moving Objects
Dec 15, 2020
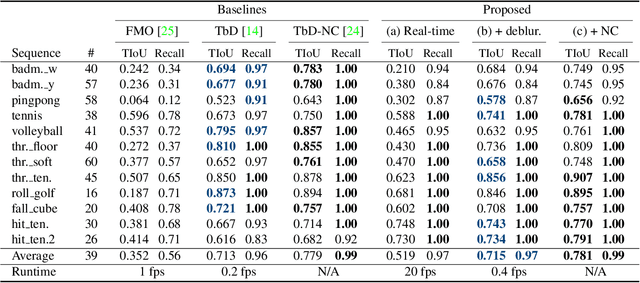
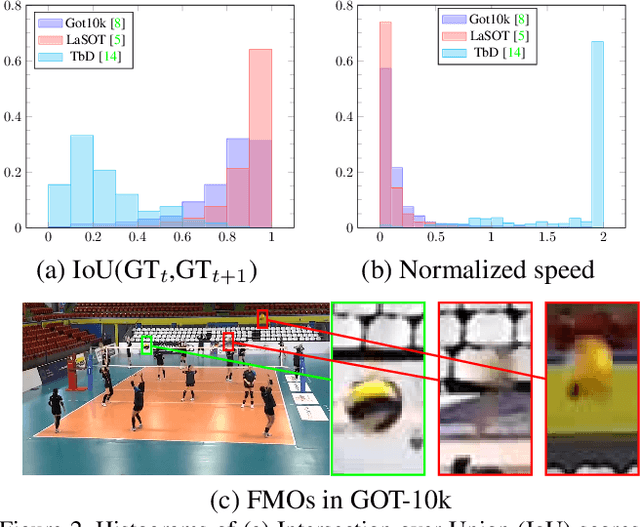

We propose the first learning-based approach for detection and trajectory estimation of fast moving objects. Such objects are highly blurred and move over large distances within one video frame. Fast moving objects are associated with a deblurring and matting problem, also called deblatting. Instead of solving the complex deblatting problem jointly, we split the problem into matting and deblurring and solve them separately. The proposed method first detects all fast moving objects as a truncated distance function to the trajectory. Subsequently, a matting and fitting network for each detected object estimates the object trajectory and its blurred appearance without background. For the sharp appearance estimation, we propose an energy minimization based deblurring. The state-of-the-art methods are outperformed in terms of trajectory estimation and sharp appearance reconstruction. Compared to other methods, such as deblatting, the inference is of several orders of magnitude faster and allows applications such as real-time fast moving object detection and retrieval in large video collections.
DeFMO: Deblurring and Shape Recovery of Fast Moving Objects
Dec 01, 2020
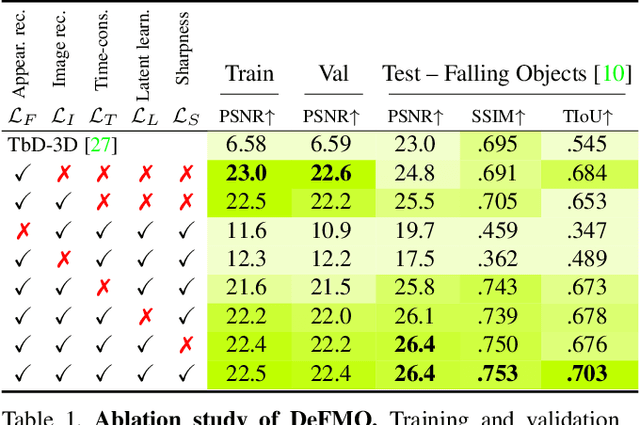
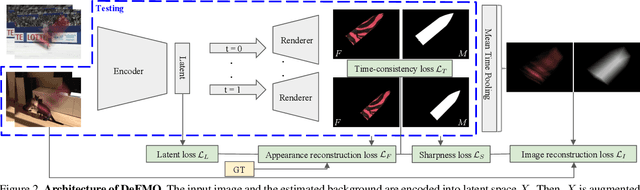
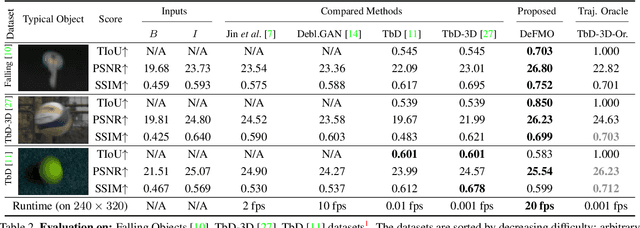
Objects moving at high speed appear significantly blurred when captured with cameras. The blurry appearance is especially ambiguous when the object has complex shape or texture. In such cases, classical methods, or even humans, are unable to recover the object's appearance and motion. We propose a method that, given a single image with its estimated background, outputs the object's appearance and position in a series of sub-frames as if captured by a high-speed camera (i.e. temporal super-resolution). The proposed generative model embeds an image of the blurred object into a latent space representation, disentangles the background, and renders the sharp appearance. Inspired by the image formation model, we design novel self-supervised loss function terms that boost performance and show good generalization capabilities. The proposed DeFMO method is trained on a complex synthetic dataset, yet it performs well on real-world data from several datasets. DeFMO outperforms the state of the art and generates high-quality temporal super-resolution frames.
RGBD-Net: Predicting color and depth images for novel views synthesis
Nov 29, 2020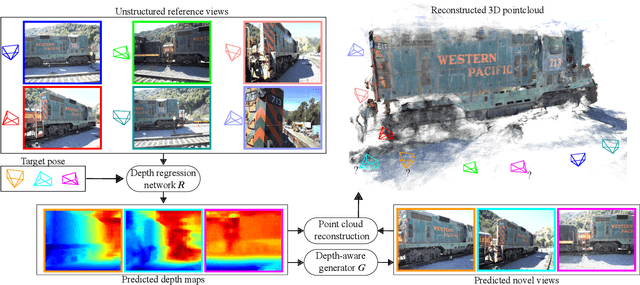
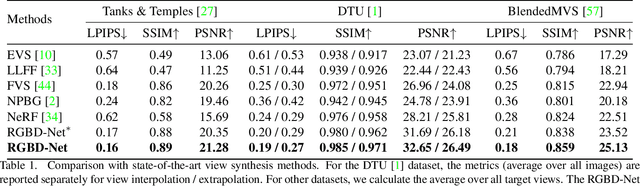
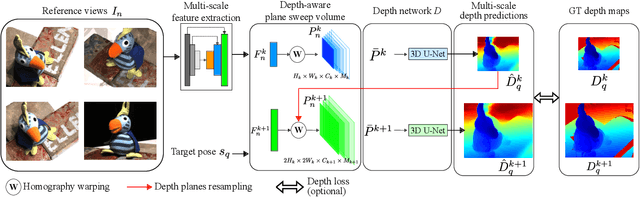
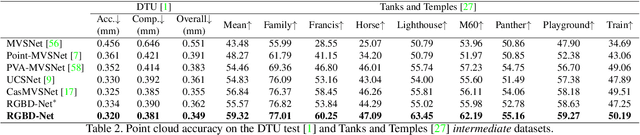
We address the problem of novel view synthesis from an unstructured set of reference images. A new method called RGBD-Net is proposed to predict the depth map and the color images at the target pose in a multi-scale manner. The reference views are warped to the target pose to obtain multi-scale plane sweep volumes, which are then passed to our first module, a hierarchical depth regression network which predicts the depth map of the novel view. Second, a depth-aware generator network refines the warped novel views and renders the final target image. These two networks can be trained with or without depth supervision. In experimental evaluation, RGBD-Net not only produces novel views with higher quality than the previous state-of-the-art methods, but also the obtained depth maps enable reconstruction of more accurate 3D point clouds than the existing multi-view stereo methods. The results indicate that RGBD-Net generalizes well to previously unseen data.
Efficient Initial Pose-graph Generation for Global SfM
Nov 26, 2020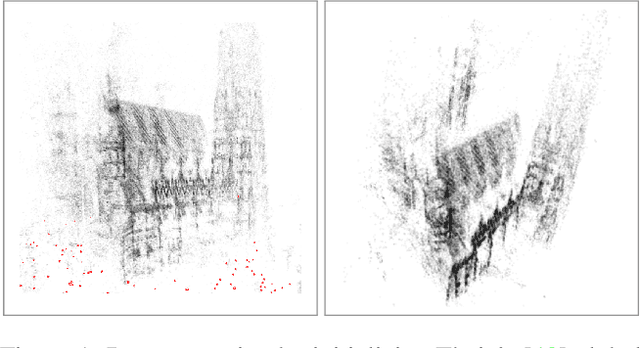
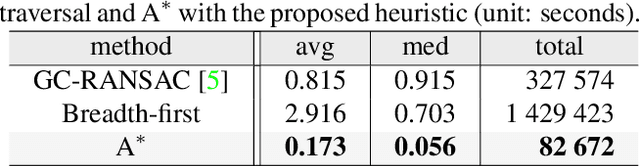
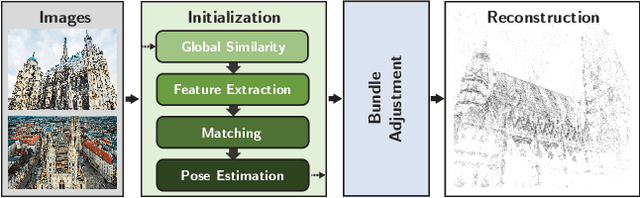
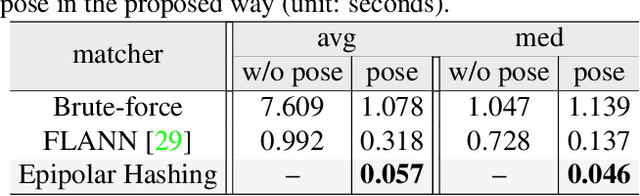
We propose ways to speed up the initial pose-graph generation for global Structure-from-Motion algorithms. To avoid forming tentative point correspondences by FLANN and geometric verification by RANSAC, which are the most time-consuming steps of the pose-graph creation, we propose two new methods - built on the fact that image pairs usually are matched consecutively. Thus, candidate relative poses can be recovered from paths in the partly-built pose-graph. We propose a heuristic for the A* traversal, considering global similarity of images and the quality of the pose-graph edges. Given a relative pose from a path, descriptor-based feature matching is made "light-weight" by exploiting the known epipolar geometry. To speed up PROSAC-based sampling when RANSAC is applied, we propose a third method to order the correspondences by their inlier probabilities from previous estimations. The algorithms are tested on 402130 image pairs from the 1DSfM dataset and they speed up the feature matching 17 times and pose estimation 5 times.
Fast Fourier Intrinsic Network
Nov 09, 2020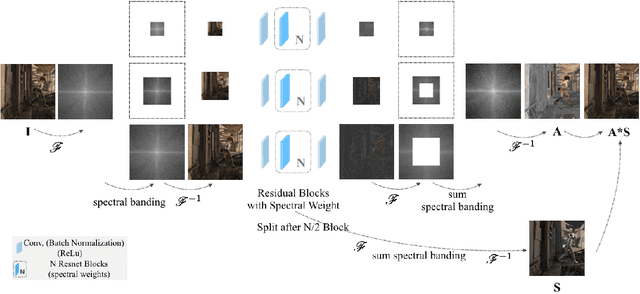
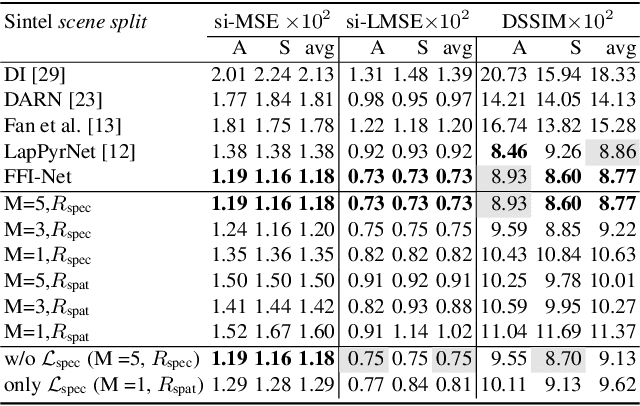
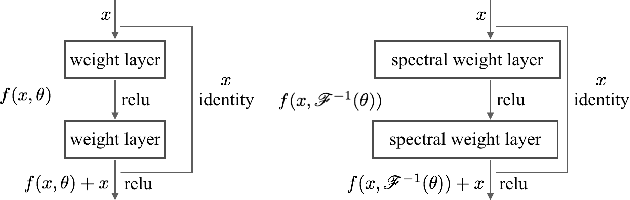
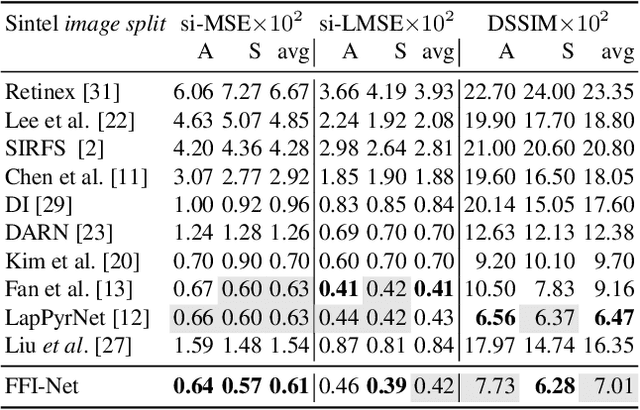
We address the problem of decomposing an image into albedo and shading. We propose the Fast Fourier Intrinsic Network, FFI-Net in short, that operates in the spectral domain, splitting the input into several spectral bands. Weights in FFI-Net are optimized in the spectral domain, allowing faster convergence to a lower error. FFI-Net is lightweight and does not need auxiliary networks for training. The network is trained end-to-end with a novel spectral loss which measures the global distance between the network prediction and corresponding ground truth. FFI-Net achieves state-of-the-art performance on MPI-Sintel, MIT Intrinsic, and IIW datasets.
BOP Challenge 2020 on 6D Object Localization
Oct 13, 2020
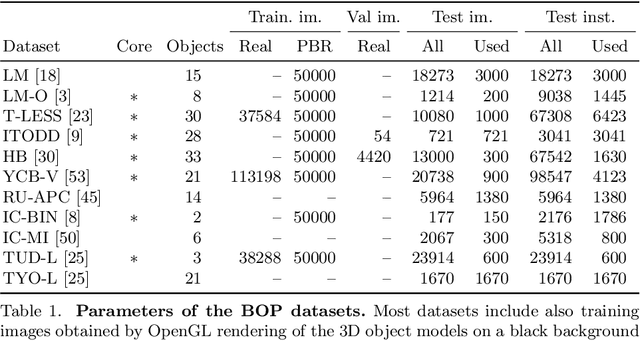

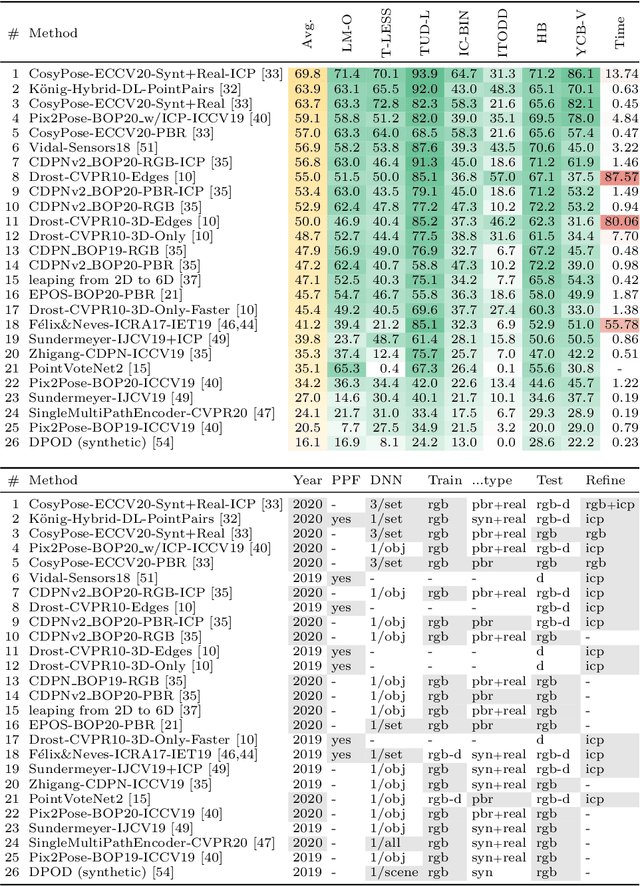
This paper presents the evaluation methodology, datasets, and results of the BOP Challenge 2020, the third in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB-D image. In 2020, to reduce the domain gap between synthetic training and real test RGB images, the participants were provided 350K photorealistic training images generated by BlenderProc4BOP, a new open-source and light-weight physically-based renderer (PBR) and procedural data generator. Methods based on deep neural networks have finally caught up with methods based on point pair features, which were dominating previous editions of the challenge. Although the top-performing methods rely on RGB-D image channels, strong results were achieved when only RGB channels were used at both training and test time - out of the 26 evaluated methods, the third method was trained on RGB channels of PBR and real images, while the fifth on RGB channels of PBR images only. Strong data augmentation was identified as a key component of the top-performing CosyPose method, and the photorealism of PBR images was demonstrated effective despite the augmentation. The online evaluation system stays open and is available on the project website: bop.felk.cvut.cz.
ArXiving Before Submission Helps Everyone
Oct 11, 2020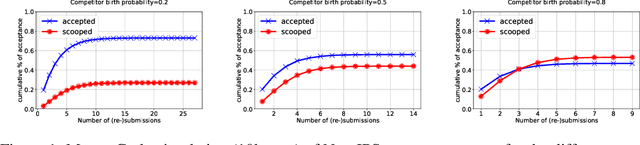
We claim, and present evidence, that allowing arXiv publication before a conference or journal submission benefits researchers, especially early career, as well as the whole scientific community. Specifically, arXiving helps professional identity building, protects against independent re-discovery, idea theft and gate-keeping; it facilitates open research result distribution and reduces inequality. The advantages dwarf the drawbacks -- mainly the relative increase in acceptance rate of papers of well-known authors -- which studies show to be marginal. Analyzing the pros and cons of arXiving papers, we conclude that requiring preprints be anonymous is nearly as detrimental as not allowing them. We see no reasons why anyone but the authors should decide whether to arXiv or not.
Text Recognition -- Real World Data and Where to Find Them
Jul 17, 2020



We present a method for exploiting weakly annotated images to improve text extraction pipelines. The approach uses an arbitrary end-to-end text recognition system to obtain text region proposals and their, possibly erroneous, transcriptions. The proposed method includes matching of imprecise transcription to weak annotations and edit distance guided neighbourhood search. It produces nearly error-free, localised instances of scene text, which we treat as "pseudo ground truth" (PGT). We apply the method to two weakly-annotated datasets. Training with the extracted PGT consistently improves the accuracy of a state of the art recognition model, by 3.7~\% on average, across different benchmark datasets (image domains) and 24.5~\% on one of the weakly annotated datasets.
Learning Surrogates via Deep Embedding
Jul 17, 2020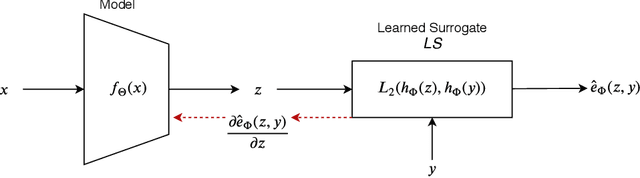
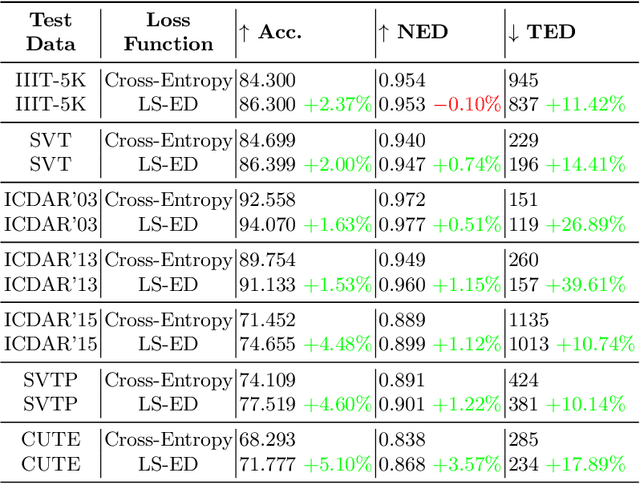
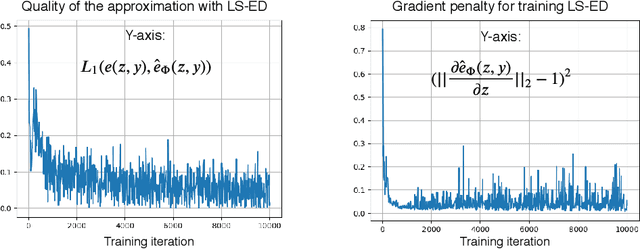
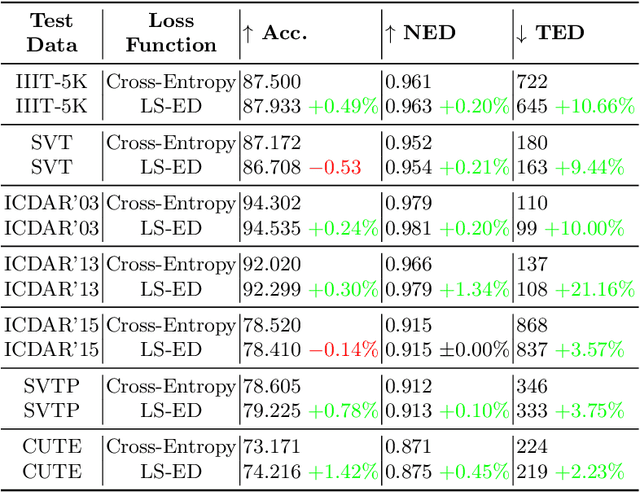
This paper proposes a technique for training a neural network by minimizing a surrogate loss that approximates the target evaluation metric, which may be non-differentiable. The surrogate is learned via a deep embedding where the Euclidean distance between the prediction and the ground truth corresponds to the value of the evaluation metric. The effectiveness of the proposed technique is demonstrated in a post-tuning setup, where a trained model is tuned using the learned surrogate. Without a significant computational overhead and any bells and whistles, improvements are demonstrated on challenging and practical tasks of scene-text recognition and detection. In the recognition task, the model is tuned using a surrogate approximating the edit distance metric and achieves up to $39\%$ relative improvement in the total edit distance. In the detection task, the surrogate approximates the intersection over union metric for rotated bounding boxes and yields up to $4.25\%$ relative improvement in the $F_{1}$ score.