 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Color Constancy
Nov 22, 2021
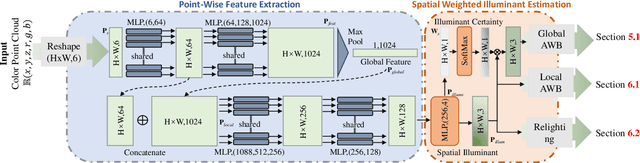
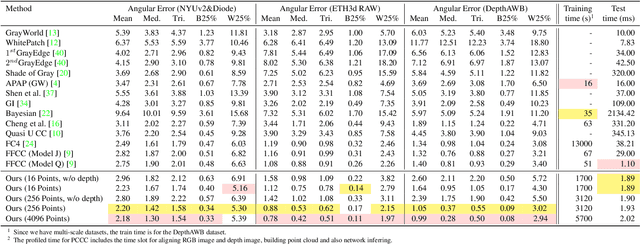
In this paper, we present Point Cloud Color Constancy, in short PCCC, an illumination chromaticity estimation algorithm exploiting a point cloud. We leverage the depth information captured by the time-of-flight (ToF) sensor mounted rigidly with the RGB sensor, and form a 6D cloud where each point contains the coordinates and RGB intensities, noted as (x,y,z,r,g,b). PCCC applies the PointNet architecture to the color constancy problem, deriving the illumination vector point-wise and then making a global decision about the global illumination chromaticity. On two popular RGB-D datasets, which we extend with illumination information, as well as on a novel benchmark, PCCC obtains lower error than the state-of-the-art algorithms. Our method is simple and fast, requiring merely 16*16-size input and reaching speed over 500 fps, including the cost of building the point cloud and net inference.
Binaural SoundNet: Predicting Semantics, Depth and Motion with Binaural Sounds
Sep 06, 2021
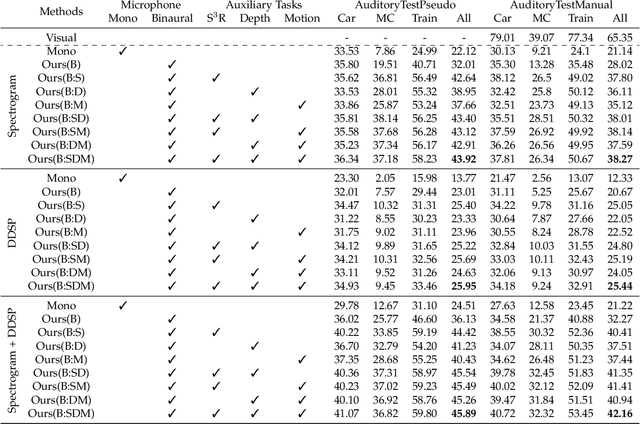
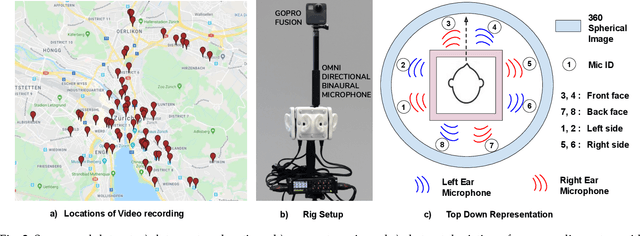
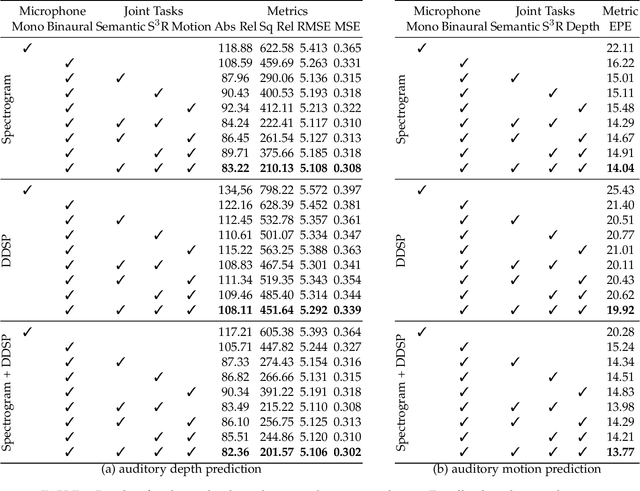
Humans can robustly recognize and localize objects by using visual and/or auditory cues. While machines are able to do the same with visual data already, less work has been done with sounds. This work develops an approach for scene understanding purely based on binaural sounds. The considered tasks include predicting the semantic masks of sound-making objects, the motion of sound-making objects, and the depth map of the scene. To this aim, we propose a novel sensor setup and record a new audio-visual dataset of street scenes with eight professional binaural microphones and a 360-degree camera. The co-existence of visual and audio cues is leveraged for supervision transfer. In particular, we employ a cross-modal distillation framework that consists of multiple vision teacher methods and a sound student method -- the student method is trained to generate the same results as the teacher methods do. This way, the auditory system can be trained without using human annotations. To further boost the performance, we propose another novel auxiliary task, coined Spatial Sound Super-Resolution, to increase the directional resolution of sounds. We then formulate the four tasks into one end-to-end trainable multi-tasking network aiming to boost the overall performance. Experimental results show that 1) our method achieves good results for all four tasks, 2) the four tasks are mutually beneficial -- training them together achieves the best performance, 3) the number and orientation of microphones are both important, and 4) features learned from the standard spectrogram and features obtained by the classic signal processing pipeline are complementary for auditory perception tasks. The data and code are released.
Recall@k Surrogate Loss with Large Batches and Similarity Mixup
Aug 25, 2021
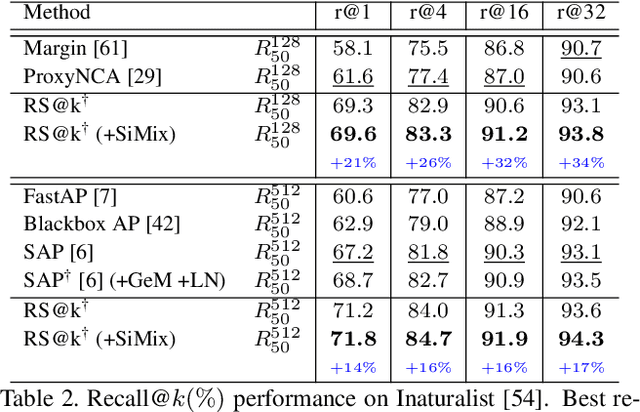
Direct optimization, by gradient descent, of an evaluation metric, is not possible when it is non-differentiable, which is the case for recall in retrieval. In this work, a differentiable surrogate loss for the recall is proposed. Using an implementation that sidesteps the hardware constraints of the GPU memory, the method trains with a very large batch size, which is essential for metrics computed on the entire retrieval database. It is assisted by an efficient mixup approach that operates on pairwise scalar similarities and virtually increases the batch size further. When used for deep metric learning, the proposed method achieves state-of-the-art results in several image retrieval benchmarks. For instance-level recognition, the method outperforms similar approaches that train using an approximation of average precision. The implementation will be made public.
Lightweight Monocular Depth with a Novel Neural Architecture Search Method
Aug 25, 2021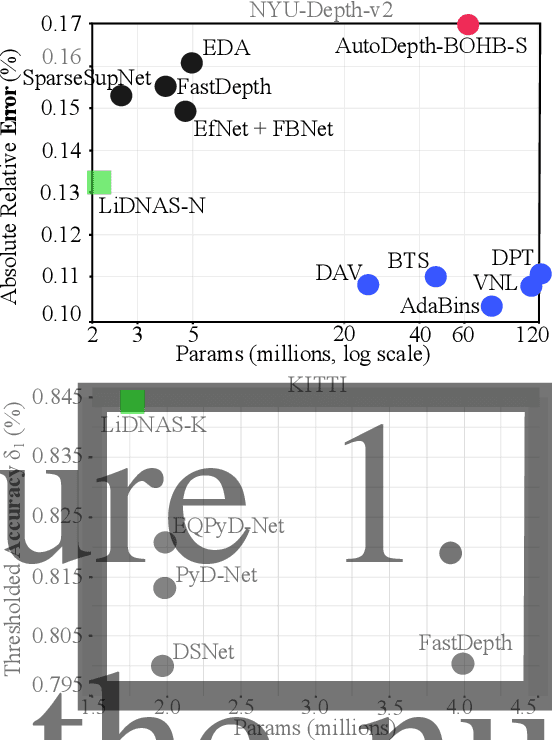

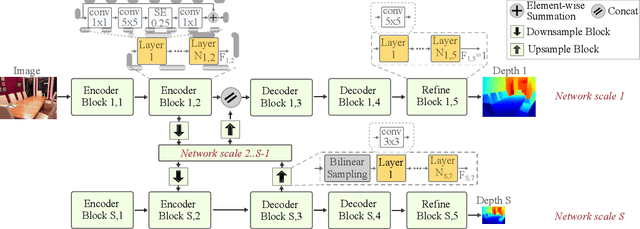
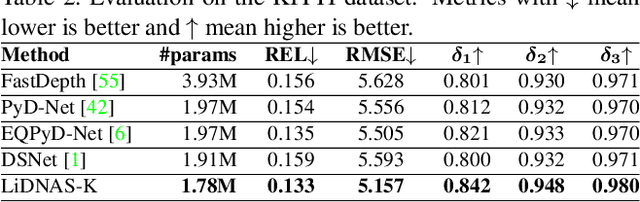
This paper presents a novel neural architecture search method, called LiDNAS, for generating lightweight monocular depth estimation models. Unlike previous neural architecture search (NAS) approaches, where finding optimized networks are computationally highly demanding, the introduced novel Assisted Tabu Search leads to efficient architecture exploration. Moreover, we construct the search space on a pre-defined backbone network to balance layer diversity and search space size. The LiDNAS method outperforms the state-of-the-art NAS approach, proposed for disparity and depth estimation, in terms of search efficiency and output model performance. The LiDNAS optimized models achieve results superior to compact depth estimation state-of-the-art on NYU-Depth-v2, KITTI, and ScanNet, while being 7%-500% more compact in size, i.e the number of model parameters.
Monocular Depth Estimation Primed by Salient Point Detection and Normalized Hessian Loss
Aug 25, 2021
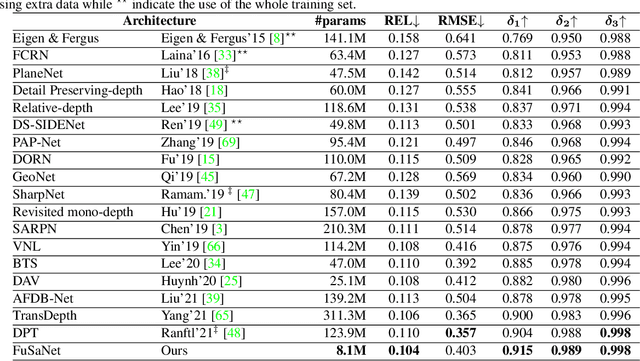
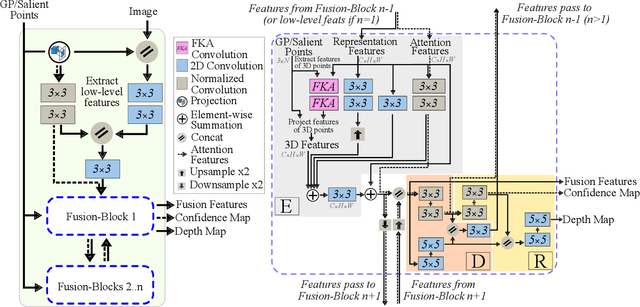
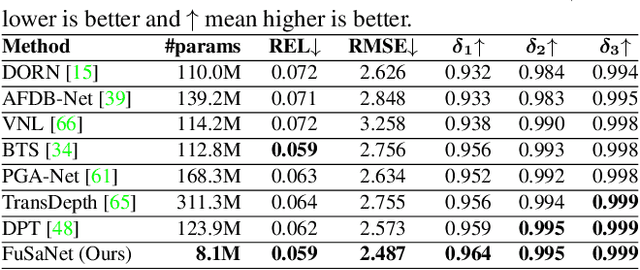
Deep neural networks have recently thrived on single image depth estimation. That being said, current developments on this topic highlight an apparent compromise between accuracy and network size. This work proposes an accurate and lightweight framework for monocular depth estimation based on a self-attention mechanism stemming from salient point detection. Specifically, we utilize a sparse set of keypoints to train a FuSaNet model that consists of two major components: Fusion-Net and Saliency-Net. In addition, we introduce a normalized Hessian loss term invariant to scaling and shear along the depth direction, which is shown to substantially improve the accuracy. The proposed method achieves state-of-the-art results on NYU-Depth-v2 and KITTI while using 3.1-38.4 times smaller model in terms of the number of parameters than baseline approaches. Experiments on the SUN-RGBD further demonstrate the generalizability of the proposed method.
The Hitchhiker's Guide to Prior-Shift Adaptation
Jun 22, 2021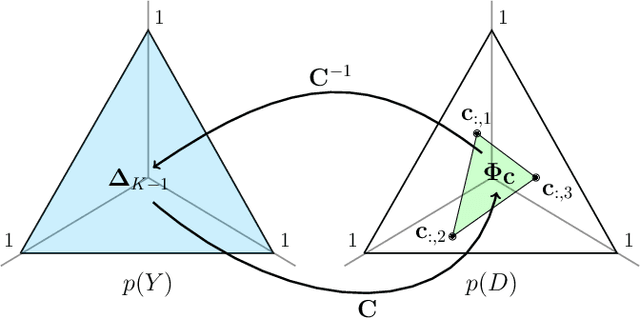
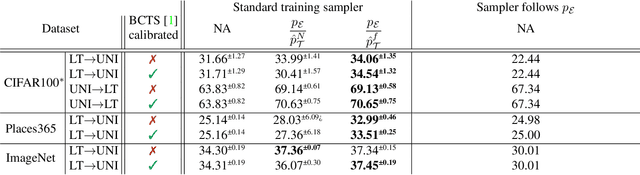
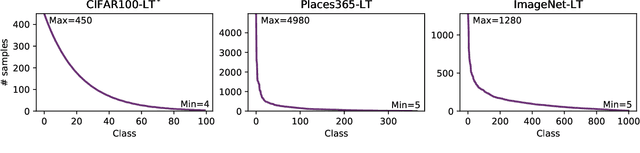
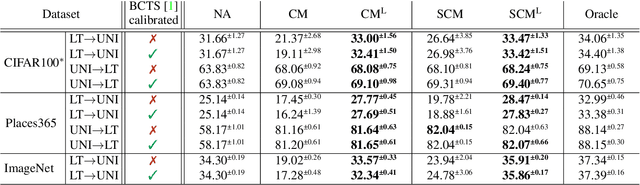
In many computer vision classification tasks, class priors at test time often differ from priors on the training set. In the case of such prior shift, classifiers must be adapted correspondingly to maintain close to optimal performance. This paper analyzes methods for adaptation of probabilistic classifiers to new priors and for estimating new priors on an unlabeled test set. We propose a novel method to address a known issue of prior estimation methods based on confusion matrices, where inconsistent estimates of decision probabilities and confusion matrices lead to negative values in the estimated priors. Experiments on fine-grained image classification datasets provide insight into the best practice of prior shift estimation and classifier adaptation and show that the proposed method achieves state-of-the-art results in prior adaptation. Applying the best practice to two tasks with naturally imbalanced priors, learning from web-crawled images and plant species classification, increased the recognition accuracy by 1.1% and 3.4% respectively.
VSAC: Efficient and Accurate Estimator for H and F
Jun 18, 2021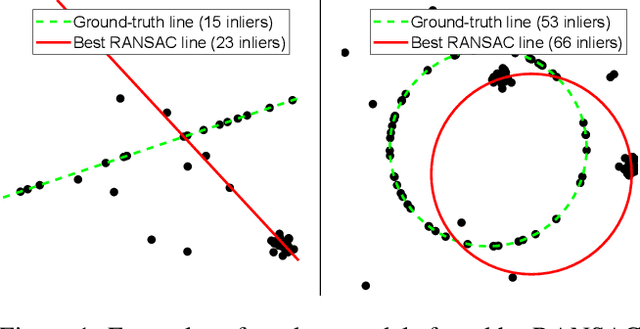
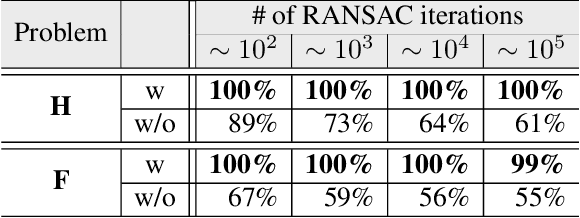
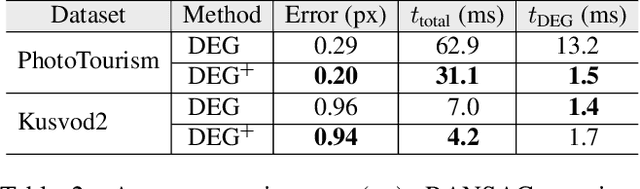
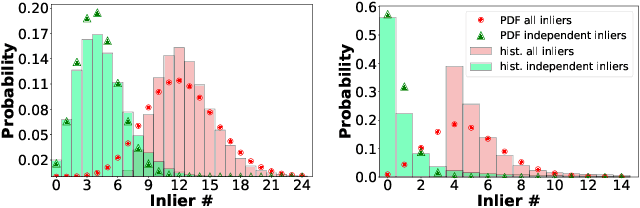
We present VSAC, a RANSAC-type robust estimator with a number of novelties. It benefits from the introduction of the concept of independent inliers that improves significantly the efficacy of the dominant plane handling and, also, allows near error-free rejection of incorrect models, without false positives. The local optimization process and its application is improved so that it is run on average only once. Further technical improvements include adaptive sequential hypothesis verification and efficient model estimation via Gaussian elimination. Experiments on four standard datasets show that VSAC is significantly faster than all its predecessors and runs on average in 1-2 ms, on a CPU. It is two orders of magnitude faster and yet as precise as MAGSAC++, the currently most accurate estimator of two-view geometry. In the repeated runs on EVD, HPatches, PhotoTourism, and Kusvod2 datasets, it never failed.
USACv20: robust essential, fundamental and homography matrix estimation
Apr 11, 2021

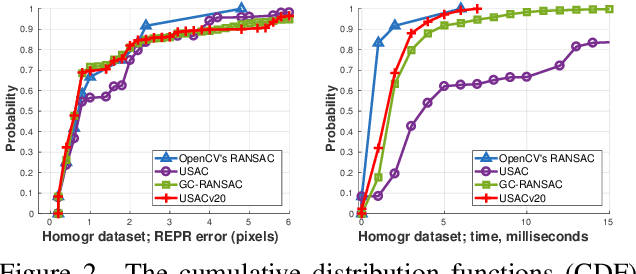

We review the most recent RANSAC-like hypothesize-and-verify robust estimators. The best performing ones are combined to create a state-of-the-art version of the Universal Sample Consensus (USAC) algorithm. A recent objective is to implement a modular and optimized framework, making future RANSAC modules easy to be included. The proposed method, USACv20, is tested on eight publicly available real-world datasets, estimating homographies, fundamental and essential matrices. On average, USACv20 leads to the most geometrically accurate models and it is the fastest in comparison to the state-of-the-art robust estimators. All reported properties improved performance of original USAC algorithm significantly. The pipeline will be made available after publication.
Progressive-X+: Clustering in the Consensus Space
Mar 25, 2021
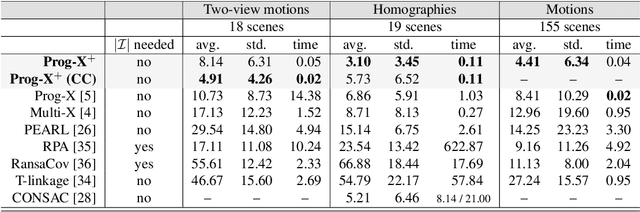

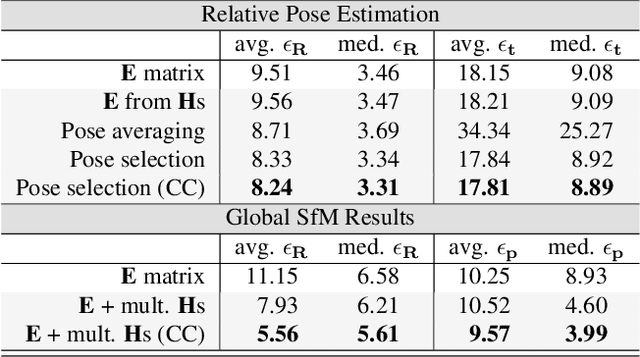
We propose Progressive-X+, a new algorithm for finding an unknown number of geometric models, e.g., homographies. The problem is formalized as finding dominant model instances progressively without forming crisp point-to-model assignments. Dominant instances are found via RANSAC-like sampling and a consolidation process driven by a model quality function considering previously proposed instances. New ones are found by clustering in the consensus space. This new formulation leads to a simple iterative algorithm with state-of-the-art accuracy while running in real-time on a number of vision problems. Also, we propose a sampler reflecting the fact that real-world data tend to form spatially coherent structures. The sampler returns connected components in a progressively growing neighborhood-graph. We present a number of applications where the use of multiple geometric models improves accuracy. These include using multiple homographies to estimate relative poses for global SfM; pose estimation from generalized homographies; and trajectory estimation of fast-moving objects.
FEDS -- Filtered Edit Distance Surrogate
Mar 08, 2021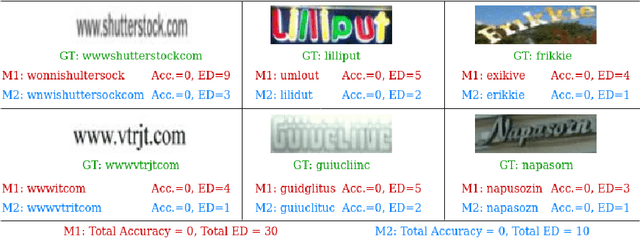
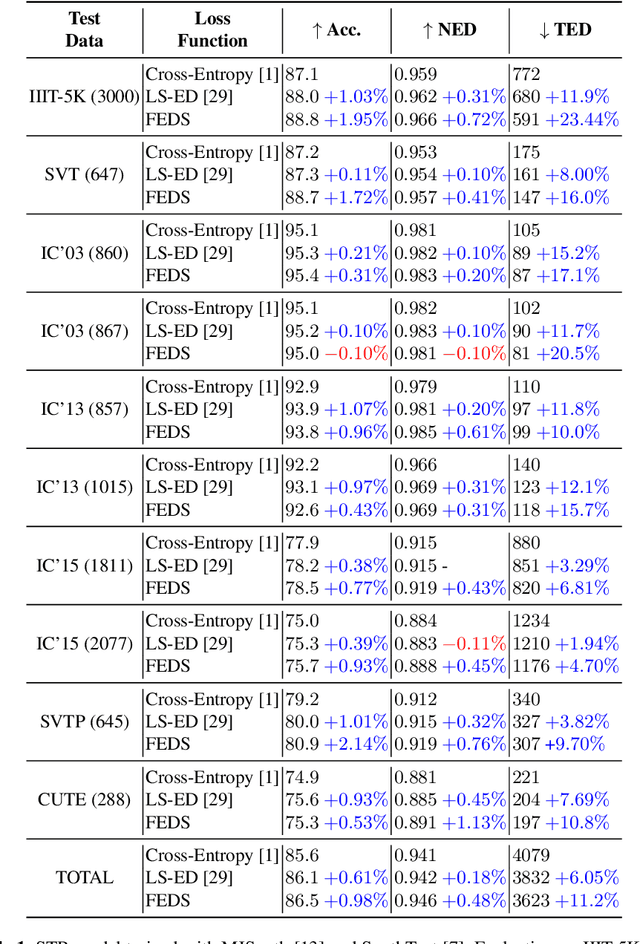
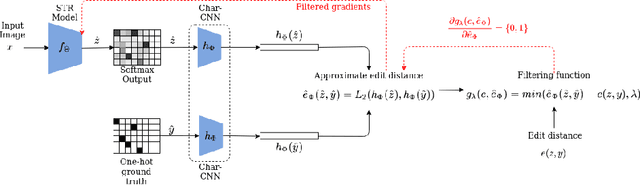
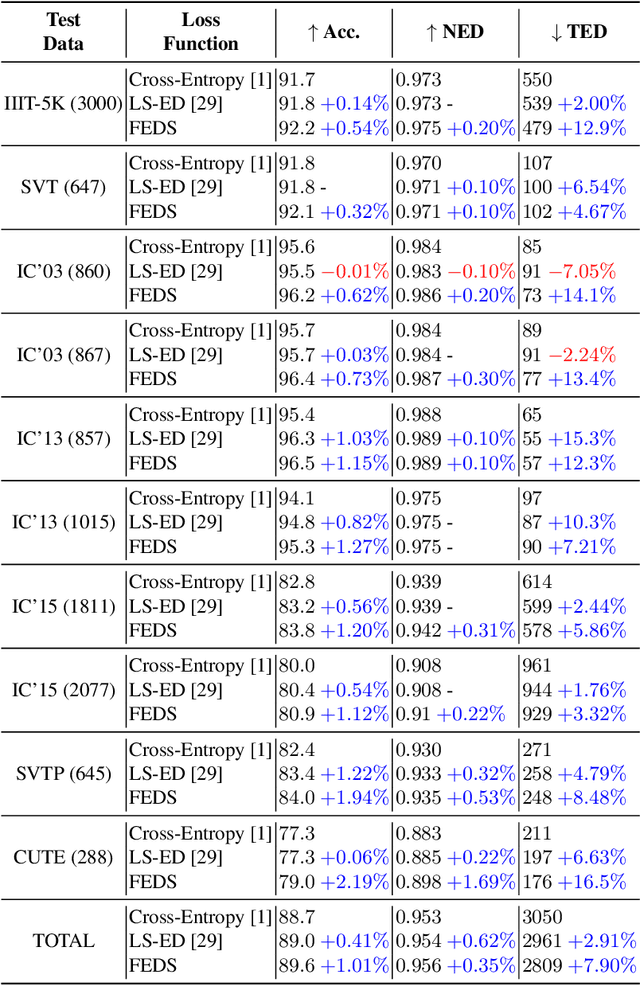
This paper proposes a procedure to robustly train a scene text recognition model using a learned surrogate of edit distance. The proposed method borrows from self-paced learning and filters out the training examples that are hard for the surrogate. The filtering is performed by judging the quality of the approximation, using a ramp function, which is piece-wise differentiable, enabling end-to-end training. Following the literature, the experiments are conducted in a post-tuning setup, where a trained scene text recognition model is tuned using the learned surrogate of edit distance. The efficacy is demonstrated by improvements on various challenging scene text datasets such as IIIT-5K, SVT, ICDAR, SVTP, and CUTE. The proposed method provides an average improvement of $11.2 \%$ on total edit distance and an error reduction of $9.5\%$ on accuracy.