 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D representation in 512-Byte:Variational tokenizer is the key for autoregressive 3D generation
Dec 03, 2024



Autoregressive transformers have revolutionized high-fidelity image generation. One crucial ingredient lies in the tokenizer, which compresses high-resolution image patches into manageable discrete tokens with a scanning or hierarchical order suitable for large language models. Extending these tokenizers to 3D generation, however, presents a significant challenge: unlike image patches that naturally exhibit spatial sequence and multi-scale relationships, 3D data lacks an inherent order, making it difficult to compress into fewer tokens while preserving structural details. To address this, we introduce the Variational Tokenizer (VAT), which transforms unordered 3D data into compact latent tokens with an implicit hierarchy, suited for efficient and high-fidelity coarse-to-fine autoregressive modeling. VAT begins with an in-context transformer, which compress numerous unordered 3D features into a reduced token set with minimal information loss. This latent space is then mapped to a Gaussian distribution for residual quantization, with token counts progressively increasing across scales. In this way, tokens at different scales naturally establish the interconnections by allocating themselves into different subspaces within the same Gaussian distribution, facilitating discrete modeling of token relationships across scales. During the decoding phase, a high-resolution triplane is utilized to convert these compact latent tokens into detailed 3D shapes. Extensive experiments demonstrate that VAT enables scalable and efficient 3D generation, outperforming existing methods in quality, efficiency, and generalization. Remarkably, VAT achieves up to a 250x compression, reducing a 1MB mesh to just 3.9KB with a 96% F-score, and can further compress to 256 int8 tokens, achieving a 2000x reduction while maintaining a 92% F-score.
HumanRig: Learning Automatic Rigging for Humanoid Character in a Large Scale Dataset
Dec 03, 2024



With the rapid evolution of 3D generation algorithms, the cost of producing 3D humanoid character models has plummeted, yet the field is impeded by the lack of a comprehensive dataset for automatic rigging, which is a pivotal step in character animation. Addressing this gap, we present HumanRig, the first large-scale dataset specifically designed for 3D humanoid character rigging, encompassing 11,434 meticulously curated T-posed meshes adhered to a uniform skeleton topology. Capitalizing on this dataset, we introduce an innovative, data-driven automatic rigging framework, which overcomes the limitations of GNN-based methods in handling complex AI-generated meshes. Our approach integrates a Prior-Guided Skeleton Estimator (PGSE) module, which uses 2D skeleton joints to provide a preliminary 3D skeleton, and a Mesh-Skeleton Mutual Attention Network (MSMAN) that fuses skeleton features with 3D mesh features extracted by a U-shaped point transformer. This enables a coarse-to-fine 3D skeleton joint regression and a robust skinning estimation, surpassing previous methods in quality and versatility. This work not only remedies the dataset deficiency in rigging research but also propels the animation industry towards more efficient and automated character rigging pipelines.
G3PT: Unleash the power of Autoregressive Modeling in 3D Generation via Cross-scale Querying Transformer
Sep 10, 2024



Autoregressive transformers have revolutionized generative models in language processing and shown substantial promise in image and video generation. However, these models face significant challenges when extended to 3D generation tasks due to their reliance on next-token prediction to learn token sequences, which is incompatible with the unordered nature of 3D data. Instead of imposing an artificial order on 3D data, in this paper, we introduce G3PT, a scalable coarse-to-fine 3D generative model utilizing a cross-scale querying transformer. The key is to map point-based 3D data into discrete tokens with different levels of detail, naturally establishing a sequential relationship between different levels suitable for autoregressive modeling. Additionally, the cross-scale querying transformer connects tokens globally across different levels of detail without requiring an ordered sequence. Benefiting from this approach, G3PT features a versatile 3D generation pipeline that effortlessly supports diverse conditional structures, enabling the generation of 3D shapes from various types of conditions. Extensive experiments demonstrate that G3PT achieves superior generation quality and generalization ability compared to previous 3D generation methods. Most importantly, for the first time in 3D generation, scaling up G3PT reveals distinct power-law scaling behaviors.
XScale-NVS: Cross-Scale Novel View Synthesis with Hash Featurized Manifold
Mar 28, 2024We propose XScale-NVS for high-fidelity cross-scale novel view synthesis of real-world large-scale scenes. Existing representations based on explicit surface suffer from discretization resolution or UV distortion, while implicit volumetric representations lack scalability for large scenes due to the dispersed weight distribution and surface ambiguity. In light of the above challenges, we introduce hash featurized manifold, a novel hash-based featurization coupled with a deferred neural rendering framework. This approach fully unlocks the expressivity of the representation by explicitly concentrating the hash entries on the 2D manifold, thus effectively representing highly detailed contents independent of the discretization resolution. We also introduce a novel dataset, namely GigaNVS, to benchmark cross-scale, high-resolution novel view synthesis of realworld large-scale scenes. Our method significantly outperforms competing baselines on various real-world scenes, yielding an average LPIPS that is 40% lower than prior state-of-the-art on the challenging GigaNVS benchmark. Please see our project page at: xscalenvs.github.io.
OmniSeg3D: Omniversal 3D Segmentation via Hierarchical Contrastive Learning
Nov 20, 2023



Towards holistic understanding of 3D scenes, a general 3D segmentation method is needed that can segment diverse objects without restrictions on object quantity or categories, while also reflecting the inherent hierarchical structure. To achieve this, we propose OmniSeg3D, an omniversal segmentation method aims for segmenting anything in 3D all at once. The key insight is to lift multi-view inconsistent 2D segmentations into a consistent 3D feature field through a hierarchical contrastive learning framework, which is accomplished by two steps. Firstly, we design a novel hierarchical representation based on category-agnostic 2D segmentations to model the multi-level relationship among pixels. Secondly, image features rendered from the 3D feature field are clustered at different levels, which can be further drawn closer or pushed apart according to the hierarchical relationship between different levels. In tackling the challenges posed by inconsistent 2D segmentations, this framework yields a global consistent 3D feature field, which further enables hierarchical segmentation, multi-object selection, and global discretization. Extensive experiments demonstrate the effectiveness of our method on high-quality 3D segmentation and accurate hierarchical structure understanding. A graphical user interface further facilitates flexible interaction for omniversal 3D segmentation.
PARF: Primitive-Aware Radiance Fusion for Indoor Scene Novel View Synthesis
Sep 29, 2023This paper proposes a method for fast scene radiance field reconstruction with strong novel view synthesis performance and convenient scene editing functionality. The key idea is to fully utilize semantic parsing and primitive extraction for constraining and accelerating the radiance field reconstruction process. To fulfill this goal, a primitive-aware hybrid rendering strategy was proposed to enjoy the best of both volumetric and primitive rendering. We further contribute a reconstruction pipeline conducts primitive parsing and radiance field learning iteratively for each input frame which successfully fuses semantic, primitive, and radiance information into a single framework. Extensive evaluations demonstrate the fast reconstruction ability, high rendering quality, and convenient editing functionality of our method.
EffLiFe: Efficient Light Field Generation via Hierarchical Sparse Gradient Descent
Jul 10, 2023



With the rise of Extended Reality (XR) technology, there is a growing need for real-time light field generation from sparse view inputs. Existing methods can be classified into offline techniques, which can generate high-quality novel views but at the cost of long inference/training time, and online methods, which either lack generalizability or produce unsatisfactory results. However, we have observed that the intrinsic sparse manifold of Multi-plane Images (MPI) enables a significant acceleration of light field generation while maintaining rendering quality. Based on this insight, we introduce EffLiFe, a novel light field optimization method, which leverages the proposed Hierarchical Sparse Gradient Descent (HSGD) to produce high-quality light fields from sparse view images in real time. Technically, the coarse MPI of a scene is first generated using a 3D CNN, and it is further sparsely optimized by focusing only on important MPI gradients in a few iterations. Nevertheless, relying solely on optimization can lead to artifacts at occlusion boundaries. Therefore, we propose an occlusion-aware iterative refinement module that removes visual artifacts in occluded regions by iteratively filtering the input. Extensive experiments demonstrate that our method achieves comparable visual quality while being 100x faster on average than state-of-the-art offline methods and delivering better performance (about 2 dB higher in PSNR) compared to other online approaches.
SurfaceNet+: An End-to-end 3D Neural Network for Very Sparse Multi-view Stereopsis
May 26, 2020
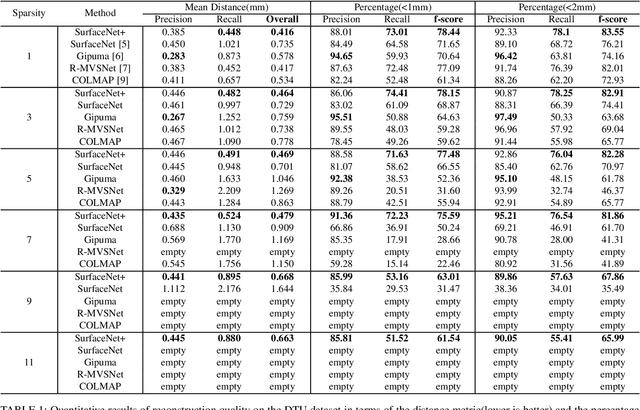
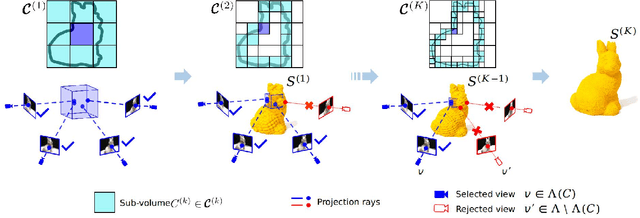
Multi-view stereopsis (MVS) tries to recover the 3D model from 2D images. As the observations become sparser, the significant 3D information loss makes the MVS problem more challenging. Instead of only focusing on densely sampled conditions, we investigate sparse-MVS with large baseline angles since the sparser sensation is more practical and more cost-efficient. By investigating various observation sparsities, we show that the classical depth-fusion pipeline becomes powerless for the case with a larger baseline angle that worsens the photo-consistency check. As another line of the solution, we present SurfaceNet+, a volumetric method to handle the 'incompleteness' and the 'inaccuracy' problems induced by a very sparse MVS setup. Specifically, the former problem is handled by a novel volume-wise view selection approach. It owns superiority in selecting valid views while discarding invalid occluded views by considering the geometric prior. Furthermore, the latter problem is handled via a multi-scale strategy that consequently refines the recovered geometry around the region with the repeating pattern. The experiments demonstrate the tremendous performance gap between SurfaceNet+ and state-of-the-art methods in terms of precision and recall. Under the extreme sparse-MVS settings in two datasets, where existing methods can only return very few points, SurfaceNet+ still works as well as in the dense MVS setting. The benchmark and the implementation are publicly available at https://github.com/mjiUST/SurfaceNet-plus.
* Accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), May 2020
Proximal Policy Optimization and its Dynamic Version for Sequence Generation
Aug 24, 2018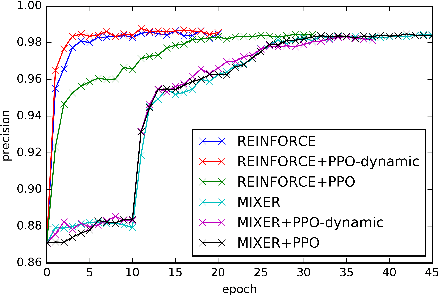
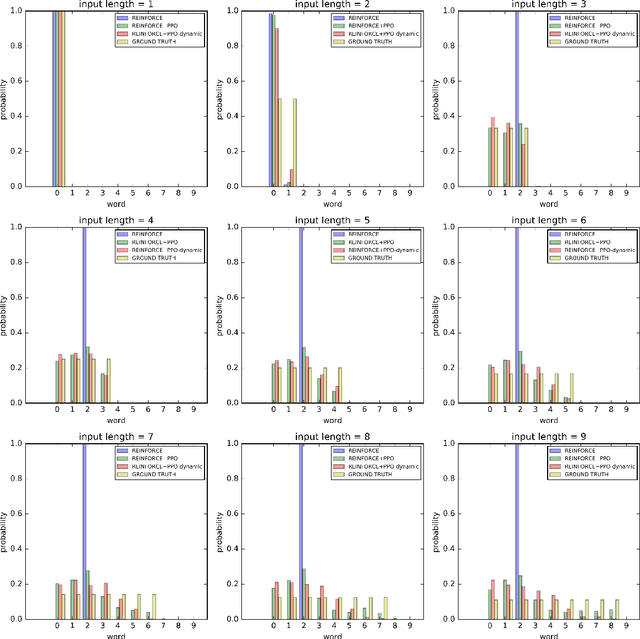
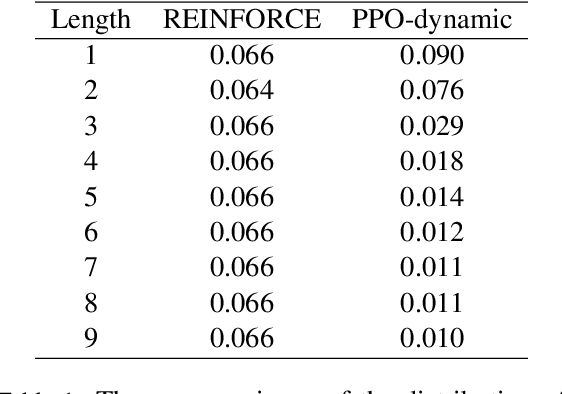
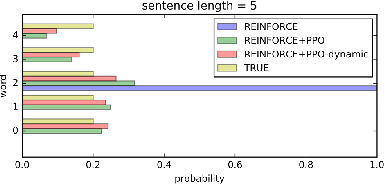
In sequence generation task, many works use policy gradient for model optimization to tackle the intractable backpropagation issue when maximizing the non-differentiable evaluation metrics or fooling the discriminator in adversarial learning. In this paper, we replace policy gradient with proximal policy optimization (PPO), which is a proved more efficient reinforcement learning algorithm, and propose a dynamic approach for PPO (PPO-dynamic). We demonstrate the efficacy of PPO and PPO-dynamic on conditional sequence generation tasks including synthetic experiment and chit-chat chatbot. The results show that PPO and PPO-dynamic can beat policy gradient by stability and performance.