 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interpretable Controllability in Object-Centric Learning
Oct 16, 2023The binding problem in artificial neural networks is actively explored with the goal of achieving human-level recognition skills through the comprehension of the world in terms of symbol-like entities. Especially in the field of computer vision, object-centric learning (OCL) is extensively researched to better understand complex scenes by acquiring object representations or slots. While recent studies in OCL have made strides with complex images or videos, the interpretability and interactivity over object representation remain largely uncharted, still holding promise in the field of OCL. In this paper, we introduce a novel method, Slot Attention with Image Augmentation (SlotAug), to explore the possibility of learning interpretable controllability over slots in a self-supervised manner by utilizing an image augmentation strategy. We also devise the concept of sustainability in controllable slots by introducing iterative and reversible controls over slots with two proposed submethods: Auxiliary Identity Manipulation and Slot Consistency Loss. Extensive empirical studies and theoretical validation confirm the effectiveness of our approach, offering a novel capability for interpretable and sustainable control of object representations. Code will be available soon.
3D Denoisers are Good 2D Teachers: Molecular Pretraining via Denoising and Cross-Modal Distillation
Sep 08, 2023Pretraining molecular representations from large unlabeled data is essential for molecular property prediction due to the high cost of obtaining ground-truth labels. While there exist various 2D graph-based molecular pretraining approaches, these methods struggle to show statistically significant gains in predictive performance. Recent work have thus instead proposed 3D conformer-based pretraining under the task of denoising, which led to promising results. During downstream finetuning, however, models trained with 3D conformers require accurate atom-coordinates of previously unseen molecules, which are computationally expensive to acquire at scale. In light of this limitation, we propose D&D, a self-supervised molecular representation learning framework that pretrains a 2D graph encoder by distilling representations from a 3D denoiser. With denoising followed by cross-modal knowledge distillation, our approach enjoys use of knowledge obtained from denoising as well as painless application to downstream tasks with no access to accurate conformers. Experiments on real-world molecular property prediction datasets show that the graph encoder trained via D&D can infer 3D information based on the 2D graph and shows superior performance and label-efficiency against other baselines.
Learning Probabilistic Symmetrization for Architecture Agnostic Equivariance
Jun 05, 2023



We present a novel framework to overcome the limitations of equivariant architectures in learning functions with group symmetries. In contrary to equivariant architectures, we use an arbitrary base model (such as an MLP or a transformer) and symmetrize it to be equivariant to the given group by employing a small equivariant network that parameterizes the probabilistic distribution underlying the symmetrization. The distribution is end-to-end trained with the base model which can maximize performance while reducing sample complexity of symmetrization. We show that this approach ensures not only equivariance to given group but also universal approximation capability in expectation. We implement our method on a simple patch-based transformer that can be initialized from pretrained vision transformers, and test it for a wide range of symmetry groups including permutation and Euclidean groups and their combinations. Empirical tests show competitive results against tailored equivariant architectures, suggesting the potential for learning equivariant functions for diverse groups using a non-equivariant universal base architecture. We further show evidence of enhanced learning in symmetric modalities, like graphs, when pretrained from non-symmetric modalities, like vision. Our implementation will be open-sourced at https://github.com/jw9730/lps.
Train a Real-world Local Path Planner in One Hour via Partially Decoupled Reinforcement Learning and Vectorized Diversity
May 07, 2023Deep Reinforcement Learning (DRL) has exhibited efficacy in resolving the Local Path Planning (LPP) problem. However, such application in the real world is immensely limited due to the deficient efficiency and generalization capability of DRL. To alleviate these two issues, a solution named Color is proposed, which consists of an Actor-Sharer-Learner (ASL) training framework and a mobile robot-oriented simulator Sparrow. Specifically, the ASL framework, intending to improve the efficiency of the DRL algorithm, employs a Vectorized Data Collection (VDC) mode to expedite data acquisition, decouples the data collection from model optimization by multithreading, and partially connects the two procedures by harnessing a Time Feedback Mechanism (TFM) to evade data underuse or overuse. Meanwhile, the Sparrow simulator utilizes a 2D grid-based world, simplified kinematics, and conversion-free data flow to achieve a lightweight design. The lightness facilitates vectorized diversity, allowing diversified simulation setups across extensive copies of the vectorized environments, resulting in a notable enhancement in the generalization capability of the DRL algorithm being trained. Comprehensive experiments, comprising 57 benchmark video games, 32 simulated and 36 real-world LPP scenarios, have been conducted to corroborate the superiority of our method in terms of efficiency and generalization. The code and the video of the experiments can be accessed on our website.
Shepherding Slots to Objects: Towards Stable and Robust Object-Centric Learning
Mar 31, 2023



Object-centric learning (OCL) aspires general and compositional understanding of scenes by representing a scene as a collection of object-centric representations. OCL has also been extended to multi-view image and video datasets to apply various data-driven inductive biases by utilizing geometric or temporal information in the multi-image data. Single-view images carry less information about how to disentangle a given scene than videos or multi-view images do. Hence, owing to the difficulty of applying inductive biases, OCL for single-view images remains challenging, resulting in inconsistent learning of object-centric representation. To this end, we introduce a novel OCL framework for single-view images, SLot Attention via SHepherding (SLASH), which consists of two simple-yet-effective modules on top of Slot Attention. The new modules, Attention Refining Kernel (ARK) and Intermediate Point Predictor and Encoder (IPPE), respectively, prevent slots from being distracted by the background noise and indicate locations for slots to focus on to facilitate learning of object-centric representation. We also propose a weak semi-supervision approach for OCL, whilst our proposed framework can be used without any assistant annotation during the inference. Experiments show that our proposed method enables consistent learning of object-centric representation and achieves strong performance across four datasets. Code is available at \url{https://github.com/object-understanding/SLASH}.
Universal Few-shot Learning of Dense Prediction Tasks with Visual Token Matching
Mar 27, 2023Dense prediction tasks are a fundamental class of problems in computer vision. As supervised methods suffer from high pixel-wise labeling cost, a few-shot learning solution that can learn any dense task from a few labeled images is desired. Yet, current few-shot learning methods target a restricted set of tasks such as semantic segmentation, presumably due to challenges in designing a general and unified model that is able to flexibly and efficiently adapt to arbitrary tasks of unseen semantics. We propose Visual Token Matching (VTM), a universal few-shot learner for arbitrary dense prediction tasks. It employs non-parametric matching on patch-level embedded tokens of images and labels that encapsulates all tasks. Also, VTM flexibly adapts to any task with a tiny amount of task-specific parameters that modulate the matching algorithm. We implement VTM as a powerful hierarchical encoder-decoder architecture involving ViT backbones where token matching is performed at multiple feature hierarchies. We experiment VTM on a challenging variant of Taskonomy dataset and observe that it robustly few-shot learns various unseen dense prediction tasks. Surprisingly, it is competitive with fully supervised baselines using only 10 labeled examples of novel tasks (0.004% of full supervision) and sometimes outperforms using 0.1% of full supervision. Codes are available at https://github.com/GitGyun/visual_token_matching.
Transformers meet Stochastic Block Models: Attention with Data-Adaptive Sparsity and Cost
Oct 27, 2022



To overcome the quadratic cost of self-attention, recent works have proposed various sparse attention modules, most of which fall under one of two groups: 1) sparse attention under a hand-crafted patterns and 2) full attention followed by a sparse variant of softmax such as $\alpha$-entmax. Unfortunately, the first group lacks adaptability to data while the second still requires quadratic cost in training. In this work, we propose SBM-Transformer, a model that resolves both problems by endowing each attention head with a mixed-membership Stochastic Block Model (SBM). Then, each attention head data-adaptively samples a bipartite graph, the adjacency of which is used as an attention mask for each input. During backpropagation, a straight-through estimator is used to flow gradients beyond the discrete sampling step and adjust the probabilities of sampled edges based on the predictive loss. The forward and backward cost are thus linear to the number of edges, which each attention head can also choose flexibly based on the input. By assessing the distribution of graphs, we theoretically show that SBM-Transformer is a universal approximator for arbitrary sequence-to-sequence functions in expectation. Empirical evaluations under the LRA and GLUE benchmarks demonstrate that our model outperforms previous efficient variants as well as the original Transformer with full attention. Our implementation can be found in https://github.com/sc782/SBM-Transformer .
Equivariant Hypergraph Neural Networks
Aug 22, 2022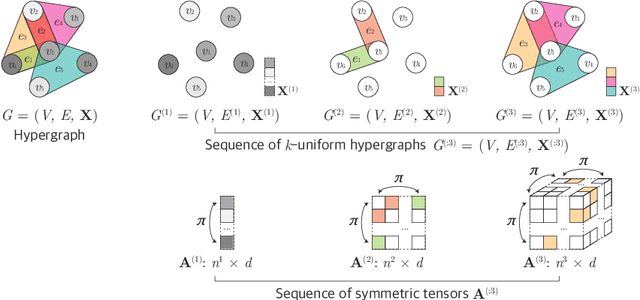

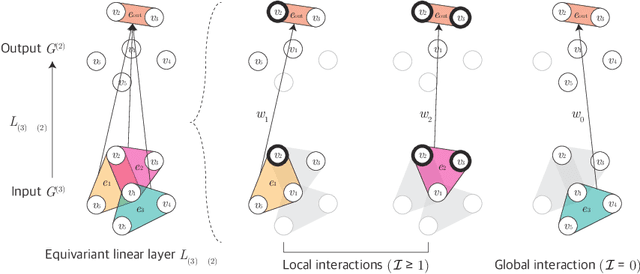
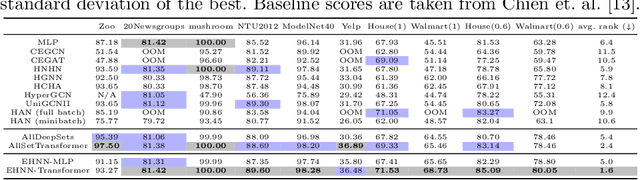
Many problems in computer vision and machine learning can be cast as learning on hypergraphs that represent higher-order relations. Recent approaches for hypergraph learning extend graph neural networks based on message passing, which is simple yet fundamentally limited in modeling long-range dependencies and expressive power. On the other hand, tensor-based equivariant neural networks enjoy maximal expressiveness, but their application has been limited in hypergraphs due to heavy computation and strict assumptions on fixed-order hyperedges. We resolve these problems and present Equivariant Hypergraph Neural Network (EHNN), the first attempt to realize maximally expressive equivariant layers for general hypergraph learning. We also present two practical realizations of our framework based on hypernetworks (EHNN-MLP) and self-attention (EHNN-Transformer), which are easy to implement and theoretically more expressive than most message passing approaches. We demonstrate their capability in a range of hypergraph learning problems, including synthetic k-edge identification, semi-supervised classification, and visual keypoint matching, and report improved performances over strong message passing baselines. Our implementation is available at https://github.com/jw9730/ehnn.
Pure Transformers are Powerful Graph Learners
Jul 06, 2022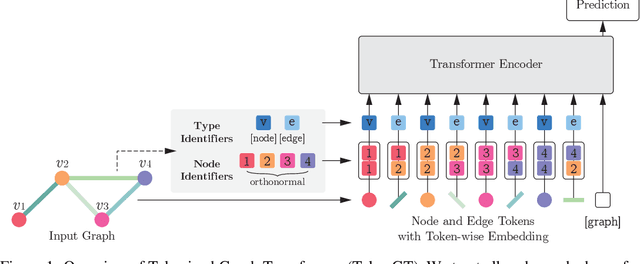
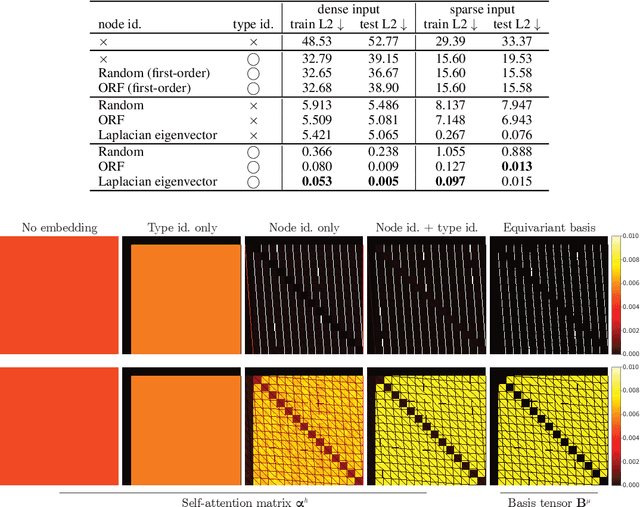
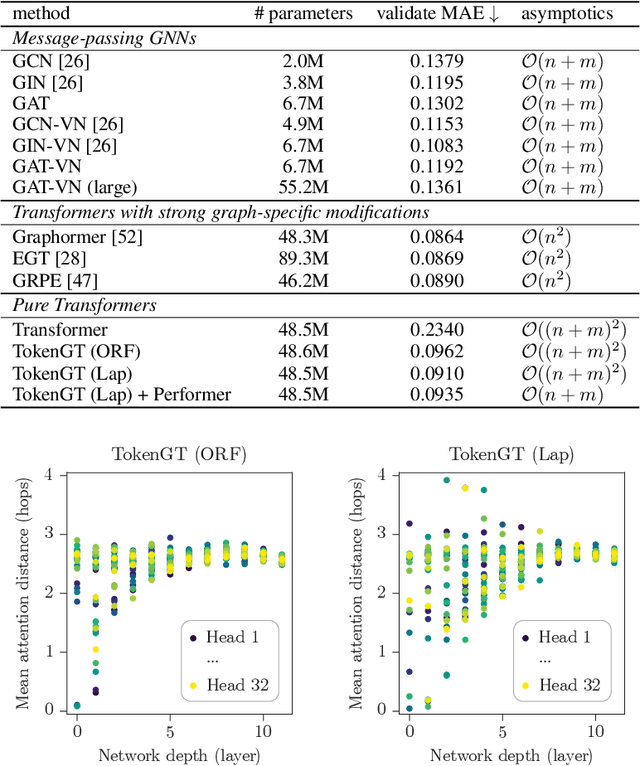

We show that standard Transformers without graph-specific modifications can lead to promising results in graph learning both in theory and practice. Given a graph, we simply treat all nodes and edges as independent tokens, augment them with token embeddings, and feed them to a Transformer. With an appropriate choice of token embeddings, we prove that this approach is theoretically at least as expressive as an invariant graph network (2-IGN) composed of equivariant linear layers, which is already more expressive than all message-passing Graph Neural Networks (GNN). When trained on a large-scale graph dataset (PCQM4Mv2), our method coined Tokenized Graph Transformer (TokenGT) achieves significantly better results compared to GNN baselines and competitive results compared to Transformer variants with sophisticated graph-specific inductive bias. Our implementation is available at https://github.com/jw9730/tokengt.
GraphDistNet: A Graph-based Collision-distance Estimator for Gradient-based Trajectory
Jun 03, 2022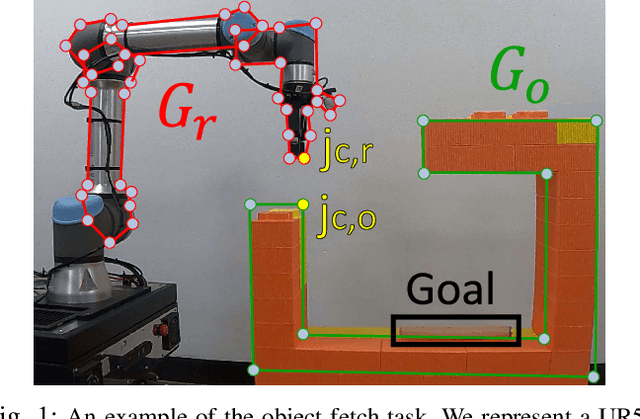
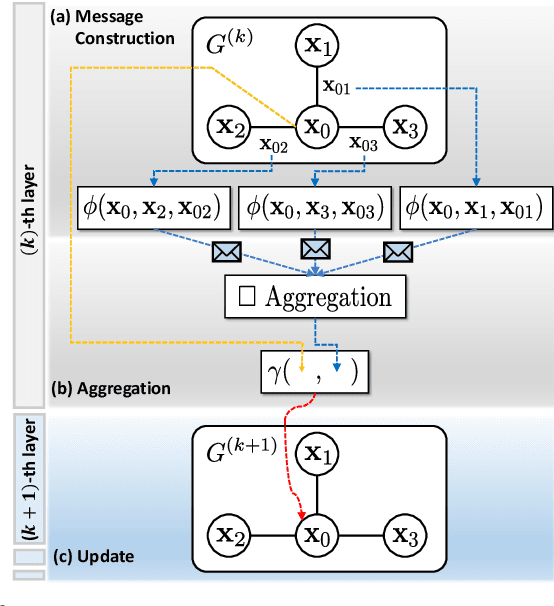
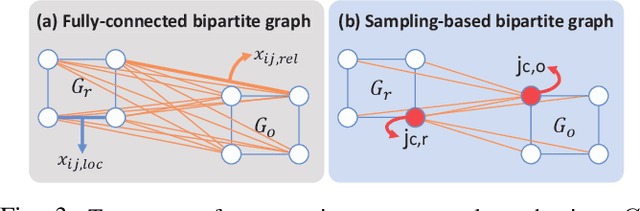
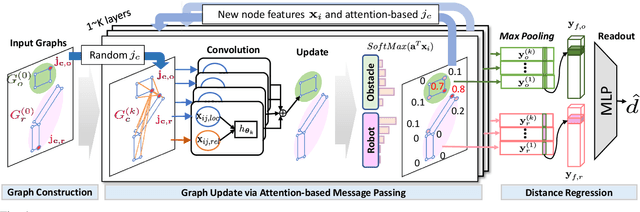
Trajectory optimization (TO) aims to find a sequence of valid states while minimizing costs. However, its fine validation process is often costly due to computationally expensive collision searches, otherwise coarse searches lower the safety of the system losing a precise solution. To resolve the issues, we introduce a new collision-distance estimator, GraphDistNet, that can precisely encode the structural information between two geometries by leveraging edge feature-based convolutional operations, and also efficiently predict a batch of collision distances and gradients through 25,000 random environments with a maximum of 20 unforeseen objects. Further, we show the adoption of attention mechanism enables our method to be easily generalized in unforeseen complex geometries toward TO. Our evaluation show GraphDistNet outperforms state-of-the-art baseline methods in both simulated and real world tasks.