 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvoSense: Overcoming Monotonous Commonsense Inferences for Conversational AI
Jan 27, 2024Mastering commonsense understanding and reasoning is a pivotal skill essential for conducting engaging conversations. While there have been several attempts to create datasets that facilitate commonsense inferences in dialogue contexts, existing datasets tend to lack in-depth details, restate information already present in the conversation, and often fail to capture the multifaceted nature of commonsense reasoning. In response to these limitations, we compile a new synthetic dataset for commonsense reasoning in dialogue contexts using GPT, ConvoSense, that boasts greater contextual novelty, offers a higher volume of inferences per example, and substantially enriches the detail conveyed by the inferences. Our dataset contains over 500,000 inferences across 12,000 dialogues with 10 popular inference types, which empowers the training of generative commonsense models for dialogue that are superior in producing plausible inferences with high novelty when compared to models trained on the previous datasets. To the best of our knowledge, ConvoSense is the first of its kind to provide such a multitude of novel inferences at such a large scale.
FedTherapist: Mental Health Monitoring with User-Generated Linguistic Expressions on Smartphones via Federated Learning
Oct 25, 2023



Psychiatrists diagnose mental disorders via the linguistic use of patients. Still, due to data privacy, existing passive mental health monitoring systems use alternative features such as activity, app usage, and location via mobile devices. We propose FedTherapist, a mobile mental health monitoring system that utilizes continuous speech and keyboard input in a privacy-preserving way via federated learning. We explore multiple model designs by comparing their performance and overhead for FedTherapist to overcome the complex nature of on-device language model training on smartphones. We further propose a Context-Aware Language Learning (CALL) methodology to effectively utilize smartphones' large and noisy text for mental health signal sensing. Our IRB-approved evaluation of the prediction of self-reported depression, stress, anxiety, and mood from 46 participants shows higher accuracy of FedTherapist compared with the performance with non-language features, achieving 0.15 AUROC improvement and 8.21% MAE reduction.
Aligning Speakers: Evaluating and Visualizing Text-based Diarization Using Efficient Multiple Sequence Alignment (Extended Version)
Sep 14, 2023



This paper presents a novel evaluation approach to text-based speaker diarization (SD), tackling the limitations of traditional metrics that do not account for any contextual information in text. Two new metrics are proposed, Text-based Diarization Error Rate and Diarization F1, which perform utterance- and word-level evaluations by aligning tokens in reference and hypothesis transcripts. Our metrics encompass more types of errors compared to existing ones, allowing us to make a more comprehensive analysis in SD. To align tokens, a multiple sequence alignment algorithm is introduced that supports multiple sequences in the reference while handling high-dimensional alignment to the hypothesis using dynamic programming. Our work is packaged into two tools, align4d providing an API for our alignment algorithm and TranscribeView for visualizing and evaluating SD errors, which can greatly aid in the creation of high-quality data, fostering the advancement of dialogue systems.
Exploring the Impact of Human Evaluator Group on Chat-Oriented Dialogue Evaluation
Sep 14, 2023



Human evaluation has been widely accepted as the standard for evaluating chat-oriented dialogue systems. However, there is a significant variation in previous work regarding who gets recruited as evaluators. Evaluator groups such as domain experts, university students, and professional annotators have been used to assess and compare dialogue systems, although it is unclear to what extent the choice of an evaluator group can affect results. This paper analyzes the evaluator group impact on dialogue system evaluation by testing 4 state-of-the-art dialogue systems using 4 distinct evaluator groups. Our analysis reveals a robustness towards evaluator groups for Likert evaluations that is not seen for Pairwise, with only minor differences observed when changing evaluator groups. Furthermore, two notable limitations to this robustness are observed, which reveal discrepancies between evaluators with different levels of chatbot expertise and indicate that evaluator objectivity is beneficial for certain dialogue metrics.
Widely Interpretable Semantic Representation: Frameless Meaning Representation for Broader Applicability
Sep 12, 2023



This paper presents a novel semantic representation, WISeR, that overcomes challenges for Abstract Meaning Representation (AMR). Despite its strengths, AMR is not easily applied to languages or domains without predefined semantic frames, and its use of numbered arguments results in semantic role labels, which are not directly interpretable and are semantically overloaded for parsers. We examine the numbered arguments of predicates in AMR and convert them to thematic roles that do not require reference to semantic frames. We create a new corpus of 1K English dialogue sentences annotated in both WISeR and AMR. WISeR shows stronger inter-annotator agreement for beginner and experienced annotators, with beginners becoming proficient in WISeR annotation more quickly. Finally, we train a state-of-the-art parser on the AMR 3.0 corpus and a WISeR corpus converted from AMR 3.0. The parser is evaluated on these corpora and our dialogue corpus. The WISeR model exhibits higher accuracy than its AMR counterpart across the board, demonstrating that WISeR is easier for parsers to learn.
Leveraging Large Language Models for Automated Dialogue Analysis
Sep 12, 2023Developing high-performing dialogue systems benefits from the automatic identification of undesirable behaviors in system responses. However, detecting such behaviors remains challenging, as it draws on a breadth of general knowledge and understanding of conversational practices. Although recent research has focused on building specialized classifiers for detecting specific dialogue behaviors, the behavior coverage is still incomplete and there is a lack of testing on real-world human-bot interactions. This paper investigates the ability of a state-of-the-art large language model (LLM), ChatGPT-3.5, to perform dialogue behavior detection for nine categories in real human-bot dialogues. We aim to assess whether ChatGPT can match specialized models and approximate human performance, thereby reducing the cost of behavior detection tasks. Our findings reveal that neither specialized models nor ChatGPT have yet achieved satisfactory results for this task, falling short of human performance. Nevertheless, ChatGPT shows promising potential and often outperforms specialized detection models. We conclude with an in-depth examination of the prevalent shortcomings of ChatGPT, offering guidance for future research to enhance LLM capabilities.
Towards Open-World Product Attribute Mining: A Lightly-Supervised Approach
May 26, 2023We present a new task setting for attribute mining on e-commerce products, serving as a practical solution to extract open-world attributes without extensive human intervention. Our supervision comes from a high-quality seed attribute set bootstrapped from existing resources, and we aim to expand the attribute vocabulary of existing seed types, and also to discover any new attribute types automatically. A new dataset is created to support our setting, and our approach Amacer is proposed specifically to tackle the limited supervision. Especially, given that no direct supervision is available for those unseen new attributes, our novel formulation exploits self-supervised heuristic and unsupervised latent attributes, which attains implicit semantic signals as additional supervision by leveraging product context. Experiments suggest that our approach surpasses various baselines by 12 F1, expanding attributes of existing types significantly by up to 12 times, and discovering values from 39% new types.
Unleashing the True Potential of Sequence-to-Sequence Models for Sequence Tagging and Structure Parsing
Feb 05, 2023Sequence-to-Sequence (S2S) models have achieved remarkable success on various text generation tasks. However, learning complex structures with S2S models remains challenging as external neural modules and additional lexicons are often supplemented to predict non-textual outputs. We present a systematic study of S2S modeling using contained decoding on four core tasks: part-of-speech tagging, named entity recognition, constituency and dependency parsing, to develop efficient exploitation methods costing zero extra parameters. In particular, 3 lexically diverse linearization schemas and corresponding constrained decoding methods are designed and evaluated. Experiments show that although more lexicalized schemas yield longer output sequences that require heavier training, their sequences being closer to natural language makes them easier to learn. Moreover, S2S models using our constrained decoding outperform other S2S approaches using external resources. Our best models perform better than or comparably to the state-of-the-art for all 4 tasks, lighting a promise for S2S models to generate non-sequential structures.
Don't Forget Your ABC's: Evaluating the State-of-the-Art in Chat-Oriented Dialogue Systems
Dec 18, 2022



There has been great recent advancement in human-computer chat. However, proper evaluation currently requires human judgements that produce notoriously high-variance metrics due to their inherent subjectivity. Furthermore, there is little standardization in the methods and labels used for evaluation, with an overall lack of work to compare and assess the validity of various evaluation approaches. As a consequence, existing evaluation results likely leave an incomplete picture of the strengths and weaknesses of open-domain chatbots. We aim towards a dimensional evaluation of human-computer chat that can reliably measure several distinct aspects of chat quality. To this end, we present our novel human evaluation method that quantifies the rate of several quality-related chatbot behaviors. Our results demonstrate our method to be more suitable for dimensional chat evaluation than alternative likert-style or comparative methods. We then use our validated method and existing methods to evaluate four open-domain chat models from the recent literature.
Online Coreference Resolution for Dialogue Processing: Improving Mention-Linking on Real-Time Conversations
May 21, 2022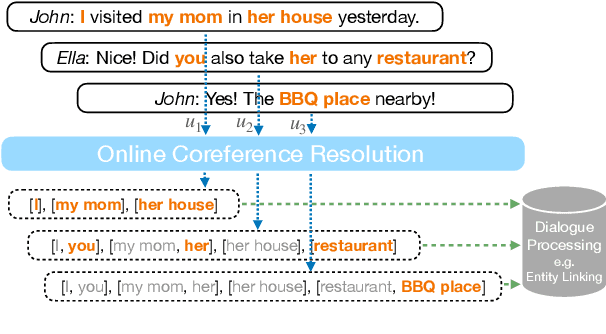
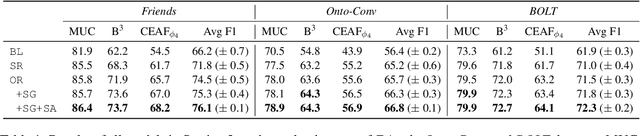
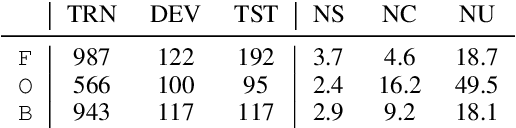
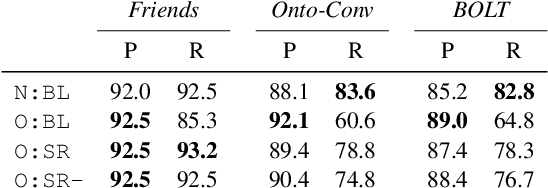
This paper suggests a direction of coreference resolution for online decoding on actively generated input such as dialogue, where the model accepts an utterance and its past context, then finds mentions in the current utterance as well as their referents, upon each dialogue turn. A baseline and four incremental-updated models adapted from the mention-linking paradigm are proposed for this new setting, which address different aspects including the singletons, speaker-grounded encoding and cross-turn mention contextualization. Our approach is assessed on three datasets: Friends, OntoNotes, and BOLT. Results show that each aspect brings out steady improvement, and our best models outperform the baseline by over 10%, presenting an effective system for this setting. Further analysis highlights the task characteristics, such as the significance of addressing the mention recall.