 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingzhao Zhang
Understanding the unstable convergence of gradient descent
Apr 03, 2022
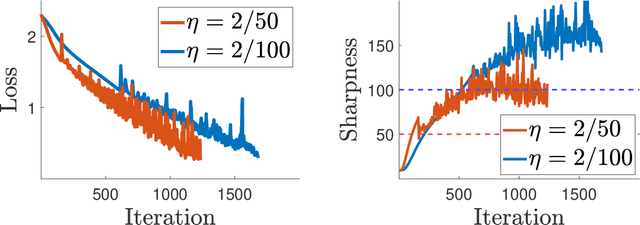

Most existing analyses of (stochastic) gradient descent rely on the condition that for $L$-smooth cost, the step size is less than $2/L$. However, many works have observed that in machine learning applications step sizes often do not fulfill this condition, yet (stochastic) gradient descent converges, albeit in an unstable manner. We investigate this unstable convergence phenomenon from first principles, and elucidate key causes behind it. We also identify its main characteristics, and how they interrelate, offering a transparent view backed by both theory and experiments.
Minimax in Geodesic Metric Spaces: Sion's Theorem and Algorithms
Feb 13, 2022
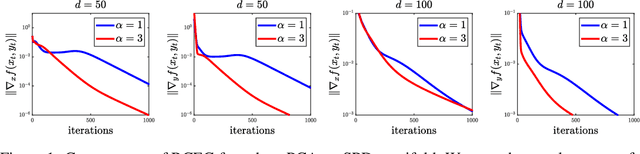

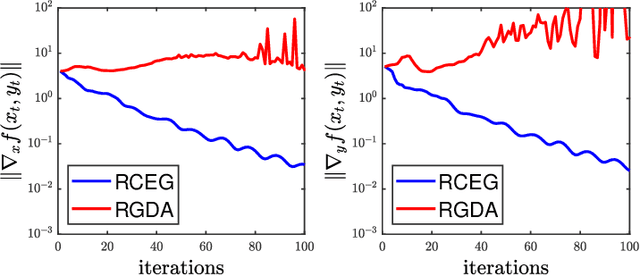
Determining whether saddle points exist or are approximable for nonconvex-nonconcave problems is usually intractable. We take a step towards understanding certain nonconvex-nonconcave minimax problems that do remain tractable. Specifically, we study minimax problems cast in geodesic metric spaces, which provide a vast generalization of the usual convex-concave saddle point problems. The first main result of the paper is a geodesic metric space version of Sion's minimax theorem; we believe our proof is novel and transparent, as it relies on Helly's theorem only. In our second main result, we specialize to geodesically complete Riemannian manifolds: we devise and analyze the complexity of first-order methods for smooth minimax problems.
Detecting Electric Vehicle Battery Failure via Dynamic-VAE
Jan 28, 2022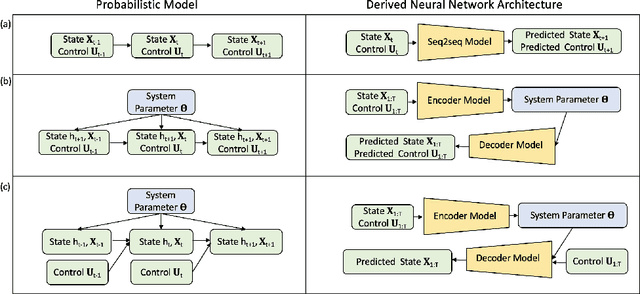
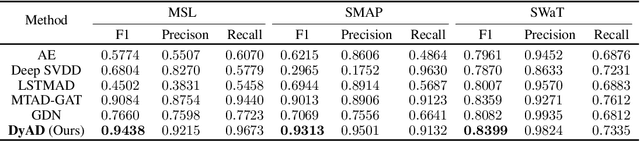
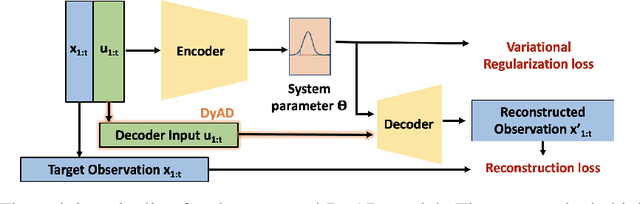

In this note, we describe a battery failure detection pipeline backed up by deep learning models. We first introduce a large-scale Electric vehicle (EV) battery dataset including cleaned battery-charging data from hundreds of vehicles. We then formulate battery failure detection as an outlier detection problem, and propose a new algorithm named Dynamic-VAE based on dynamic system and variational autoencoders. We validate the performance of our proposed algorithm against several baselines on our released dataset and demonstrated the effectiveness of Dynamic-VAE.
On Convergence of Training Loss Without Reaching Stationary Points
Oct 12, 2021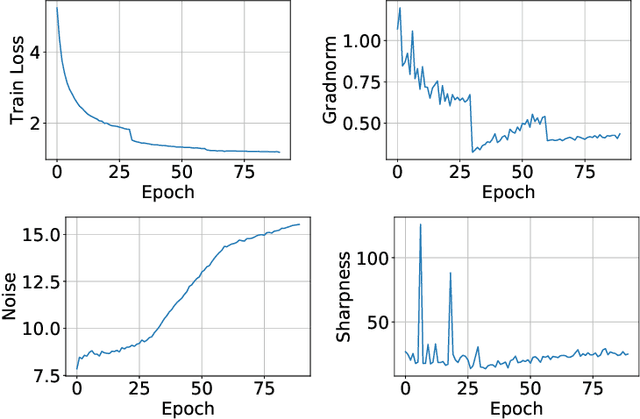
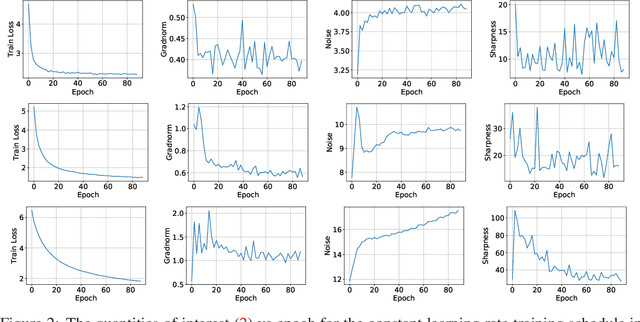

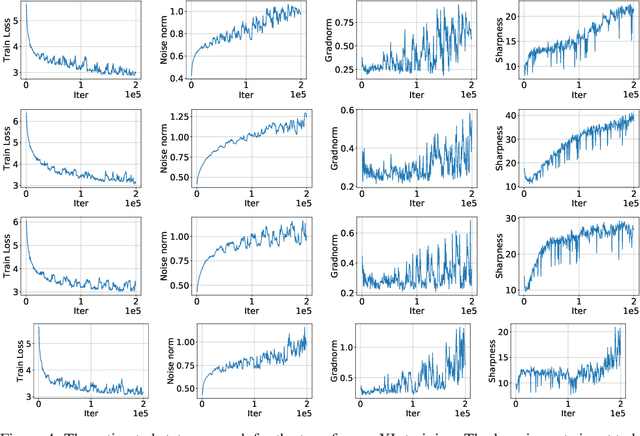
It is a well-known fact that nonconvex optimization is computationally intractable in the worst case. As a result, theoretical analysis of optimization algorithms such as gradient descent often focuses on local convergence to stationary points where the gradient norm is zero or negligible. In this work, we examine the disconnect between the existing theoretical analysis of gradient-based algorithms and actual practice. Specifically, we provide numerical evidence that in large-scale neural network training, such as in ImageNet, ResNet, and WT103 + TransformerXL models, the Neural Network weight variables do not converge to stationary points where the gradient of the loss function vanishes. Remarkably, however, we observe that while weights do not converge to stationary points, the value of the loss function converges. Inspired by this observation, we propose a new perspective based on ergodic theory of dynamical systems. We prove convergence of the distribution of weight values to an approximate invariant measure (without smoothness assumptions) that explains this phenomenon. We further discuss how this perspective can better align the theory with empirical observations.
Fast Federated Learning in the Presence of Arbitrary Device Unavailability
Jun 08, 2021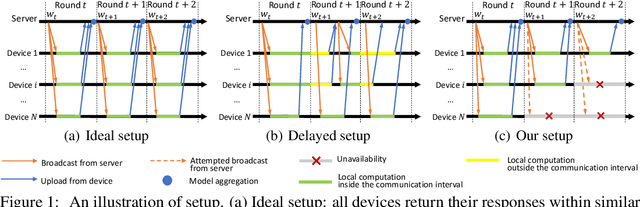
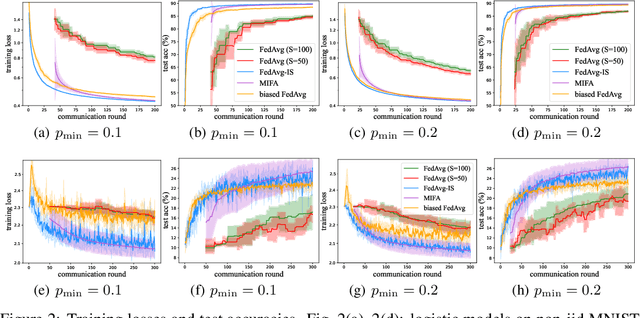
Federated Learning (FL) coordinates with numerous heterogeneous devices to collaboratively train a shared model while preserving user privacy. Despite its multiple advantages, FL faces new challenges. One challenge arises when devices drop out of the training process beyond the control of the central server. In this case, the convergence of popular FL algorithms such as FedAvg is severely influenced by the straggling devices. To tackle this challenge, we study federated learning algorithms under arbitrary device unavailability and propose an algorithm named Memory-augmented Impatient Federated Averaging (MIFA). Our algorithm efficiently avoids excessive latency induced by inactive devices, and corrects the gradient bias using the memorized latest updates from the devices. We prove that MIFA achieves minimax optimal convergence rates on non-i.i.d. data for both strongly convex and non-convex smooth functions. We also provide an explicit characterization of the improvement over baseline algorithms through a case study, and validate the results by numerical experiments on real-world datasets.
Complexity Lower Bounds for Nonconvex-Strongly-Concave Min-Max Optimization
Apr 18, 2021
We provide a first-order oracle complexity lower bound for finding stationary points of min-max optimization problems where the objective function is smooth, nonconvex in the minimization variable, and strongly concave in the maximization variable. We establish a lower bound of $\Omega\left(\sqrt{\kappa}\epsilon^{-2}\right)$ for deterministic oracles, where $\epsilon$ defines the level of approximate stationarity and $\kappa$ is the condition number. Our analysis shows that the upper bound achieved in (Lin et al., 2020b) is optimal in the $\epsilon$ and $\kappa$ dependence up to logarithmic factors. For stochastic oracles, we provide a lower bound of $\Omega\left(\sqrt{\kappa}\epsilon^{-2} + \kappa^{1/3}\epsilon^{-4}\right)$. It suggests that there is a significant gap between the upper bound $\mathcal{O}(\kappa^3 \epsilon^{-4})$ in (Lin et al., 2020a) and our lower bound in the condition number dependence.
Provably Efficient Algorithms for Multi-Objective Competitive RL
Feb 05, 2021
We study multi-objective reinforcement learning (RL) where an agent's reward is represented as a vector. In settings where an agent competes against opponents, its performance is measured by the distance of its average return vector to a target set. We develop statistically and computationally efficient algorithms to approach the associated target set. Our results extend Blackwell's approachability theorem (Blackwell, 1956) to tabular RL, where strategic exploration becomes essential. The algorithms presented are adaptive; their guarantees hold even without Blackwell's approachability condition. If the opponents use fixed policies, we give an improved rate of approaching the target set while also tackling the more ambitious goal of simultaneously minimizing a scalar cost function. We discuss our analysis for this special case by relating our results to previous works on constrained RL. To our knowledge, this work provides the first provably efficient algorithms for vector-valued Markov games and our theoretical guarantees are near-optimal.
Coping with Label Shift via Distributionally Robust Optimisation
Oct 23, 2020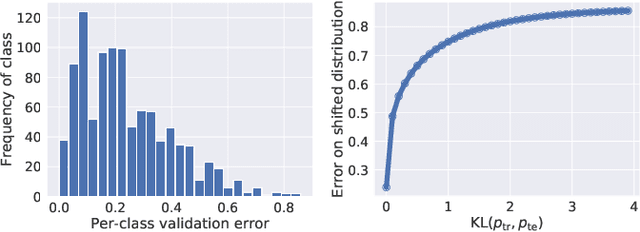

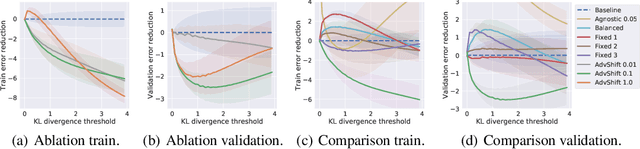
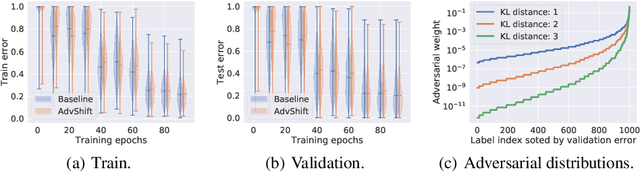
The label shift problem refers to the supervised learning setting where the train and test label distributions do not match. Existing work addressing label shift usually assumes access to an \emph{unlabelled} test sample. This sample may be used to estimate the test label distribution, and to then train a suitably re-weighted classifier. While approaches using this idea have proven effective, their scope is limited as it is not always feasible to access the target domain; further, they require repeated retraining if the model is to be deployed in \emph{multiple} test environments. Can one instead learn a \emph{single} classifier that is robust to arbitrary label shifts from a broad family? In this paper, we answer this question by proposing a model that minimises an objective based on distributionally robust optimisation (DRO). We then design and analyse a gradient descent-proximal mirror ascent algorithm tailored for large-scale problems to optimise the proposed objective. %, and establish its convergence. Finally, through experiments on CIFAR-100 and ImageNet, we show that our technique can significantly improve performance over a number of baselines in settings where label shift is present.
Stochastic Optimization with Non-stationary Noise
Jun 09, 2020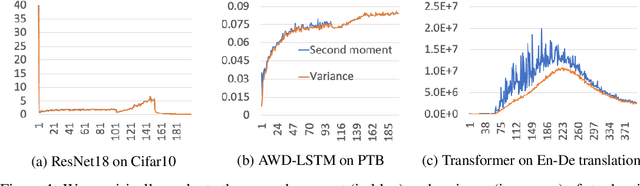

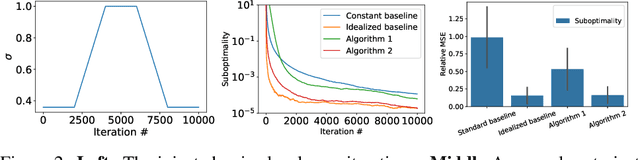

We investigate stochastic optimization problems under relaxed assumptions on the distribution of noise that are motivated by empirical observations in neural network training. Standard results on optimal convergence rates for stochastic optimization assume either there exists a uniform bound on the moments of the gradient noise, or that the noise decays as the algorithm progresses. These assumptions do not match the empirical behavior of optimization algorithms used in neural network training where the noise level in stochastic gradients could even increase with time. We address this behavior by studying convergence rates of stochastic gradient methods subject to changing second moment (or variance) of the stochastic oracle as the iterations progress. When the variation in the noise is known, we show that it is always beneficial to adapt the step-size and exploit the noise variability. When the noise statistics are unknown, we obtain similar improvements by developing an online estimator of the noise level, thereby recovering close variants of RMSProp. Consequently, our results reveal an important scenario where adaptive stepsize methods outperform SGD.
On Complexity of Finding Stationary Points of Nonsmooth Nonconvex Functions
Feb 16, 2020
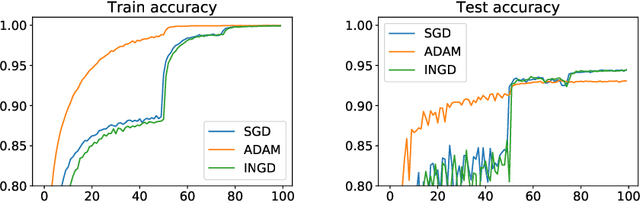
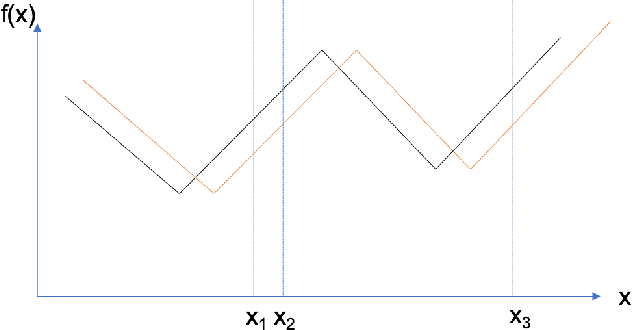
We provide the first \emph{non-asymptotic} analysis for finding stationary points of nonsmooth, nonconvex functions. In particular, we study the class of Hadamard semi-differentiable functions, perhaps the largest class of nonsmooth functions for which the chain rule of calculus holds. This class contains important examples such as ReLU neural networks and others with non-differentiable activation functions. First, we show that finding an $\epsilon$-stationary point with first-order methods is impossible in finite time. Therefore, we introduce the notion of \emph{$(\delta, \epsilon)$-stationarity}, a generalization that allows for a point to be within distance $\delta$ of an $\epsilon$-stationary point and reduces to $\epsilon$-stationarity for smooth functions. We propose a series of randomized first-order methods and analyze their complexity of finding a $(\delta, \epsilon)$-stationary point. Furthermore, we provide a lower bound and show that our stochastic algorithm has min-max optimal dependence on $\delta$. Empirically, our methods perform well for training ReLU neural networks.