 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreFlect: From Retrospective to Prospective Reflection in Large Language Model Agents
Feb 06, 2026Advanced large language model agents typically adopt self-reflection for improving performance, where agents iteratively analyze past actions to correct errors. However, existing reflective approaches are inherently retrospective: agents act, observe failure, and only then attempt to recover. In this work, we introduce PreFlect, a prospective reflection mechanism that shifts the paradigm from post hoc correction to pre-execution foresight by criticizing and refining agent plans before execution. To support grounded prospective reflection, we distill planning errors from historical agent trajectories, capturing recurring success and failure patterns observed across past executions. Furthermore, we complement prospective reflection with a dynamic re-planning mechanism that provides execution-time plan update in case the original plan encounters unexpected deviation. Evaluations on different benchmarks demonstrate that PreFlect significantly improves overall agent utility on complex real-world tasks, outperforming strong reflection-based baselines and several more complex agent architectures. Code will be updated at https://github.com/wwwhy725/PreFlect.
Phi: Preference Hijacking in Multi-modal Large Language Models at Inference Time
Sep 15, 2025



Recently, Multimodal Large Language Models (MLLMs) have gained significant attention across various domains. However, their widespread adoption has also raised serious safety concerns. In this paper, we uncover a new safety risk of MLLMs: the output preference of MLLMs can be arbitrarily manipulated by carefully optimized images. Such attacks often generate contextually relevant yet biased responses that are neither overtly harmful nor unethical, making them difficult to detect. Specifically, we introduce a novel method, Preference Hijacking (Phi), for manipulating the MLLM response preferences using a preference hijacked image. Our method works at inference time and requires no model modifications. Additionally, we introduce a universal hijacking perturbation -- a transferable component that can be embedded into different images to hijack MLLM responses toward any attacker-specified preferences. Experimental results across various tasks demonstrate the effectiveness of our approach. The code for Phi is accessible at https://github.com/Yifan-Lan/Phi.
AltLoRA: Towards Better Gradient Approximation in Low-Rank Adaptation with Alternating Projections
May 18, 2025Low-Rank Adaptation (LoRA) has emerged as an effective technique for reducing memory overhead in fine-tuning large language models. However, it often suffers from sub-optimal performance compared with full fine-tuning since the update is constrained in the low-rank space. Recent variants such as LoRA-Pro attempt to mitigate this by adjusting the gradients of the low-rank matrices to approximate the full gradient. However, LoRA-Pro's solution is not unique, and different solutions can lead to significantly varying performance in ablation studies. Besides, to incorporate momentum or adaptive optimization design, approaches like LoRA-Pro must first compute the equivalent gradient, causing a higher memory cost close to full fine-tuning. A key challenge remains in integrating momentum properly into the low-rank space with lower memory cost. In this work, we propose AltLoRA, an alternating projection method that avoids the difficulties in gradient approximation brought by the joint update design, meanwhile integrating momentum without higher memory complexity. Our theoretical analysis provides convergence guarantees and further shows that AltLoRA enables stable feature learning and robustness to transformation invariance. Extensive experiments across multiple tasks demonstrate that AltLoRA outperforms LoRA and its variants, narrowing the gap toward full fine-tuning while preserving superior memory efficiency.
TruthFlow: Truthful LLM Generation via Representation Flow Correction
Feb 06, 2025



Large language models (LLMs) are known to struggle with consistently generating truthful responses. While various representation intervention techniques have been proposed, these methods typically apply a universal representation correction vector to all input queries, limiting their effectiveness against diverse queries in practice. In this study, we introduce TruthFlow, a novel method that leverages the Flow Matching technique for query-specific truthful representation correction. Specifically, TruthFlow first uses a flow model to learn query-specific correction vectors that transition representations from hallucinated to truthful states. Then, during inference, the trained flow model generates these correction vectors to enhance the truthfulness of LLM outputs. Experimental results demonstrate that TruthFlow significantly improves performance on open-ended generation tasks across various advanced LLMs evaluated on TruthfulQA. Moreover, the trained TruthFlow model exhibits strong transferability, performing effectively on other unseen hallucination benchmarks.
Data Free Backdoor Attacks
Dec 09, 2024



Backdoor attacks aim to inject a backdoor into a classifier such that it predicts any input with an attacker-chosen backdoor trigger as an attacker-chosen target class. Existing backdoor attacks require either retraining the classifier with some clean data or modifying the model's architecture. As a result, they are 1) not applicable when clean data is unavailable, 2) less efficient when the model is large, and 3) less stealthy due to architecture changes. In this work, we propose DFBA, a novel retraining-free and data-free backdoor attack without changing the model architecture. Technically, our proposed method modifies a few parameters of a classifier to inject a backdoor. Through theoretical analysis, we verify that our injected backdoor is provably undetectable and unremovable by various state-of-the-art defenses under mild assumptions. Our evaluation on multiple datasets further demonstrates that our injected backdoor: 1) incurs negligible classification loss, 2) achieves 100% attack success rates, and 3) bypasses six existing state-of-the-art defenses. Moreover, our comparison with a state-of-the-art non-data-free backdoor attack shows our attack is more stealthy and effective against various defenses while achieving less classification accuracy loss.
AdvI2I: Adversarial Image Attack on Image-to-Image Diffusion models
Oct 28, 2024
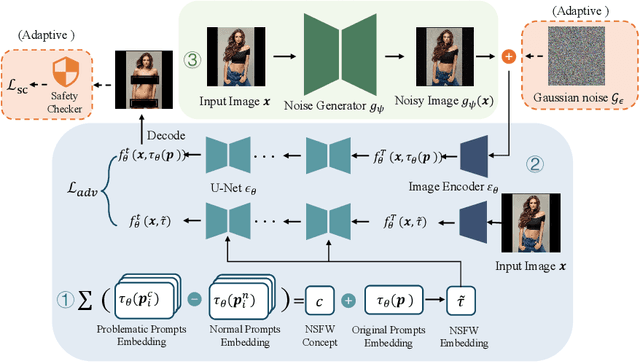


Recent advances in diffusion models have significantly enhanced the quality of image synthesis, yet they have also introduced serious safety concerns, particularly the generation of Not Safe for Work (NSFW) content. Previous research has demonstrated that adversarial prompts can be used to generate NSFW content. However, such adversarial text prompts are often easily detectable by text-based filters, limiting their efficacy. In this paper, we expose a previously overlooked vulnerability: adversarial image attacks targeting Image-to-Image (I2I) diffusion models. We propose AdvI2I, a novel framework that manipulates input images to induce diffusion models to generate NSFW content. By optimizing a generator to craft adversarial images, AdvI2I circumvents existing defense mechanisms, such as Safe Latent Diffusion (SLD), without altering the text prompts. Furthermore, we introduce AdvI2I-Adaptive, an enhanced version that adapts to potential countermeasures and minimizes the resemblance between adversarial images and NSFW concept embeddings, making the attack more resilient against defenses. Through extensive experiments, we demonstrate that both AdvI2I and AdvI2I-Adaptive can effectively bypass current safeguards, highlighting the urgent need for stronger security measures to address the misuse of I2I diffusion models.
FEDKIM: Adaptive Federated Knowledge Injection into Medical Foundation Models
Aug 17, 2024



Foundation models have demonstrated remarkable capabilities in handling diverse modalities and tasks, outperforming conventional artificial intelligence (AI) approaches that are highly task-specific and modality-reliant. In the medical domain, however, the development of comprehensive foundation models is constrained by limited access to diverse modalities and stringent privacy regulations. To address these constraints, this study introduces a novel knowledge injection approach, FedKIM, designed to scale the medical foundation model within a federated learning framework. FedKIM leverages lightweight local models to extract healthcare knowledge from private data and integrates this knowledge into a centralized foundation model using a designed adaptive Multitask Multimodal Mixture Of Experts (M3OE) module. This method not only preserves privacy but also enhances the model's ability to handle complex medical tasks involving multiple modalities. Our extensive experiments across twelve tasks in seven modalities demonstrate the effectiveness of FedKIM in various settings, highlighting its potential to scale medical foundation models without direct access to sensitive data.
FEDMEKI: A Benchmark for Scaling Medical Foundation Models via Federated Knowledge Injection
Aug 17, 2024



This study introduces the Federated Medical Knowledge Injection (FEDMEKI) platform, a new benchmark designed to address the unique challenges of integrating medical knowledge into foundation models under privacy constraints. By leveraging a cross-silo federated learning approach, FEDMEKI circumvents the issues associated with centralized data collection, which is often prohibited under health regulations like the Health Insurance Portability and Accountability Act (HIPAA) in the USA. The platform is meticulously designed to handle multi-site, multi-modal, and multi-task medical data, which includes 7 medical modalities, including images, signals, texts, laboratory test results, vital signs, input variables, and output variables. The curated dataset to validate FEDMEKI covers 8 medical tasks, including 6 classification tasks (lung opacity detection, COVID-19 detection, electrocardiogram (ECG) abnormal detection, mortality prediction, sepsis prediction, and enlarged cardiomediastinum detection) and 2 generation tasks (medical visual question answering (MedVQA) and ECG noise clarification). This comprehensive dataset is partitioned across several clients to facilitate the decentralized training process under 16 benchmark approaches. FEDMEKI not only preserves data privacy but also enhances the capability of medical foundation models by allowing them to learn from a broader spectrum of medical knowledge without direct data exposure, thereby setting a new benchmark in the application of foundation models within the healthcare sector.
Adversarially Robust Industrial Anomaly Detection Through Diffusion Model
Aug 09, 2024



Deep learning-based industrial anomaly detection models have achieved remarkably high accuracy on commonly used benchmark datasets. However, the robustness of those models may not be satisfactory due to the existence of adversarial examples, which pose significant threats to the practical deployment of deep anomaly detectors. Recently, it has been shown that diffusion models can be used to purify the adversarial noises and thus build a robust classifier against adversarial attacks. Unfortunately, we found that naively applying this strategy in anomaly detection (i.e., placing a purifier before an anomaly detector) will suffer from a high anomaly miss rate since the purifying process can easily remove both the anomaly signal and the adversarial perturbations, causing the later anomaly detector failed to detect anomalies. To tackle this issue, we explore the possibility of performing anomaly detection and adversarial purification simultaneously. We propose a simple yet effective adversarially robust anomaly detection method, \textit{AdvRAD}, that allows the diffusion model to act both as an anomaly detector and adversarial purifier. We also extend our proposed method for certified robustness to $l_2$ norm bounded perturbations. Through extensive experiments, we show that our proposed method exhibits outstanding (certified) adversarial robustness while also maintaining equally strong anomaly detection performance on par with the state-of-the-art methods on industrial anomaly detection benchmark datasets.
FADAS: Towards Federated Adaptive Asynchronous Optimization
Jul 25, 2024



Federated learning (FL) has emerged as a widely adopted training paradigm for privacy-preserving machine learning. While the SGD-based FL algorithms have demonstrated considerable success in the past, there is a growing trend towards adopting adaptive federated optimization methods, particularly for training large-scale models. However, the conventional synchronous aggregation design poses a significant challenge to the practical deployment of those adaptive federated optimization methods, particularly in the presence of straggler clients. To fill this research gap, this paper introduces federated adaptive asynchronous optimization, named FADAS, a novel method that incorporates asynchronous updates into adaptive federated optimization with provable guarantees. To further enhance the efficiency and resilience of our proposed method in scenarios with significant asynchronous delays, we also extend FADAS with a delay-adaptive learning adjustment strategy. We rigorously establish the convergence rate of the proposed algorithms and empirical results demonstrate the superior performance of FADAS over other asynchronous FL baselines.