 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Stepsize Gradient Descent for Logistic Loss: Non-Monotonicity of the Loss Improves Optimization Efficiency
Feb 24, 2024


We consider gradient descent (GD) with a constant stepsize applied to logistic regression with linearly separable data, where the constant stepsize $\eta$ is so large that the loss initially oscillates. We show that GD exits this initial oscillatory phase rapidly -- in $\mathcal{O}(\eta)$ steps -- and subsequently achieves an $\tilde{\mathcal{O}}(1 / (\eta t) )$ convergence rate after $t$ additional steps. Our results imply that, given a budget of $T$ steps, GD can achieve an accelerated loss of $\tilde{\mathcal{O}}(1/T^2)$ with an aggressive stepsize $\eta:= \Theta( T)$, without any use of momentum or variable stepsize schedulers. Our proof technique is versatile and also handles general classification loss functions (where exponential tails are needed for the $\tilde{\mathcal{O}}(1/T^2)$ acceleration), nonlinear predictors in the neural tangent kernel regime, and online stochastic gradient descent (SGD) with a large stepsize, under suitable separability conditions.
In-Context Learning of a Linear Transformer Block: Benefits of the MLP Component and One-Step GD Initialization
Feb 22, 2024
We study the \emph{in-context learning} (ICL) ability of a \emph{Linear Transformer Block} (LTB) that combines a linear attention component and a linear multi-layer perceptron (MLP) component. For ICL of linear regression with a Gaussian prior and a \emph{non-zero mean}, we show that LTB can achieve nearly Bayes optimal ICL risk. In contrast, using only linear attention must incur an irreducible additive approximation error. Furthermore, we establish a correspondence between LTB and one-step gradient descent estimators with learnable initialization ($\mathsf{GD}\text{-}\mathbf{\beta}$), in the sense that every $\mathsf{GD}\text{-}\mathbf{\beta}$ estimator can be implemented by an LTB estimator and every optimal LTB estimator that minimizes the in-class ICL risk is effectively a $\mathsf{GD}\text{-}\mathbf{\beta}$ estimator. Finally, we show that $\mathsf{GD}\text{-}\mathbf{\beta}$ estimators can be efficiently optimized with gradient flow, despite a non-convex training objective. Our results reveal that LTB achieves ICL by implementing $\mathsf{GD}\text{-}\mathbf{\beta}$, and they highlight the role of MLP layers in reducing approximation error.
Risk Bounds of Accelerated SGD for Overparameterized Linear Regression
Nov 23, 2023Accelerated stochastic gradient descent (ASGD) is a workhorse in deep learning and often achieves better generalization performance than SGD. However, existing optimization theory can only explain the faster convergence of ASGD, but cannot explain its better generalization. In this paper, we study the generalization of ASGD for overparameterized linear regression, which is possibly the simplest setting of learning with overparameterization. We establish an instance-dependent excess risk bound for ASGD within each eigen-subspace of the data covariance matrix. Our analysis shows that (i) ASGD outperforms SGD in the subspace of small eigenvalues, exhibiting a faster rate of exponential decay for bias error, while in the subspace of large eigenvalues, its bias error decays slower than SGD; and (ii) the variance error of ASGD is always larger than that of SGD. Our result suggests that ASGD can outperform SGD when the difference between the initialization and the true weight vector is mostly confined to the subspace of small eigenvalues. Additionally, when our analysis is specialized to linear regression in the strongly convex setting, it yields a tighter bound for bias error than the best-known result.
How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?
Oct 12, 2023Transformers pretrained on diverse tasks exhibit remarkable in-context learning (ICL) capabilities, enabling them to solve unseen tasks solely based on input contexts without adjusting model parameters. In this paper, we study ICL in one of its simplest setups: pretraining a linearly parameterized single-layer linear attention model for linear regression with a Gaussian prior. We establish a statistical task complexity bound for the attention model pretraining, showing that effective pretraining only requires a small number of independent tasks. Furthermore, we prove that the pretrained model closely matches the Bayes optimal algorithm, i.e., optimally tuned ridge regression, by achieving nearly Bayes optimal risk on unseen tasks under a fixed context length. These theoretical findings complement prior experimental research and shed light on the statistical foundations of ICL.
Private Federated Frequency Estimation: Adapting to the Hardness of the Instance
Jun 15, 2023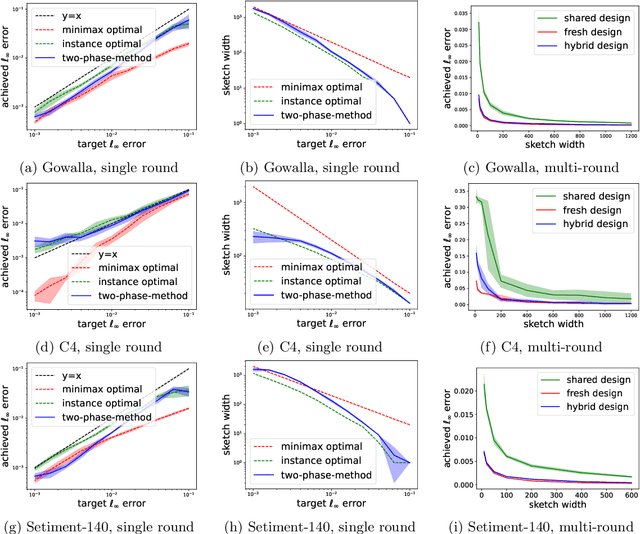
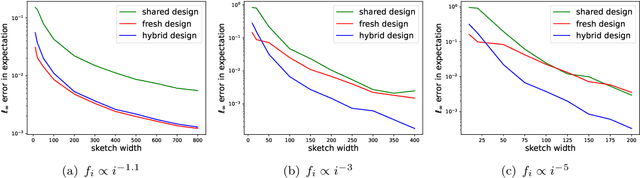
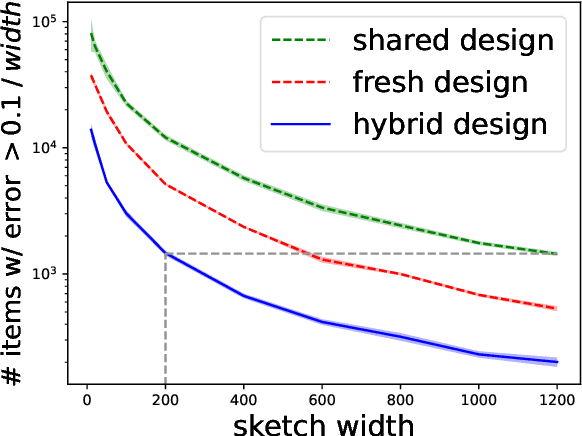
In federated frequency estimation (FFE), multiple clients work together to estimate the frequencies of their collective data by communicating with a server that respects the privacy constraints of Secure Summation (SecSum), a cryptographic multi-party computation protocol that ensures that the server can only access the sum of client-held vectors. For single-round FFE, it is known that count sketching is nearly information-theoretically optimal for achieving the fundamental accuracy-communication trade-offs [Chen et al., 2022]. However, we show that under the more practical multi-round FEE setting, simple adaptations of count sketching are strictly sub-optimal, and we propose a novel hybrid sketching algorithm that is provably more accurate. We also address the following fundamental question: how should a practitioner set the sketch size in a way that adapts to the hardness of the underlying problem? We propose a two-phase approach that allows for the use of a smaller sketch size for simpler problems (e.g. near-sparse or light-tailed distributions). We conclude our work by showing how differential privacy can be added to our algorithm and verifying its superior performance through extensive experiments conducted on large-scale datasets.
Implicit Bias of Gradient Descent for Logistic Regression at the Edge of Stability
May 19, 2023Recent research has observed that in machine learning optimization, gradient descent (GD) often operates at the edge of stability (EoS) [Cohen, et al., 2021], where the stepsizes are set to be large, resulting in non-monotonic losses induced by the GD iterates. This paper studies the convergence and implicit bias of constant-stepsize GD for logistic regression on linearly separable data in the EoS regime. Despite the presence of local oscillations, we prove that the logistic loss can be minimized by GD with any constant stepsize over a long time scale. Furthermore, we prove that with any constant stepsize, the GD iterates tend to infinity when projected to a max-margin direction (the hard-margin SVM direction) and converge to a fixed vector that minimizes a strongly convex potential when projected to the orthogonal complement of the max-margin direction. In contrast, we also show that in the EoS regime, GD iterates may diverge catastrophically under the exponential loss, highlighting the superiority of the logistic loss. These theoretical findings are in line with numerical simulations and complement existing theories on the convergence and implicit bias of GD, which are only applicable when the stepsizes are sufficiently small.
Fixed Design Analysis of Regularization-Based Continual Learning
Mar 17, 2023We consider a continual learning (CL) problem with two linear regression tasks in the fixed design setting, where the feature vectors are assumed fixed and the labels are assumed to be random variables. We consider an $\ell_2$-regularized CL algorithm, which computes an Ordinary Least Squares parameter to fit the first dataset, then computes another parameter that fits the second dataset under an $\ell_2$-regularization penalizing its deviation from the first parameter, and outputs the second parameter. For this algorithm, we provide tight bounds on the average risk over the two tasks. Our risk bounds reveal a provable trade-off between forgetting and intransigence of the $\ell_2$-regularized CL algorithm: with a large regularization parameter, the algorithm output forgets less information about the first task but is intransigent to extract new information from the second task; and vice versa. Our results suggest that catastrophic forgetting could happen for CL with dissimilar tasks (under a precise similarity measurement) and that a well-tuned $\ell_2$-regularization can partially mitigate this issue by introducing intransigence.
Learning High-Dimensional Single-Neuron ReLU Networks with Finite Samples
Mar 03, 2023This paper considers the problem of learning a single ReLU neuron with squared loss (a.k.a., ReLU regression) in the overparameterized regime, where the input dimension can exceed the number of samples. We analyze a Perceptron-type algorithm called GLM-tron (Kakade et al., 2011), and provide its dimension-free risk upper bounds for high-dimensional ReLU regression in both well-specified and misspecified settings. Our risk bounds recover several existing results as special cases. Moreover, in the well-specified setting, we also provide an instance-wise matching risk lower bound for GLM-tron. Our upper and lower risk bounds provide a sharp characterization of the high-dimensional ReLU regression problems that can be learned via GLM-tron. On the other hand, we provide some negative results for stochastic gradient descent (SGD) for ReLU regression with symmetric Bernoulli data: if the model is well-specified, the excess risk of SGD is provably no better than that of GLM-tron ignoring constant factors, for each problem instance; and in the noiseless case, GLM-tron can achieve a small risk while SGD unavoidably suffers from a constant risk in expectation. These results together suggest that GLM-tron might be preferable than SGD for high-dimensional ReLU regression.
The Power and Limitation of Pretraining-Finetuning for Linear Regression under Covariate Shift
Aug 03, 2022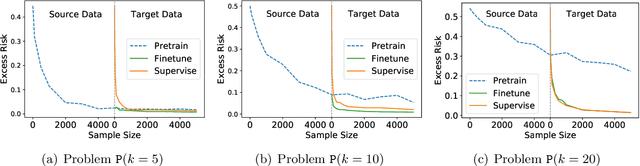
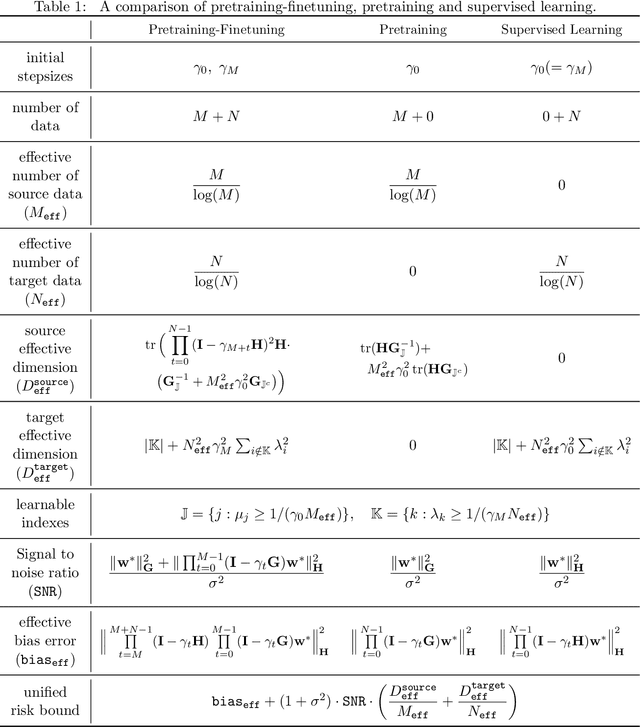
We study linear regression under covariate shift, where the marginal distribution over the input covariates differs in the source and the target domains, while the conditional distribution of the output given the input covariates is similar across the two domains. We investigate a transfer learning approach with pretraining on the source data and finetuning based on the target data (both conducted by online SGD) for this problem. We establish sharp instance-dependent excess risk upper and lower bounds for this approach. Our bounds suggest that for a large class of linear regression instances, transfer learning with $O(N^2)$ source data (and scarce or no target data) is as effective as supervised learning with $N$ target data. In addition, we show that finetuning, even with only a small amount of target data, could drastically reduce the amount of source data required by pretraining. Our theory sheds light on the effectiveness and limitation of pretraining as well as the benefits of finetuning for tackling covariate shift problems.
Risk Bounds of Multi-Pass SGD for Least Squares in the Interpolation Regime
Mar 07, 2022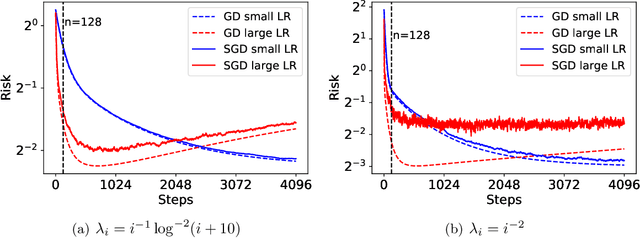
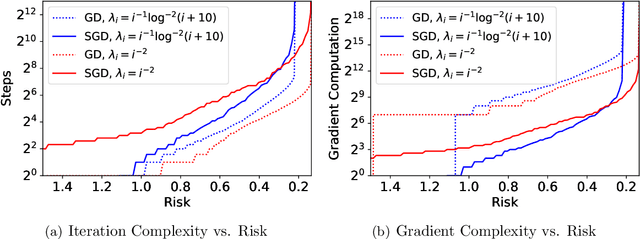
Stochastic gradient descent (SGD) has achieved great success due to its superior performance in both optimization and generalization. Most of existing generalization analyses are made for single-pass SGD, which is a less practical variant compared to the commonly-used multi-pass SGD. Besides, theoretical analyses for multi-pass SGD often concern a worst-case instance in a class of problems, which may be pessimistic to explain the superior generalization ability for some particular problem instance. The goal of this paper is to sharply characterize the generalization of multi-pass SGD, by developing an instance-dependent excess risk bound for least squares in the interpolation regime, which is expressed as a function of the iteration number, stepsize, and data covariance. We show that the excess risk of SGD can be exactly decomposed into the excess risk of GD and a positive fluctuation error, suggesting that SGD always performs worse, instance-wisely, than GD, in generalization. On the other hand, we show that although SGD needs more iterations than GD to achieve the same level of excess risk, it saves the number of stochastic gradient evaluations, and therefore is preferable in terms of computational time.