 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapitch: Adaption Multi-Speaker Text-to-Speech Conditioned on Pitch Disentangling with Untranscribed Data
Oct 25, 2022In this paper, we proposed Adapitch, a multi-speaker TTS method that makes adaptation of the supervised module with untranscribed data. We design two self supervised modules to train the text encoder and mel decoder separately with untranscribed data to enhance the representation of text and mel. To better handle the prosody information in a synthesized voice, a supervised TTS module is designed conditioned on content disentangling of pitch, text, and speaker. The training phase was separated into two parts, pretrained and fixed the text encoder and mel decoder with unsupervised mode, then the supervised mode on the disentanglement of TTS. Experiment results show that the Adaptich achieved much better quality than baseline methods.
Linguistic-Enhanced Transformer with CTC Embedding for Speech Recognition
Oct 25, 2022



The recent emergence of joint CTC-Attention model shows significant improvement in automatic speech recognition (ASR). The improvement largely lies in the modeling of linguistic information by decoder. The decoder joint-optimized with an acoustic encoder renders the language model from ground-truth sequences in an auto-regressive manner during training. However, the training corpus of the decoder is limited to the speech transcriptions, which is far less than the corpus needed to train an acceptable language model. This leads to poor robustness of decoder. To alleviate this problem, we propose linguistic-enhanced transformer, which introduces refined CTC information to decoder during training process, so that the decoder can be more robust. Our experiments on AISHELL-1 speech corpus show that the character error rate (CER) is relatively reduced by up to 7%. We also find that in joint CTC-Attention ASR model, decoder is more sensitive to linguistic information than acoustic information.
Semi-Supervised Learning Based on Reference Model for Low-resource TTS
Oct 25, 2022Most previous neural text-to-speech (TTS) methods are mainly based on supervised learning methods, which means they depend on a large training dataset and hard to achieve comparable performance under low-resource conditions. To address this issue, we propose a semi-supervised learning method for neural TTS in which labeled target data is limited, which can also resolve the problem of exposure bias in the previous auto-regressive models. Specifically, we pre-train the reference model based on Fastspeech2 with much source data, fine-tuned on a limited target dataset. Meanwhile, pseudo labels generated by the original reference model are used to guide the fine-tuned model's training further, achieve a regularization effect, and reduce the overfitting of the fine-tuned model during training on the limited target data. Experimental results show that our proposed semi-supervised learning scheme with limited target data significantly improves the voice quality for test data to achieve naturalness and robustness in speech synthesis.
Improving Imbalanced Text Classification with Dynamic Curriculum Learning
Oct 25, 2022Recent advances in pre-trained language models have improved the performance for text classification tasks. However, little attention is paid to the priority scheduling strategy on the samples during training. Humans acquire knowledge gradually from easy to complex concepts, and the difficulty of the same material can also vary significantly in different learning stages. Inspired by this insights, we proposed a novel self-paced dynamic curriculum learning (SPDCL) method for imbalanced text classification, which evaluates the sample difficulty by both linguistic character and model capacity. Meanwhile, rather than using static curriculum learning as in the existing research, our SPDCL can reorder and resample training data by difficulty criterion with an adaptive from easy to hard pace. The extensive experiments on several classification tasks show the effectiveness of SPDCL strategy, especially for the imbalanced dataset.
MetaSpeech: Speech Effects Switch Along with Environment for Metaverse
Oct 25, 2022Metaverse expands the physical world to a new dimension, and the physical environment and Metaverse environment can be directly connected and entered. Voice is an indispensable communication medium in the real world and Metaverse. Fusion of the voice with environment effects is important for user immersion in Metaverse. In this paper, we proposed using the voice conversion based method for the conversion of target environment effect speech. The proposed method was named MetaSpeech, which introduces an environment effect module containing an effect extractor to extract the environment information and an effect encoder to encode the environment effect condition, in which gradient reversal layer was used for adversarial training to keep the speech content and speaker information while disentangling the environmental effects. From the experiment results on the public dataset of LJSpeech with four environment effects, the proposed model could complete the specific environment effect conversion and outperforms the baseline methods from the voice conversion task.
SVLDL: Improved Speaker Age Estimation Using Selective Variance Label Distribution Learning
Oct 18, 2022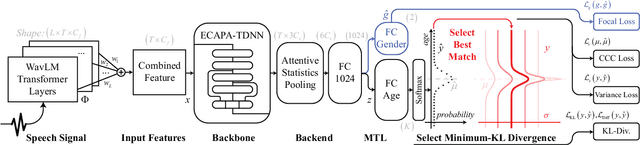
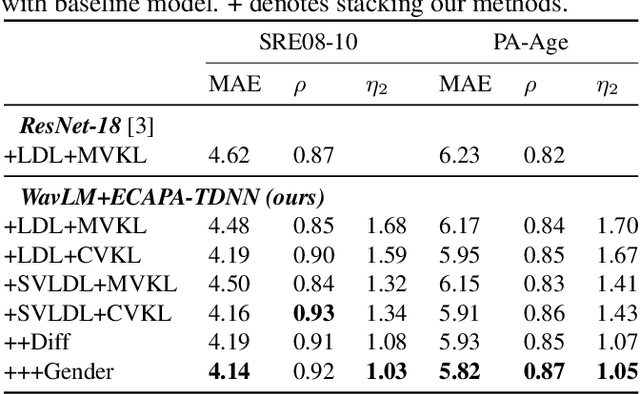
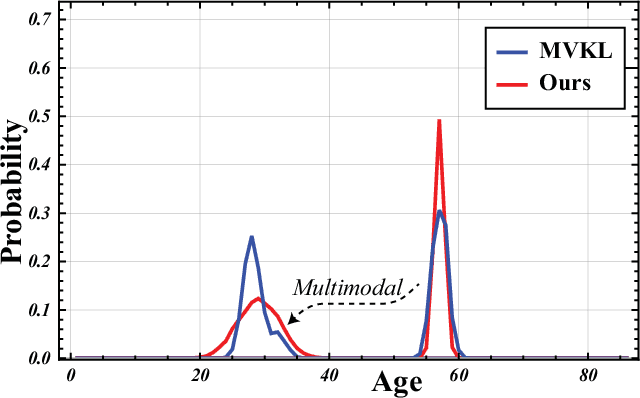

Estimating age from a single speech is a classic and challenging topic. Although Label Distribution Learning (LDL) can represent adjacent indistinguishable ages well, the uncertainty of the age estimate for each utterance varies from person to person, i.e., the variance of the age distribution is different. To address this issue, we propose selective variance label distribution learning (SVLDL) method to adapt the variance of different age distributions. Furthermore, the model uses WavLM as the speech feature extractor and adds the auxiliary task of gender recognition to further improve the performance. Two tricks are applied on the loss function to enhance the robustness of the age estimation and improve the quality of the fitted age distribution. Extensive experiments show that the model achieves state-of-the-art performance on all aspects of the NIST SRE08-10 and a real-world datasets.
Learning Invariant Representation and Risk Minimized for Unsupervised Accent Domain Adaptation
Oct 15, 2022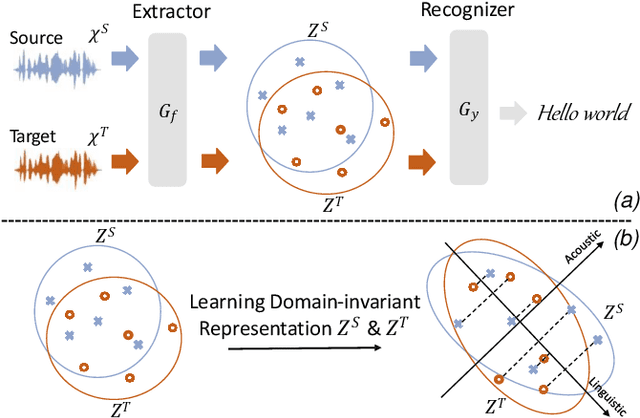
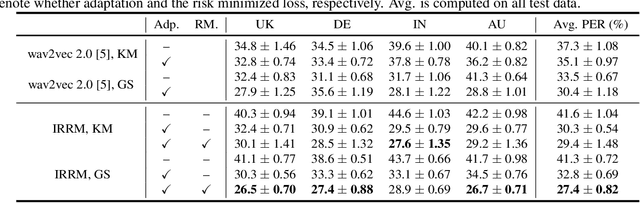
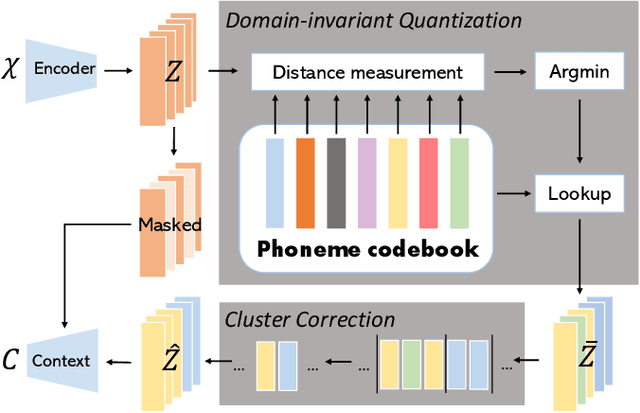

Unsupervised representation learning for speech audios attained impressive performances for speech recognition tasks, particularly when annotated speech is limited. However, the unsupervised paradigm needs to be carefully designed and little is known about what properties these representations acquire. There is no guarantee that the model learns meaningful representations for valuable information for recognition. Moreover, the adaptation ability of the learned representations to other domains still needs to be estimated. In this work, we explore learning domain-invariant representations via a direct mapping of speech representations to their corresponding high-level linguistic informations. Results prove that the learned latents not only capture the articulatory feature of each phoneme but also enhance the adaptation ability, outperforming the baseline largely on accented benchmarks.
Pre-Avatar: An Automatic Presentation Generation Framework Leveraging Talking Avatar
Oct 13, 2022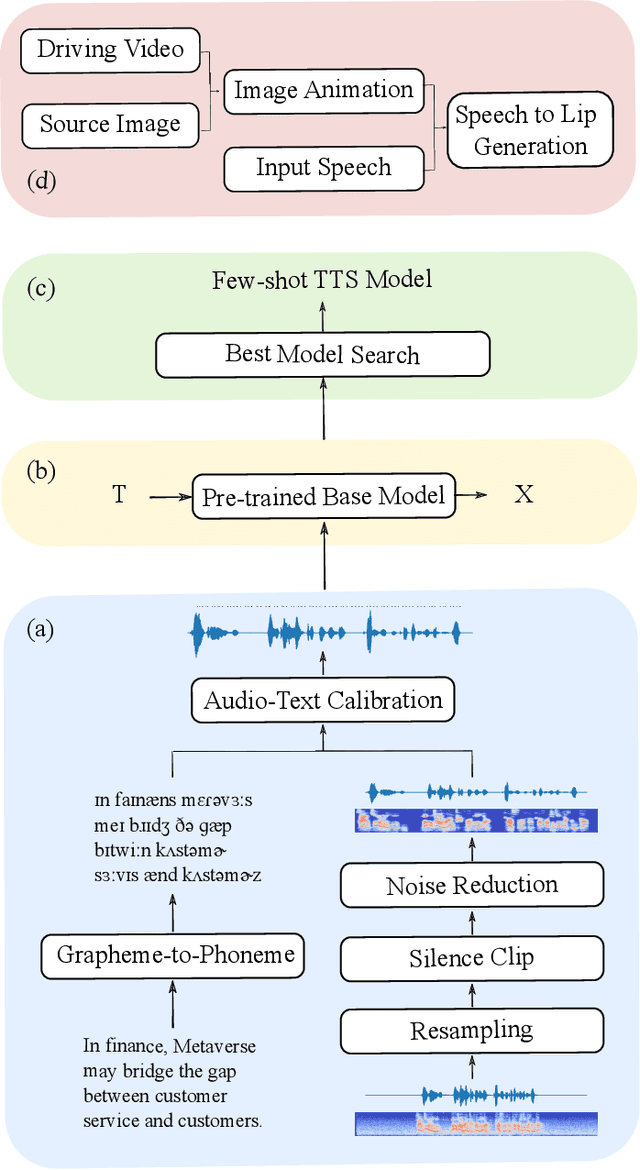
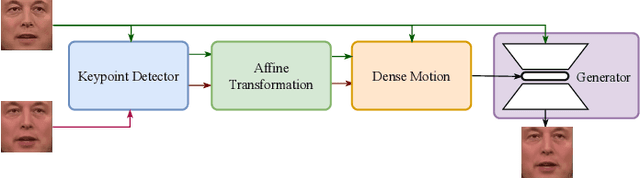

Since the beginning of the COVID-19 pandemic, remote conferencing and school-teaching have become important tools. The previous applications aim to save the commuting cost with real-time interactions. However, our application is going to lower the production and reproduction costs when preparing the communication materials. This paper proposes a system called Pre-Avatar, generating a presentation video with a talking face of a target speaker with 1 front-face photo and a 3-minute voice recording. Technically, the system consists of three main modules, user experience interface (UEI), talking face module and few-shot text-to-speech (TTS) module. The system firstly clones the target speaker's voice, and then generates the speech, and finally generate an avatar with appropriate lip and head movements. Under any scenario, users only need to replace slides with different notes to generate another new video. The demo has been released here and will be published as free software for use.
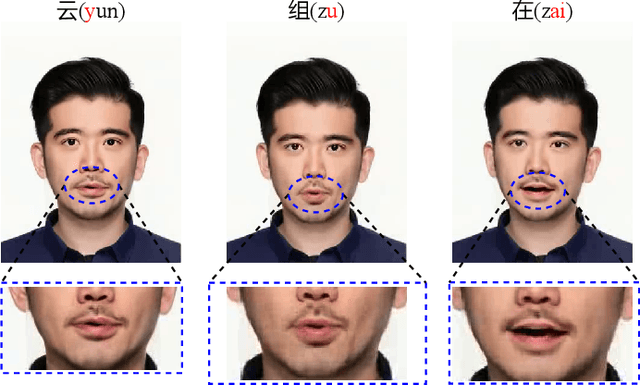
Pose Guided Human Image Synthesis with Partially Decoupled GAN
Oct 07, 2022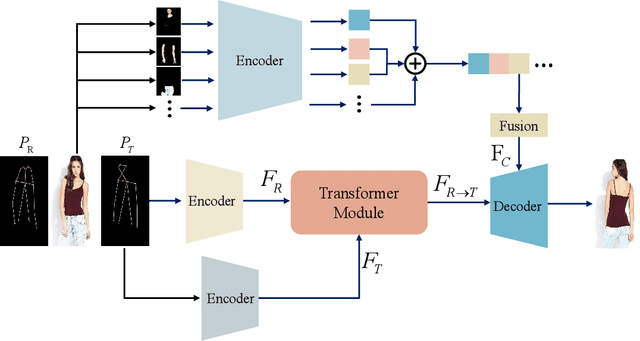
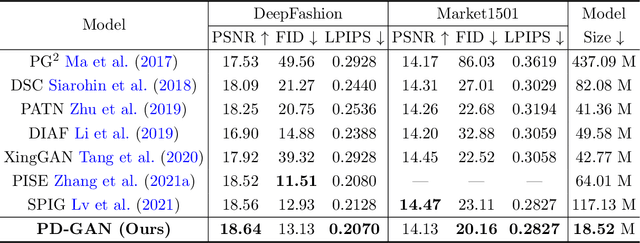
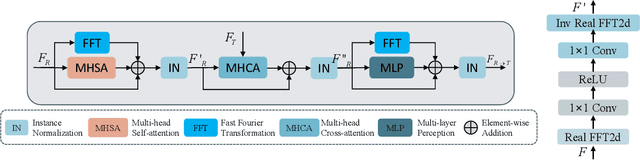

Pose Guided Human Image Synthesis (PGHIS) is a challenging task of transforming a human image from the reference pose to a target pose while preserving its style. Most existing methods encode the texture of the whole reference human image into a latent space, and then utilize a decoder to synthesize the image texture of the target pose. However, it is difficult to recover the detailed texture of the whole human image. To alleviate this problem, we propose a method by decoupling the human body into several parts (\eg, hair, face, hands, feet, \etc) and then using each of these parts to guide the synthesis of a realistic image of the person, which preserves the detailed information of the generated images. In addition, we design a multi-head attention-based module for PGHIS. Because most convolutional neural network-based methods have difficulty in modeling long-range dependency due to the convolutional operation, the long-range modeling capability of attention mechanism is more suitable than convolutional neural networks for pose transfer task, especially for sharp pose deformation. Extensive experiments on Market-1501 and DeepFashion datasets reveal that our method almost outperforms other existing state-of-the-art methods in terms of both qualitative and quantitative metrics.
RL-MD: A Novel Reinforcement Learning Approach for DNA Motif Discovery
Sep 30, 2022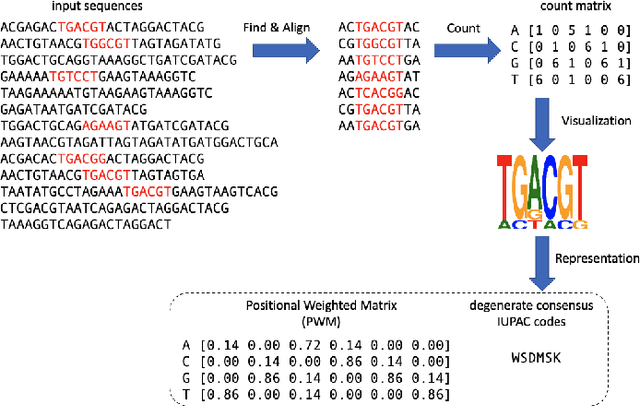
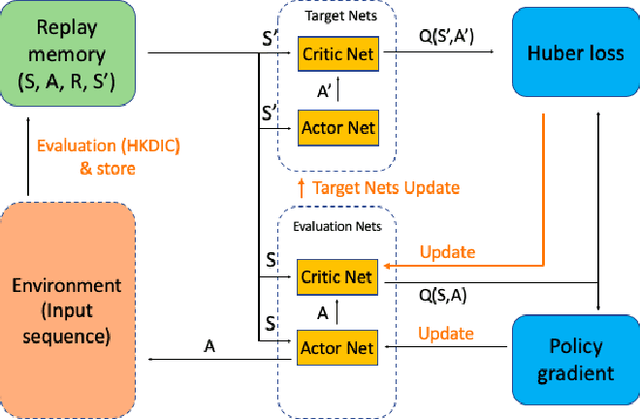
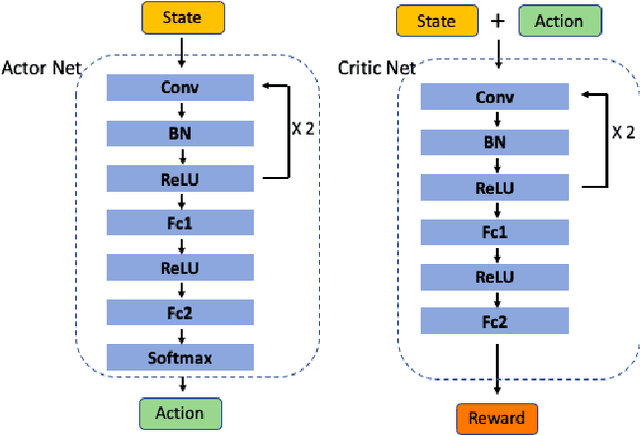

The extraction of sequence patterns from a collection of functionally linked unlabeled DNA sequences is known as DNA motif discovery, and it is a key task in computational biology. Several deep learning-based techniques have recently been introduced to address this issue. However, these algorithms can not be used in real-world situations because of the need for labeled data. Here, we presented RL-MD, a novel reinforcement learning based approach for DNA motif discovery task. RL-MD takes unlabelled data as input, employs a relative information-based method to evaluate each proposed motif, and utilizes these continuous evaluation results as the reward. The experiments show that RL-MD can identify high-quality motifs in real-world data.