 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCITADEL: Conditional Token Interaction via Dynamic Lexical Routing for Efficient and Effective Multi-Vector Retrieval
Nov 18, 2022



Multi-vector retrieval methods combine the merits of sparse (e.g. BM25) and dense (e.g. DPR) retrievers and have achieved state-of-the-art performance on various retrieval tasks. These methods, however, are orders of magnitude slower and need much more space to store their indices compared to their single-vector counterparts. In this paper, we unify different multi-vector retrieval models from a token routing viewpoint and propose conditional token interaction via dynamic lexical routing, namely CITADEL, for efficient and effective multi-vector retrieval. CITADEL learns to route different token vectors to the predicted lexical ``keys'' such that a query token vector only interacts with document token vectors routed to the same key. This design significantly reduces the computation cost while maintaining high accuracy. Notably, CITADEL achieves the same or slightly better performance than the previous state of the art, ColBERT-v2, on both in-domain (MS MARCO) and out-of-domain (BEIR) evaluations, while being nearly 40 times faster. Code and data are available at https://github.com/facebookresearch/dpr-scale.
On the Interaction Between Differential Privacy and Gradient Compression in Deep Learning
Nov 01, 2022While differential privacy and gradient compression are separately well-researched topics in machine learning, the study of interaction between these two topics is still relatively new. We perform a detailed empirical study on how the Gaussian mechanism for differential privacy and gradient compression jointly impact test accuracy in deep learning. The existing literature in gradient compression mostly evaluates compression in the absence of differential privacy guarantees, and demonstrate that sufficiently high compression rates reduce accuracy. Similarly, existing literature in differential privacy evaluates privacy mechanisms in the absence of compression, and demonstrates that sufficiently strong privacy guarantees reduce accuracy. In this work, we observe while gradient compression generally has a negative impact on test accuracy in non-private training, it can sometimes improve test accuracy in differentially private training. Specifically, we observe that when employing aggressive sparsification or rank reduction to the gradients, test accuracy is less affected by the Gaussian noise added for differential privacy. These observations are explained through an analysis how differential privacy and compression effects the bias and variance in estimating the average gradient. We follow this study with a recommendation on how to improve test accuracy under the context of differentially private deep learning and gradient compression. We evaluate this proposal and find that it can reduce the negative impact of noise added by differential privacy mechanisms on test accuracy by up to 24.6%, and reduce the negative impact of gradient sparsification on test accuracy by up to 15.1%.
XRICL: Cross-lingual Retrieval-Augmented In-Context Learning for Cross-lingual Text-to-SQL Semantic Parsing
Oct 25, 2022



In-context learning using large language models has recently shown surprising results for semantic parsing tasks such as Text-to-SQL translation. Prompting GPT-3 or Codex using several examples of question-SQL pairs can produce excellent results, comparable to state-of-the-art finetuning-based models. However, existing work primarily focuses on English datasets, and it is unknown whether large language models can serve as competitive semantic parsers for other languages. To bridge this gap, our work focuses on cross-lingual Text-to-SQL semantic parsing for translating non-English utterances into SQL queries based on an English schema. We consider a zero-shot transfer learning setting with the assumption that we do not have any labeled examples in the target language (but have annotated examples in English). This work introduces the XRICL framework, which learns to retrieve relevant English exemplars for a given query to construct prompts. We also include global translation exemplars for a target language to facilitate the translation process for large language models. To systematically evaluate our model, we construct two new benchmark datasets, XSpider and XKaggle-dbqa, which include questions in Chinese, Vietnamese, Farsi, and Hindi. Our experiments show that XRICL effectively leverages large pre-trained language models to outperform existing baselines. Data and code are publicly available at https://github.com/Impavidity/XRICL.
Making a MIRACL: Multilingual Information Retrieval Across a Continuum of Languages
Oct 18, 2022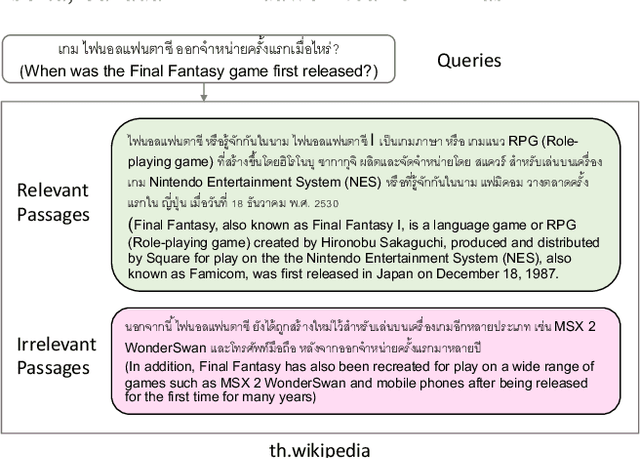
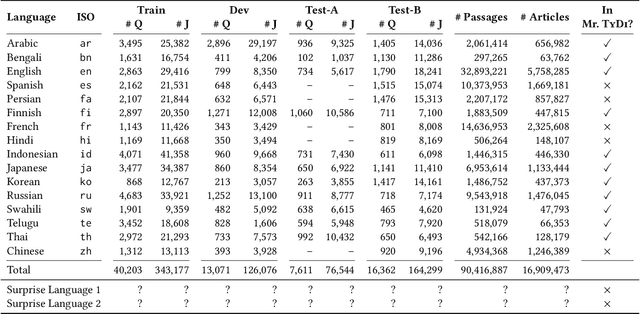
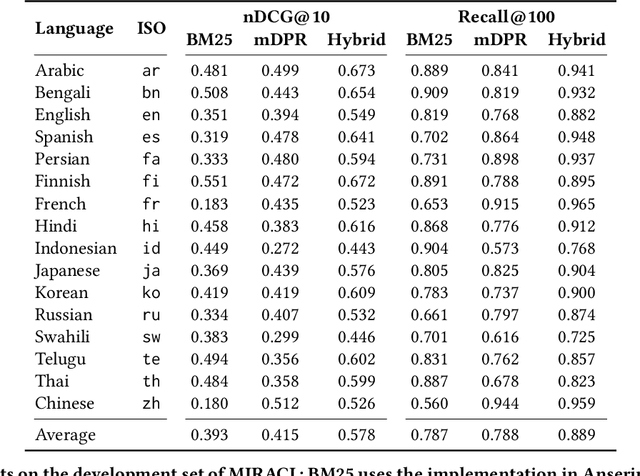
MIRACL (Multilingual Information Retrieval Across a Continuum of Languages) is a multilingual dataset we have built for the WSDM 2023 Cup challenge that focuses on ad hoc retrieval across 18 different languages, which collectively encompass over three billion native speakers around the world. These languages have diverse typologies, originate from many different language families, and are associated with varying amounts of available resources -- including what researchers typically characterize as high-resource as well as low-resource languages. Our dataset is designed to support the creation and evaluation of models for monolingual retrieval, where the queries and the corpora are in the same language. In total, we have gathered over 700k high-quality relevance judgments for around 77k queries over Wikipedia in these 18 languages, where all assessments have been performed by native speakers hired by our team. Our goal is to spur research that will improve retrieval across a continuum of languages, thus enhancing information access capabilities for diverse populations around the world, particularly those that have been traditionally underserved. This overview paper describes the dataset and baselines that we share with the community. The MIRACL website is live at http://miracl.ai/.
VoxelCache: Accelerating Online Mapping in Robotics and 3D Reconstruction Tasks
Oct 17, 2022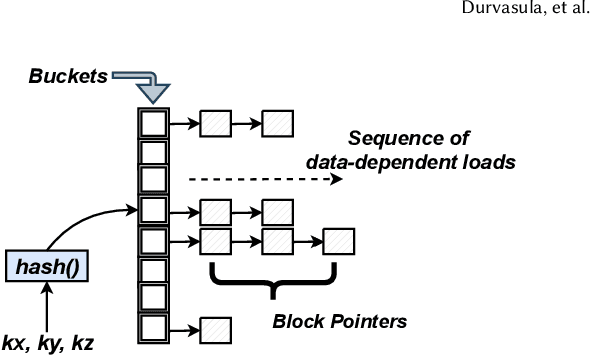
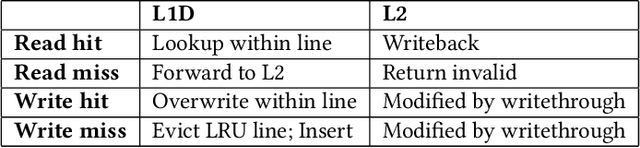
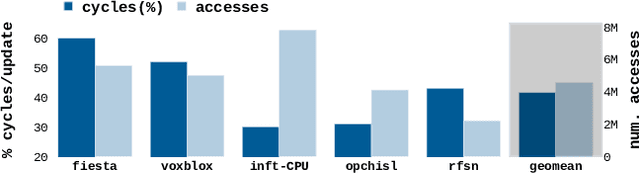
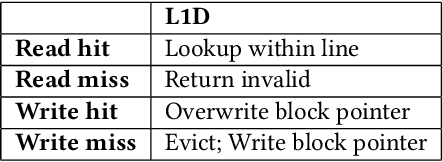
Real-time 3D mapping is a critical component in many important applications today including robotics, AR/VR, and 3D visualization. 3D mapping involves continuously fusing depth maps obtained from depth sensors in phones, robots, and autonomous vehicles into a single 3D representative model of the scene. Many important applications, e.g., global path planning and trajectory generation in micro aerial vehicles, require the construction of large maps at high resolutions. In this work, we identify mapping, i.e., construction and updates of 3D maps to be a critical bottleneck in these applications. The memory required and access times of these maps limit the size of the environment and the resolution with which the environment can be feasibly mapped, especially in resource constrained environments such as autonomous robot platforms and portable devices. To address this challenge, we propose VoxelCache: a hardware-software technique to accelerate map data access times in 3D mapping applications. We observe that mapping applications typically access voxels in the map that are spatially co-located to each other. We leverage this temporal locality in voxel accesses to cache indices to blocks of voxels to enable quick lookup and avoid expensive access times. We evaluate VoxelCache on popularly used mapping and reconstruction applications on both GPUs and CPUs. We demonstrate an average speedup of 1.47X (up to 1.66X) and 1.79X (up to 1.91X) on CPUs and GPUs respectively.
Query Expansion Using Contextual Clue Sampling with Language Models
Oct 13, 2022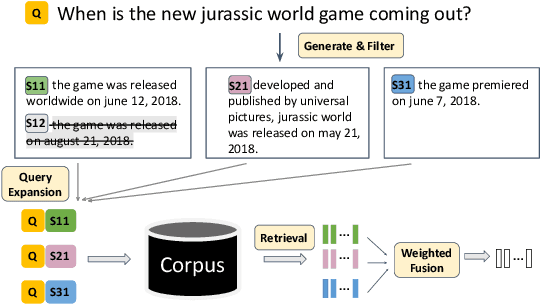
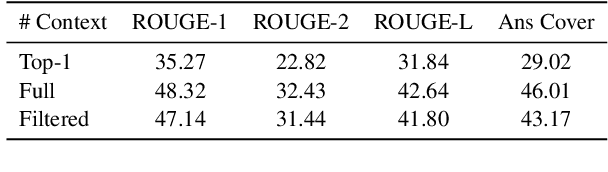
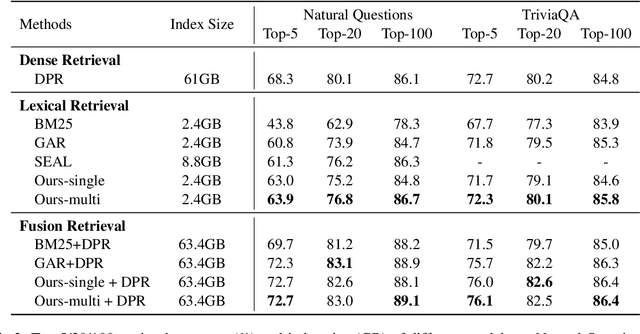
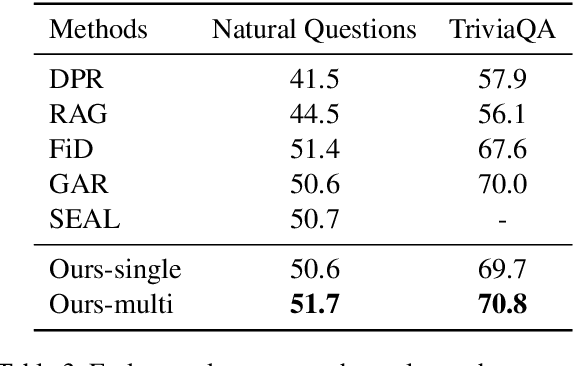
Query expansion is an effective approach for mitigating vocabulary mismatch between queries and documents in information retrieval. One recent line of research uses language models to generate query-related contexts for expansion. Along this line, we argue that expansion terms from these contexts should balance two key aspects: diversity and relevance. The obvious way to increase diversity is to sample multiple contexts from the language model. However, this comes at the cost of relevance, because there is a well-known tendency of models to hallucinate incorrect or irrelevant contexts. To balance these two considerations, we propose a combination of an effective filtering strategy and fusion of the retrieved documents based on the generation probability of each context. Our lexical matching based approach achieves a similar top-5/top-20 retrieval accuracy and higher top-100 accuracy compared with the well-established dense retrieval model DPR, while reducing the index size by more than 96%. For end-to-end QA, the reader model also benefits from our method and achieves the highest Exact-Match score against several competitive baselines.
What the DAAM: Interpreting Stable Diffusion Using Cross Attention
Oct 11, 2022
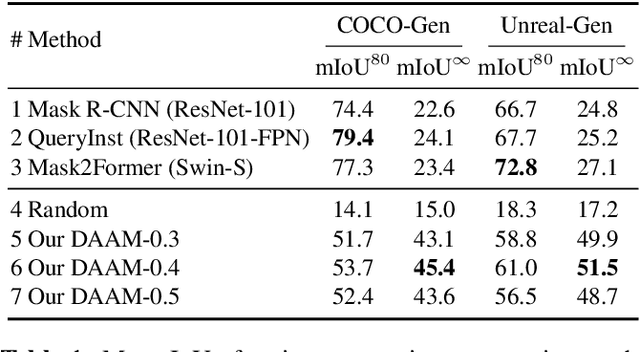
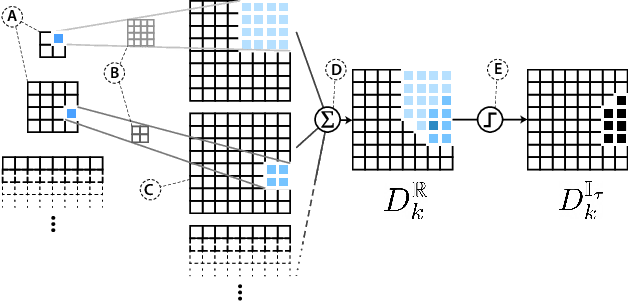

Large-scale diffusion neural networks represent a substantial milestone in text-to-image generation, with some performing similar to real photographs in human evaluation. However, they remain poorly understood, lacking explainability and interpretability analyses, largely due to their proprietary, closed-source nature. In this paper, to shine some much-needed light on text-to-image diffusion models, we perform a text-image attribution analysis on Stable Diffusion, a recently open-sourced large diffusion model. To produce pixel-level attribution maps, we propose DAAM, a novel method based on upscaling and aggregating cross-attention activations in the latent denoising subnetwork. We support its correctness by evaluating its unsupervised semantic segmentation quality on its own generated imagery, compared to supervised segmentation models. We show that DAAM performs strongly on COCO caption-generated images, achieving an mIoU of 61.0, and it outperforms supervised models on open-vocabulary segmentation, for an mIoU of 51.5. We further find that certain parts of speech, like punctuation and conjunctions, influence the generated imagery most, which agrees with the prior literature, while determiners and numerals the least, suggesting poor numeracy. To our knowledge, we are the first to propose and study word-pixel attribution for large-scale text-to-image diffusion models. Our code and data are at https://github.com/castorini/daam.
Better Than Whitespace: Information Retrieval for Languages without Custom Tokenizers
Oct 11, 2022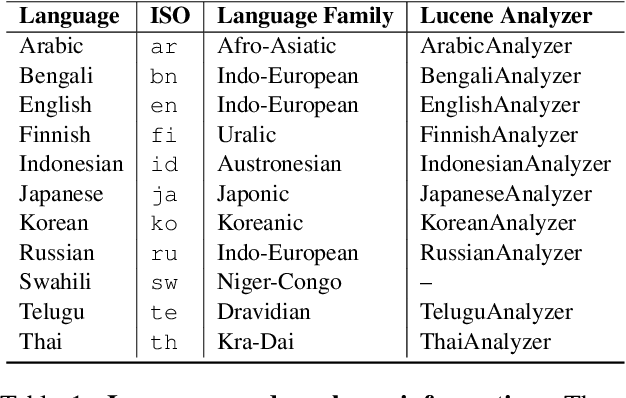
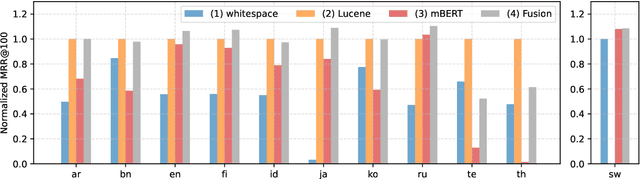
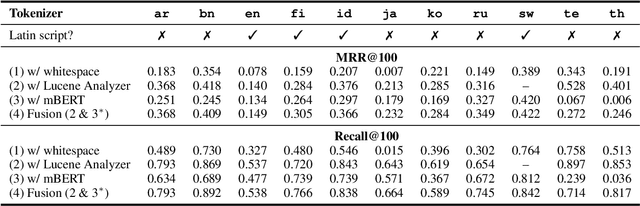
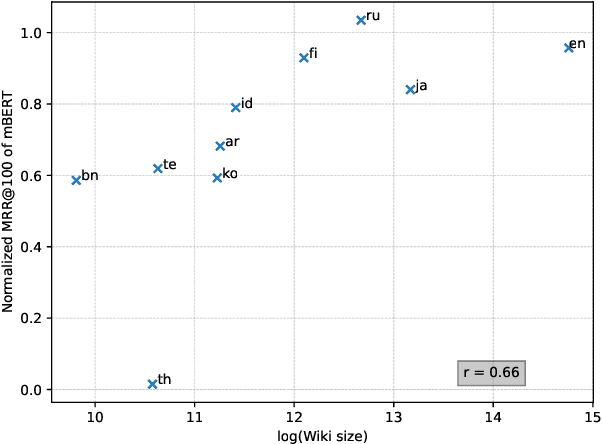
Tokenization is a crucial step in information retrieval, especially for lexical matching algorithms, where the quality of indexable tokens directly impacts the effectiveness of a retrieval system. Since different languages have unique properties, the design of the tokenization algorithm is usually language-specific and requires at least some lingustic knowledge. However, only a handful of the 7000+ languages on the planet benefit from specialized, custom-built tokenization algorithms, while the other languages are stuck with a "default" whitespace tokenizer, which cannot capture the intricacies of different languages. To address this challenge, we propose a different approach to tokenization for lexical matching retrieval algorithms (e.g., BM25): using the WordPiece tokenizer, which can be built automatically from unsupervised data. We test the approach on 11 typologically diverse languages in the MrTyDi collection: results show that the mBERT tokenizer provides strong relevance signals for retrieval "out of the box", outperforming whitespace tokenization on most languages. In many cases, our approach also improves retrieval effectiveness when combined with existing custom-built tokenizers.
Aggretriever: A Simple Approach to Aggregate Textual Representation for Robust Dense Passage Retrieval
Jul 31, 2022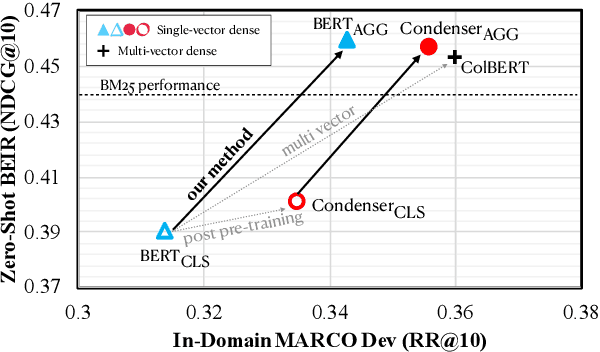
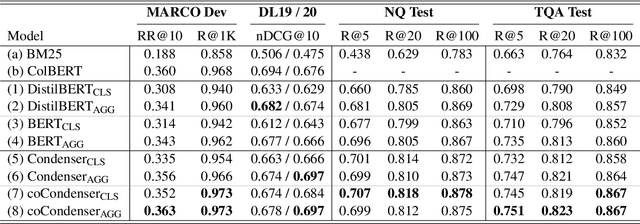
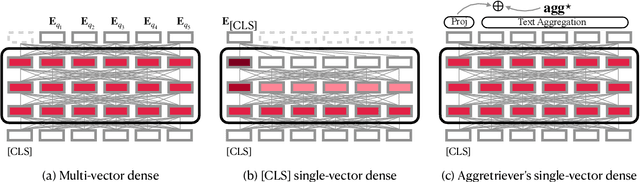
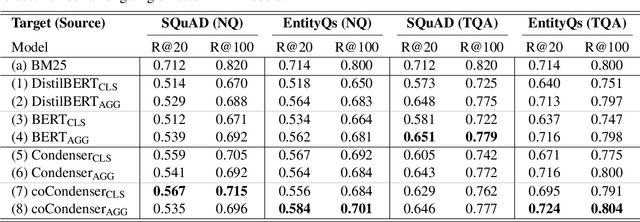
Pre-trained transformers has declared its success in many NLP tasks. One thread of work focuses on training bi-encoder models (i.e., dense retrievers) to effectively encode sentences or passages into single-vector dense vectors for efficient approximate nearest neighbor (ANN) search. However, recent work has demonstrated that transformers pre-trained with mask language modeling (MLM) are not capable of effectively aggregating text information into a single dense vector due to task-mismatch between pre-training and fine-tuning. Therefore, computationally expensive techniques have been adopted to train dense retrievers, such as large batch size, knowledge distillation or post pre-training. In this work, we present a simple approach to effectively aggregate textual representation from the pre-trained transformer into a dense vector. Extensive experiments show that our approach improves the robustness of the single-vector approach under both in-domain and zero-shot evaluations without any computationally expensive training techniques. Our work demonstrates that MLM pre-trained transformers can be used to effectively encode text information into a single-vector for dense retrieval. Code are available at: https://github.com/castorini/dhr
Building an Efficiency Pipeline: Commutativity and Cumulativeness of Efficiency Operators for Transformers
Jul 31, 2022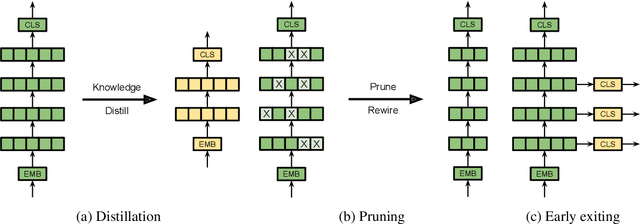
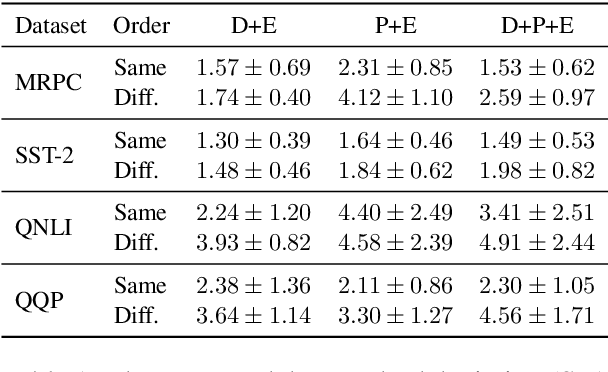
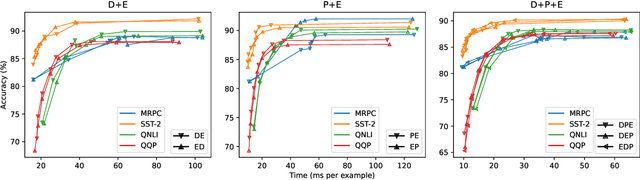
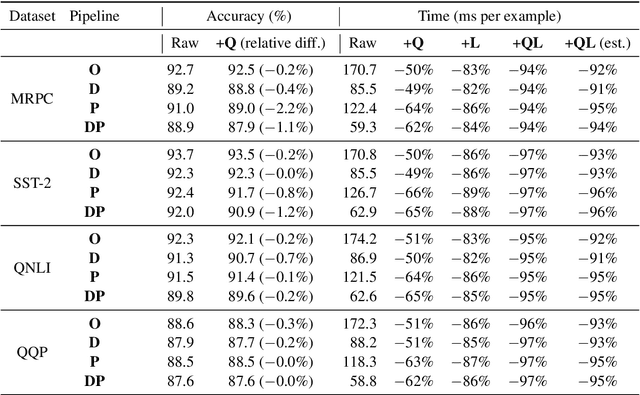
There exists a wide variety of efficiency methods for natural language processing (NLP) tasks, such as pruning, distillation, dynamic inference, quantization, etc. We can consider an efficiency method as an operator applied on a model. Naturally, we may construct a pipeline of multiple efficiency methods, i.e., to apply multiple operators on the model sequentially. In this paper, we study the plausibility of this idea, and more importantly, the commutativity and cumulativeness of efficiency operators. We make two interesting observations: (1) Efficiency operators are commutative -- the order of efficiency methods within the pipeline has little impact on the final results; (2) Efficiency operators are also cumulative -- the final results of combining several efficiency methods can be estimated by combining the results of individual methods. These observations deepen our understanding of efficiency operators and provide useful guidelines for their real-world applications.