 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponse-Aware User Memory Selection for LLM Personalization
Apr 15, 2026A common approach to personalization in large language models (LLMs) is to incorporate a subset of the user memory into the prompt at inference time to guide the model's generation. Existing methods select these subsets primarily using similarity between user memory items and input queries, ignoring how features actually affect the model's response distribution. We propose Response-Utility optimization for Memory Selection (RUMS), a novel method that selects user memory items by measuring the mutual information between a subset of memory and the model's outputs, identifying items that reduce response uncertainty and sharpen predictions beyond semantic similarity. We demonstrate that this information-theoretic foundation enables more principled user memory selection that aligns more closely with human selection compared to state-of-the-art methods, and models $400\times$ larger. Additionally, we show that memory items selected using RUMS result in better response quality compared to existing approaches, while having up to $95\%$ reduction in computational cost.
FDARxBench: Benchmarking Regulatory and Clinical Reasoning on FDA Generic Drug Assessment
Mar 20, 2026We introduce an expert curated, real-world benchmark for evaluating document-grounded question-answering (QA) motivated by generic drug assessment, using the U.S. Food and Drug Administration (FDA) drug label documents. Drug labels contain rich but heterogeneous clinical and regulatory information, making accurate question answering difficult for current language models. In collaboration with FDA regulatory assessors, we introduce FDARxBench, and construct a multi-stage pipeline for generating high-quality, expert curated, QA examples spanning factual, multi-hop, and refusal tasks, and design evaluation protocols to assess both open-book and closed-book reasoning. Experiments across proprietary and open-weight models reveal substantial gaps in factual grounding, long-context retrieval, and safe refusal behavior. While motivated by FDA generic drug assessment needs, this benchmark also provides a substantial foundation for challenging regulatory-grade evaluation of label comprehension. The benchmark is designed to support evaluation of LLM behavior on drug-label questions.
Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
Mar 15, 2025



High-quality training data has proven crucial for developing performant large language models (LLMs). However, commercial LLM providers disclose few, if any, details about the data used for training. This lack of transparency creates multiple challenges: it limits external oversight and inspection of LLMs for issues such as copyright infringement, it undermines the agency of data authors, and it hinders scientific research on critical issues such as data contamination and data selection. How can we recover what training data is known to LLMs? In this work, we demonstrate a new method to identify training data known to proprietary LLMs like GPT-4 without requiring any access to model weights or token probabilities, by using information-guided probes. Our work builds on a key observation: text passages with high surprisal are good search material for memorization probes. By evaluating a model's ability to successfully reconstruct high-surprisal tokens in text, we can identify a surprising number of texts memorized by LLMs.
Biased AI can Influence Political Decision-Making
Oct 08, 2024



As modern AI models become integral to everyday tasks, concerns about their inherent biases and their potential impact on human decision-making have emerged. While bias in models are well-documented, less is known about how these biases influence human decisions. This paper presents two interactive experiments investigating the effects of partisan bias in AI language models on political decision-making. Participants interacted freely with either a biased liberal, conservative, or unbiased control model while completing political decision-making tasks. We found that participants exposed to politically biased models were significantly more likely to adopt opinions and make decisions aligning with the AI's bias, regardless of their personal political partisanship. However, we also discovered that prior knowledge about AI could lessen the impact of the bias, highlighting the possible importance of AI education for robust bias mitigation. Our findings not only highlight the critical effects of interacting with biased AI and its ability to impact public discourse and political conduct, but also highlights potential techniques for mitigating these risks in the future.
StyleRemix: Interpretable Authorship Obfuscation via Distillation and Perturbation of Style Elements
Aug 28, 2024



Authorship obfuscation, rewriting a text to intentionally obscure the identity of the author, is an important but challenging task. Current methods using large language models (LLMs) lack interpretability and controllability, often ignoring author-specific stylistic features, resulting in less robust performance overall. To address this, we develop StyleRemix, an adaptive and interpretable obfuscation method that perturbs specific, fine-grained style elements of the original input text. StyleRemix uses pre-trained Low Rank Adaptation (LoRA) modules to rewrite an input specifically along various stylistic axes (e.g., formality and length) while maintaining low computational cost. StyleRemix outperforms state-of-the-art baselines and much larger LLMs in a variety of domains as assessed by both automatic and human evaluation. Additionally, we release AuthorMix, a large set of 30K high-quality, long-form texts from a diverse set of 14 authors and 4 domains, and DiSC, a parallel corpus of 1,500 texts spanning seven style axes in 16 unique directions
Modular Pluralism: Pluralistic Alignment via Multi-LLM Collaboration
Jun 22, 2024While existing alignment paradigms have been integral in developing large language models (LLMs), LLMs often learn an averaged human preference and struggle to model diverse preferences across cultures, demographics, and communities. We propose Modular Pluralism, a modular framework based on multi-LLM collaboration for pluralistic alignment: it "plugs into" a base LLM a pool of smaller but specialized community LMs, where models collaborate in distinct modes to flexibility support three modes of pluralism: Overton, steerable, and distributional. Modular Pluralism is uniquely compatible with black-box LLMs and offers the modular control of adding new community LMs for previously underrepresented communities. We evaluate Modular Pluralism with six tasks and four datasets featuring questions/instructions with value-laden and perspective-informed responses. Extensive experiments demonstrate that Modular Pluralism advances the three pluralism objectives across six black-box and open-source LLMs. Further analysis reveals that LLMs are generally faithful to the inputs from smaller community LLMs, allowing seamless patching by adding a new community LM to better cover previously underrepresented communities.
JAMDEC: Unsupervised Authorship Obfuscation using Constrained Decoding over Small Language Models
Feb 13, 2024



The permanence of online content combined with the enhanced authorship identification techniques calls for stronger computational methods to protect the identity and privacy of online authorship when needed, e.g., blind reviews for scientific papers, anonymous online reviews, or anonymous interactions in the mental health forums. In this paper, we propose an unsupervised inference-time approach to authorship obfuscation to address the unique challenges of authorship obfuscation: lack of supervision data for diverse authorship and domains, and the need for a sufficient level of revision beyond simple paraphrasing to obfuscate the authorship, all the while preserving the original content and fluency. We introduce JAMDEC, a user-controlled, inference-time algorithm for authorship obfuscation that can be in principle applied to any text and authorship. Our approach builds on small language models such as GPT2-XL in order to help avoid disclosing the original content to proprietary LLM's APIs, while also reducing the performance gap between small and large language models via algorithmic enhancement. The key idea behind our approach is to boost the creative power of smaller language models through constrained decoding, while also allowing for user-specified controls and flexibility. Experimental results demonstrate that our approach based on GPT2-XL outperforms previous state-of-the-art methods based on comparably small models, while performing competitively against GPT3.5 175B, a propriety model that is two orders of magnitudes larger.
A Roadmap to Pluralistic Alignment
Feb 07, 2024With increased power and prevalence of AI systems, it is ever more critical that AI systems are designed to serve all, i.e., people with diverse values and perspectives. However, aligning models to serve pluralistic human values remains an open research question. In this piece, we propose a roadmap to pluralistic alignment, specifically using language models as a test bed. We identify and formalize three possible ways to define and operationalize pluralism in AI systems: 1) Overton pluralistic models that present a spectrum of reasonable responses; 2) Steerably pluralistic models that can steer to reflect certain perspectives; and 3) Distributionally pluralistic models that are well-calibrated to a given population in distribution. We also propose and formalize three possible classes of pluralistic benchmarks: 1) Multi-objective benchmarks, 2) Trade-off steerable benchmarks, which incentivize models to steer to arbitrary trade-offs, and 3) Jury-pluralistic benchmarks which explicitly model diverse human ratings. We use this framework to argue that current alignment techniques may be fundamentally limited for pluralistic AI; indeed, we highlight empirical evidence, both from our own experiments and from other work, that standard alignment procedures might reduce distributional pluralism in models, motivating the need for further research on pluralistic alignment.
The Generative AI Paradox: "What It Can Create, It May Not Understand"
Oct 31, 2023
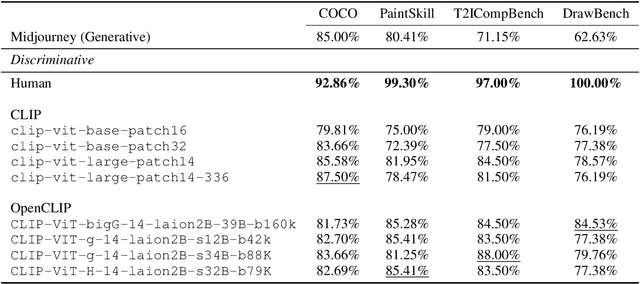
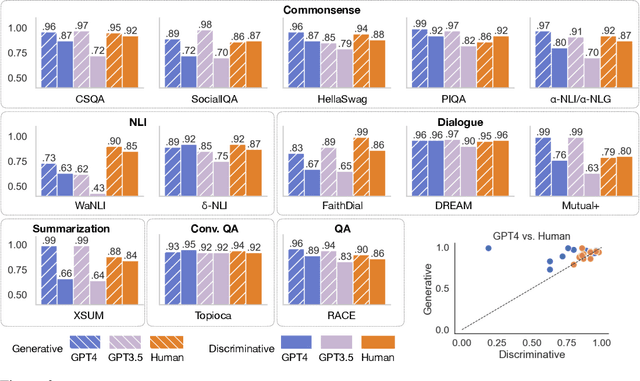
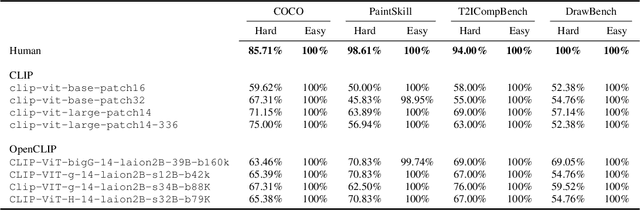
The recent wave of generative AI has sparked unprecedented global attention, with both excitement and concern over potentially superhuman levels of artificial intelligence: models now take only seconds to produce outputs that would challenge or exceed the capabilities even of expert humans. At the same time, models still show basic errors in understanding that would not be expected even in non-expert humans. This presents us with an apparent paradox: how do we reconcile seemingly superhuman capabilities with the persistence of errors that few humans would make? In this work, we posit that this tension reflects a divergence in the configuration of intelligence in today's generative models relative to intelligence in humans. Specifically, we propose and test the Generative AI Paradox hypothesis: generative models, having been trained directly to reproduce expert-like outputs, acquire generative capabilities that are not contingent upon -- and can therefore exceed -- their ability to understand those same types of outputs. This contrasts with humans, for whom basic understanding almost always precedes the ability to generate expert-level outputs. We test this hypothesis through controlled experiments analyzing generation vs. understanding in generative models, across both language and image modalities. Our results show that although models can outperform humans in generation, they consistently fall short of human capabilities in measures of understanding, as well as weaker correlation between generation and understanding performance, and more brittleness to adversarial inputs. Our findings support the hypothesis that models' generative capability may not be contingent upon understanding capability, and call for caution in interpreting artificial intelligence by analogy to human intelligence.
Impossible Distillation: from Low-Quality Model to High-Quality Dataset & Model for Summarization and Paraphrasing
May 26, 2023



It is commonly perceived that the strongest language models (LMs) rely on a combination of massive scale, instruction data, and human feedback to perform specialized tasks -- e.g. summarization and paraphrasing, without supervision. In this paper, we propose that language models can learn to summarize and paraphrase sentences, with none of these 3 factors. We present Impossible Distillation, a framework that distills a task-specific dataset directly from an off-the-shelf LM, even when it is impossible for the LM itself to reliably solve the task. By training a student model on the generated dataset and amplifying its capability through self-distillation, our method yields a high-quality model and dataset from a low-quality teacher model, without the need for scale or supervision. Using Impossible Distillation, we are able to distill an order of magnitude smaller model (with only 770M parameters) that outperforms 175B parameter GPT-3, in both quality and controllability, as confirmed by automatic and human evaluations. Furthermore, as a useful byproduct of our approach, we obtain DIMSUM+, a high-quality dataset with 3.4M sentence summaries and paraphrases. Our analyses show that this dataset, as a purely LM-generated corpus, is more diverse and more effective for generalization to unseen domains than all human-authored datasets -- including Gigaword with 4M samples.