 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM100: An Orchestrated Dataflow Architecture Powering General AI Computing
Apr 20, 2026As deep learning-based AI technologies gain momentum, the demand for general-purpose AI computing architectures continues to grow. While GPGPU-based architectures offer versatility for diverse AI workloads, they often fall short in efficiency and cost-effectiveness. Various Domain-Specific Architectures (DSAs) excel at particular AI tasks but struggle to extend across broader applications or adapt to the rapidly evolving AI landscape. M100 is Li Auto's response: a performant, cost-effective architecture for AI inference in Autonomous Driving (AD), Large Language Models (LLMs), and intelligent human interactions, domains crucial to today's most competitive automobile platforms. M100 employs a dataflow parallel architecture, where compiler-architecture co-design orchestrates not only computation but, more critically, data movement across time and space. Leveraging dataflow computing efficiency, our hardware-software co-design improves system performance while reducing hardware complexity and cost. M100 largely eliminates caching: tensor computations are driven by compiler- and runtime-managed data streams flowing between computing elements and on/off-chip memories, yielding greater efficiency and scalability than cache-based systems. Another key principle was selecting the right operational granularity for scheduling, issuing, and execution across compiler, firmware, and hardware. Recognizing commonalities in AI workloads, we chose the tensor as the fundamental data element. M100 demonstrates general AI computing capability across diverse inference applications, including UniAD (for AD) and LLaMA (for LLMs). Benchmarks show M100 outperforms GPGPU architectures in AD applications with higher utilization, representing a promising direction for future general AI computing.
Movable Cell-Free Massive MIMO For High-Speed Train Communications: A PPO-Based Antenna Position Optimization
Mar 16, 2025



In recent years, high-speed trains (HSTs) communications have developed rapidly to enhance the stability of train operations and improve passenger connectivity experiences. However, as the train continues to accelerate, urgent technological innovations are needed to overcome challenges such as frequency handover and significant Doppler effects. In this paper, we present a novel architecture featuring movable antennas (MAs) to fully exploit macro spatial diversity, enabling a cell-free (CF) massive multiple-input multiple-output (MIMO) system that supports high-speed train communications. Considering the high likelihood of line-of-sight (LoS) transmission in HST scenario, we derive the uplink spectral efficiency (SE) expression for the movable CF massive MIMO system. Moreover, an optimization problem is formulated to maximize the sum SE of the considered system by optimizing the positions of the antennas. Since the formulated problem is non-convex and highly non-linear, we improve a deep reinforcement learning algorithm to address it by using proximal policy optimization (PPO). Different from traditional optimization approaches, which optimize variables separately and alternately, our improved PPO-based approach optimizes all the variables in unison. Simulation results demonstrate that movable CF massive MIMO effectively suppresses the negative impact of the Doppler effect in HST communications.
Application of Multi-channel 3D-cube Successive Convolution Network for Convective Storm Nowcasting
Mar 02, 2017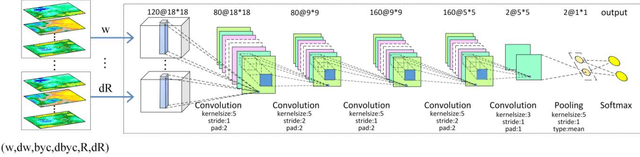
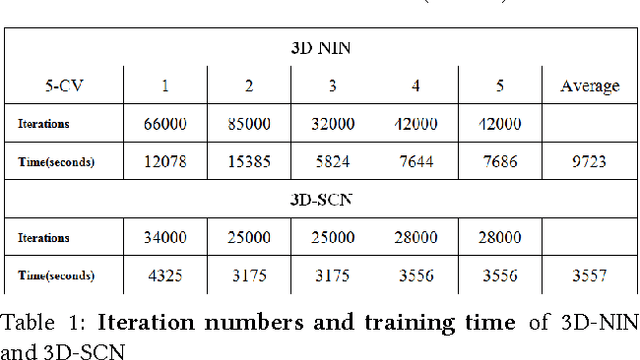
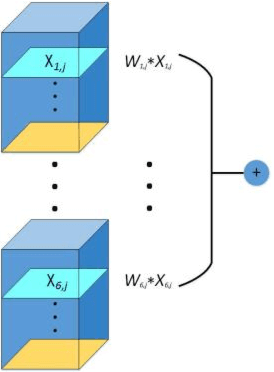
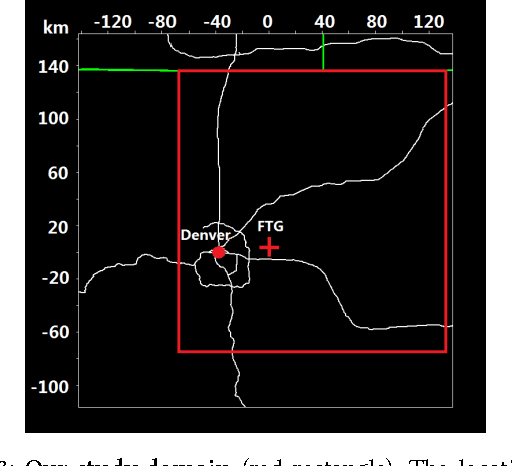
Convective storm nowcasting has attracted substantial attention in various fields. Existing methods under a deep learning framework rely primarily on radar data. Although they perform nowcast storm advection well, it is still challenging to nowcast storm initiation and growth, due to the limitations of the radar observations. This paper describes the first attempt to nowcast storm initiation, growth, and advection simultaneously under a deep learning framework using multi-source meteorological data. To this end, we present a multi-channel 3D-cube successive convolution network (3D-SCN). As real-time re-analysis meteorological data can now provide valuable atmospheric boundary layer thermal dynamic information, which is essential to predict storm initiation and growth, both raw 3D radar and re-analysis data are used directly without any handcraft feature engineering. These data are formulated as multi-channel 3D cubes, to be fed into our network, which are convolved by cross-channel 3D convolutions. By stacking successive convolutional layers without pooling, we build an end-to-end trainable model for nowcasting. Experimental results show that deep learning methods achieve better performance than traditional extrapolation methods. The qualitative analyses of 3D-SCN show encouraging results of nowcasting of storm initiation, growth, and advection.