 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Deformable Radiance Fields for Disentangled Image Synthesis of Topology-Varying Objects
Sep 09, 2022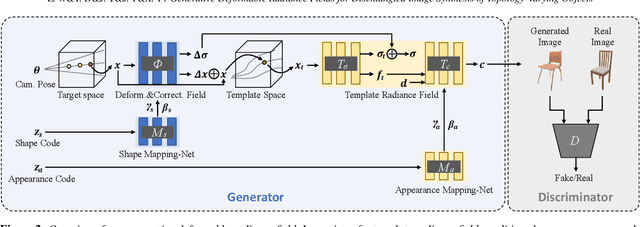
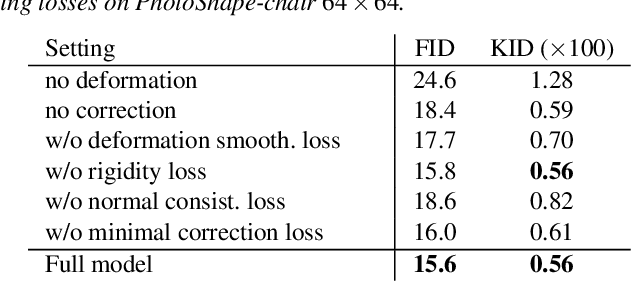
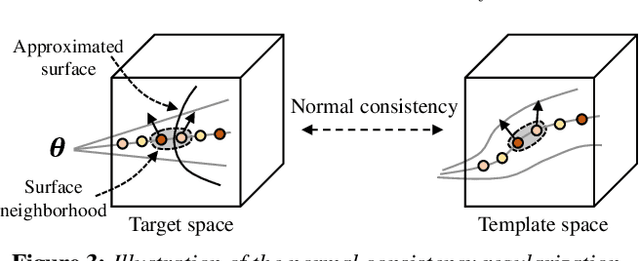
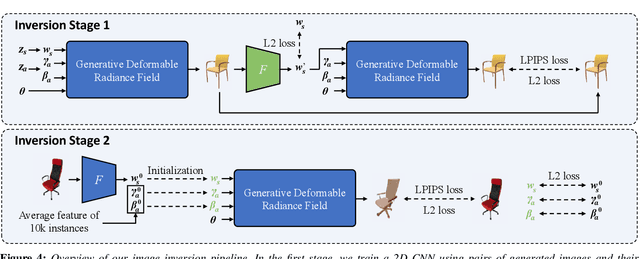
3D-aware generative models have demonstrated their superb performance to generate 3D neural radiance fields (NeRF) from a collection of monocular 2D images even for topology-varying object categories. However, these methods still lack the capability to separately control the shape and appearance of the objects in the generated radiance fields. In this paper, we propose a generative model for synthesizing radiance fields of topology-varying objects with disentangled shape and appearance variations. Our method generates deformable radiance fields, which builds the dense correspondence between the density fields of the objects and encodes their appearances in a shared template field. Our disentanglement is achieved in an unsupervised manner without introducing extra labels to previous 3D-aware GAN training. We also develop an effective image inversion scheme for reconstructing the radiance field of an object in a real monocular image and manipulating its shape and appearance. Experiments show that our method can successfully learn the generative model from unstructured monocular images and well disentangle the shape and appearance for objects (e.g., chairs) with large topological variance. The model trained on synthetic data can faithfully reconstruct the real object in a given single image and achieve high-quality texture and shape editing results.
Deep Deformable 3D Caricatures with Learned Shape Control
Jul 29, 2022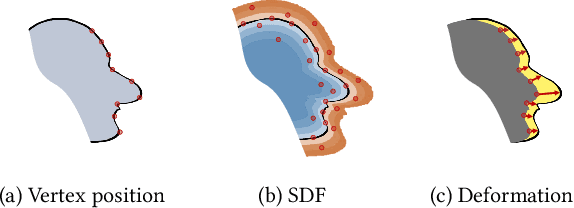
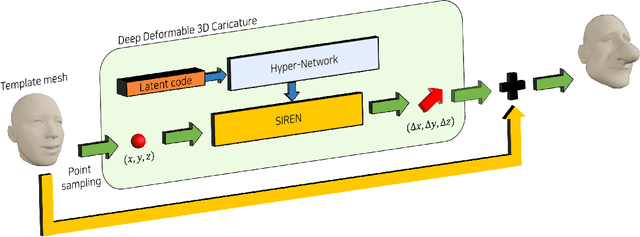


A 3D caricature is an exaggerated 3D depiction of a human face. The goal of this paper is to model the variations of 3D caricatures in a compact parameter space so that we can provide a useful data-driven toolkit for handling 3D caricature deformations. To achieve the goal, we propose an MLP-based framework for building a deformable surface model, which takes a latent code and produces a 3D surface. In the framework, a SIREN MLP models a function that takes a 3D position on a fixed template surface and returns a 3D displacement vector for the input position. We create variations of 3D surfaces by learning a hypernetwork that takes a latent code and produces the parameters of the MLP. Once learned, our deformable model provides a nice editing space for 3D caricatures, supporting label-based semantic editing and point-handle-based deformation, both of which produce highly exaggerated and natural 3D caricature shapes. We also demonstrate other applications of our deformable model, such as automatic 3D caricature creation.
GRAM-HD: 3D-Consistent Image Generation at High Resolution with Generative Radiance Manifolds
Jun 15, 2022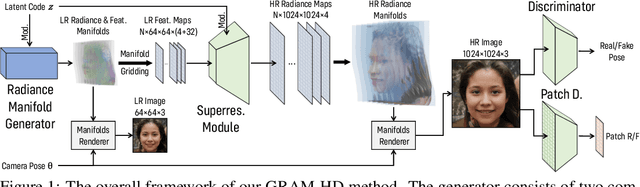



Recent works have shown that 3D-aware GANs trained on unstructured single image collections can generate multiview images of novel instances. The key underpinnings to achieve this are a 3D radiance field generator and a volume rendering process. However, existing methods either cannot generate high-resolution images (e.g., up to 256X256) due to the high computation cost of neural volume rendering, or rely on 2D CNNs for image-space upsampling which jeopardizes the 3D consistency across different views. This paper proposes a novel 3D-aware GAN that can generate high resolution images (up to 1024X1024) while keeping strict 3D consistency as in volume rendering. Our motivation is to achieve super-resolution directly in the 3D space to preserve 3D consistency. We avoid the otherwise prohibitively-expensive computation cost by applying 2D convolutions on a set of 2D radiance manifolds defined in the recent generative radiance manifold (GRAM) approach, and apply dedicated loss functions for effective GAN training at high resolution. Experiments on FFHQ and AFHQv2 datasets show that our method can produce high-quality 3D-consistent results that significantly outperform existing methods.
Single-View View Synthesis in the Wild with Learned Adaptive Multiplane Images
May 24, 2022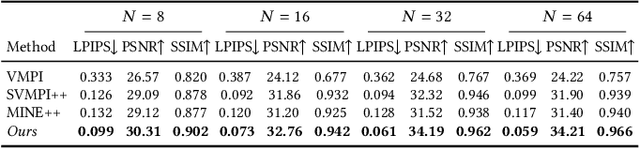
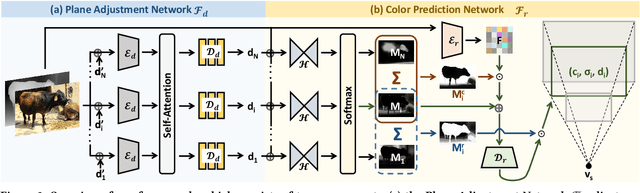
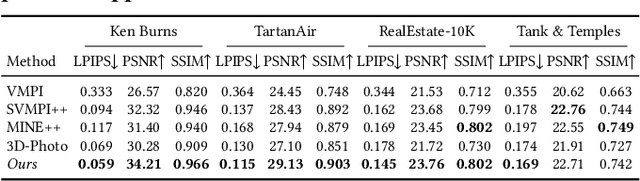
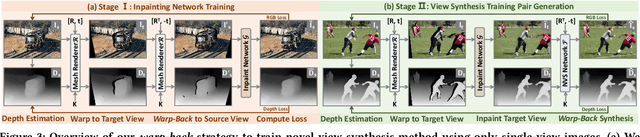
This paper deals with the challenging task of synthesizing novel views for in-the-wild photographs. Existing methods have shown promising results leveraging monocular depth estimation and color inpainting with layered depth representations. However, these methods still have limited capability to handle scenes with complex 3D geometry. We propose a new method based on the multiplane image (MPI) representation. To accommodate diverse scene layouts in the wild and tackle the difficulty in producing high-dimensional MPI contents, we design a network structure that consists of two novel modules, one for plane depth adjustment and another for depth-aware color prediction. The former adjusts the initial plane positions using the RGBD context feature and an attention mechanism. Given adjusted depth values, the latter predicts the color and density for each plane separately with proper inter-plane interactions achieved via a feature masking strategy. To train our method, we construct large-scale stereo training data using only unconstrained single-view image collections by a simple yet effective warp-back strategy. The experiments on both synthetic and real datasets demonstrate that our trained model works remarkably well and achieves state-of-the-art results.
Real-Time Neural Character Rendering with Pose-Guided Multiplane Images
Apr 25, 2022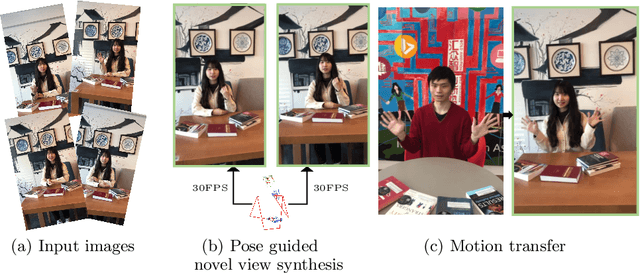
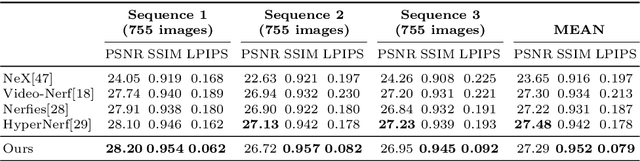
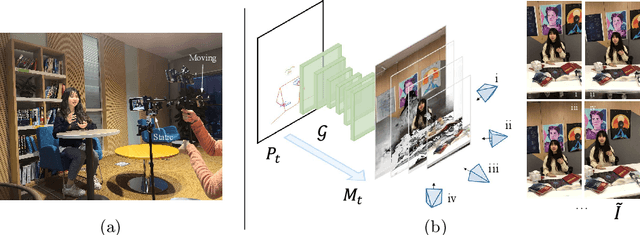
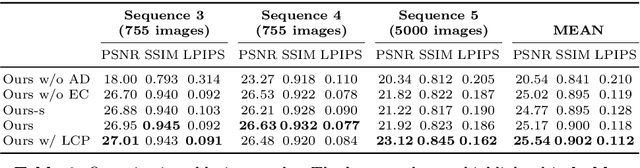
We propose pose-guided multiplane image (MPI) synthesis which can render an animatable character in real scenes with photorealistic quality. We use a portable camera rig to capture the multi-view images along with the driving signal for the moving subject. Our method generalizes the image-to-image translation paradigm, which translates the human pose to a 3D scene representation -- MPIs that can be rendered in free viewpoints, using the multi-views captures as supervision. To fully cultivate the potential of MPI, we propose depth-adaptive MPI which can be learned using variable exposure images while being robust to inaccurate camera registration. Our method demonstrates advantageous novel-view synthesis quality over the state-of-the-art approaches for characters with challenging motions. Moreover, the proposed method is generalizable to novel combinations of training poses and can be explicitly controlled. Our method achieves such expressive and animatable character rendering all in real time, serving as a promising solution for practical applications.
MPS-NeRF: Generalizable 3D Human Rendering from Multiview Images
Mar 31, 2022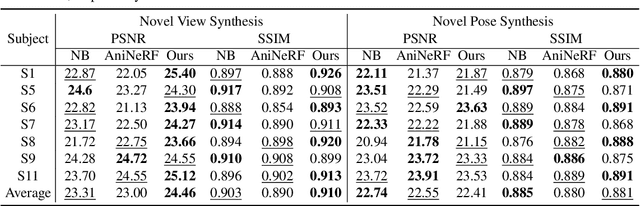
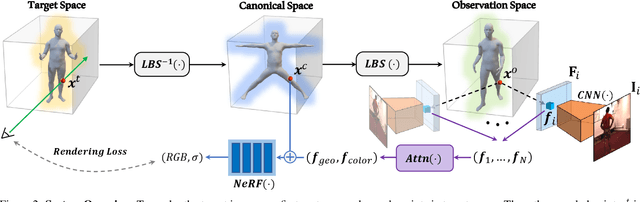
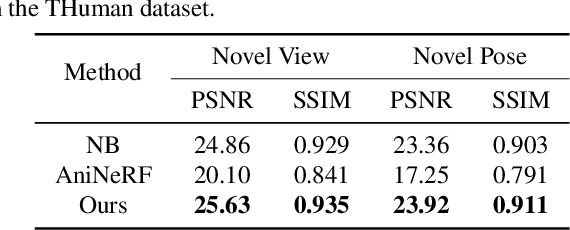

There has been rapid progress recently on 3D human rendering, including novel view synthesis and pose animation, based on the advances of neural radiance fields (NeRF). However, most existing methods focus on person-specific training and their training typically requires multi-view videos. This paper deals with a new challenging task -- rendering novel views and novel poses for a person unseen in training, using only multiview images as input. For this task, we propose a simple yet effective method to train a generalizable NeRF with multiview images as conditional input. The key ingredient is a dedicated representation combining a canonical NeRF and a volume deformation scheme. Using a canonical space enables our method to learn shared properties of human and easily generalize to different people. Volume deformation is used to connect the canonical space with input and target images and query image features for radiance and density prediction. We leverage the parametric 3D human model fitted on the input images to derive the deformation, which works quite well in practice when combined with our canonical NeRF. The experiments on both real and synthetic data with the novel view synthesis and pose animation tasks collectively demonstrate the efficacy of our method.
VirtualCube: An Immersive 3D Video Communication System
Dec 29, 2021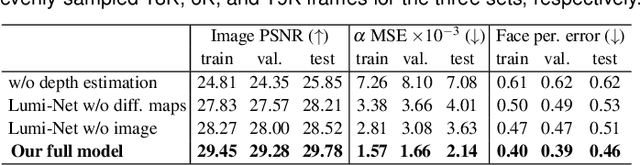
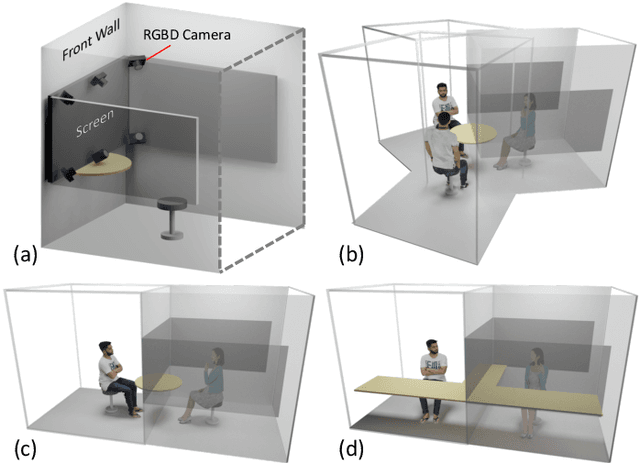

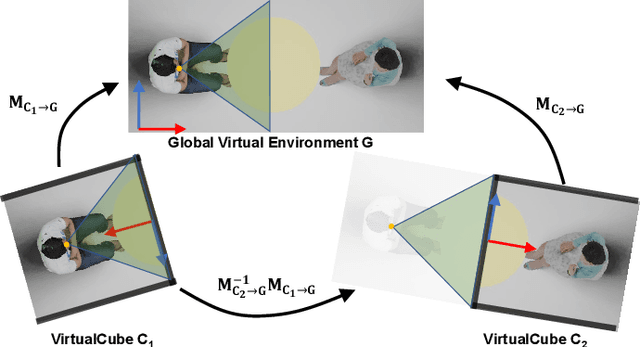
The VirtualCube system is a 3D video conference system that attempts to overcome some limitations of conventional technologies. The key ingredient is VirtualCube, an abstract representation of a real-world cubicle instrumented with RGBD cameras for capturing the 3D geometry and texture of a user. We design VirtualCube so that the task of data capturing is standardized and significantly simplified, and everything can be built using off-the-shelf hardware. We use VirtualCubes as the basic building blocks of a virtual conferencing environment, and we provide each VirtualCube user with a surrounding display showing life-size videos of remote participants. To achieve real-time rendering of remote participants, we develop the V-Cube View algorithm, which uses multi-view stereo for more accurate depth estimation and Lumi-Net rendering for better rendering quality. The VirtualCube system correctly preserves the mutual eye gaze between participants, allowing them to establish eye contact and be aware of who is visually paying attention to them. The system also allows a participant to have side discussions with remote participants as if they were in the same room. Finally, the system sheds lights on how to support the shared space of work items (e.g., documents and applications) and track the visual attention of participants to work items.
GRAM: Generative Radiance Manifolds for 3D-Aware Image Generation
Dec 17, 2021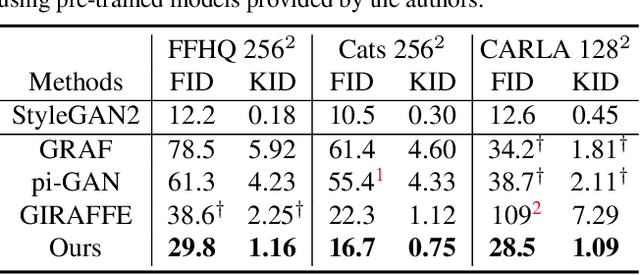


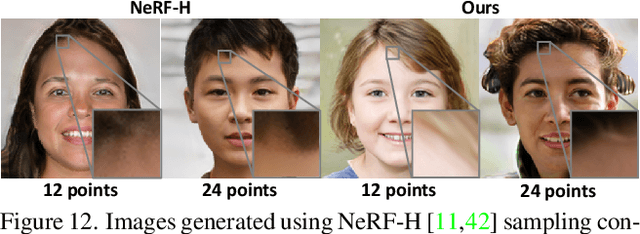
3D-aware image generative modeling aims to generate 3D-consistent images with explicitly controllable camera poses. Recent works have shown promising results by training neural radiance field (NeRF) generators on unstructured 2D images, but still can not generate highly-realistic images with fine details. A critical reason is that the high memory and computation cost of volumetric representation learning greatly restricts the number of point samples for radiance integration during training. Deficient sampling not only limits the expressive power of the generator to handle fine details but also impedes effective GAN training due to the noise caused by unstable Monte Carlo sampling. We propose a novel approach that regulates point sampling and radiance field learning on 2D manifolds, embodied as a set of learned implicit surfaces in the 3D volume. For each viewing ray, we calculate ray-surface intersections and accumulate their radiance generated by the network. By training and rendering such radiance manifolds, our generator can produce high quality images with realistic fine details and strong visual 3D consistency.
Physics-based Noise Modeling for Extreme Low-light Photography
Aug 04, 2021

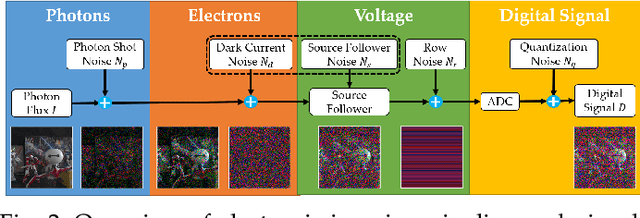
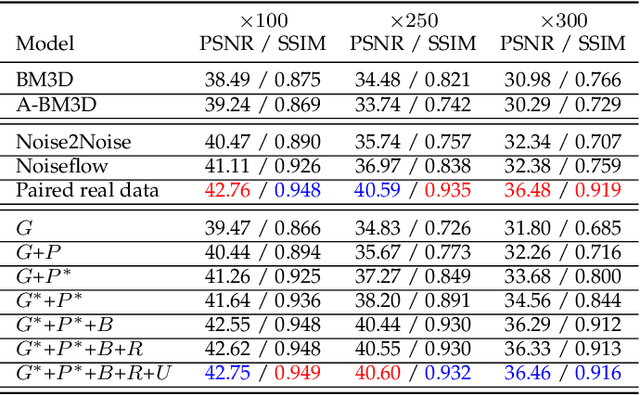
Enhancing the visibility in extreme low-light environments is a challenging task. Under nearly lightless condition, existing image denoising methods could easily break down due to significantly low SNR. In this paper, we systematically study the noise statistics in the imaging pipeline of CMOS photosensors, and formulate a comprehensive noise model that can accurately characterize the real noise structures. Our novel model considers the noise sources caused by digital camera electronics which are largely overlooked by existing methods yet have significant influence on raw measurement in the dark. It provides a way to decouple the intricate noise structure into different statistical distributions with physical interpretations. Moreover, our noise model can be used to synthesize realistic training data for learning-based low-light denoising algorithms. In this regard, although promising results have been shown recently with deep convolutional neural networks, the success heavily depends on abundant noisy clean image pairs for training, which are tremendously difficult to obtain in practice. Generalizing their trained models to images from new devices is also problematic. Extensive experiments on multiple low-light denoising datasets -- including a newly collected one in this work covering various devices -- show that a deep neural network trained with our proposed noise formation model can reach surprisingly-high accuracy. The results are on par with or sometimes even outperform training with paired real data, opening a new door to real-world extreme low-light photography.
StyleCariGAN: Caricature Generation via StyleGAN Feature Map Modulation
Jul 09, 2021
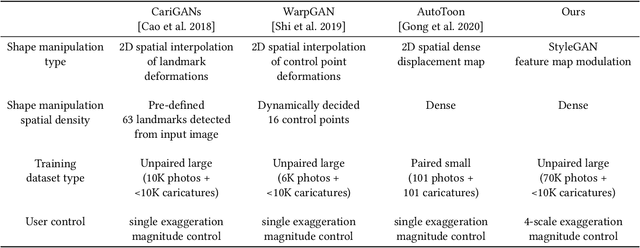


We present a caricature generation framework based on shape and style manipulation using StyleGAN. Our framework, dubbed StyleCariGAN, automatically creates a realistic and detailed caricature from an input photo with optional controls on shape exaggeration degree and color stylization type. The key component of our method is shape exaggeration blocks that are used for modulating coarse layer feature maps of StyleGAN to produce desirable caricature shape exaggerations. We first build a layer-mixed StyleGAN for photo-to-caricature style conversion by swapping fine layers of the StyleGAN for photos to the corresponding layers of the StyleGAN trained to generate caricatures. Given an input photo, the layer-mixed model produces detailed color stylization for a caricature but without shape exaggerations. We then append shape exaggeration blocks to the coarse layers of the layer-mixed model and train the blocks to create shape exaggerations while preserving the characteristic appearances of the input. Experimental results show that our StyleCariGAN generates realistic and detailed caricatures compared to the current state-of-the-art methods. We demonstrate StyleCariGAN also supports other StyleGAN-based image manipulations, such as facial expression control.
* Accepted to SIGGRAPH 2021. For supplementary material, see http://cg.postech.ac.kr/papers/2021_StyleCariGAN_supp.zip