 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Identification and Generation in the Limit
May 07, 2026In the classical identification in the limit model of Gold [1967], a stream of positive examples is presented round by round, and the learner must eventually recover the target hypothesis. Recently, Kleinberg and Mullainathan [2024] introduced generation in the limit, where the learner instead must eventually output novel elements of the target's support. Both lines of work focus on positive-only or fully labeled data. Yet many natural supervision signals are inherently relational rather than singleton, which encode relationships between examples rather than labels of individual ones. We initiate the study of contrastive identification and generation in the limit, where the learner observes a contrastive presentation of data: a stream of unordered pairs $\{x,y\}$ satisfying $h(x)\ne h(y)$ for an unknown target binary hypothesis $h$, but which element is positive is hidden from the learner. We first present three results in the noiseless setting: an exact characterization of contrastive identifiable classes (a one-line geometric refinement of Angluin [1980]'s tell-tale condition), a combinatorial dimension called contrastive closure dimension (a contrasitive analogue of the closure dimension in Raman et al. [2025]) and exactly characterizing uniform contrastive generation with tight sample complexity, and a strict hierarchy in which contrastive generation and text identification are mutually incomparable. We then prove a sharp reversal under finite adversarial corruption: there exist classes identifiable from contrastive pairs under any finite corruption budget by a single budget-independent algorithm, yet not identifiable from positive examples under even one corrupted observation. The unifying technical object is the common crossing graph, which encodes pairwise ambiguity, family-level generation obstructions, and corruption defects in a single coverage-and-incidence language.
LAVA: Layered Audio-Visual Anti-tampering Watermarking for Robust Deepfake Detection and Localization
Apr 27, 2026Proactive watermarking offers a promising approach for deepfake tamper detection and localization in short-form videos. However, existing methods often decouple audio and visual evidence and assume that watermark signals remain reliable under real-world degradations, making tamper localization vulnerable to multimodal misalignment and compression distortions. Moreover, existing semi-fragile visual watermarking methods often degrade significantly under codec compression because their embedding bands overlap with compression-sensitive frequency regions. To address these limitations, we propose Layered Audio-Visual Anti-tampering Watermarking (LAVA), a calibration-aware audio-visual watermark fusion framework for deepfake tamper detection and localization. LAVA leverages cross-modal watermark fusion and calibration-aware alignment to preserve consistent and reliable tamper evidence under compression and audio-visual asynchrony, enabling robust tamper localization. Extensive experiments demonstrate that LAVA achieves near-perfect detection performance (AP = 0.999), remains robust to compression and multimodal misalignment, and significantly improves tamper localization reliability over existing audio-visual fusion baselines.
On the Price of Privacy for Language Identification and Generation
Apr 08, 2026As large language models (LLMs) are increasingly trained on sensitive user data, understanding the fundamental cost of privacy in language learning becomes essential. We initiate the study of differentially private (DP) language identification and generation in the agnostic statistical setting, establishing algorithms and matching lower bounds that precisely quantify the cost of privacy. For both tasks, approximate $(\varepsilon, δ)$-DP with constant $\varepsilon > 0$ recovers the non-private error rates: $\exp(-r(n))$ for identification (for any $r(n) = o(n)$) and $\exp(-Ω(n))$ for generation. Under pure $\varepsilon$-DP, the exponents degrade by a multiplicative factor of $\min\{1, \varepsilon\}$, which we show is tight up to constants. Notably, for generation under pure DP with mild assumptions, the upper bound $\exp(-\min\{1,\varepsilon\} \cdot Ω(n))$ matches the lower bound up to some constants, establishing an optimal rate. Our results show that the cost of privacy in language learning is surprisingly mild: absent entirely under approximate DP, and exactly a $\min\{1,\varepsilon\}$ factor in the exponent under pure DP.
SHIFT: Stochastic Hidden-Trajectory Deflection for Removing Diffusion-based Watermark
Apr 01, 2026Diffusion-based watermarking methods embed verifiable marks by manipulating the initial noise or the reverse diffusion trajectory. However, these methods share a critical assumption: verification can succeed only if the diffusion trajectory can be faithfully reconstructed. This reliance on trajectory recovery constitutes a fundamental and exploitable vulnerability. We propose $\underline{\mathbf{S}}$tochastic $\underline{\mathbf{Hi}}$dden-Trajectory De$\underline{\mathbf{f}}$lec$\underline{\mathbf{t}}$ion ($\mathbf{SHIFT}$), a training-free attack that exploits this common weakness across diverse watermarking paradigms. SHIFT leverages stochastic diffusion resampling to deflect the generative trajectory in latent space, making the reconstructed image statistically decoupled from the original watermark-embedded trajectory while preserving strong visual quality and semantic consistency. Extensive experiments on nine representative watermarking methods spanning noise-space, frequency-domain, and optimization-based paradigms show that SHIFT achieves 95%--100% attack success rates with nearly no loss in semantic quality, without requiring any watermark-specific knowledge or model retraining.
SLICE: Semantic Latent Injection via Compartmentalized Embedding for Image Watermarking
Mar 13, 2026Watermarking the initial noise of diffusion models has emerged as a promising approach for image provenance, but content-independent noise patterns can be forged via inversion and regeneration attacks. Recent semantic-aware watermarking methods improve robustness by conditioning verification on image semantics. However, their reliance on a single global semantic binding makes them vulnerable to localized but globally coherent semantic edits. To address this limitation and provide a trustworthy semantic-aware watermark, we propose $\underline{\textbf{S}}$emantic $\underline{\textbf{L}}$atent $\underline{\textbf{I}}$njection via $\underline{\textbf{C}}$ompartmentalized $\underline{\textbf{E}}$mbedding ($\textbf{SLICE}$). Our framework decouples image semantics into four semantic factors (subject, environment, action, and detail) and precisely anchors them to distinct regions in the initial Gaussian noise. This fine-grained semantic binding enables advanced watermark verification where semantic tampering is detectable and localizable. We theoretically justify why SLICE enables robust and reliable tamper localization and provides statistical guarantees on false-accept rates. Experimental results demonstrate that SLICE significantly outperforms existing baselines against advanced semantic-guided regeneration attacks, substantially reducing attack success while preserving image quality and semantic fidelity. Overall, SLICE offers a practical, training-free provenance solution that is both fine-grained in diagnosis and robust to realistic adversarial manipulations.
Breaking Semantic-Aware Watermarks via LLM-Guided Coherence-Preserving Semantic Injection
Feb 25, 2026Generative images have proliferated on Web platforms in social media and online copyright distribution scenarios, and semantic watermarking has increasingly been integrated into diffusion models to support reliable provenance tracking and forgery prevention for web content. Traditional noise-layer-based watermarking, however, remains vulnerable to inversion attacks that can recover embedded signals. To mitigate this, recent content-aware semantic watermarking schemes bind watermark signals to high-level image semantics, constraining local edits that would otherwise disrupt global coherence. Yet, large language models (LLMs) possess structured reasoning capabilities that enable targeted exploration of semantic spaces, allowing locally fine-grained but globally coherent semantic alterations that invalidate such bindings. To expose this overlooked vulnerability, we introduce a Coherence-Preserving Semantic Injection (CSI) attack that leverages LLM-guided semantic manipulation under embedding-space similarity constraints. This alignment enforces visual-semantic consistency while selectively perturbing watermark-relevant semantics, ultimately inducing detector misclassification. Extensive empirical results show that CSI consistently outperforms prevailing attack baselines against content-aware semantic watermarking, revealing a fundamental security weakness of current semantic watermark designs when confronted with LLM-driven semantic perturbations.
LLMs for Law: Evaluating Legal-Specific LLMs on Contract Understanding
Aug 11, 2025Despite advances in legal NLP, no comprehensive evaluation covering multiple legal-specific LLMs currently exists for contract classification tasks in contract understanding. To address this gap, we present an evaluation of 10 legal-specific LLMs on three English language contract understanding tasks and compare them with 7 general-purpose LLMs. The results show that legal-specific LLMs consistently outperform general-purpose models, especially on tasks requiring nuanced legal understanding. Legal-BERT and Contracts-BERT establish new SOTAs on two of the three tasks, despite having 69% fewer parameters than the best-performing general-purpose LLM. We also identify CaseLaw-BERT and LexLM as strong additional baselines for contract understanding. Our results provide a holistic evaluation of legal-specific LLMs and will facilitate the development of more accurate contract understanding systems.
"Pull or Not to Pull?'': Investigating Moral Biases in Leading Large Language Models Across Ethical Dilemmas
Aug 10, 2025As large language models (LLMs) increasingly mediate ethically sensitive decisions, understanding their moral reasoning processes becomes imperative. This study presents a comprehensive empirical evaluation of 14 leading LLMs, both reasoning enabled and general purpose, across 27 diverse trolley problem scenarios, framed by ten moral philosophies, including utilitarianism, deontology, and altruism. Using a factorial prompting protocol, we elicited 3,780 binary decisions and natural language justifications, enabling analysis along axes of decisional assertiveness, explanation answer consistency, public moral alignment, and sensitivity to ethically irrelevant cues. Our findings reveal significant variability across ethical frames and model types: reasoning enhanced models demonstrate greater decisiveness and structured justifications, yet do not always align better with human consensus. Notably, "sweet zones" emerge in altruistic, fairness, and virtue ethics framings, where models achieve a balance of high intervention rates, low explanation conflict, and minimal divergence from aggregated human judgments. However, models diverge under frames emphasizing kinship, legality, or self interest, often producing ethically controversial outcomes. These patterns suggest that moral prompting is not only a behavioral modifier but also a diagnostic tool for uncovering latent alignment philosophies across providers. We advocate for moral reasoning to become a primary axis in LLM alignment, calling for standardized benchmarks that evaluate not just what LLMs decide, but how and why.
LayerPlexRank: Exploring Node Centrality and Layer Influence through Algebraic Connectivity in Multiplex Networks
May 09, 2024As the calculation of centrality in complex networks becomes increasingly vital across technological, biological, and social systems, precise and scalable ranking methods are essential for understanding these networks. This paper introduces LayerPlexRank, an algorithm that simultaneously assesses node centrality and layer influence in multiplex networks using algebraic connectivity metrics. This method enhances the robustness of the ranking algorithm by effectively assessing structural changes across layers using random walk, considering the overall connectivity of the graph. We substantiate the utility of LayerPlexRank with theoretical analyses and empirical validations on varied real-world datasets, contrasting it with established centrality measures.
Fake News Quick Detection on Dynamic Heterogeneous Information Networks
May 14, 2022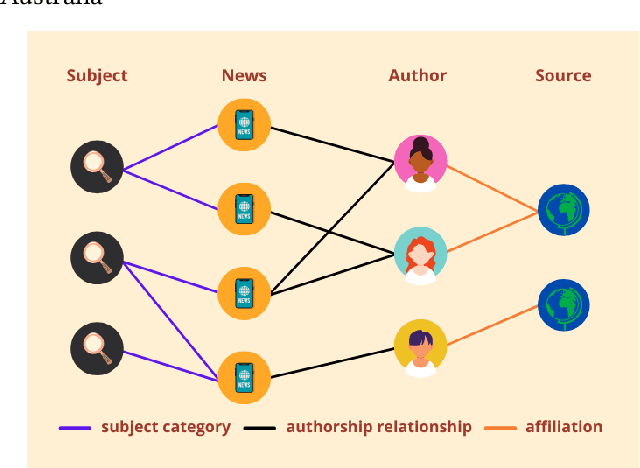
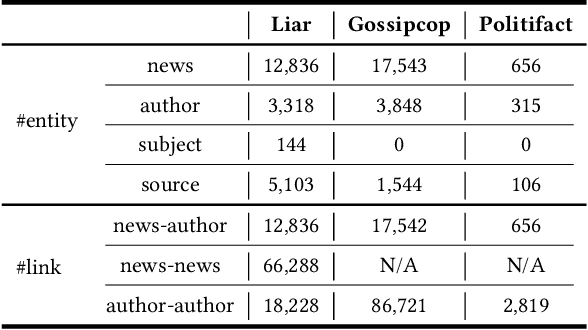
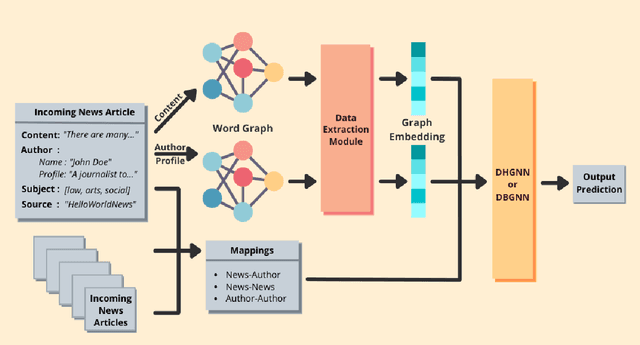

The spread of fake news has caused great harm to society in recent years. So the quick detection of fake news has become an important task. Some current detection methods often model news articles and other related components as a static heterogeneous information network (HIN) and use expensive message-passing algorithms. However, in the real-world, quickly identifying fake news is of great significance and the network may vary over time in terms of dynamic nodes and edges. Therefore, in this paper, we propose a novel Dynamic Heterogeneous Graph Neural Network (DHGNN) for fake news quick detection. More specifically, we first implement BERT and fine-tuned BERT to get a semantic representation of the news article contents and author profiles and convert it into graph data. Then, we construct the heterogeneous news-author graph to reflect contextual information and relationships. Additionally, we adapt ideas from personalized PageRank propagation and dynamic propagation to heterogeneous networks in order to reduce the time complexity of back-propagating through many nodes during training. Experiments on three real-world fake news datasets show that DHGNN can outperform other GNN-based models in terms of both effectiveness and efficiency.