 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment Invariant Linear Least Squares
Mar 06, 2023



This paper considers a multiple environments linear regression model in which data from multiple experimental settings are collected. The joint distribution of the response variable and covariate may vary across different environments, yet the conditional expectation of $y$ given the unknown set of important variables are invariant across environments. Such a statistical model is related to the problem of endogeneity, causal inference, and transfer learning. The motivation behind it is illustrated by how the goals of prediction and attribution are inherent in estimating the true parameter and the important variable set. We construct a novel {\it environment invariant linear least squares (EILLS)} objective function, a multiple-environment version of linear least squares that leverages the above conditional expectation invariance structure and heterogeneity among different environments to determine the true parameter. Our proposed method is applicable without any additional structural knowledge and can identify the true parameter under a near-minimal identification condition. We establish non-asymptotic $\ell_2$ error bounds on the estimation error for the EILLS estimator in the presence of spurious variables. Moreover, we further show that the EILLS estimator is able to eliminate all endogenous variables and the $\ell_0$ penalized EILLS estimator can achieve variable selection consistency in high-dimensional regimes. These non-asymptotic results demonstrate the sample efficiency of the EILLS estimator and its capability to circumvent the curse of endogeneity in an algorithmic manner without any prior structural knowledge.
On the Provable Advantage of Unsupervised Pretraining
Mar 02, 2023Unsupervised pretraining, which learns a useful representation using a large amount of unlabeled data to facilitate the learning of downstream tasks, is a critical component of modern large-scale machine learning systems. Despite its tremendous empirical success, the rigorous theoretical understanding of why unsupervised pretraining generally helps remains rather limited -- most existing results are restricted to particular methods or approaches for unsupervised pretraining with specialized structural assumptions. This paper studies a generic framework, where the unsupervised representation learning task is specified by an abstract class of latent variable models $\Phi$ and the downstream task is specified by a class of prediction functions $\Psi$. We consider a natural approach of using Maximum Likelihood Estimation (MLE) for unsupervised pretraining and Empirical Risk Minimization (ERM) for learning downstream tasks. We prove that, under a mild ''informative'' condition, our algorithm achieves an excess risk of $\tilde{\mathcal{O}}(\sqrt{\mathcal{C}_\Phi/m} + \sqrt{\mathcal{C}_\Psi/n})$ for downstream tasks, where $\mathcal{C}_\Phi, \mathcal{C}_\Psi$ are complexity measures of function classes $\Phi, \Psi$, and $m, n$ are the number of unlabeled and labeled data respectively. Comparing to the baseline of $\tilde{\mathcal{O}}(\sqrt{\mathcal{C}_{\Phi \circ \Psi}/n})$ achieved by performing supervised learning using only the labeled data, our result rigorously shows the benefit of unsupervised pretraining when $m \gg n$ and $\mathcal{C}_{\Phi\circ \Psi} > \mathcal{C}_\Psi$. This paper further shows that our generic framework covers a wide range of approaches for unsupervised pretraining, including factor models, Gaussian mixture models, and contrastive learning.
Communication-Efficient Distributed Estimation and Inference for Cox's Model
Feb 23, 2023



Motivated by multi-center biomedical studies that cannot share individual data due to privacy and ownership concerns, we develop communication-efficient iterative distributed algorithms for estimation and inference in the high-dimensional sparse Cox proportional hazards model. We demonstrate that our estimator, even with a relatively small number of iterations, achieves the same convergence rate as the ideal full-sample estimator under very mild conditions. To construct confidence intervals for linear combinations of high-dimensional hazard regression coefficients, we introduce a novel debiased method, establish central limit theorems, and provide consistent variance estimators that yield asymptotically valid distributed confidence intervals. In addition, we provide valid and powerful distributed hypothesis tests for any coordinate element based on a decorrelated score test. We allow time-dependent covariates as well as censored survival times. Extensive numerical experiments on both simulated and real data lend further support to our theory and demonstrate that our communication-efficient distributed estimators, confidence intervals, and hypothesis tests improve upon alternative methods.
Deep Neural Networks for Nonparametric Interaction Models with Diverging Dimension
Feb 12, 2023Deep neural networks have achieved tremendous success due to their representation power and adaptation to low-dimensional structures. Their potential for estimating structured regression functions has been recently established in the literature. However, most of the studies require the input dimension to be fixed and consequently ignore the effect of dimension on the rate of convergence and hamper their applications to modern big data with high dimensionality. In this paper, we bridge this gap by analyzing a $k^{th}$ order nonparametric interaction model in both growing dimension scenarios ($d$ grows with $n$ but at a slower rate) and in high dimension ($d \gtrsim n$). In the latter case, sparsity assumptions and associated regularization are required in order to obtain optimal rates of convergence. A new challenge in diverging dimension setting is in calculation mean-square error, the covariance terms among estimated additive components are an order of magnitude larger than those of the variances and they can deteriorate statistical properties without proper care. We introduce a critical debiasing technique to amend the problem. We show that under certain standard assumptions, debiased deep neural networks achieve a minimax optimal rate both in terms of $(n, d)$. Our proof techniques rely crucially on a novel debiasing technique that makes the covariances of additive components negligible in the mean-square error calculation. In addition, we establish the matching lower bounds.
Uncertainty Quantification of MLE for Entity Ranking with Covariates
Dec 20, 2022This paper concerns with statistical estimation and inference for the ranking problems based on pairwise comparisons with additional covariate information such as the attributes of the compared items. Despite extensive studies, few prior literatures investigate this problem under the more realistic setting where covariate information exists. To tackle this issue, we propose a novel model, Covariate-Assisted Ranking Estimation (CARE) model, that extends the well-known Bradley-Terry-Luce (BTL) model, by incorporating the covariate information. Specifically, instead of assuming every compared item has a fixed latent score $\{\theta_i^*\}_{i=1}^n$, we assume the underlying scores are given by $\{\alpha_i^*+{x}_i^\top\beta^*\}_{i=1}^n$, where $\alpha_i^*$ and ${x}_i^\top\beta^*$ represent latent baseline and covariate score of the $i$-th item, respectively. We impose natural identifiability conditions and derive the $\ell_{\infty}$- and $\ell_2$-optimal rates for the maximum likelihood estimator of $\{\alpha_i^*\}_{i=1}^{n}$ and $\beta^*$ under a sparse comparison graph, using a novel `leave-one-out' technique (Chen et al., 2019) . To conduct statistical inferences, we further derive asymptotic distributions for the MLE of $\{\alpha_i^*\}_{i=1}^n$ and $\beta^*$ with minimal sample complexity. This allows us to answer the question whether some covariates have any explanation power for latent scores and to threshold some sparse parameters to improve the ranking performance. We improve the approximation method used in (Gao et al., 2021) for the BLT model and generalize it to the CARE model. Moreover, we validate our theoretical results through large-scale numerical studies and an application to the mutual fund stock holding dataset.
Ranking Inferences Based on the Top Choice of Multiway Comparisons
Dec 07, 2022



This paper considers ranking inference of $n$ items based on the observed data on the top choice among $M$ randomly selected items at each trial. This is a useful modification of the Plackett-Luce model for $M$-way ranking with only the top choice observed and is an extension of the celebrated Bradley-Terry-Luce model that corresponds to $M=2$. Under a uniform sampling scheme in which any $M$ distinguished items are selected for comparisons with probability $p$ and the selected $M$ items are compared $L$ times with multinomial outcomes, we establish the statistical rates of convergence for underlying $n$ preference scores using both $\ell_2$-norm and $\ell_\infty$-norm, with the minimum sampling complexity. In addition, we establish the asymptotic normality of the maximum likelihood estimator that allows us to construct confidence intervals for the underlying scores. Furthermore, we propose a novel inference framework for ranking items through a sophisticated maximum pairwise difference statistic whose distribution is estimated via a valid Gaussian multiplier bootstrap. The estimated distribution is then used to construct simultaneous confidence intervals for the differences in the preference scores and the ranks of individual items. They also enable us to address various inference questions on the ranks of these items. Extensive simulation studies lend further support to our theoretical results. A real data application illustrates the usefulness of the proposed methods convincingly.
Robust High-dimensional Tuning Free Multiple Testing
Nov 23, 2022



A stylized feature of high-dimensional data is that many variables have heavy tails, and robust statistical inference is critical for valid large-scale statistical inference. Yet, the existing developments such as Winsorization, Huberization and median of means require the bounded second moments and involve variable-dependent tuning parameters, which hamper their fidelity in applications to large-scale problems. To liberate these constraints, this paper revisits the celebrated Hodges-Lehmann (HL) estimator for estimating location parameters in both the one- and two-sample problems, from a non-asymptotic perspective. Our study develops Berry-Esseen inequality and Cram\'{e}r type moderate deviation for the HL estimator based on newly developed non-asymptotic Bahadur representation, and builds data-driven confidence intervals via a weighted bootstrap approach. These results allow us to extend the HL estimator to large-scale studies and propose \emph{tuning-free} and \emph{moment-free} high-dimensional inference procedures for testing global null and for large-scale multiple testing with false discovery proportion control. It is convincingly shown that the resulting tuning-free and moment-free methods control false discovery proportion at a prescribed level. The simulation studies lend further support to our developed theory.
SIMPLE-RC: Group Network Inference with Non-Sharp Nulls and Weak Signals
Oct 31, 2022



Large-scale network inference with uncertainty quantification has important applications in natural, social, and medical sciences. The recent work of Fan, Fan, Han and Lv (2022) introduced a general framework of statistical inference on membership profiles in large networks (SIMPLE) for testing the sharp null hypothesis that a pair of given nodes share the same membership profiles. In real applications, there are often groups of nodes under investigation that may share similar membership profiles at the presence of relatively weaker signals than the setting considered in SIMPLE. To address these practical challenges, in this paper we propose a SIMPLE method with random coupling (SIMPLE-RC) for testing the non-sharp null hypothesis that a group of given nodes share similar (not necessarily identical) membership profiles under weaker signals. Utilizing the idea of random coupling, we construct our test as the maximum of the SIMPLE tests for subsampled node pairs from the group. Such technique reduces significantly the correlation among individual SIMPLE tests while largely maintaining the power, enabling delicate analysis on the asymptotic distributions of the SIMPLE-RC test. Our method and theory cover both the cases with and without node degree heterogeneity. These new theoretical developments are empowered by a second-order expansion of spiked eigenvectors under the $\ell_\infty$-norm, built upon our work for random matrices with weak spikes. Our theoretical results and the practical advantages of the newly suggested method are demonstrated through several simulation and real data examples.
Factor-Augmented Regularized Model for Hazard Regression
Oct 03, 2022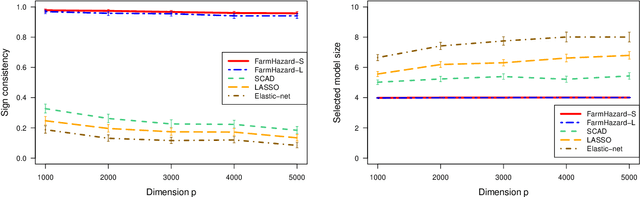
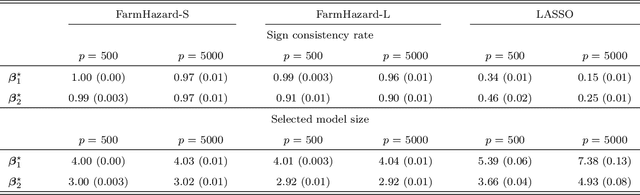
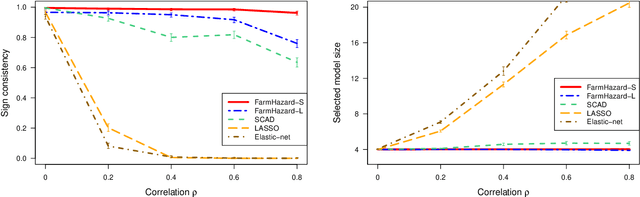
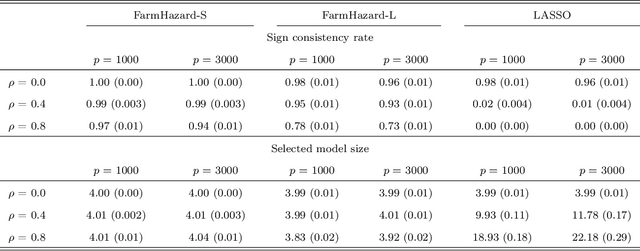
A prevalent feature of high-dimensional data is the dependence among covariates, and model selection is known to be challenging when covariates are highly correlated. To perform model selection for the high-dimensional Cox proportional hazards model in presence of correlated covariates with factor structure, we propose a new model, Factor-Augmented Regularized Model for Hazard Regression (FarmHazard), which builds upon latent factors that drive covariate dependence and extends Cox's model. This new model generates procedures that operate in two steps by learning factors and idiosyncratic components from high-dimensional covariate vectors and then using them as new predictors. Cox's model is a widely used semi-parametric model for survival analysis, where censored data and time-dependent covariates bring additional technical challenges. We prove model selection consistency and estimation consistency under mild conditions. We also develop a factor-augmented variable screening procedure to deal with strong correlations in ultra-high dimensional problems. Extensive simulations and real data experiments demonstrate that our procedures enjoy good performance and achieve better results on model selection, out-of-sample C-index and screening than alternative methods.
Strategic Decision-Making in the Presence of Information Asymmetry: Provably Efficient RL with Algorithmic Instruments
Aug 23, 2022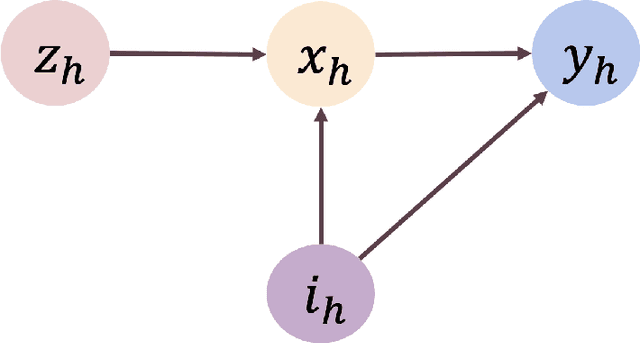
We study offline reinforcement learning under a novel model called strategic MDP, which characterizes the strategic interactions between a principal and a sequence of myopic agents with private types. Due to the bilevel structure and private types, strategic MDP involves information asymmetry between the principal and the agents. We focus on the offline RL problem, where the goal is to learn the optimal policy of the principal concerning a target population of agents based on a pre-collected dataset that consists of historical interactions. The unobserved private types confound such a dataset as they affect both the rewards and observations received by the principal. We propose a novel algorithm, Pessimistic policy Learning with Algorithmic iNstruments (PLAN), which leverages the ideas of instrumental variable regression and the pessimism principle to learn a near-optimal principal's policy in the context of general function approximation. Our algorithm is based on the critical observation that the principal's actions serve as valid instrumental variables. In particular, under a partial coverage assumption on the offline dataset, we prove that PLAN outputs a $1 / \sqrt{K}$-optimal policy with $K$ being the number of collected trajectories. We further apply our framework to some special cases of strategic MDP, including strategic regression, strategic bandit, and noncompliance in recommendation systems.