 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General Preference Alignment: Diffusion Models at Nash Equilibrium
May 06, 2026Reinforcement learning from human feedback (RLHF) has been popular for aligning text-to-image (T2I) diffusion models with human preferences. As a mainstream branch of RLHF, Direct Preference Optimization (DPO) offers a computationally efficient alternative that avoids explicit reward modeling and has been widely adopted in diffusion alignment. However, existing preference-based methods for diffusion alignment still rely on reward-induced preference signals and typically assume that human preferences can be adequately modeled by the Bradley--Terry (BT) model, which may fail to capture the full complexity of human preferences. In this paper, we formulate diffusion alignment from a game-theoretic perspective. We propose Diffusion Nash Preference Optimization (Diff.-NPO), an intuitive general preference framework for diffusion alignment. Diff.-NPO encourages the current policy to play against itself to achieve self improvement and lead to a better alignment. Empirically, we demonstrate the effectiveness of Diff.-NPO on the text-to-image generation task via various metrics. Diff.-NPO consistently outperforms existing preference-based diffusion alignment methods.
Adaptive Estimation and Inference in Semi-parametric Heterogeneous Clustered Multitask Learning via Neyman Orthogonality
May 03, 2026We study clustered multitask learning in a semiparametric setting where tasks share a latent cluster structure in their target parameters but exhibit heterogeneous, potentially infinite-dimensional nuisance components. Such heterogeneity poses a major challenge for existing multitask learning methods, which typically rely on aligned feature spaces or homogeneous task structures. To address this challenge, we propose an adaptive fused orthogonal estimator that integrates Neyman-orthogonal losses with data-driven pairwise fusion penalties. Our framework leverages task-specific pilot estimates to calibrate the fusion penalties and combines adaptive aggregation with orthogonalization to mitigate the impact of nuisance-parameter estimation error. Theoretically, we show that the proposed estimator achieves exact recovery of the latent clustering with high probability and attains pooled parametric convergence rates proportional to cluster size. Moreover, we establish asymptotic normality and show that, asymptotically, our estimator matches the performance of an oracle procedure that knows the true clustering in advance. Empirically, we show that the proposed method consistently outperforms strong baselines in various simulation setups. A real-world application to U.S. residential energy consumption demonstrates the effectiveness of our approach in uncovering meaningful regional clustering in electricity price elasticity, showcasing the efficacy of our method.
On the estimation rate of Bayesian PINN for inverse problems
Jun 21, 2024Solving partial differential equations (PDEs) and their inverse problems using Physics-informed neural networks (PINNs) is a rapidly growing approach in the physics and machine learning community. Although several architectures exist for PINNs that work remarkably in practice, our theoretical understanding of their performances is somewhat limited. In this work, we study the behavior of a Bayesian PINN estimator of the solution of a PDE from $n$ independent noisy measurement of the solution. We focus on a class of equations that are linear in their parameters (with unknown coefficients $\theta_\star$). We show that when the partial differential equation admits a classical solution (say $u_\star$), differentiable to order $\beta$, the mean square error of the Bayesian posterior mean is at least of order $n^{-2\beta/(2\beta + d)}$. Furthermore, we establish a convergence rate of the linear coefficients of $\theta_\star$ depending on the order of the underlying differential operator. Last but not least, our theoretical results are validated through extensive simulations.
Optimal Aggregation of Prediction Intervals under Unsupervised Domain Shift
May 16, 2024As machine learning models are increasingly deployed in dynamic environments, it becomes paramount to assess and quantify uncertainties associated with distribution shifts. A distribution shift occurs when the underlying data-generating process changes, leading to a deviation in the model's performance. The prediction interval, which captures the range of likely outcomes for a given prediction, serves as a crucial tool for characterizing uncertainties induced by their underlying distribution. In this paper, we propose methodologies for aggregating prediction intervals to obtain one with minimal width and adequate coverage on the target domain under unsupervised domain shift, under which we have labeled samples from a related source domain and unlabeled covariates from the target domain. Our analysis encompasses scenarios where the source and the target domain are related via i) a bounded density ratio, and ii) a measure-preserving transformation. Our proposed methodologies are computationally efficient and easy to implement. Beyond illustrating the performance of our method through a real-world dataset, we also delve into the theoretical details. This includes establishing rigorous theoretical guarantees, coupled with finite sample bounds, regarding the coverage and width of our prediction intervals. Our approach excels in practical applications and is underpinned by a solid theoretical framework, ensuring its reliability and effectiveness across diverse contexts.
Trade-off Between Dependence and Complexity for Nonparametric Learning -- an Empirical Process Approach
Jan 17, 2024Empirical process theory for i.i.d. observations has emerged as a ubiquitous tool for understanding the generalization properties of various statistical problems. However, in many applications where the data exhibit temporal dependencies (e.g., in finance, medical imaging, weather forecasting etc.), the corresponding empirical processes are much less understood. Motivated by this observation, we present a general bound on the expected supremum of empirical processes under standard $\beta/\rho$-mixing assumptions. Unlike most prior work, our results cover both the long and the short-range regimes of dependence. Our main result shows that a non-trivial trade-off between the complexity of the underlying function class and the dependence among the observations characterizes the learning rate in a large class of nonparametric problems. This trade-off reveals a new phenomenon, namely that even under long-range dependence, it is possible to attain the same rates as in the i.i.d. setting, provided the underlying function class is complex enough. We demonstrate the practical implications of our findings by analyzing various statistical estimators in both fixed and growing dimensions. Our main examples include a comprehensive case study of generalization error bounds in nonparametric regression over smoothness classes in fixed as well as growing dimension using neural nets, shape-restricted multivariate convex regression, estimating the optimal transport (Wasserstein) distance between two probability distributions, and classification under the Mammen-Tsybakov margin condition -- all under appropriate mixing assumptions. In the process, we also develop bounds on $L_r$ ($1\le r\le 2$)-localized empirical processes with dependent observations, which we then leverage to get faster rates for (a) tuning-free adaptation, and (b) set-structured learning problems.
UTOPIA: Universally Trainable Optimal Prediction Intervals Aggregation
Jun 28, 2023



Uncertainty quantification for prediction is an intriguing problem with significant applications in various fields, such as biomedical science, economic studies, and weather forecasts. Numerous methods are available for constructing prediction intervals, such as quantile regression and conformal predictions, among others. Nevertheless, model misspecification (especially in high-dimension) or sub-optimal constructions can frequently result in biased or unnecessarily-wide prediction intervals. In this paper, we propose a novel and widely applicable technique for aggregating multiple prediction intervals to minimize the average width of the prediction band along with coverage guarantee, called Universally Trainable Optimal Predictive Intervals Aggregation (UTOPIA). The method also allows us to directly construct predictive bands based on elementary basis functions. Our approach is based on linear or convex programming which is easy to implement. All of our proposed methodologies are supported by theoretical guarantees on the coverage probability and optimal average length, which are detailed in this paper. The effectiveness of our approach is convincingly demonstrated by applying it to synthetic data and two real datasets on finance and macroeconomics.
Deep Neural Networks for Nonparametric Interaction Models with Diverging Dimension
Feb 12, 2023Deep neural networks have achieved tremendous success due to their representation power and adaptation to low-dimensional structures. Their potential for estimating structured regression functions has been recently established in the literature. However, most of the studies require the input dimension to be fixed and consequently ignore the effect of dimension on the rate of convergence and hamper their applications to modern big data with high dimensionality. In this paper, we bridge this gap by analyzing a $k^{th}$ order nonparametric interaction model in both growing dimension scenarios ($d$ grows with $n$ but at a slower rate) and in high dimension ($d \gtrsim n$). In the latter case, sparsity assumptions and associated regularization are required in order to obtain optimal rates of convergence. A new challenge in diverging dimension setting is in calculation mean-square error, the covariance terms among estimated additive components are an order of magnitude larger than those of the variances and they can deteriorate statistical properties without proper care. We introduce a critical debiasing technique to amend the problem. We show that under certain standard assumptions, debiased deep neural networks achieve a minimax optimal rate both in terms of $(n, d)$. Our proof techniques rely crucially on a novel debiasing technique that makes the covariances of additive components negligible in the mean-square error calculation. In addition, we establish the matching lower bounds.
Predictor-corrector algorithms for stochastic optimization under gradual distribution shift
May 26, 2022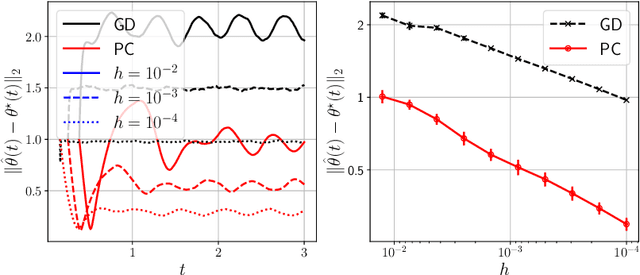
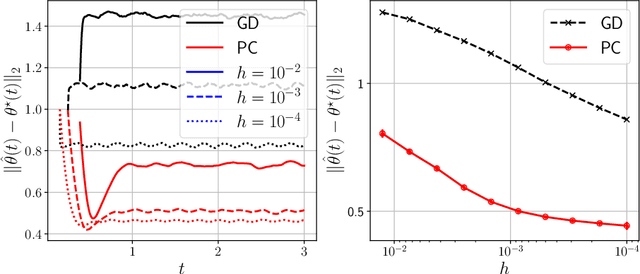
Time-varying stochastic optimization problems frequently arise in machine learning practice (e.g. gradual domain shift, object tracking, strategic classification). Although most problems are solved in discrete time, the underlying process is often continuous in nature. We exploit this underlying continuity by developing predictor-corrector algorithms for time-varying stochastic optimizations. We provide error bounds for the iterates, both in presence of pure and noisy access to the queries from the relevant derivatives of the loss function. Furthermore, we show (theoretically and empirically in several examples) that our method outperforms non-predictor corrector methods that do not exploit the underlying continuous process.
Domain Adaptation meets Individual Fairness. And they get along
May 01, 2022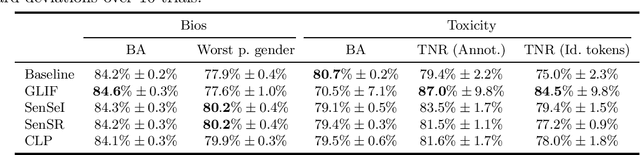
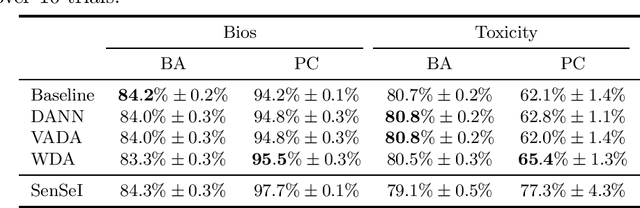
Many instances of algorithmic bias are caused by distributional shifts. For example, machine learning (ML) models often perform worse on demographic groups that are underrepresented in the training data. In this paper, we leverage this connection between algorithmic fairness and distribution shifts to show that algorithmic fairness interventions can help ML models overcome distribution shifts, and that domain adaptation methods (for overcoming distribution shifts) can mitigate algorithmic biases. In particular, we show that (i) enforcing suitable notions of individual fairness (IF) can improve the out-of-distribution accuracy of ML models, and that (ii) it is possible to adapt representation alignment methods for domain adaptation to enforce (individual) fairness. The former is unexpected because IF interventions were not developed with distribution shifts in mind. The latter is also unexpected because representation alignment is not a common approach in the IF literature.
Post-processing for Individual Fairness
Oct 26, 2021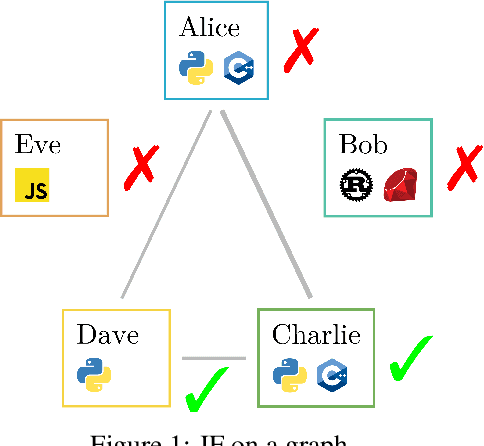
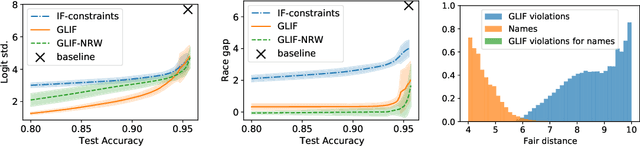

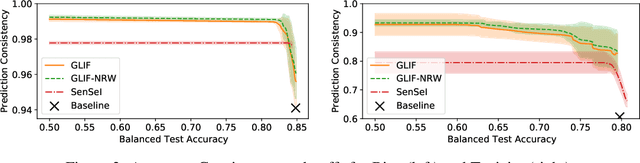
Post-processing in algorithmic fairness is a versatile approach for correcting bias in ML systems that are already used in production. The main appeal of post-processing is that it avoids expensive retraining. In this work, we propose general post-processing algorithms for individual fairness (IF). We consider a setting where the learner only has access to the predictions of the original model and a similarity graph between individuals, guiding the desired fairness constraints. We cast the IF post-processing problem as a graph smoothing problem corresponding to graph Laplacian regularization that preserves the desired "treat similar individuals similarly" interpretation. Our theoretical results demonstrate the connection of the new objective function to a local relaxation of the original individual fairness. Empirically, our post-processing algorithms correct individual biases in large-scale NLP models such as BERT, while preserving accuracy.