 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Contrastive Learning for Long-Tailed Visual Recognition
Jul 19, 2022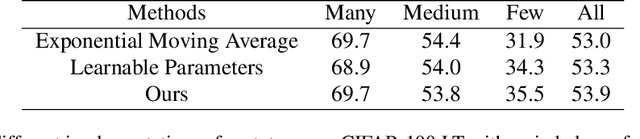
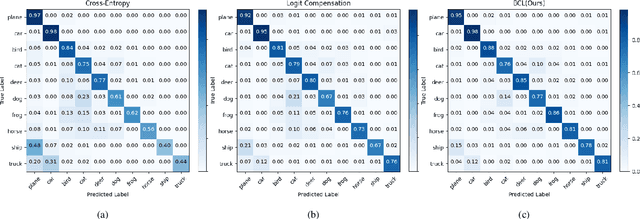
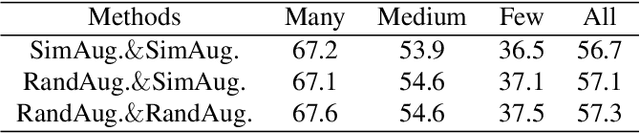
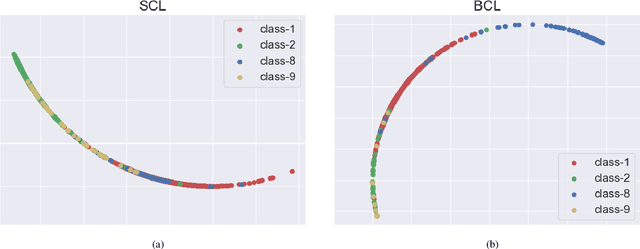
Real-world data typically follow a long-tailed distribution, where a few majority categories occupy most of the data while most minority categories contain a limited number of samples. Classification models minimizing cross-entropy struggle to represent and classify the tail classes. Although the problem of learning unbiased classifiers has been well studied, methods for representing imbalanced data are under-explored. In this paper, we focus on representation learning for imbalanced data. Recently, supervised contrastive learning has shown promising performance on balanced data recently. However, through our theoretical analysis, we find that for long-tailed data, it fails to form a regular simplex which is an ideal geometric configuration for representation learning. To correct the optimization behavior of SCL and further improve the performance of long-tailed visual recognition, we propose a novel loss for balanced contrastive learning (BCL). Compared with SCL, we have two improvements in BCL: class-averaging, which balances the gradient contribution of negative classes; class-complement, which allows all classes to appear in every mini-batch. The proposed balanced contrastive learning (BCL) method satisfies the condition of forming a regular simplex and assists the optimization of cross-entropy. Equipped with BCL, the proposed two-branch framework can obtain a stronger feature representation and achieve competitive performance on long-tailed benchmark datasets such as CIFAR-10-LT, CIFAR-100-LT, ImageNet-LT, and iNaturalist2018. Our code is available at \href{https://github.com/FlamieZhu/BCL}{this URL}.
GitHub Copilot AI pair programmer: Asset or Liability?
Jun 30, 2022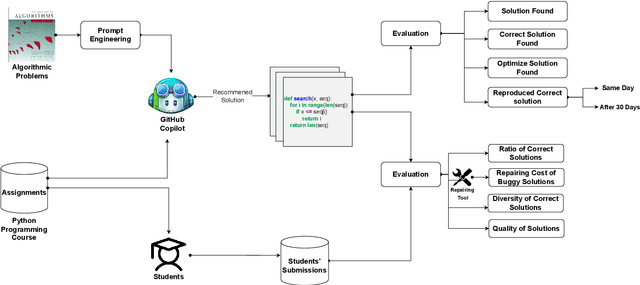
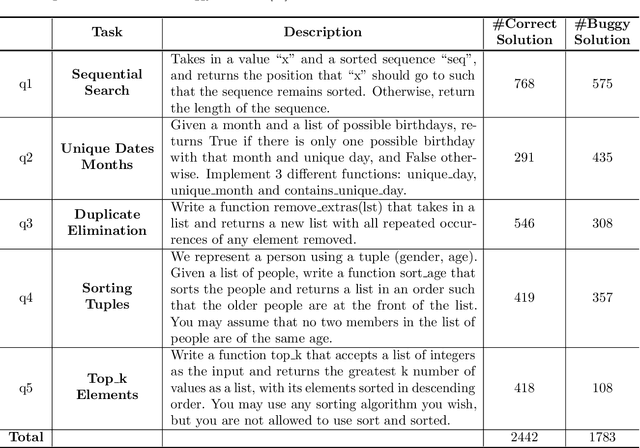

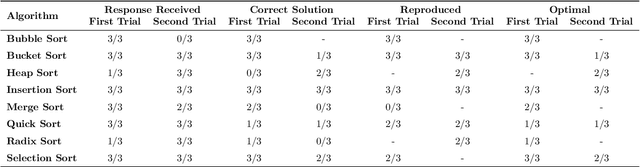
Automatic program synthesis is a long-lasting dream in software engineering. Recently, a promising Deep Learning (DL) based solution, called Copilot, has been proposed by Open AI and Microsoft as an industrial product. Although some studies evaluate the correctness of Copilot solutions and report its issues, more empirical evaluations are necessary to understand how developers can benefit from it effectively. In this paper, we study the capabilities of Copilot in two different programming tasks: (1) generating (and reproducing) correct and efficient solutions for fundamental algorithmic problems, and (2) comparing Copilot's proposed solutions with those of human programmers on a set of programming tasks. For the former, we assess the performance and functionality of Copilot in solving selected fundamental problems in computer science, like sorting and implementing basic data structures. In the latter, a dataset of programming problems with human-provided solutions is used. The results show that Copilot is capable of providing solutions for almost all fundamental algorithmic problems, however, some solutions are buggy and non-reproducible. Moreover, Copilot has some difficulties in combining multiple methods to generate a solution. Comparing Copilot to humans, our results show that the correct ratio of human solutions is greater than Copilot's correct ratio, while the buggy solutions generated by Copilot require less effort to be repaired. While Copilot shows limitations as an assistant for developers especially in advanced programming tasks, as highlighted in this study and previous ones, it can generate preliminary solutions for basic programming tasks.
An Empirical Study of Challenges in Converting Deep Learning Models
Jun 28, 2022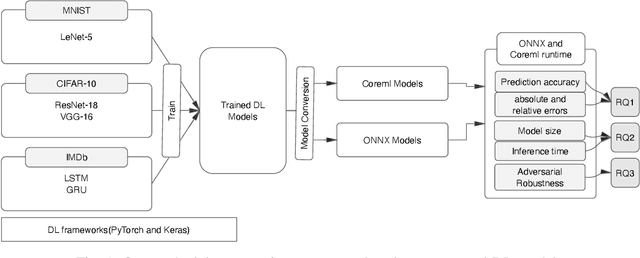
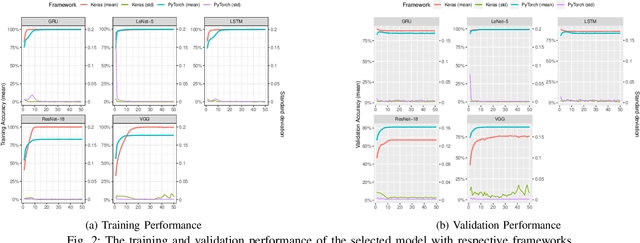
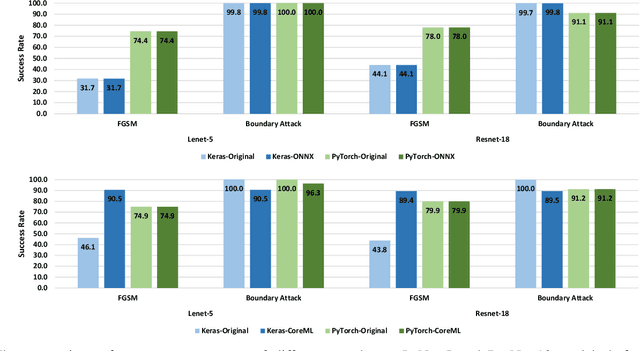
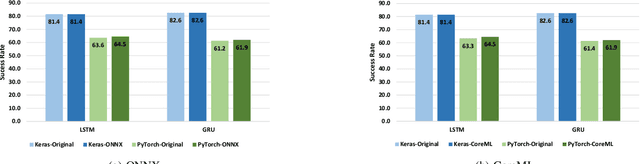
There is an increase in deploying Deep Learning (DL)-based software systems in real-world applications. Usually DL models are developed and trained using DL frameworks that have their own internal mechanisms/formats to represent and train DL models, and usually those formats cannot be recognized by other frameworks. Moreover, trained models are usually deployed in environments different from where they were developed. To solve the interoperability issue and make DL models compatible with different frameworks/environments, some exchange formats are introduced for DL models, like ONNX and CoreML. However, ONNX and CoreML were never empirically evaluated by the community to reveal their prediction accuracy, performance, and robustness after conversion. Poor accuracy or non-robust behavior of converted models may lead to poor quality of deployed DL-based software systems. We conduct, in this paper, the first empirical study to assess ONNX and CoreML for converting trained DL models. In our systematic approach, two popular DL frameworks, Keras and PyTorch, are used to train five widely used DL models on three popular datasets. The trained models are then converted to ONNX and CoreML and transferred to two runtime environments designated for such formats, to be evaluated. We investigate the prediction accuracy before and after conversion. Our results unveil that the prediction accuracy of converted models are at the same level of originals. The performance (time cost and memory consumption) of converted models are studied as well. The size of models are reduced after conversion, which can result in optimized DL-based software deployment. Converted models are generally assessed as robust at the same level of originals. However, obtained results show that CoreML models are more vulnerable to adversarial attacks compared to ONNX.
Bugs in Machine Learning-based Systems: A Faultload Benchmark
Jun 24, 2022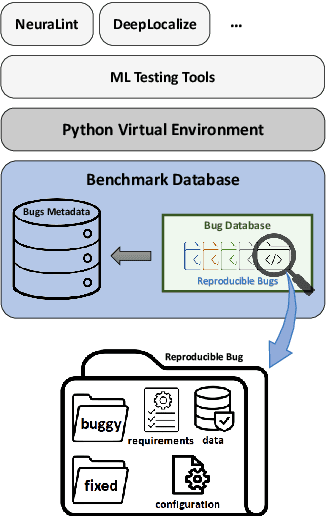

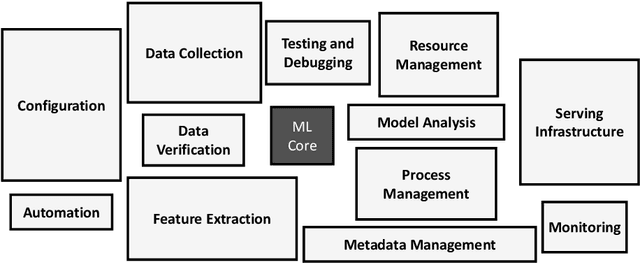

The rapid escalation of applying Machine Learning (ML) in various domains has led to paying more attention to the quality of ML components. There is then a growth of techniques and tools aiming at improving the quality of ML components and integrating them into the ML-based system safely. Although most of these tools use bugs' lifecycle, there is no standard benchmark of bugs to assess their performance, compare them and discuss their advantages and weaknesses. In this study, we firstly investigate the reproducibility and verifiability of the bugs in ML-based systems and show the most important factors in each one. Then, we explore the challenges of generating a benchmark of bugs in ML-based software systems and provide a bug benchmark namely defect4ML that satisfies all criteria of standard benchmark, i.e. relevance, reproducibility, fairness, verifiability, and usability. This faultload benchmark contains 113 bugs reported by ML developers on GitHub and Stack Overflow, using two of the most popular ML frameworks: TensorFlow and Keras. defect4ML also addresses important challenges in Software Reliability Engineering of ML-based software systems, like: 1) fast changes in frameworks, by providing various bugs for different versions of frameworks, 2) code portability, by delivering similar bugs in different ML frameworks, 3) bug reproducibility, by providing fully reproducible bugs with complete information about required dependencies and data, and 4) lack of detailed information on bugs, by presenting links to the bugs' origins. defect4ML can be of interest to ML-based systems practitioners and researchers to assess their testing tools and techniques.
Towards a Change Taxonomy for Machine Learning Systems
Mar 21, 2022

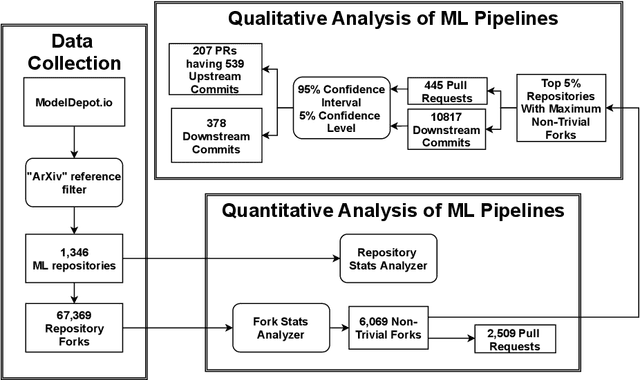
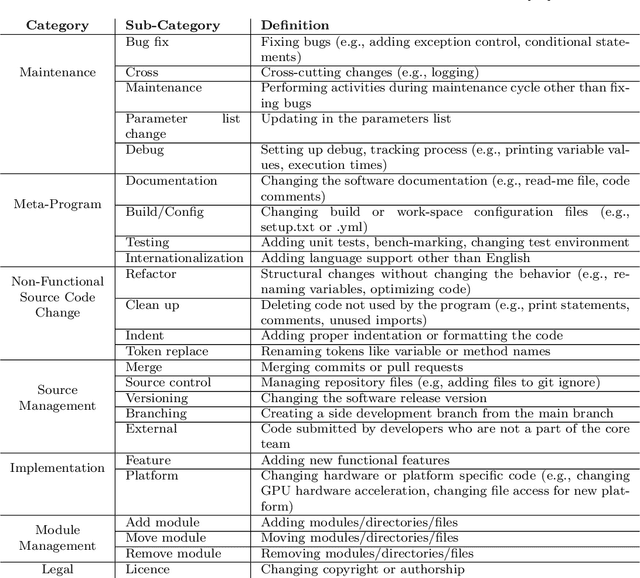
Machine Learning (ML) research publications commonly provide open-source implementations on GitHub, allowing their audience to replicate, validate, or even extend machine learning algorithms, data sets, and metadata. However, thus far little is known about the degree of collaboration activity happening on such ML research repositories, in particular regarding (1) the degree to which such repositories receive contributions from forks, (2) the nature of such contributions (i.e., the types of changes), and (3) the nature of changes that are not contributed back to forks, which might represent missed opportunities. In this paper, we empirically study contributions to 1,346 ML research repositories and their 67,369 forks, both quantitatively and qualitatively (by building on Hindle et al.'s seminal taxonomy of code changes). We found that while ML research repositories are heavily forked, only 9% of the forks made modifications to the forked repository. 42% of the latter sent changes to the parent repositories, half of which (52%) were accepted by the parent repositories. Our qualitative analysis on 539 contributed and 378 local (fork-only) changes, extends Hindle et al.'s taxonomy with one new top-level change category related to ML (Data), and 15 new sub-categories, including nine ML-specific ones (input data, output data, program data, sharing, change evaluation, parameter tuning, performance, pre-processing, model training). While the changes that are not contributed back by the forks mostly concern domain-specific customizations and local experimentation (e.g., parameter tuning), the origin ML repositories do miss out on a non-negligible 15.4% of Documentation changes, 13.6% of Feature changes and 11.4% of Bug fix changes. The findings in this paper will be useful for practitioners, researchers, toolsmiths, and educators.
Towards a consistent interpretation of AIOps models
Feb 04, 2022



Artificial Intelligence for IT Operations (AIOps) has been adopted in organizations in various tasks, including interpreting models to identify indicators of service failures. To avoid misleading practitioners, AIOps model interpretations should be consistent (i.e., different AIOps models on the same task agree with one another on feature importance). However, many AIOps studies violate established practices in the machine learning community when deriving interpretations, such as interpreting models with suboptimal performance, though the impact of such violations on the interpretation consistency has not been studied. In this paper, we investigate the consistency of AIOps model interpretation along three dimensions: internal consistency, external consistency, and time consistency. We conduct a case study on two AIOps tasks: predicting Google cluster job failures, and Backblaze hard drive failures. We find that the randomness from learners, hyperparameter tuning, and data sampling should be controlled to generate consistent interpretations. AIOps models with AUCs greater than 0.75 yield more consistent interpretation compared to low-performing models. Finally, AIOps models that are constructed with the Sliding Window or Full History approaches have the most consistent interpretation with the trends presented in the entire datasets. Our study provides valuable guidelines for practitioners to derive consistent AIOps model interpretation.
Towards Training Reproducible Deep Learning Models
Feb 04, 2022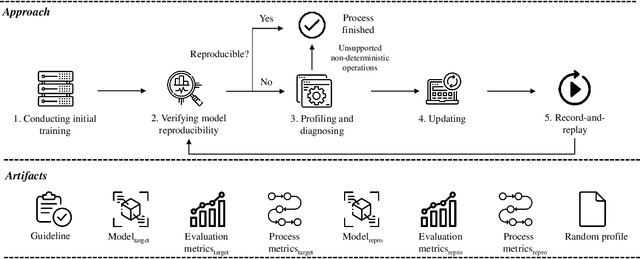
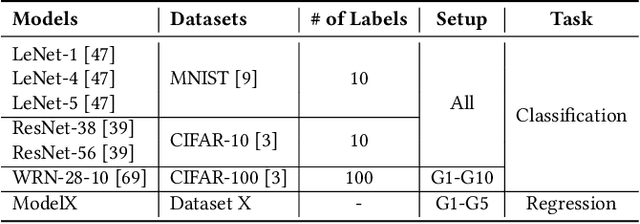

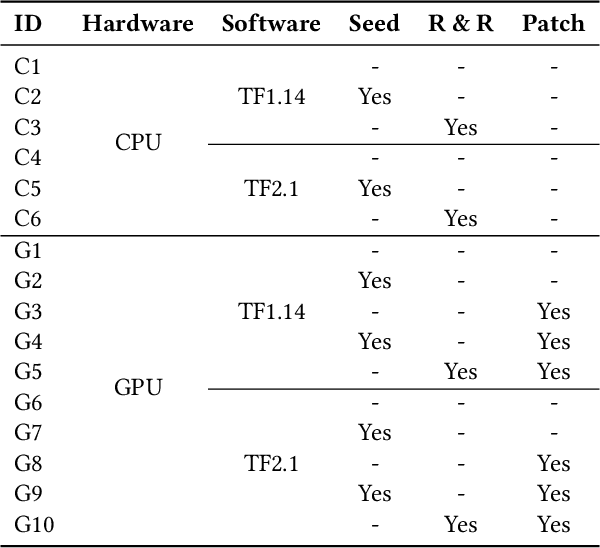
Reproducibility is an increasing concern in Artificial Intelligence (AI), particularly in the area of Deep Learning (DL). Being able to reproduce DL models is crucial for AI-based systems, as it is closely tied to various tasks like training, testing, debugging, and auditing. However, DL models are challenging to be reproduced due to issues like randomness in the software (e.g., DL algorithms) and non-determinism in the hardware (e.g., GPU). There are various practices to mitigate some of the aforementioned issues. However, many of them are either too intrusive or can only work for a specific usage context. In this paper, we propose a systematic approach to training reproducible DL models. Our approach includes three main parts: (1) a set of general criteria to thoroughly evaluate the reproducibility of DL models for two different domains, (2) a unified framework which leverages a record-and-replay technique to mitigate software-related randomness and a profile-and-patch technique to control hardware-related non-determinism, and (3) a reproducibility guideline which explains the rationales and the mitigation strategies on conducting a reproducible training process for DL models. Case study results show our approach can successfully reproduce six open source and one commercial DL models.
Can I use this publicly available dataset to build commercial AI software? Most likely not
Nov 09, 2021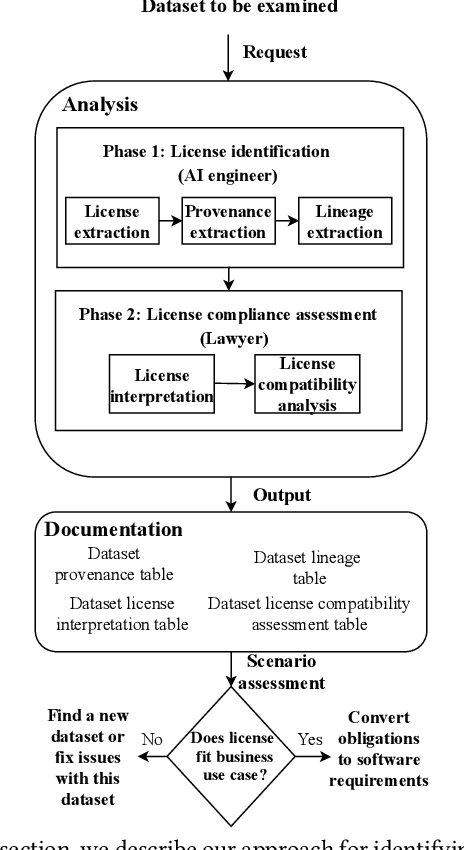

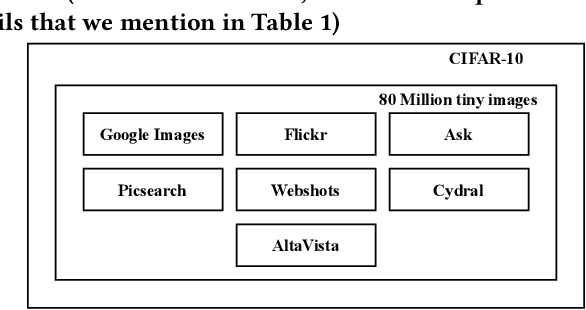
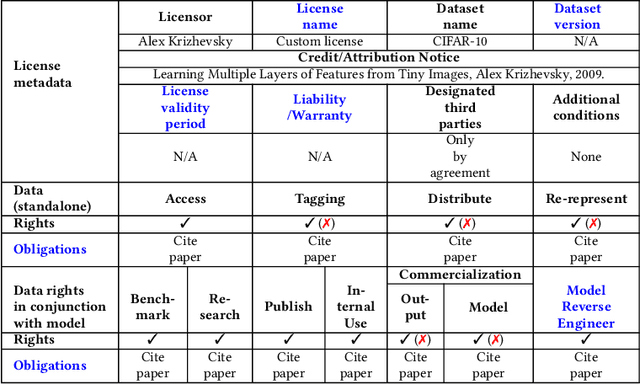
Publicly available datasets are one of the key drivers for commercial AI software. The use of publicly available datasets (particularly for commercial purposes) is governed by dataset licenses. These dataset licenses outline the rights one is entitled to on a given dataset and the obligations that one must fulfil to enjoy such rights without any license compliance violations. However, unlike standardized Open Source Software (OSS) licenses, existing dataset licenses are defined in an ad-hoc manner and do not clearly outline the rights and obligations associated with their usage. This makes checking for potential license compliance violations difficult. Further, a public dataset may be hosted in multiple locations and created from multiple data sources each of which may have different licenses. Hence, existing approaches on checking OSS license compliance cannot be used. In this paper, we propose a new approach to assess the potential license compliance violations if a given publicly available dataset were to be used for building commercial AI software. We conduct trials of our approach on two product groups within Huawei on 6 commonly used publicly available datasets. Our results show that there are risks of license violations on 5 of these 6 studied datasets if they were used for commercial purposes. Consequently, we provide recommendations for AI engineers on how to better assess publicly available datasets for license compliance violations.
LiveMap: Real-Time Dynamic Map in Automotive Edge Computing
Dec 16, 2020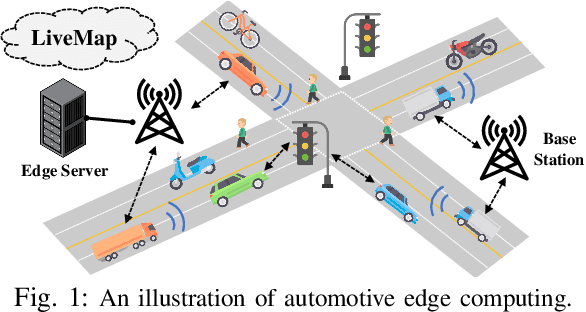
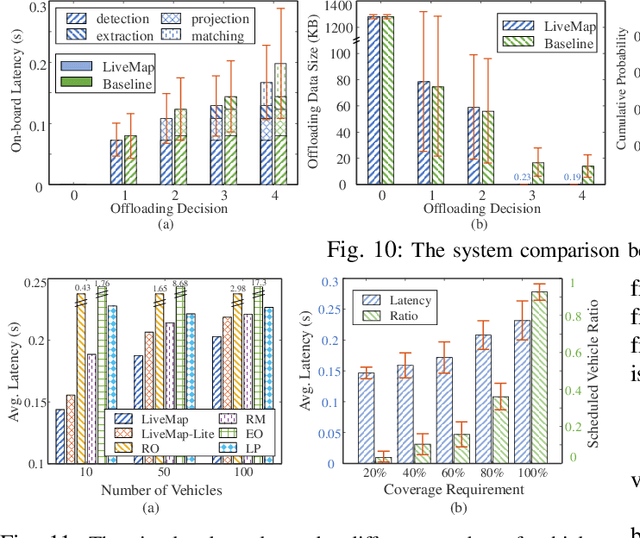
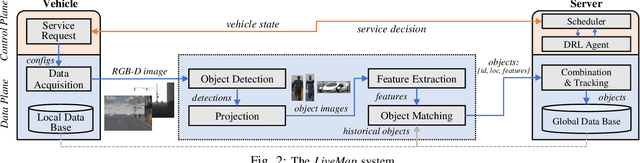
Autonomous driving needs various line-of-sight sensors to perceive surroundings that could be impaired under diverse environment uncertainties such as visual occlusion and extreme weather. To improve driving safety, we explore to wirelessly share perception information among connected vehicles within automotive edge computing networks. Sharing massive perception data in real time, however, is challenging under dynamic networking conditions and varying computation workloads. In this paper, we propose LiveMap, a real-time dynamic map, that detects, matches, and tracks objects on the road with crowdsourcing data from connected vehicles in sub-second. We develop the data plane of LiveMap that efficiently processes individual vehicle data with object detection, projection, feature extraction, object matching, and effectively integrates objects from multiple vehicles with object combination. We design the control plane of LiveMap that allows adaptive offloading of vehicle computations, and develop an intelligent vehicle scheduling and offloading algorithm to reduce the offloading latency of vehicles based on deep reinforcement learning (DRL) techniques. We implement LiveMap on a small-scale testbed and develop a large-scale network simulator. We evaluate the performance of LiveMap with both experiments and simulations, and the results show LiveMap reduces 34.1% average latency than the baseline solution.
Empirical Study on the Software Engineering Practices in Open Source ML Package Repositories
Dec 08, 2020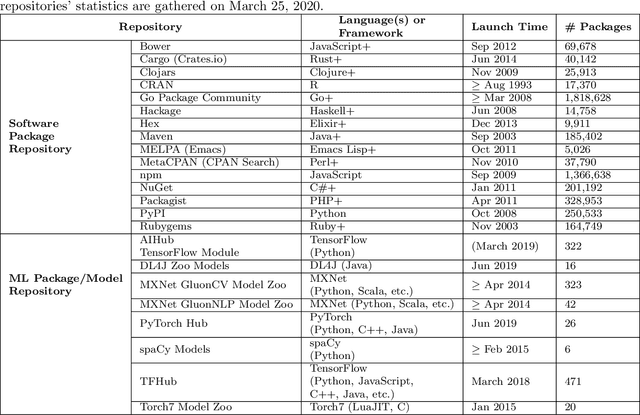
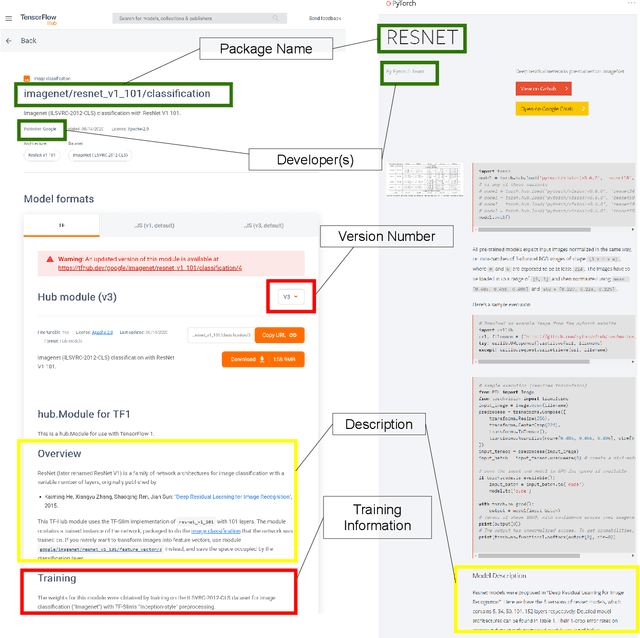
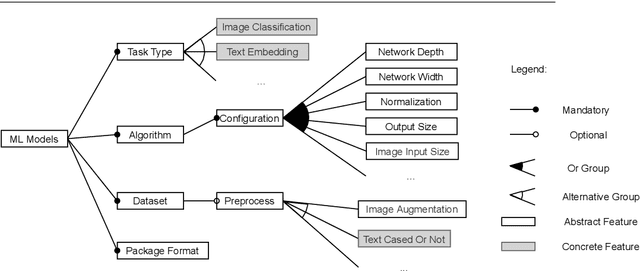
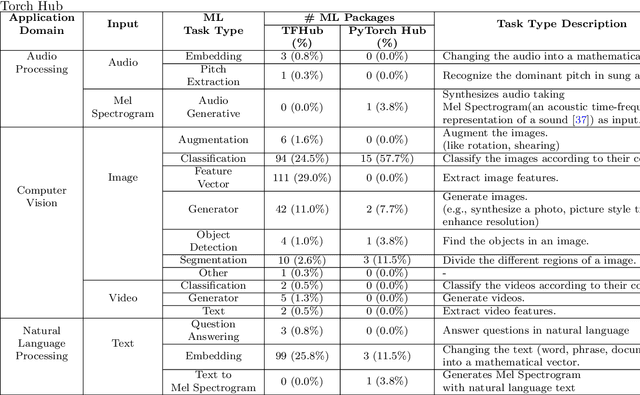
Recent advances in Artificial Intelligence (AI), especially in Machine Learning (ML), have introduced various practical applications (e.g., virtual personal assistants and autonomous cars) that enhance the experience of everyday users. However, modern ML technologies like Deep Learning require considerable technical expertise and resources to develop, train and deploy such models, making effective reuse of the ML models a necessity. Such discovery and reuse by practitioners and researchers are being addressed by public ML package repositories, which bundle up pre-trained models into packages for publication. Since such repositories are a recent phenomenon, there is no empirical data on their current state and challenges. Hence, this paper conducts an exploratory study that analyzes the structure and contents of two popular ML package repositories, TFHub and PyTorch Hub, comparing their information elements (features and policies), package organization, package manager functionalities and usage contexts against popular software package repositories (npm, PyPI, and CRAN). Through these studies, we have identified unique SE practices and challenges for sharing ML packages. These findings and implications would be useful for data scientists, researchers and software developers who intend to use these shared ML packages.