 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neurosymbolic Approach to Natural Language Formalization and Verification
Nov 12, 2025Large Language Models perform well at natural language interpretation and reasoning, but their inherent stochasticity limits their adoption in regulated industries like finance and healthcare that operate under strict policies. To address this limitation, we present a two-stage neurosymbolic framework that (1) uses LLMs with optional human guidance to formalize natural language policies, allowing fine-grained control of the formalization process, and (2) uses inference-time autoformalization to validate logical correctness of natural language statements against those policies. When correctness is paramount, we perform multiple redundant formalization steps at inference time, cross checking the formalizations for semantic equivalence. Our benchmarks demonstrate that our approach exceeds 99% soundness, indicating a near-zero false positive rate in identifying logical validity. Our approach produces auditable logical artifacts that substantiate the verification outcomes and can be used to improve the original text.
Reinforcement Learning with Formal Performance Metrics for Quadcopter Attitude Control under Non-nominal Contexts
Jul 27, 2021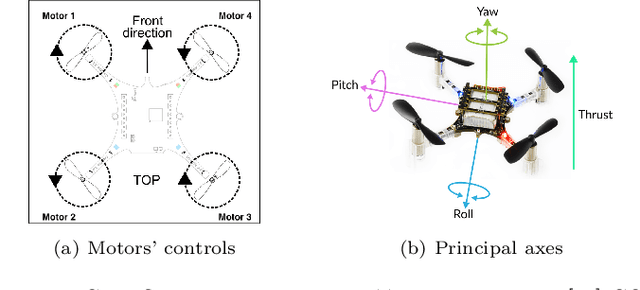
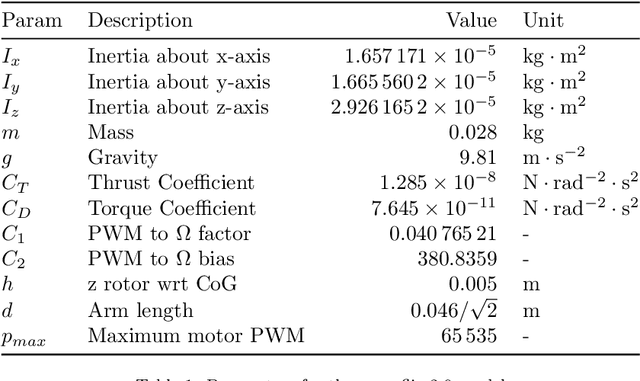

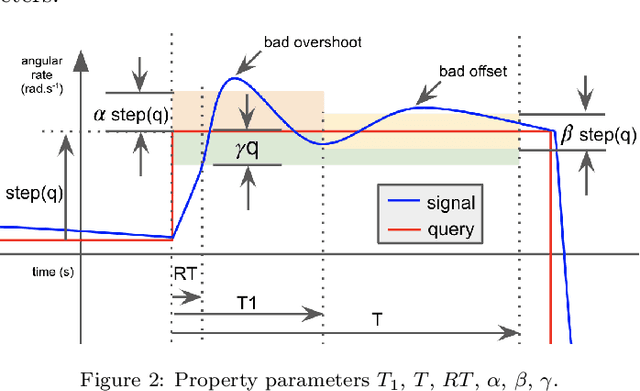
We explore the reinforcement learning approach to designing controllers by extensively discussing the case of a quadcopter attitude controller. We provide all details allowing to reproduce our approach, starting with a model of the dynamics of a crazyflie 2.0 under various nominal and non-nominal conditions, including partial motor failures and wind gusts. We develop a robust form of a signal temporal logic to quantitatively evaluate the vehicle's behavior and measure the performance of controllers. The paper thoroughly describes the choices in training algorithms, neural net architecture, hyperparameters, observation space in view of the different performance metrics we have introduced. We discuss the robustness of the obtained controllers, both to partial loss of power for one rotor and to wind gusts and finish by drawing conclusions on practical controller design by reinforcement learning.