 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSyn: Autonomously Scaling Synthetic Environments for Reasoning Models
Feb 23, 2026Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising approach for training reasoning language models (RLMs) by leveraging supervision from verifiers. Although verifier implementation is easier than solution annotation for many tasks, existing synthetic data generation methods remain largely solution-centric, while verifier-based methods rely on a few hand-crafted procedural environments. In this work, we scale RLVR by introducing ReSyn, a pipeline that generates diverse reasoning environments equipped with instance generators and verifiers, covering tasks such as constraint satisfaction, algorithmic puzzles, and spatial reasoning. A Qwen2.5-7B-Instruct model trained with RL on ReSyn data achieves consistent gains across reasoning benchmarks and out-of-domain math benchmarks, including a 27\% relative improvement on the challenging BBEH benchmark. Ablations show that verifier-based supervision and increased task diversity both contribute significantly, providing empirical evidence that generating reasoning environments at scale can enhance reasoning abilities in RLMs
VERGE: Formal Refinement and Guidance Engine for Verifiable LLM Reasoning
Jan 27, 2026Despite the syntactic fluency of Large Language Models (LLMs), ensuring their logical correctness in high-stakes domains remains a fundamental challenge. We present a neurosymbolic framework that combines LLMs with SMT solvers to produce verification-guided answers through iterative refinement. Our approach decomposes LLM outputs into atomic claims, autoformalizes them into first-order logic, and verifies their logical consistency using automated theorem proving. We introduce three key innovations: (1) multi-model consensus via formal semantic equivalence checking to ensure logic-level alignment between candidates, eliminating the syntactic bias of surface-form metrics, (2) semantic routing that directs different claim types to appropriate verification strategies: symbolic solvers for logical claims and LLM ensembles for commonsense reasoning, and (3) precise logical error localization via Minimal Correction Subsets (MCS), which pinpoint the exact subset of claims to revise, transforming binary failure signals into actionable feedback. Our framework classifies claims by their logical status and aggregates multiple verification signals into a unified score with variance-based penalty. The system iteratively refines answers using structured feedback until acceptance criteria are met or convergence is achieved. This hybrid approach delivers formal guarantees where possible and consensus verification elsewhere, advancing trustworthy AI. With the GPT-OSS-120B model, VERGE demonstrates an average performance uplift of 18.7% at convergence across a set of reasoning benchmarks compared to single-pass approaches.
A Neurosymbolic Approach to Natural Language Formalization and Verification
Nov 12, 2025Large Language Models perform well at natural language interpretation and reasoning, but their inherent stochasticity limits their adoption in regulated industries like finance and healthcare that operate under strict policies. To address this limitation, we present a two-stage neurosymbolic framework that (1) uses LLMs with optional human guidance to formalize natural language policies, allowing fine-grained control of the formalization process, and (2) uses inference-time autoformalization to validate logical correctness of natural language statements against those policies. When correctness is paramount, we perform multiple redundant formalization steps at inference time, cross checking the formalizations for semantic equivalence. Our benchmarks demonstrate that our approach exceeds 99% soundness, indicating a near-zero false positive rate in identifying logical validity. Our approach produces auditable logical artifacts that substantiate the verification outcomes and can be used to improve the original text.
VeriCoT: Neuro-symbolic Chain-of-Thought Validation via Logical Consistency Checks
Nov 06, 2025



LLMs can perform multi-step reasoning through Chain-of-Thought (CoT), but they cannot reliably verify their own logic. Even when they reach correct answers, the underlying reasoning may be flawed, undermining trust in high-stakes scenarios. To mitigate this issue, we introduce VeriCoT, a neuro-symbolic method that extracts and verifies formal logical arguments from CoT reasoning. VeriCoT formalizes each CoT reasoning step into first-order logic and identifies premises that ground the argument in source context, commonsense knowledge, or prior reasoning steps. The symbolic representation enables automated solvers to verify logical validity while the NL premises allow humans and systems to identify ungrounded or fallacious reasoning steps. Experiments on the ProofWriter, LegalBench, and BioASQ datasets show VeriCoT effectively identifies flawed reasoning, and serves as a strong predictor of final answer correctness. We also leverage VeriCoT's verification signal for (1) inference-time self-reflection, (2) supervised fine-tuning (SFT) on VeriCoT-distilled datasets and (3) preference fine-tuning (PFT) with direct preference optimization (DPO) using verification-based pairwise rewards, further improving reasoning validity and accuracy.
The Configurable SAT Solver Challenge (CSSC)
Aug 02, 2016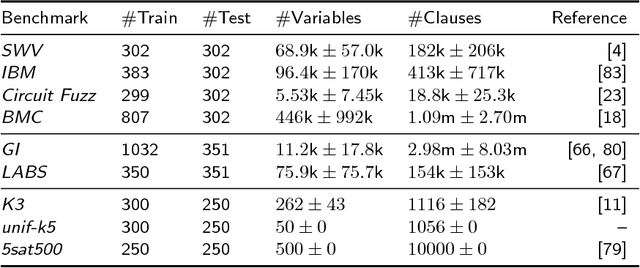
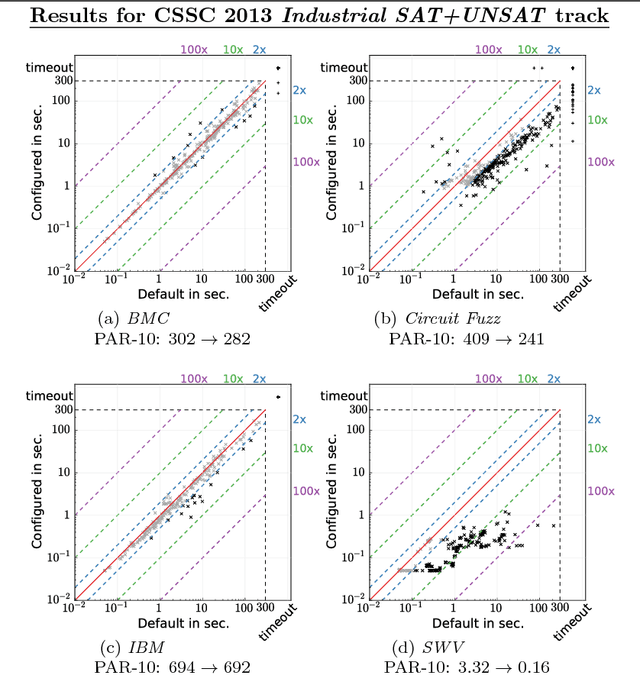
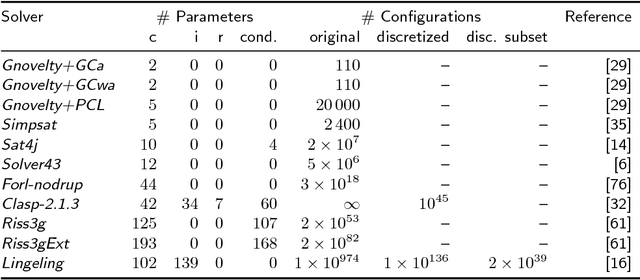
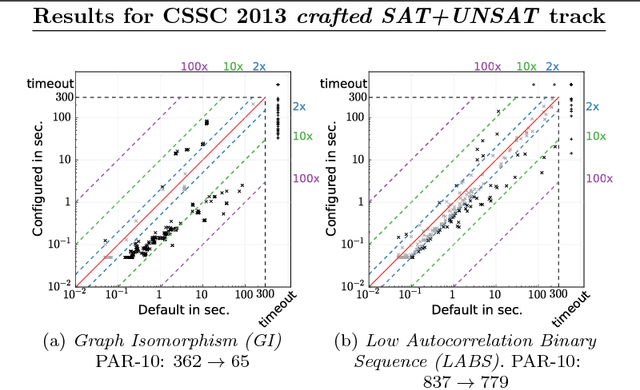
It is well known that different solution strategies work well for different types of instances of hard combinatorial problems. As a consequence, most solvers for the propositional satisfiability problem (SAT) expose parameters that allow them to be customized to a particular family of instances. In the international SAT competition series, these parameters are ignored: solvers are run using a single default parameter setting (supplied by the authors) for all benchmark instances in a given track. While this competition format rewards solvers with robust default settings, it does not reflect the situation faced by a practitioner who only cares about performance on one particular application and can invest some time into tuning solver parameters for this application. The new Configurable SAT Solver Competition (CSSC) compares solvers in this latter setting, scoring each solver by the performance it achieved after a fully automated configuration step. This article describes the CSSC in more detail, and reports the results obtained in its two instantiations so far, CSSC 2013 and 2014.