 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Generative Sampling of 6-DoF Grasps
Feb 21, 2023



Most state-of-the-art data-driven grasp sampling methods propose stable and collision-free grasps uniformly on the target object. For bin-picking, executing any of those grasps is sufficient. However, for completing specific tasks, such as squeezing out liquid from a bottle, we want the grasp to be on a specific part on the object body while avoiding other locations, such as the cap. In this work, we present a generative grasp sampling network, VCGS, capable of constrained 6-Degrees-of-Freedom (DoF) grasp sampling. In addition, we also curate a new dataset designed to train and evaluate methods for constrained grasping. The new dataset, called CONG, consists of over 14 million training samples of synthetically rendered point clouds and grasps at random target areas on 2889 objects. VCGS is benchmarked against GraspNet, a state-of-the-art unconstrained grasp sampler, in simulation and on a real robot. The results demonstrate that VCGS achieves a 10-15% higher grasp success rate than the baseline while being 2-3 times as sample efficient.
A Novel Simulation-Based Quality Metric for Evaluating Grasps on 3D Deformable Objects
Mar 23, 2022
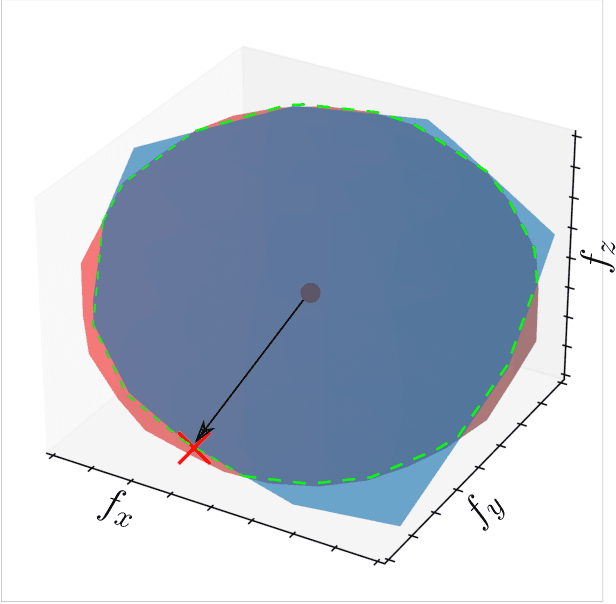
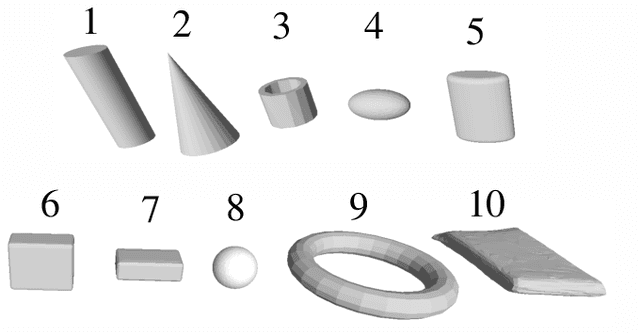
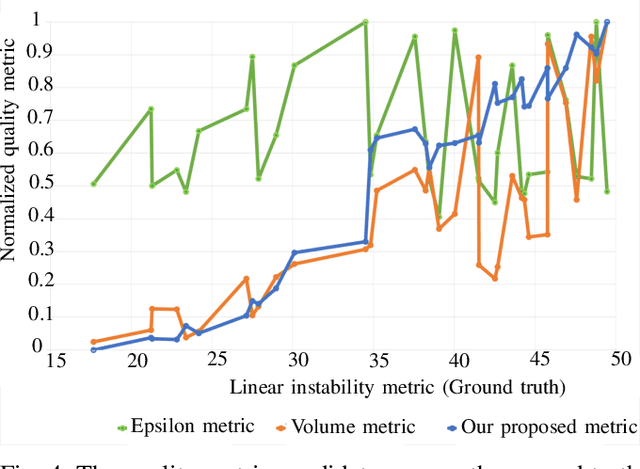
Evaluation of grasps on deformable 3D objects is a little-studied problem, even if the applicability of rigid object grasp quality measures for deformable ones is an open question. A central issue with most quality measures is their dependence on contact points which for deformable objects depend on the deformations. This paper proposes a grasp quality measure for deformable objects that uses information about object deformation to calculate the grasp quality. Grasps are evaluated by simulating the deformations during grasping and predicting the contacts between the gripper and the grasped object. The contact information is then used as input for a new grasp quality metric to quantify the grasp quality. The approach is benchmarked against two classical rigid-body quality metrics on over 600 grasps in the Isaac gym simulation and over 50 real-world grasps. Experimental results show an average improvement of 18\% in the grasp success rate for deformable objects compared to the classical rigid-body quality metrics.
Active Visuo-Haptic Object Shape Completion
Mar 17, 2022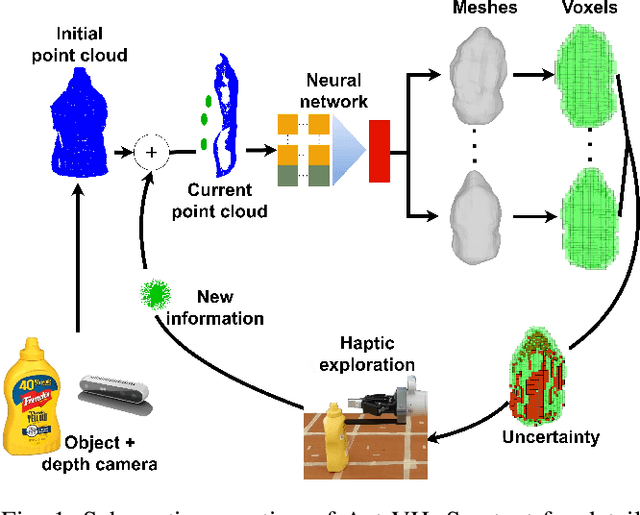
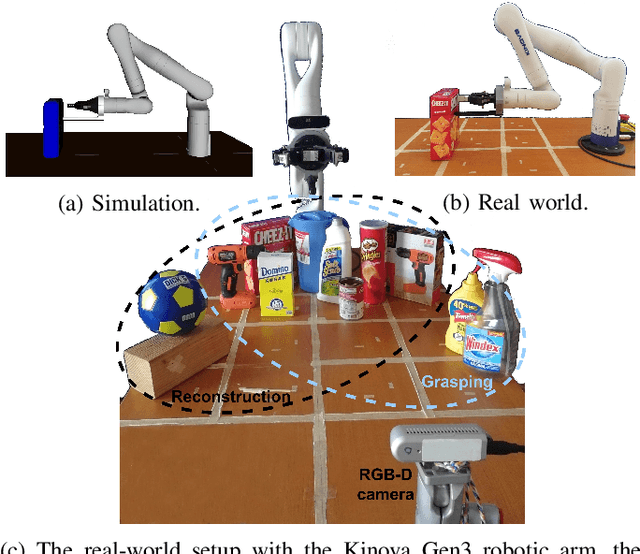
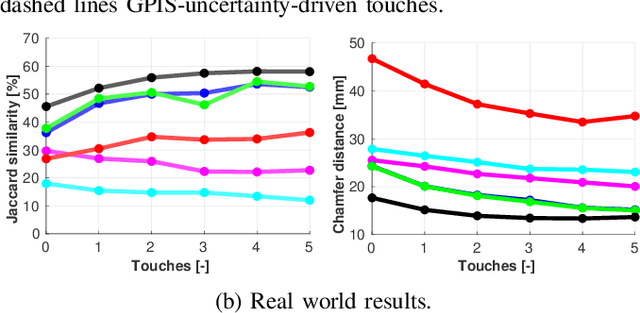
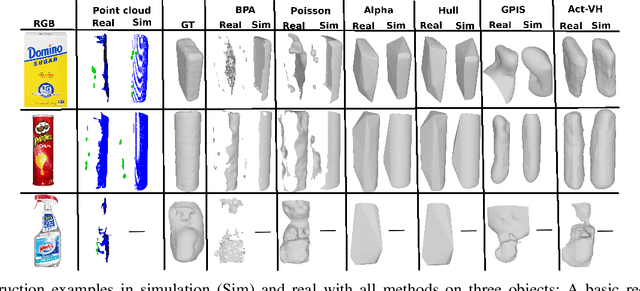
Recent advancements in object shape completion have enabled impressive object reconstructions using only visual input. However, due to self-occlusion, the reconstructions have high uncertainty in the occluded object parts, which negatively impacts the performance of downstream robotic tasks such as grasping. In this work, we propose an active visuo-haptic shape completion method called Act-VH that actively computes where to touch the objects based on the reconstruction uncertainty. Act-VH reconstructs objects from point clouds and calculates the reconstruction uncertainty using IGR, a recent state-of-the-art implicit surface deep neural network. We experimentally evaluate the reconstruction accuracy of Act-VH against five baselines in simulation and in the real world. We also propose a new simulation environment for this purpose. The results show that Act-VH outperforms all baselines and that an uncertainty-driven haptic exploration policy leads to higher reconstruction accuracy than a random policy and a policy driven by Gaussian Process Implicit Surfaces. As a final experiment, we evaluate Act-VH and the best reconstruction baseline on grasping 10 novel objects. The results show that Act-VH reaches a significantly higher grasp success rate than the baseline on all objects. Together, this work opens up the door for using active visuo-haptic shape completion in more complex cluttered scenes.
* 8 pages, 7 figures
Deformation-Aware Data-Driven Grasp Synthesis
Sep 11, 2021

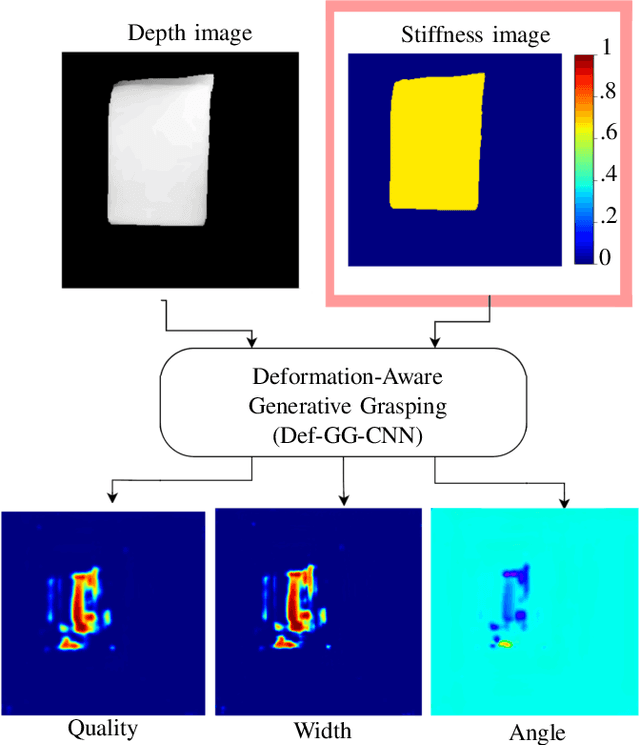
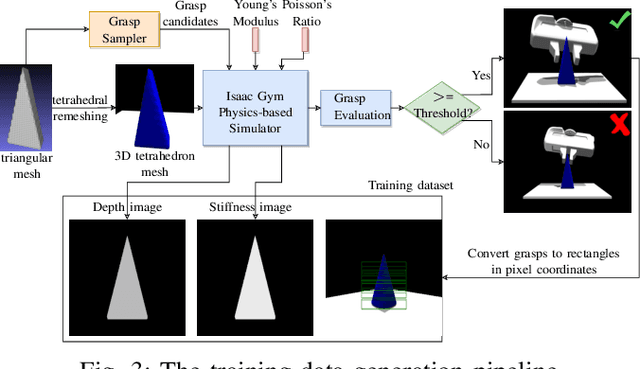
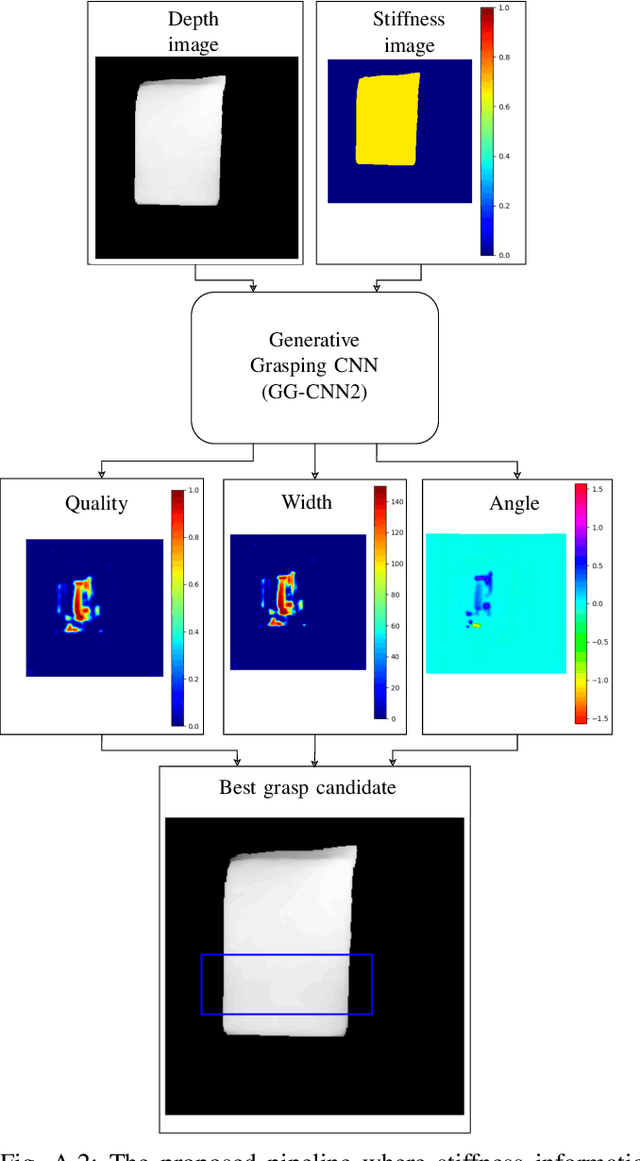
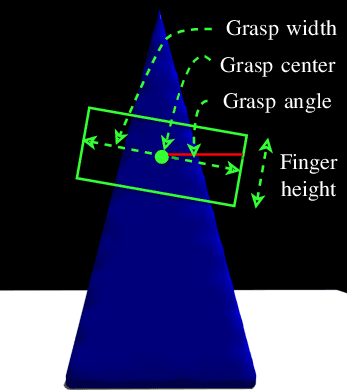
Grasp synthesis for 3D deformable objects remains a little-explored topic, most works aiming to minimize deformations. However, deformations are not necessarily harmful -- humans are, for example, able to exploit deformations to generate new potential grasps. How to achieve that on a robot is though an open question. This paper proposes an approach that uses object stiffness information in addition to depth images for synthesizing high-quality grasps. We achieve this by incorporating object stiffness as an additional input to a state-of-the-art deep grasp planning network. We also curate a new synthetic dataset of grasps on objects of varying stiffness using the Isaac Gym simulator for training the network. We experimentally validate and compare our proposed approach against the case where we do not incorporate object stiffness on a total of 2800 grasps in simulation and 420 grasps on a real Franka Emika Panda. The experimental results show significant improvement in grasp success rate using the proposed approach on a wide range of objects with varying shapes, sizes, and stiffness. Furthermore, we demonstrate that the approach can generate different grasping strategies for different stiffness values, such as pinching for soft objects and caging for hard objects. Together, the results clearly show the value of incorporating stiffness information when grasping objects of varying stiffness.
Towards synthesizing grasps for 3D deformable objects with physics-based simulation
Jul 19, 2021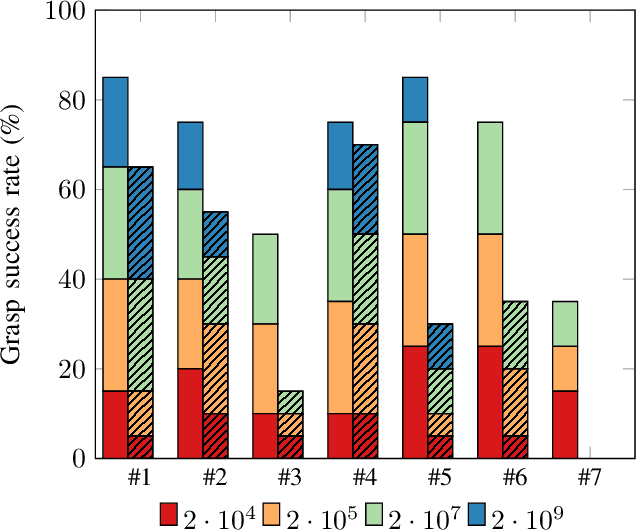
Grasping deformable objects is not well researched due to the complexity in modelling and simulating the dynamic behavior of such objects. However, with the rapid development of physics-based simulators that support soft bodies, the research gap between rigid and deformable objects is getting smaller. To leverage the capability of such simulators and to challenge the assumption that has guided robotic grasping research so far, i.e., object rigidity, we proposed a deep-learning based approach that generates stiffness-dependent grasps. Our network is trained on purely synthetic data generated from a physics-based simulator. The same simulator is also used to evaluate the trained network. The results show improvement in terms of grasp ranking and grasp success rate. Furthermore, our network can adapt the grasps based on the stiffness. We are currently validating the proposed approach on a larger test dataset in simulation and on a physical robot.
DDGC: Generative Deep Dexterous Grasping in Clutter
Mar 08, 2021
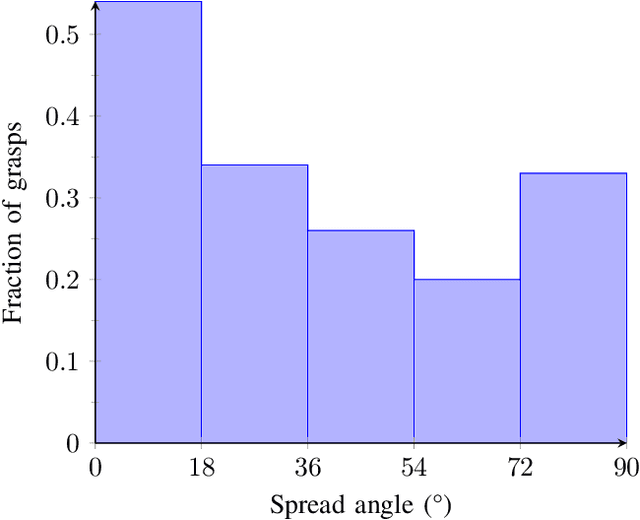
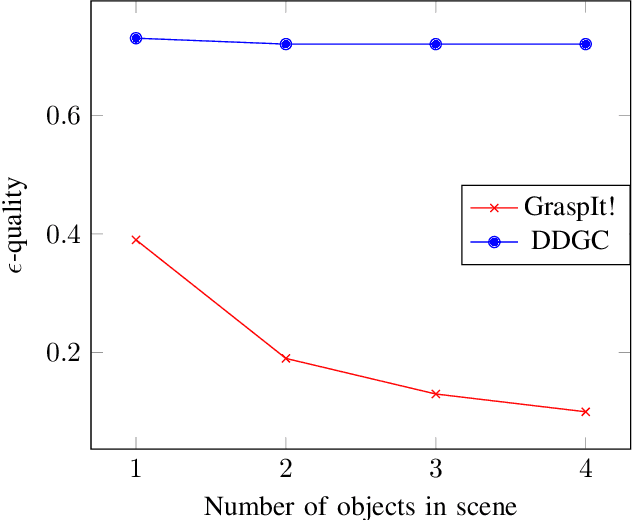

Recent advances in multi-fingered robotic grasping have enabled fast 6-Degrees-Of-Freedom (DOF) single object grasping. Multi-finger grasping in cluttered scenes, on the other hand, remains mostly unexplored due to the added difficulty of reasoning over obstacles which greatly increases the computational time to generate high-quality collision-free grasps. In this work we address such limitations by introducing DDGC, a fast generative multi-finger grasp sampling method that can generate high quality grasps in cluttered scenes from a single RGB-D image. DDGC is built as a network that encodes scene information to produce coarse-to-fine collision-free grasp poses and configurations. We experimentally benchmark DDGC against the simulated-annealing planner in GraspIt! on 1200 simulated cluttered scenes and 7 real world scenes. The results show that DDGC outperforms the baseline on synthesizing high-quality grasps and removing clutter while being 5 times faster. This, in turn, opens up the door for using multi-finger grasps in practical applications which has so far been limited due to the excessive computation time needed by other methods.
Multi-FinGAN: Generative Coarse-To-Fine Sampling of Multi-Finger Grasps
Dec 17, 2020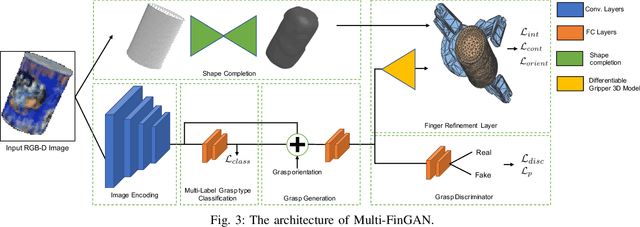

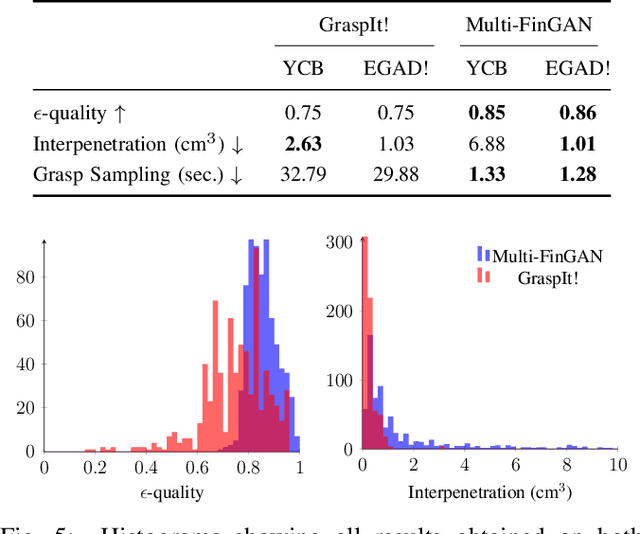
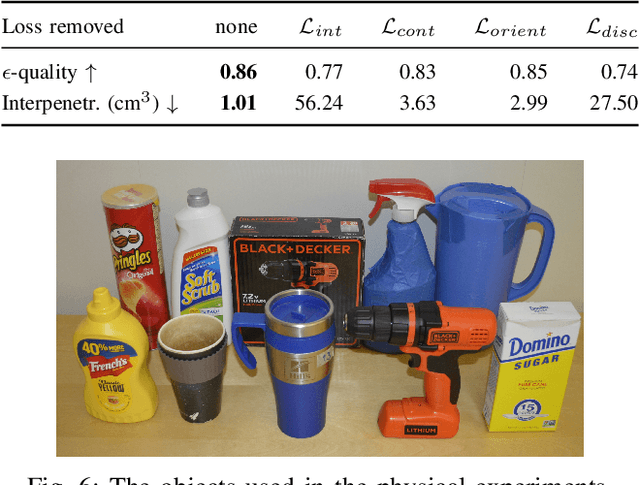
While there exists a large number of methods for manipulating rigid objects with parallel-jaw grippers, grasping with multi-finger robotic hands remains a quite unexplored research topic. Reasoning and planning collision-free trajectories on the additional degrees of freedom of several fingers represents an important challenge that, so far, involves computationally costly and slow processes. In this work, we present Multi-FinGAN, a fast generative multi-finger grasp sampling method that synthesizes high quality grasps directly from RGB-D images in about a second. We achieve this by training in an end-to-end fashion a coarse-to-fine model composed of a classification network that distinguishes grasp types according to a specific taxonomy and a refinement network that produces refined grasp poses and joint angles. We experimentally validate and benchmark our method against standard grasp-sampling methods on 790 grasps in simulation and 20 grasps on a real Franka Emika Panda. All experimental results using our method show consistent improvements both in terms of grasp quality metrics and grasp success rate. Remarkably, our approach is up to 20-30 times faster than the baseline, a significant improvement that opens the door to feedback-based grasp re-planning and task informative grasping.
POMDP Manipulation Planning under Object Composition Uncertainty
Oct 26, 2020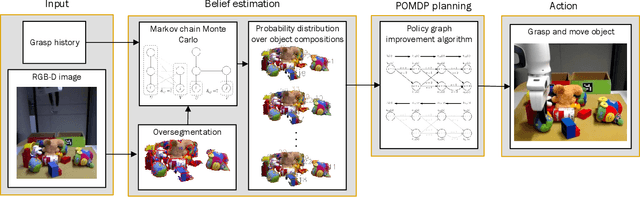
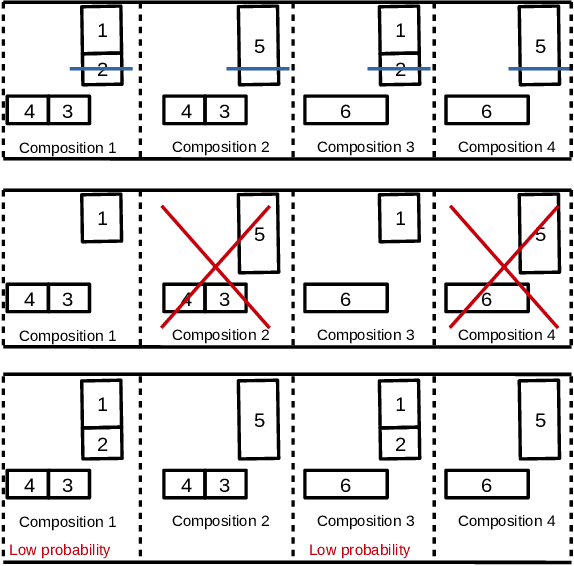
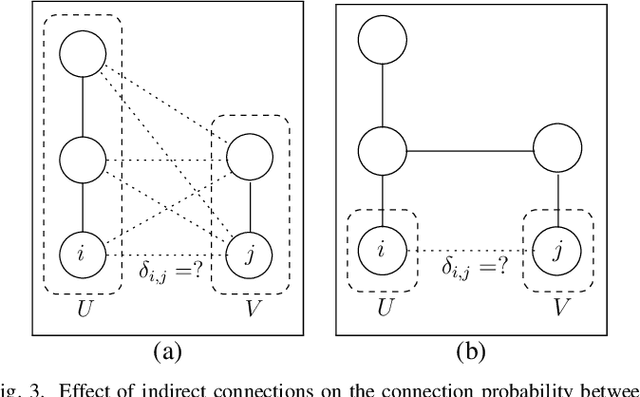
Manipulating unknown objects in a cluttered environment is difficult because segmentation of the scene into objects, that is, object composition is uncertain. Due to this uncertainty, earlier work has concentrated on either identifying the "best" object composition and deciding on manipulation actions accordingly, or, tried to greedily gather information about the "best" object composition. Contrary to earlier work, we 1) utilize different possible object compositions in planning, 2) take advantage of object composition information provided by robot actions, 3) take into account the effect of different competing object hypotheses on the actual task to be performed. We cast the manipulation planning problem as a partially observable Markov decision process (POMDP) which plans over possible hypotheses of object compositions. The POMDP model chooses the action that maximizes the long-term expected task specific utility, and while doing so, considers the value of informative actions and the effect of different object hypotheses on the completion of the task. In simulations and in experiments with an RGB-D sensor, a Kinova Jaco and a Franka Emika Panda robot arm, a probabilistic approach outperforms an approach that only considers the most likely object composition and long term planning outperforms greedy decision making.
Beyond Top-Grasps Through Scene Completion
Sep 15, 2019
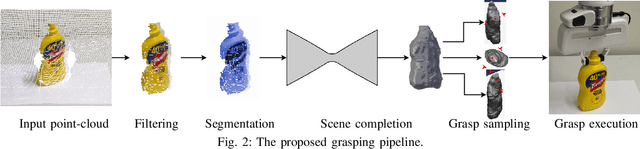

Current end-to-end grasp planning methods propose grasps in the order of (milli)seconds that attain high grasp success rates on a diverse set of objects, but often by constraining the workspace to top-grasps. In this work, we present a method that allows end-to-end top grasp planning methods to generate full six-degree-of-freedom grasps using a single RGB-D view as input. This is achieved by estimating the complete shape of the object to be grasped, then simulating different viewpoints of the object, passing the simulated viewpoints to an end-to-end grasp generation method, and finally executing the overall best grasp. The method was experimentally validated on a Franka Emika Panda by comparing 429 grasps generated by the state-of-the-art Fully Convolutional Grasp Quality CNN, both on simulated and real camera viewpoints. The results show statistically significant improvements in terms of grasp success rate when using simulated viewpoints over real camera viewpoints, especially when the real camera viewpoint is angled.
Safe Grasping with a Force Controlled Soft Robotic Hand
Sep 15, 2019
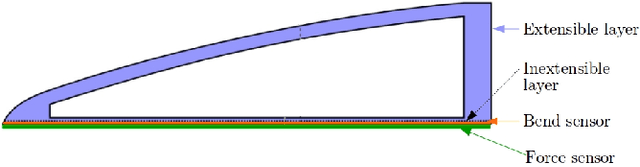
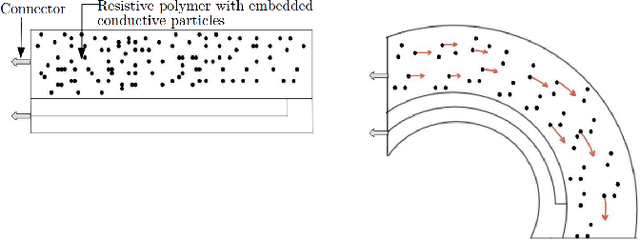
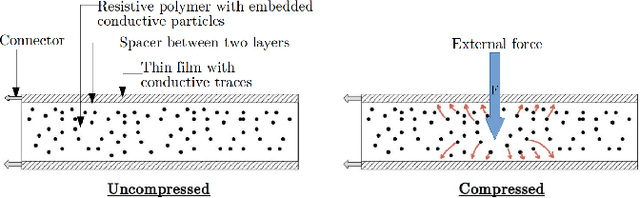
Safe yet stable grasping requires a robotic hand to apply sufficient force on the object to immobilize it while keeping it from getting damaged. Soft robotic hands have been proposed for safe grasping due to their passive compliance, but even such a hand can crush objects if the applied force is too high. Thus for safe grasping, regulating the grasping force is of uttermost importance even with soft hands. In this work, we present a force controlled soft hand and use it to achieve safe grasping. To this end, resistive force and bend sensors are integrated in a soft hand, and a data-driven calibration method is proposed to estimate contact interaction forces. Given the force readings, the pneumatic pressures are regulated using a proportional-integral controller to achieve desired force. The controller is experimentally evaluated and benchmarked by grasping easily deformable objects such as plastic and paper cups without neither dropping nor deforming them. Together, the results demonstrate that our force controlled soft hand can grasp deformable objects in a safe yet stable manner.