 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwin Augmented Architectures for Robust Classification of COVID-19 Chest X-Ray Images
Feb 16, 2021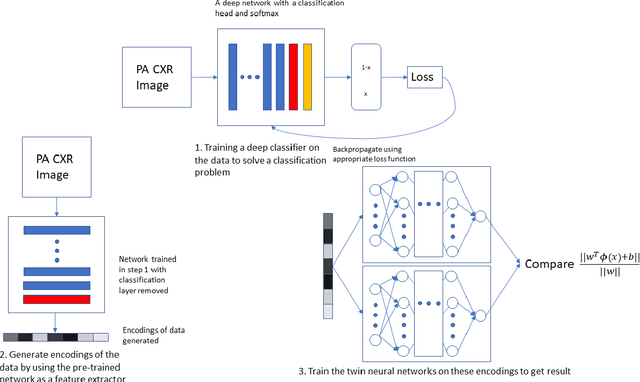
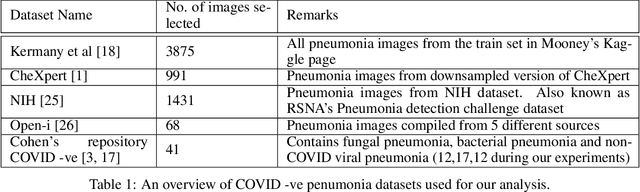
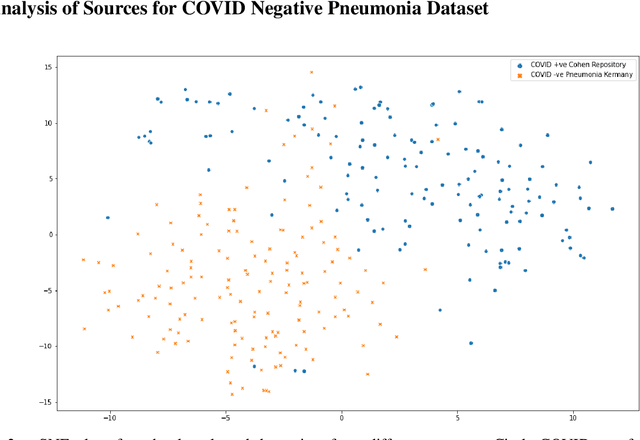
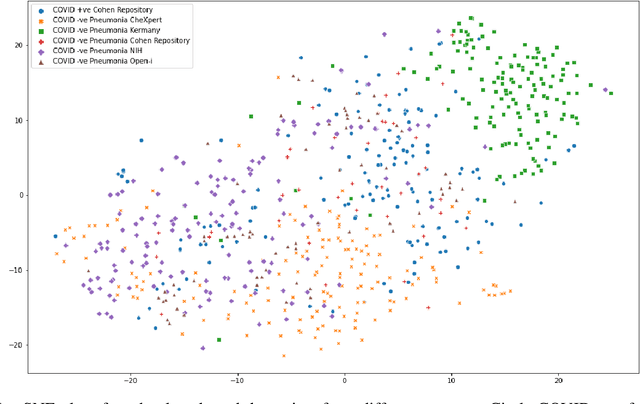
The gold standard for COVID-19 is RT-PCR, testing facilities for which are limited and not always optimally distributed. Test results are delayed, which impacts treatment. Expert radiologists, one of whom is a co-author, are able to diagnose COVID-19 positivity from Chest X-Rays (CXR) and CT scans, that can facilitate timely treatment. Such diagnosis is particularly valuable in locations lacking radiologists with sufficient expertise and familiarity with COVID-19 patients. This paper has two contributions. One, we analyse literature on CXR based COVID-19 diagnosis. We show that popular choices of dataset selection suffer from data homogeneity, leading to misleading results. We compile and analyse a viable benchmark dataset from multiple existing heterogeneous sources. Such a benchmark is important for realistically testing models. Our second contribution relates to learning from imbalanced data. Datasets for COVID X-Ray classification face severe class imbalance, since most subjects are COVID -ve. Twin Support Vector Machines (Twin SVM) and Twin Neural Networks (Twin NN) have, in recent years, emerged as effective ways of handling skewed data. We introduce a state-of-the-art technique, termed as Twin Augmentation, for modifying popular pre-trained deep learning models. Twin Augmentation boosts the performance of a pre-trained deep neural network without requiring re-training. Experiments show, that across a multitude of classifiers, Twin Augmentation is very effective in boosting the performance of given pre-trained model for classification in imbalanced settings.
Complexity Controlled Generative Adversarial Networks
Nov 20, 2020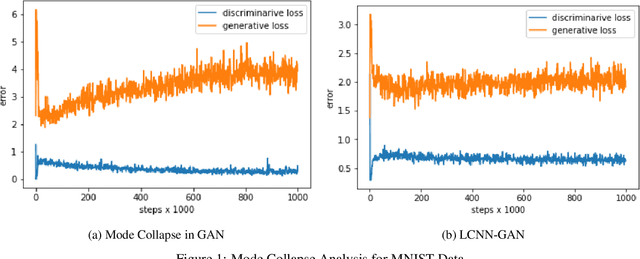
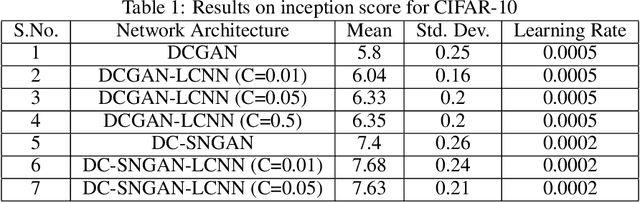


One of the issues faced in training Generative Adversarial Nets (GANs) and their variants is the problem of mode collapse, wherein the training stability in terms of the generative loss increases as more training data is used. In this paper, we propose an alternative architecture via the Low-Complexity Neural Network (LCNN), which attempts to learn models with low complexity. The motivation is that controlling model complexity leads to models that do not overfit the training data. We incorporate the LCNN loss function for GANs, Deep Convolutional GANs (DCGANs) and Spectral Normalized GANs (SNGANs), in order to develop hybrid architectures called the LCNN-GAN, LCNN-DCGAN and LCNN-SNGAN respectively. On various large benchmark image datasets, we show that the use of our proposed models results in stable training while avoiding the problem of mode collapse, resulting in better training stability. We also show how the learning behavior can be controlled by a hyperparameter in the LCNN functional, which also provides an improved inception score.
Scalable Twin Neural Networks for Classification of Unbalanced Data
Jan 27, 2018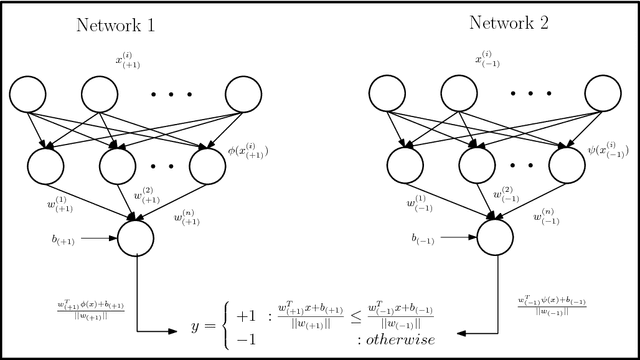
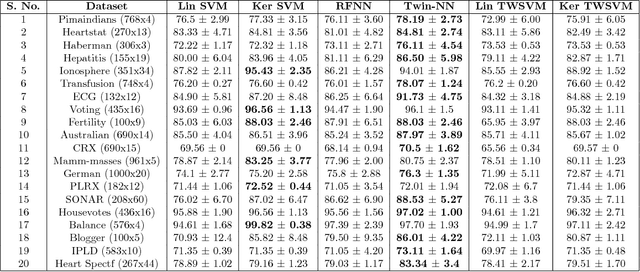
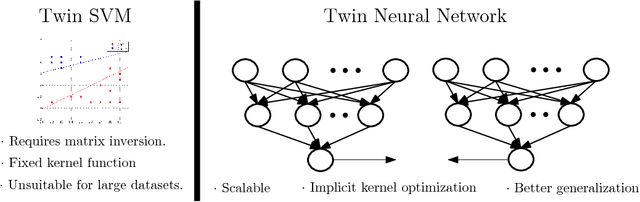
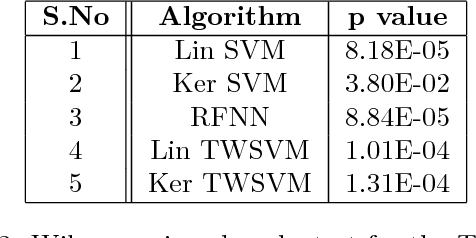
Twin Support Vector Machines (TWSVMs) have emerged an efficient alternative to Support Vector Machines (SVM) for learning from imbalanced datasets. The TWSVM learns two non-parallel classifying hyperplanes by solving a couple of smaller sized problems. However, it is unsuitable for large datasets, as it involves matrix operations. In this paper, we discuss a Twin Neural Network (Twin NN) architecture for learning from large unbalanced datasets. The Twin NN also learns an optimal feature map, allowing for better discrimination between classes. We also present an extension of this network architecture for multiclass datasets. Results presented in the paper demonstrate that the Twin NN generalizes well and scales well on large unbalanced datasets.
Learning Neural Network Classifiers with Low Model Complexity
Jan 02, 2018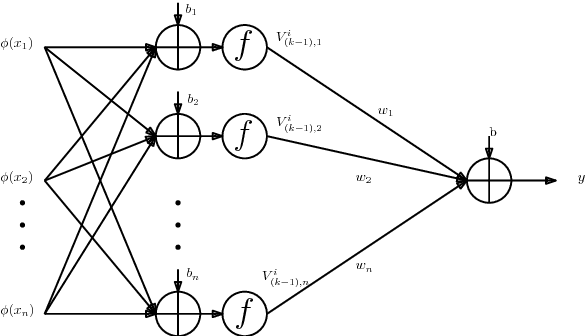


Modern neural network architectures for large-scale learning tasks have substantially higher model complexities, which makes understanding, visualizing and training these architectures difficult. Recent contributions to deep learning techniques have focused on architectural modifications to improve parameter efficiency and performance. In this paper, we derive a continuous and differentiable error functional for a neural network that minimizes its empirical error as well as a measure of the model complexity. The latter measure is obtained by deriving a differentiable upper bound on the Vapnik-Chervonenkis (VC) dimension of the classifier layer of a class of deep networks. Using standard backpropagation, we realize a training rule that tries to minimize the error on training samples, while improving generalization by keeping the model complexity low. We demonstrate the effectiveness of our formulation (the Low Complexity Neural Network - LCNN) across several deep learning algorithms, and a variety of large benchmark datasets. We show that hidden layer neurons in the resultant networks learn features that are crisp, and in the case of image datasets, quantitatively sharper. Our proposed approach yields benefits across a wide range of architectures, in comparison to and in conjunction with methods such as Dropout and Batch Normalization, and our results strongly suggest that deep learning techniques can benefit from model complexity control methods such as the LCNN learning rule.