 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDERT: Distilling Encoder Representations with Co-learning for Transducer-based Speech Recognition
Jun 14, 2021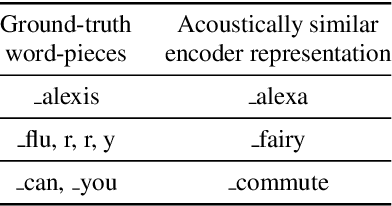
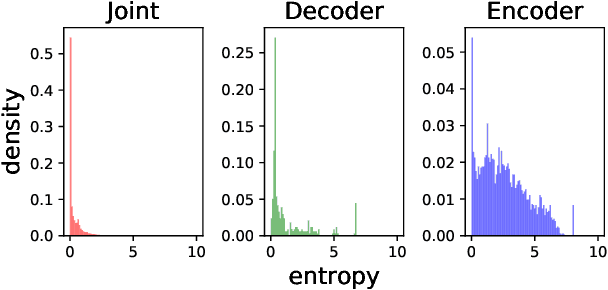
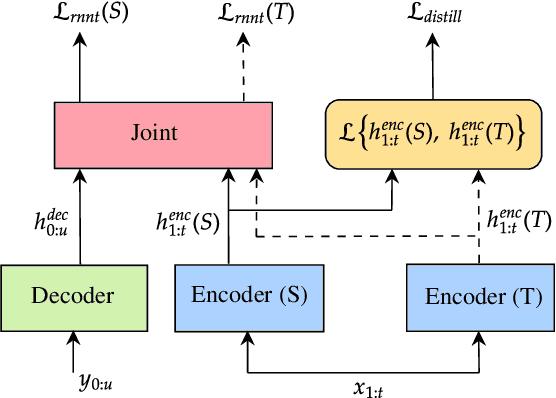
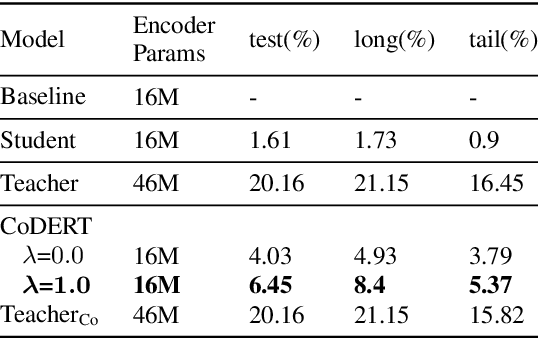
We propose a simple yet effective method to compress an RNN-Transducer (RNN-T) through the well-known knowledge distillation paradigm. We show that the transducer's encoder outputs naturally have a high entropy and contain rich information about acoustically similar word-piece confusions. This rich information is suppressed when combined with the lower entropy decoder outputs to produce the joint network logits. Consequently, we introduce an auxiliary loss to distill the encoder logits from a teacher transducer's encoder, and explore training strategies where this encoder distillation works effectively. We find that tandem training of teacher and student encoders with an inplace encoder distillation outperforms the use of a pre-trained and static teacher transducer. We also report an interesting phenomenon we refer to as implicit distillation, that occurs when the teacher and student encoders share the same decoder. Our experiments show 5.37-8.4% relative word error rate reductions (WERR) on in-house test sets, and 5.05-6.18% relative WERRs on LibriSpeech test sets.
Scaling Laws for Acoustic Models
Jun 11, 2021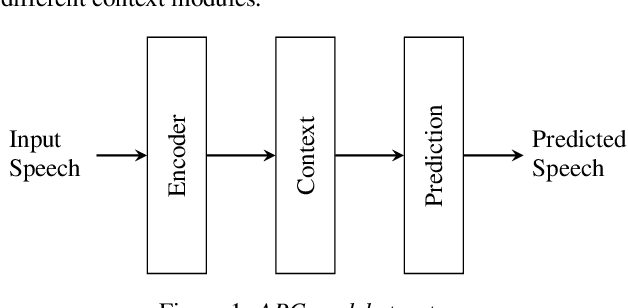
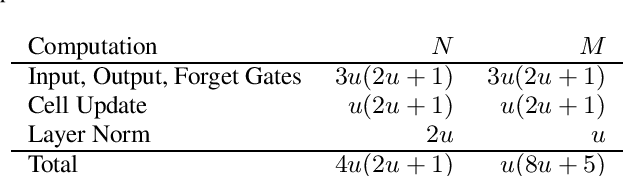
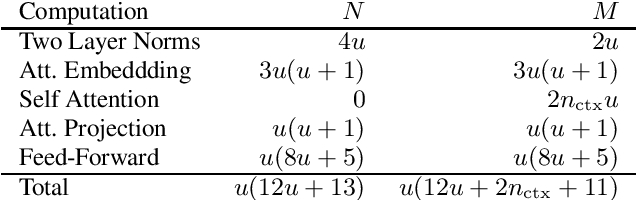
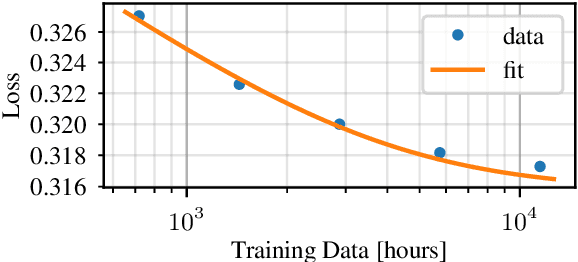
There is a recent trend in machine learning to increase model quality by growing models to sizes previously thought to be unreasonable. Recent work has shown that autoregressive generative models with cross-entropy objective functions exhibit smooth power-law relationships, or scaling laws, that predict model quality from model size, training set size, and the available compute budget. These scaling laws allow one to choose nearly optimal hyper-parameters given constraints on available training data, model parameter count, or training computation budget. In this paper, we demonstrate that acoustic models trained with an auto-predictive coding loss behave as if they are subject to similar scaling laws. We extend previous work to jointly predict loss due to model size, to training set size, and to the inherent "irreducible loss" of the task. We find that the scaling laws accurately match model performance over two orders of magnitude in both model size and training set size, and make predictions about the limits of model performance.
Improving multi-speaker TTS prosody variance with a residual encoder and normalizing flows
Jun 10, 2021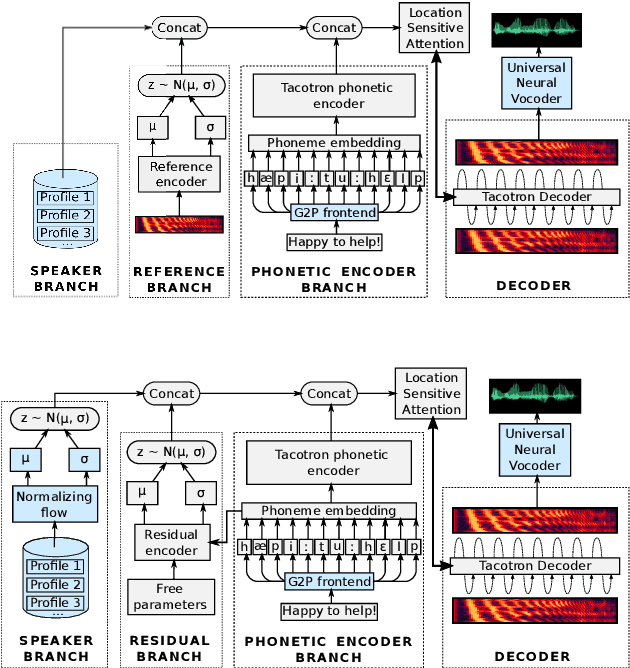

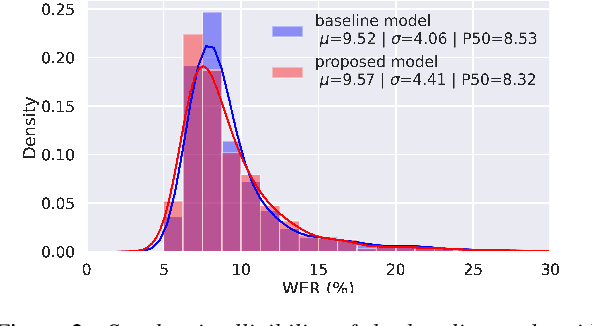

Text-to-speech systems recently achieved almost indistinguishable quality from human speech. However, the prosody of those systems is generally flatter than natural speech, producing samples with low expressiveness. Disentanglement of speaker id and prosody is crucial in text-to-speech systems to improve on naturalness and produce more variable syntheses. This paper proposes a new neural text-to-speech model that approaches the disentanglement problem by conditioning a Tacotron2-like architecture on flow-normalized speaker embeddings, and by substituting the reference encoder with a new learned latent distribution responsible for modeling the intra-sentence variability due to the prosody. By removing the reference encoder dependency, the speaker-leakage problem typically happening in this kind of systems disappears, producing more distinctive syntheses at inference time. The new model achieves significantly higher prosody variance than the baseline in a set of quantitative prosody features, as well as higher speaker distinctiveness, without decreasing the speaker intelligibility. Finally, we observe that the normalized speaker embeddings enable much richer speaker interpolations, substantially improving the distinctiveness of the new interpolated speakers.
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 14, 2021

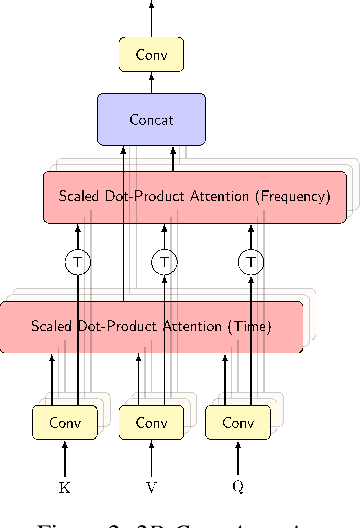

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.
Listen with Intent: Improving Speech Recognition with Audio-to-Intent Front-End
May 14, 2021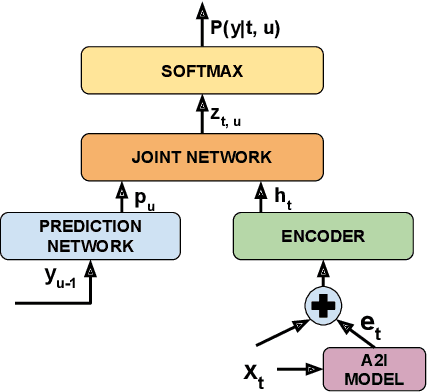
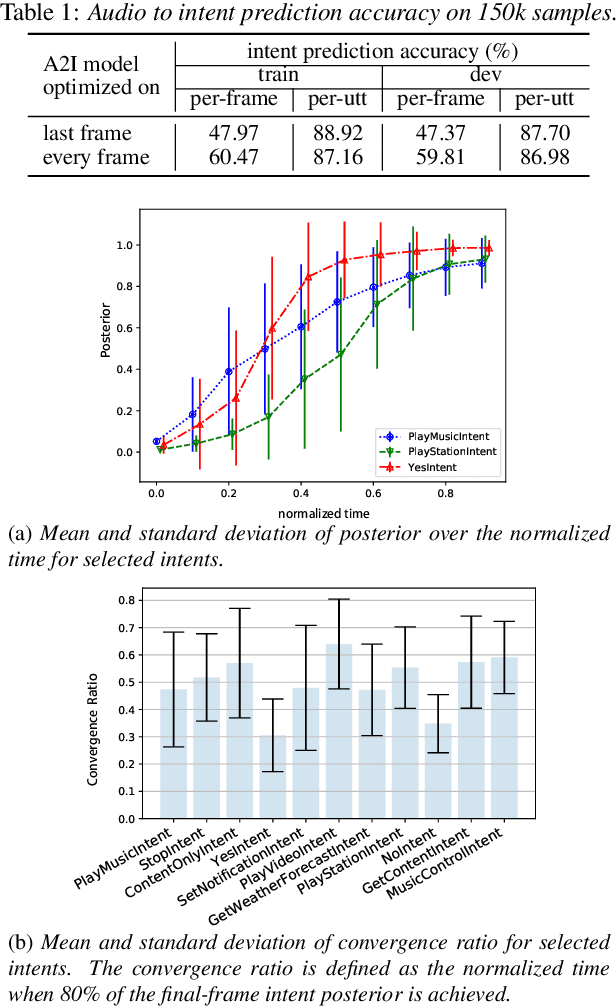
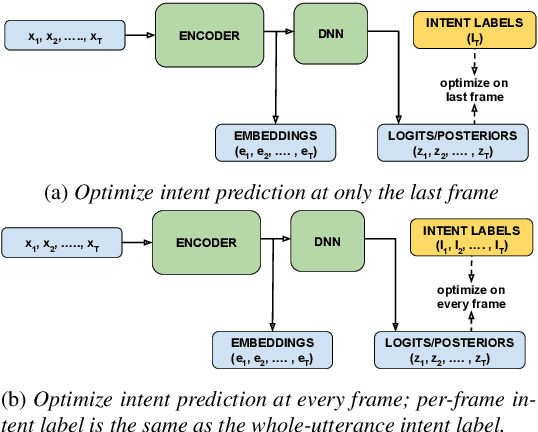
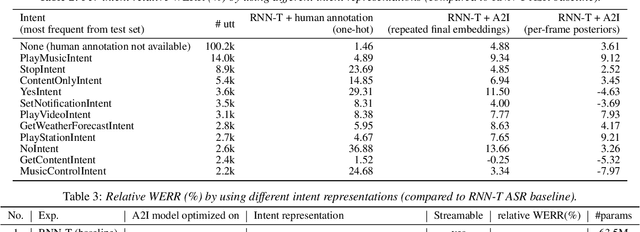
Comprehending the overall intent of an utterance helps a listener recognize the individual words spoken. Inspired by this fact, we perform a novel study of the impact of explicitly incorporating intent representations as additional information to improve a recurrent neural network-transducer (RNN-T) based automatic speech recognition (ASR) system. An audio-to-intent (A2I) model encodes the intent of the utterance in the form of embeddings or posteriors, and these are used as auxiliary inputs for RNN-T training and inference. Experimenting with a 50k-hour far-field English speech corpus, this study shows that when running the system in non-streaming mode, where intent representation is extracted from the entire utterance and then used to bias streaming RNN-T search from the start, it provides a 5.56% relative word error rate reduction (WERR). On the other hand, a streaming system using per-frame intent posteriors as extra inputs for the RNN-T ASR system yields a 3.33% relative WERR. A further detailed analysis of the streaming system indicates that our proposed method brings especially good gain on media-playing related intents (e.g. 9.12% relative WERR on PlayMusicIntent).
Wav2vec-C: A Self-supervised Model for Speech Representation Learning
Mar 09, 2021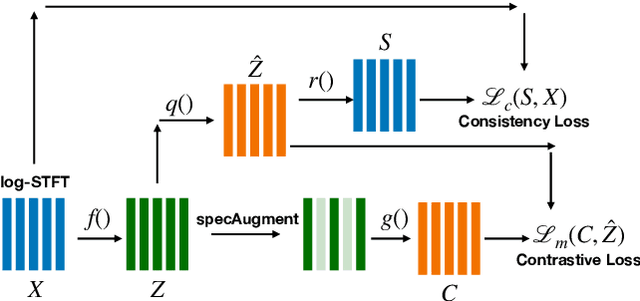

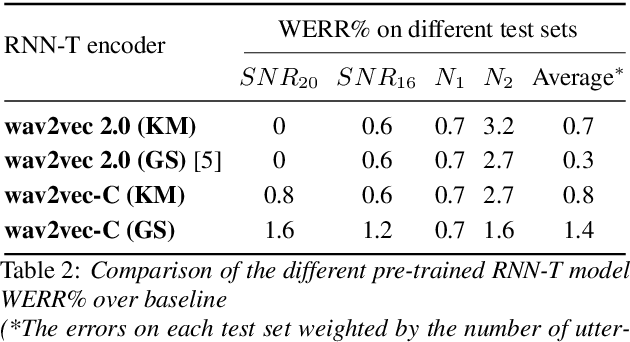
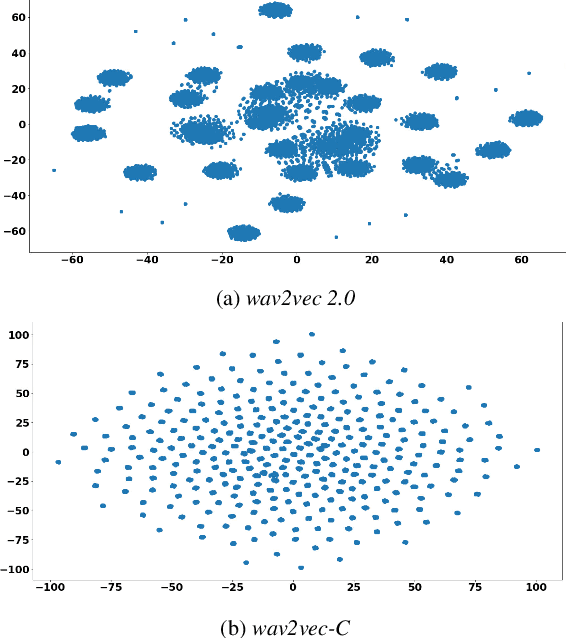
Wav2vec-C introduces a novel representation learning technique combining elements from wav2vec 2.0 and VQ-VAE. Our model learns to reproduce quantized representations from partially masked speech encoding using a contrastive loss in a way similar to Wav2vec 2.0. However, the quantization process is regularized by an additional consistency network that learns to reconstruct the input features to the wav2vec 2.0 network from the quantized representations in a way similar to a VQ-VAE model. The proposed self-supervised model is trained on 10k hours of unlabeled data and subsequently used as the speech encoder in a RNN-T ASR model and fine-tuned with 1k hours of labeled data. This work is one of only a few studies of self-supervised learning on speech tasks with a large volume of real far-field labeled data. The Wav2vec-C encoded representations achieves, on average, twice the error reduction over baseline and a higher codebook utilization in comparison to wav2vec 2.0
Do as I mean, not as I say: Sequence Loss Training for Spoken Language Understanding
Feb 12, 2021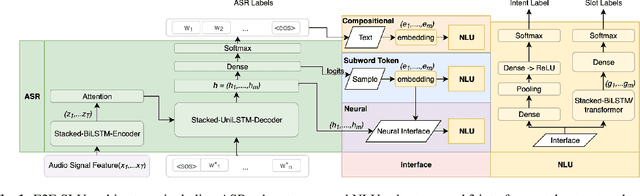
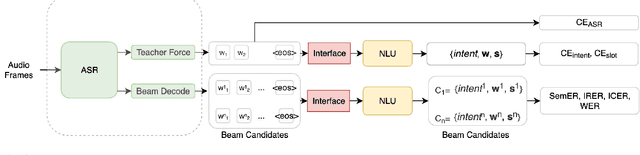
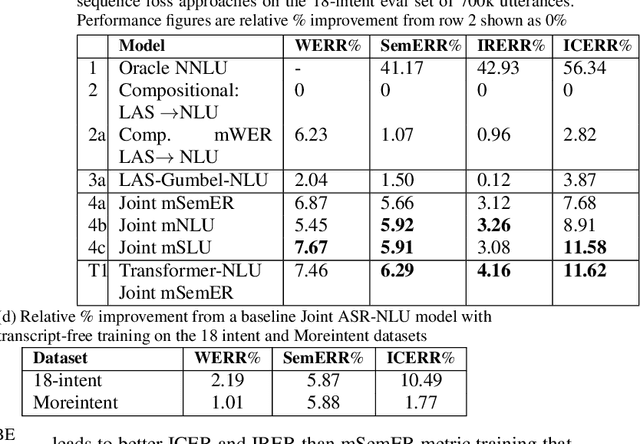
Spoken language understanding (SLU) systems extract transcriptions, as well as semantics of intent or named entities from speech, and are essential components of voice activated systems. SLU models, which either directly extract semantics from audio or are composed of pipelined automatic speech recognition (ASR) and natural language understanding (NLU) models, are typically trained via differentiable cross-entropy losses, even when the relevant performance metrics of interest are word or semantic error rates. In this work, we propose non-differentiable sequence losses based on SLU metrics as a proxy for semantic error and use the REINFORCE trick to train ASR and SLU models with this loss. We show that custom sequence loss training is the state-of-the-art on open SLU datasets and leads to 6% relative improvement in both ASR and NLU performance metrics on large proprietary datasets. We also demonstrate how the semantic sequence loss training paradigm can be used to update ASR and SLU models without transcripts, using semantic feedback alone.
Detection of Lexical Stress Errors in Non-native English with Data Augmentation and Attention
Dec 29, 2020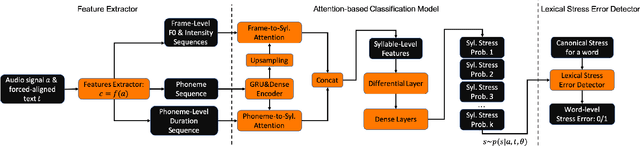
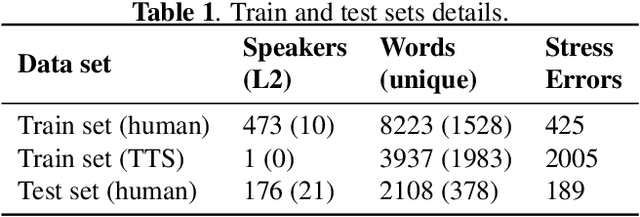
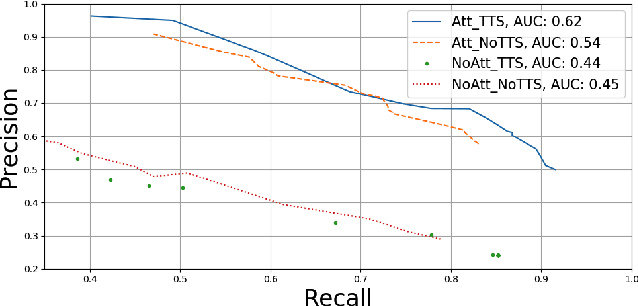
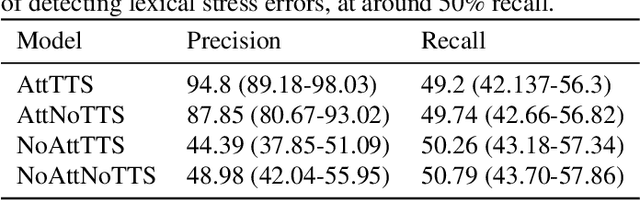
This paper describes two novel complementary techniques that improve the detection of lexical stress errors in non-native (L2) English speech: attention-based feature extraction and data augmentation based on Neural Text-To-Speech (TTS). In a classical approach, audio features are usually extracted from fixed regions of speech such as syllable nucleus. We propose an attention-based deep learning model that automatically derives optimal syllable-level representation from frame-level and phoneme-level audio features. Training this model is challenging because of the limited amount of incorrect stress patterns. To solve this problem, we propose to augment the training set with incorrectly stressed words generated with Neural TTS. Combining both techniques achieves 94.8\% precision and 49.2\% recall for the detection of incorrectly stressed words in L2 English speech of Slavic speakers.
Efficient minimum word error rate training of RNN-Transducer for end-to-end speech recognition
Jul 27, 2020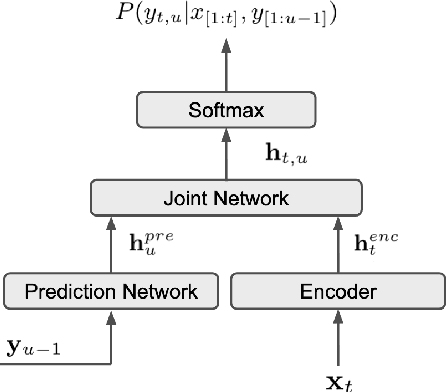
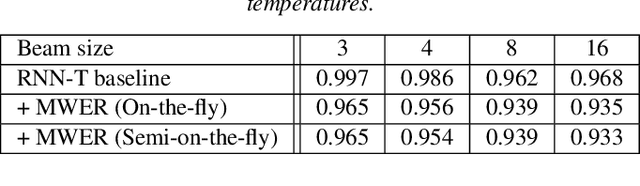
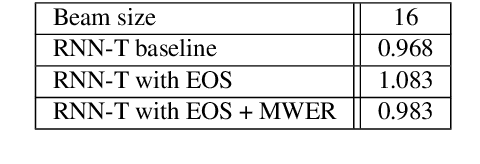
In this work, we propose a novel and efficient minimum word error rate (MWER) training method for RNN-Transducer (RNN-T). Unlike previous work on this topic, which performs on-the-fly limited-size beam-search decoding and generates alignment scores for expected edit-distance computation, in our proposed method, we re-calculate and sum scores of all the possible alignments for each hypothesis in N-best lists. The hypothesis probability scores and back-propagated gradients are calculated efficiently using the forward-backward algorithm. Moreover, the proposed method allows us to decouple the decoding and training processes, and thus we can perform offline parallel-decoding and MWER training for each subset iteratively. Experimental results show that this proposed semi-on-the-fly method can speed up the on-the-fly method by 6 times and result in a similar WER improvement (3.6%) over a baseline RNN-T model. The proposed MWER training can also effectively reduce high-deletion errors (9.2% WER-reduction) introduced by RNN-T models when EOS is added for endpointer. Further improvement can be achieved if we use a proposed RNN-T rescoring method to re-rank hypotheses and use external RNN-LM to perform additional rescoring. The best system achieves a 5% relative improvement on an English test-set of real far-field recordings and a 11.6% WER reduction on music-domain utterances.
Acoustic-To-Word Model Without OOV
Nov 28, 2017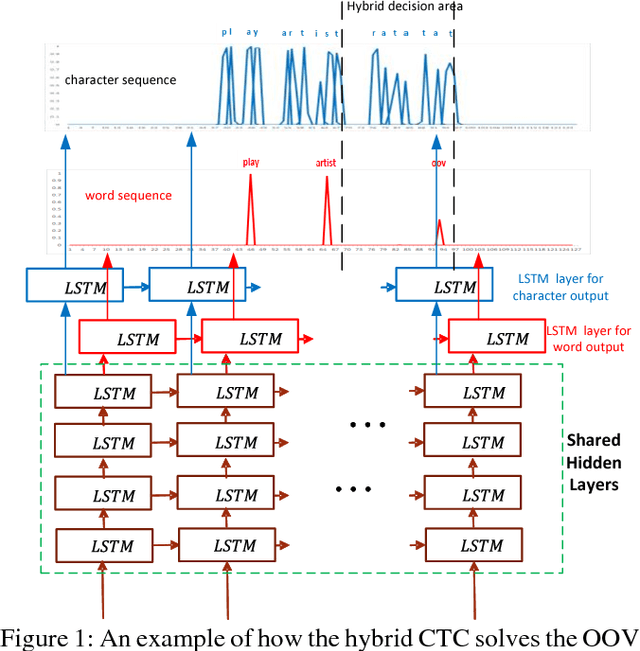


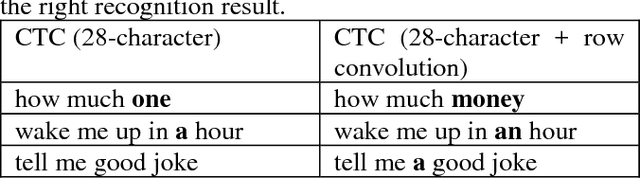
Recently, the acoustic-to-word model based on the Connectionist Temporal Classification (CTC) criterion was shown as a natural end-to-end model directly targeting words as output units. However, this type of word-based CTC model suffers from the out-of-vocabulary (OOV) issue as it can only model limited number of words in the output layer and maps all the remaining words into an OOV output node. Therefore, such word-based CTC model can only recognize the frequent words modeled by the network output nodes. It also cannot easily handle the hot-words which emerge after the model is trained. In this study, we improve the acoustic-to-word model with a hybrid CTC model which can predict both words and characters at the same time. With a shared-hidden-layer structure and modular design, the alignments of words generated from the word-based CTC and the character-based CTC are synchronized. Whenever the acoustic-to-word model emits an OOV token, we back off that OOV segment to the word output generated from the character-based CTC, hence solving the OOV or hot-words issue. Evaluated on a Microsoft Cortana voice assistant task, the proposed model can reduce the errors introduced by the OOV output token in the acoustic-to-word model by 30%.